
Today the subject of investigation is the Temporal Table, which is a new feature in SQL Server 2016. My focus will slightly be on how to use it in Data Warehouse environments, but there is some general information passing by as I write.
I want to cover next topics:
- What is a temporal table (in short)?
- Can I use a temporal table for a table in the PSA (Persistent Staging Area)?
- Can I use a temporal table for a Data Vault Satellite?
- Is using temporal tables for full auditing in an OLTP system a good idea?
What is a temporal table (in short)?
In short, a temporal table is a table that tracks changes in a (temporal) table to a second “History” table, and this process is managed by SQL Server 2016 itself, you do not have to write extra code for that.
Stated in the free eBook Introducing Microsoft SQL Server 2016 is the following:
“When you create a temporal table, you must include a primary key and non-nullable period columns, a pair of columns having a datetime2 data type that you use as the start and end periods for which a row is valid.”
For more details please read the book.
You can also read more about temporal tables on MSDN.
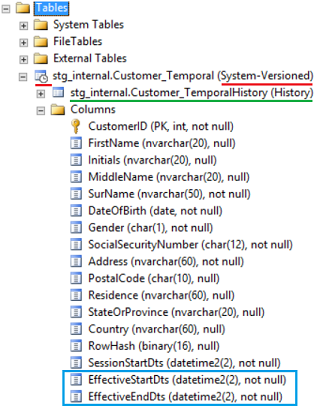
An example of how a temporal table looks in SQL Server Management Studio. You can see by the icon and the suffix (System Versioned) (both marked red) that this is a temporal table. Underneath the table node is history table is shown (marked with green). Start- and enddatetime are required columns, but you can give them a custom name (marked blue).
There are three ways to create the history table for a temporal table:
- Create a temporal table with an anonymous history table: you don’t bother really about the history table, SQL Server gives it a name and creates it.
- Create a temporal table with a default history table: same as anonymous, but you provide the name for the history table to use.
- Create a temporal table with an existing history table: you create the history table first, and can optimize storage and/or indexes. Then you create the temporal table and in the CREATE statement provide the name of the existing history table.
So the first two are the “lazy” options, and they might be good enough for smaller tables. The third option allows you to fully tweak the history table.
I have used the third option in my Persistent Staging Area, see below.
Can I use a temporal table for a table in the PSA (Persistent Staging Area)?
In my previous blog post – Using a Persistent Staging Area: What, Why, and How – you could read what a Persistent Staging Area (or PSA for short) is.
Today I want to share my experiences on my lab tests using temporal tables in the PSA.
But besides a temporal table, I have also created a “normal” staging table, for loading the data. This is because:
- A temporal table cannot be truncated, and because truncate is much faster than delete, I create a normal staging table to load the data from the source.
- I want load the source data as fast as possible, so I prefer plain insert instead of doing change detection with the rows currently in the temporal table. This would be slower, and I preferably do that later in parallel with loading the rest of the EDW.
- Because I want the PSA to stay optional and not a core part of the EDW. If the PSA is additional to a normal Staging Area, it is easier to switch off later.
Here is the script I used to create the temporal table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
--\ ---) Create the history table ourselves, to be used as a backing table ---) for a Temporal table, so we can tweak it for optimal performance. ---) Please note that I use the datatype DATETIME2(2) because it ---) uses 6 bytes storage, whereas DATETIME2(7) uses 8 bytes. ---) If the centiseconds precision of DATETIME2(2) is not enough ---) in your data warehouse, you can change it to DATETIME2(7). --/ CREATE TABLE [psa].[Customer_TemporalHistory] ( [CustomerID] INT NOT NULL, [FirstName] NVARCHAR(20) NULL, [Initials] NVARCHAR(20) NULL, [MiddleName] NVARCHAR(20) NULL, [SurName] NVARCHAR(50) NOT NULL, [DateOfBirth] DATE NOT NULL, [Gender] CHAR(1) NOT NULL, [SocialSecurityNumber] CHAR(12) NOT NULL, [Address] NVARCHAR(60) NOT NULL, [PostalCode] CHAR(10) NULL, [Residence] NVARCHAR(60) NULL, [StateOrProvince] NVARCHAR(20) NULL, [Country] NVARCHAR(60) NULL, [RowHash] BINARY(16), [SessionStartDts] DATETIME2(2) NOT NULL, [EffectiveStartDts] DATETIME2(2) NOT NULL, [EffectiveEndDts] DATETIME2(2) NOT NULL ); GO --\ ---) Add indexes to history table --/ CREATE CLUSTERED COLUMNSTORE INDEX [IXCS_Customer_TemporalHistory] ON [psa].[Customer_TemporalHistory]; CREATE NONCLUSTERED INDEX [IXNC_Customer_TemporalHistory__EffectiveEndDts_EffectiveStartDts_CustomerID] ON [psa].[Customer_TemporalHistory] ([EffectiveEndDts], [EffectiveStartDts], [CustomerID]); GO --\ ---) Now create the temporal table --/ CREATE TABLE [psa].[Customer_Temporal] ( [CustomerID] INT NOT NULL, [FirstName] NVARCHAR(20) NULL, [Initials] NVARCHAR(20) NULL, [MiddleName] NVARCHAR(20) NULL, [SurName] NVARCHAR(50) NOT NULL, [DateOfBirth] DATE NOT NULL, [Gender] CHAR(1) NOT NULL, [SocialSecurityNumber] CHAR(12) NOT NULL, [Address] NVARCHAR(60) NOT NULL, [PostalCode] CHAR(10) NULL, [Residence] NVARCHAR(60) NULL, [StateOrProvince] NVARCHAR(20) NULL, [Country] NVARCHAR(60) NULL, [RowHash] BINARY(16), [SessionStartDts] DATETIME2(2) NOT NULL, -- SessionStartDts is manually set, and is the same for all -- rows of the same session/loadcycle. CONSTRAINT [PK_Customer_Temporal] PRIMARY KEY CLUSTERED ([CustomerID] ASC), [EffectiveStartDts] DATETIME2(2) GENERATED ALWAYS AS ROW START NOT NULL, [EffectiveEndDts] DATETIME2(2) GENERATED ALWAYS AS ROW END NOT NULL, PERIOD FOR SYSTEM_TIME ([EffectiveStartDts], [EffectiveEndDts]) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [psa].[Customer_TemporalHistory])); GO -- Add a few indexes. CREATE NONCLUSTERED INDEX [IXNC_Customer_Temporal__EffectiveEndDts_EffectiveStartDts_CustomerID] ON [psa].[Customer_Temporal] ([EffectiveEndDts], [EffectiveStartDts], [CustomerID]); CREATE NONCLUSTERED INDEX [IXNC_Customer_Temporal__CustomerID_RowHash] ON [psa].[Customer_Temporal] ([CustomerID], [RowHash]); GO |
Note: I have not included all the scripts that I used for my test in this article, because it could be overwhelming. But if you are interested you can download all the scripts and the two SSIS testpackages here.
Maybe you are as curious as me to know if using temporal tables for a PSA is a good idea.
Considerations are the following:
- Speed of data loading.
- Speed of reading rows at a certain moment in time (time travel mechanism).
- Ability to adopt changes in the datamodel.
- Simplicity and reliability of the solution
- Ability to do historic loads, for instance from archived source files or an older data warehouse.
And of course we need something to compare with. Let that be a plain SQL Server table with a start- and enddatetime.
Before I present you the testresults, I just want to tell a few details about the test:
- For testing I use a “Customer” table that is filled with half a million rows of dummy data.
- I simulate 50 daily loads with deletes, inserts and updates in the staging table. After those 50 runs, the total number of rows has more than quadrupled to just over 2.2 million (2237460 to be exactly).
- For the DATETIME2 columns, I use a precision of centiseconds, so DATETIME2(2). For justification see one of my older blog posts: Stop being so precise! and more about using Load(end)dates (Datavault Series). If needed you can use a higher precision for your data warehouse.
- For change detection I use a [RowHash] column, which is a MD5 hashvalue of all columns of a row that are relevant for a change (so start- and enddate are not used for the hashvalue). This is done primarily for having a better performance while comparing new and existing rows.
- I have compared all data in both the Non temporal PSA table and the temporal table with backing history table to check that the rows where exactly the same and this was the case (except for Start- and Enddates).
Speed of data loading
Using T-SQL for synchronizing data from a staging table to a PSA table I got the following testresults:
| Testcase | Average duration (50 loads, in ms) |
| Synchronize PSA temporal | 6159 |
| Synchronize PSA Non-temporal | 24590 |
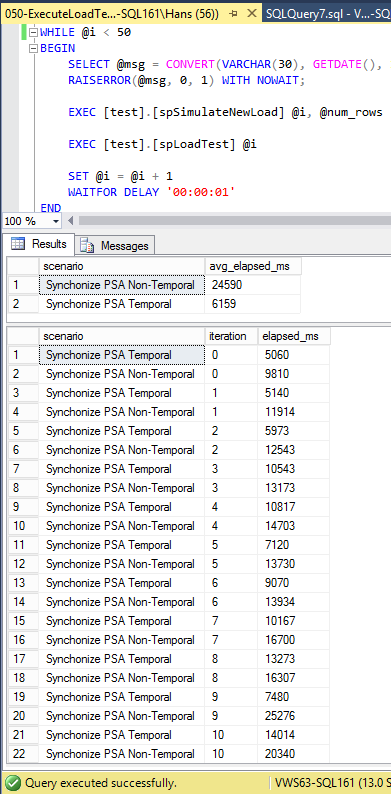
So we have a winner here, it’s the temporal table! It’s four times faster!
Speed of reading rows at a certain moment in time (time travel mechanism)
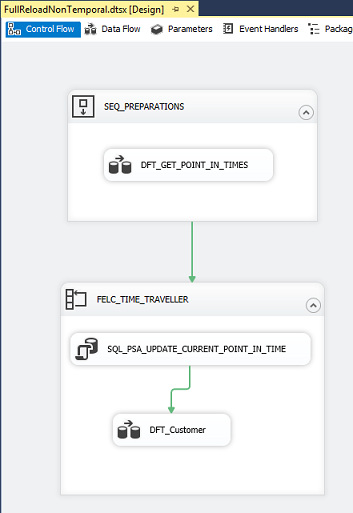
For reading, I used two views and two SSIS Packages with a time travel mechanism and a data flow task.
The views return the rows valid at a certain point in time, selected from the temporal and non-temporal history table, respectively.
The data flow tasks in the SSIS packages have a conditional split that is used to prevent that the rows actually are inserted into the OLE DB Destination. In this way it is a more pure readtest.
Here are the views that were used:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 |
--\ ---) For the demo, the virtualization layer is slightly different from a real life scenario. ---) Normally you would create separate databases for the Staging Area and the PSA, so you could do ---) the connection swap as explained here: ---) http://www.hansmichiels.com/2017/02/18/using-a-persistent-staging-area-what-why-and-how/ ---) Normally you would also either have a normal history table or a temporal one, but not both. ---) As I now have three objects that would like to have the virtual name [stg].[Customer], I use a ---) suffix for the PSA versions, as this is workable for the demo. ---) So: ---) [stg].[Customer]: view on the normal [stg_internal].[Customer] table (only in downloadable materials). ---) [stg].[Customer_H]: view on the [psa].[Customer_History] table. ---) [stg].[Customer_TH]: view on the [psa].[Customer_Temporal] table. --/ -------------- [Customer_H] -------------- IF OBJECT_ID('[stg].[Customer_H]', 'V') IS NOT NULL DROP VIEW [stg].[Customer_H]; SET ANSI_NULLS ON SET QUOTED_IDENTIFIER ON GO CREATE VIEW [stg].[Customer_H] AS /* ========================================================================================== Author: Hans Michiels Create date: 15-FEB-2017 Description: Virtualization view in order to be able to to full reloads from the PSA. ========================================================================================== */ SELECT hist.[CustomerID], hist.[FirstName], hist.[Initials], hist.[MiddleName], hist.[SurName], hist.[DateOfBirth], hist.[Gender], hist.[SocialSecurityNumber], hist.[Address], hist.[PostalCode], hist.[Residence], hist.[StateOrProvince], hist.[Country], hist.[RowHash], hist.[SessionStartDts] FROM [psa].[PointInTime] AS pit JOIN [psa].[Customer_History] AS hist ON hist.EffectiveStartDts <= pit.CurrentPointInTime AND hist.EffectiveEndDts > pit.CurrentPointInTime GO -------------- [Customer_TH] -------------- IF OBJECT_ID('[stg].[Customer_TH]', 'V') IS NOT NULL DROP VIEW [stg].[Customer_TH]; SET ANSI_NULLS ON SET QUOTED_IDENTIFIER ON GO CREATE VIEW [stg].[Customer_TH] AS /* ========================================================================================== Author: Hans Michiels Create date: 15-FEB-2017 Description: Virtualization view in order to be able to to full reloads from the PSA. ========================================================================================== */ SELECT hist.[CustomerID], hist.[FirstName], hist.[Initials], hist.[MiddleName], hist.[SurName], hist.[DateOfBirth], hist.[Gender], hist.[SocialSecurityNumber], hist.[Address], hist.[PostalCode], hist.[Residence], hist.[StateOrProvince], hist.[Country], hist.[RowHash], hist.[SessionStartDts] FROM [psa].[PointInTime] AS pit JOIN [psa].[Customer_Temporal] FOR SYSTEM_TIME ALL AS hist -- "FOR SYSTEM_TIME AS OF" does only work with a constant value or variable, -- not by using a column from a joined table, e.g. pit.[CurrentPointInTime] -- So unfortunately we have to select all rows, and then do the date logic ourselves -- -- Under the hood, a temporal table uses EXCLUSIVE enddating: -- the enddate of a row is equal to the startdate of the rows that replaces it. -- Therefore we can not use BETWEEN, as this includes the enddatetime. ON hist.EffectiveStartDts <= pit.CurrentPointInTime AND hist.EffectiveEndDts > pit.CurrentPointInTime -- By the way, there are more ways to do this, you could also use a CROSS JOIN and -- a WHERE clause here, instead doing the datetime filtering in the join. GO |
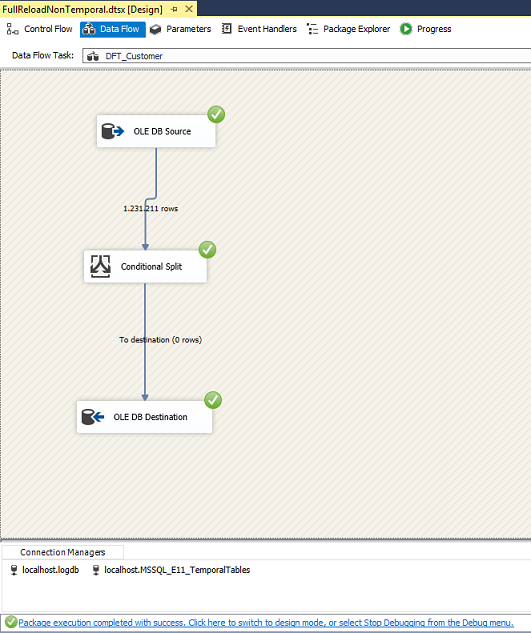
For measuring the duration I simply used my logging framework (see A Plug and Play Logging Solution) and selected the start- and enddatetime of the package executions from the [logdb].[log].[Execution] table.
Here are the results:
| Testcase | Total duration (50 reads, in seconds) |
| Read PSA temporal | 164 |
| Read PSA Non-temporal | 2686 |
And again, a very convincing winner, it is the temporal table again. It is even 16 times faster! I am still wondering how this is possible. Both tables have similar indexes, of which one columnstore, and whatever I tried, I kept getting the same differences.
Ability to adopt changes in the datamodel
Change happens. So if a column is deleted or added in the source, we want to make a change in the PSA:
- if a column is deleted, we make keep in the PSA to retain history (and make it NULLABLE when required).
- if a column is added, we also add a column.
I have tested the cases above plus the deletion of a column for the temporal table.
And yes, this works. You only have to change the temporal table (add, alter or drop column), the backing history table is changed automaticly by SQL Server.
There are however a few exceptions when this is not the case, e.g. IDENTITY columns. You can read more about this on MSDN.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
--\ ---) Adapt Changes ---) After running this script, most other scripts are broken!! --/ --\ ---) Add a column --/ -- Staging table ALTER TABLE [stg_internal].[Customer] ADD [CreditRating] CHAR(5) NULL; GO -- Non-temporal history table ALTER TABLE [psa].[Customer_History] ADD [CreditRating] CHAR(5) NULL; GO -- Temporal history table and it's backing table. ALTER TABLE [psa].[Customer_Temporal] ADD [CreditRating] CHAR(5) NULL; -- Not needed, SQL Server will do this behind the scenes: -- ALTER TABLE [psa].[Customer_TemporalHistory] ADD [CreditRating] CHAR(5) NULL; GO --\ ---) Make a column NULLABLE --/ -- Staging table ALTER TABLE [stg_internal].[Customer] ALTER COLUMN [SocialSecurityNumber] CHAR(12) NULL; GO -- Non-temporal history table ALTER TABLE [psa].[Customer_History] ALTER COLUMN [SocialSecurityNumber] CHAR(12) NULL; GO -- Temporal history table and it's backing table. ALTER TABLE [psa].[Customer_Temporal] ALTER COLUMN [SocialSecurityNumber] CHAR(12) NULL; -- Not needed, SQL Server will do this behind the scenes: -- ALTER TABLE [psa].[Customer_TemporalHistory] ALTER COLUMN [SocialSecurityNumber] CHAR(12) NULL; GO --\ ---) Delete a column (not adviced since you will then lose history). --/ -- Staging table ALTER TABLE [stg_internal].[Customer] DROP COLUMN [StateOrProvince]; GO -- Non-temporal history table ALTER TABLE [psa].[Customer_History] DROP COLUMN [StateOrProvince]; GO -- Temporal history table and it's backing table. ALTER TABLE [psa].[Customer_Temporal] DROP COLUMN [StateOrProvince]; GO |
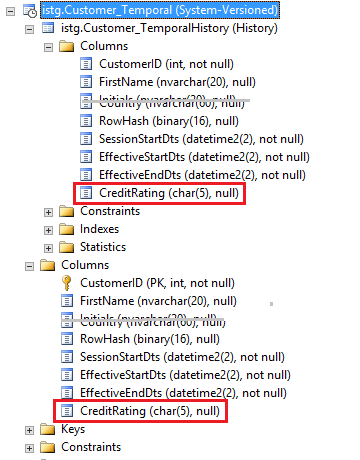
Temporal table with added column “CreditRating”: when added to the temporal table the column is also automaticly added to the backing history table. (I removed some other columns from the picture for simplicity)
But the conclusion is that a temporal table structure can be changed when needed. This is what I wanted to know.
Simplicity and reliability of the solution
Unless you use code generation tools that generate the loading process for you, and the code that comes out is thoroughly tested, I would say the code to keep track of changing using a temporal table is less complex and thus less prone to errors. Especially the enddating mechanism is handled by SQL Server, and that sounds nice to me.
There is however also a disadvantage of using a temporal table: the start- and end-datetime are out of your control, SQL Server gives it a value and there is nothing you can do about that. For Data Vault loading it is a common best practice to set the LoadDts of a Satellite to the same value for the entire load and you could defend that this would also be a good idea for a PSA table.
But, as you might have noticed, my solution for that is to just add a SessionStartDts to the table in addition to the start and end Dts that SQL Server controls. I think this is an acceptable workaround.
By the way, SQL Server always uses the UTC date for start and end datetimes of a temporal table, keep that in mind!
Ability to do historic loads
For this topic I refer to Data Vault best practices again. When using Data Vault, the LoadDateTimeStamp always reflects the current system time except when historic data is loaded: then the LoadDateTimeStamp is changed to the value of the (estimated) original date/time of the delivery of the datarow.
This can be a bit problematic when you use a PSA with system generated start and end dates, at least that is what I thought for a while. I thought this was spoiling all the fun of the temporal table.
But suddenly I realized it is not!
Let me explain this. Suppose you have this staging table SessionStartDts (or LoadDts if you like) for which you provide the value.
Besides that you have the EffectiveStartDts and EffectiveEndDts (or whatever name you give to these columns) of the temporal table that SQL Server controls.
Be aware of the role that both “timelines” must play:
- The columns that SQL Server controls are only used to select the staging rows at a point in time. They are ignored further down the way into the EDW.
- The manually set SessionStartDts, which can be set to a historic date/time, is used further down the way into the EDW to do the enddating of satellites and so on.
How this would work? As an example a view that I used for the readtest, which contain both the [SessionStartDts] and the [PointInTimeDts] (for technical reasons converted to VARCHAR). The math to get the right rows out works on the ‘technical timeline’ (SQL Server controlled columns), while the [SessionStartDts] is available later for creating timelines in satellites.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
CREATE VIEW [psa].[Timeline_H] AS /* ========================================================================================== Author: Hans Michiels Create date: 15-FEB-2017 Description: View used for time travelling. ========================================================================================== */ SELECT TOP 2147483647 CONVERT(VARCHAR(30), alltables_timeline.[SessionStartDts], 126) AS [SessionStartDtsString], -- If the point in time is the maximum value of the [EffectiveStartDts] of the applicable [SessionStartDts] -- you will select all rows that were effective/valid after this session/load. CONVERT(VARCHAR(30), MAX(alltables_timeline.[EffectiveStartDts]), 126) AS [PointInTimeDtsString] FROM ( SELECT DISTINCT subh.[SessionStartDts], subh.[EffectiveStartDts] FROM [psa].[Customer_History] subh WITH (READPAST) -- UNION MORE STAGING TABLES HERE WHEN APPLICABLE ) alltables_timeline GROUP BY CONVERT(VARCHAR(30), alltables_timeline.[SessionStartDts], 126) ORDER BY CONVERT(VARCHAR(30), alltables_timeline.[SessionStartDts], 126) GO CREATE VIEW [psa].[Timeline_TH] AS /* ========================================================================================== Author: Hans Michiels Create date: 15-FEB-2017 Description: View used for time travelling. ========================================================================================== */ SELECT TOP 2147483647 CONVERT(VARCHAR(30), alltables_timeline.[SessionStartDts], 126) AS [SessionStartDtsString], -- If the point in time is the maximum value of the [EffectiveStartDts] of the applicable [SessionStartDts] -- you will select all rows that were effective/valid after this session/load. CONVERT(VARCHAR(30), MAX(alltables_timeline.[EffectiveStartDts]), 126) AS [PointInTimeDtsString] FROM ( SELECT DISTINCT subh.[SessionStartDts], subh.[EffectiveStartDts] FROM [psa].[Customer_Temporal] FOR SYSTEM_TIME ALL AS subh WITH (READPAST) -- UNION MORE STAGING TABLES HERE WHEN APPLICABLE ) alltables_timeline GROUP BY CONVERT(VARCHAR(30), alltables_timeline.[SessionStartDts], 126) ORDER BY CONVERT(VARCHAR(30), alltables_timeline.[SessionStartDts], 126) GO |
Drawing a conclusion about using temporal tables for a PSA
| Consideration | And the winner is .. |
| Speed of data loading | Temporal table (4 times faster!) |
| Speed of reading rows at a certain moment in time (time travel mechanism) | Temporal table (16 times faster!) |
| Ability to adopt changes in the datamodel | Ex aequo (only in exceptional cases changing the temporal table is more complex). |
| Simplicity and reliability of the solution | Temporal table. |
| Ability to do historic loads | Ex aequo, if you know what you are doing. |
I think there are enough reasons for using temporal tables for a PSA! Do you agree?
Can I use a temporal table for a Data Vault Satellite?
Due to the similarities with a table in the Persistent Staging Area, I think those test results on read- and write performance also hold true for satellites.
However in satellites you cannot get away with the system generated start- and enddatetimestamps when you have to deal with historic loads, unless you do serious compromises on the technical design.
What does not work is removing SYSTEM_VERSIONING temporarily ( ALTER TABLE [psa].[Customer_temporal] SET (SYSTEM_VERSIONING = OFF)) and update the dates then. Because the columns are created as GENERATED ALWAYS this is not allowed.
Besides that, this would be a clumsy solution that still requires manual management of the timeline in a more complex way than when normal satellites were used!
So that leaves only one other solution, which requires – as said – a serious compromise on the technical design.
If you make the use of point in time tables mandatory for every hub and its satellites, you could decouple historical and technical timelines. Using a similar mechanism as the view for time travelling, you could attach the point in time date 2013-02-02 (historical) to the EffectiveStartDts (or LoadDts if you like) of 2017-02-28 06:34:42.98 (technical date from temporal table) of a certain satellite row.
And .. if you follow the holy rule that the Business Vault (in which the point in time tables exist) should always be rebuildable from the Raw Vault, you must also store the historical Startdate as an additional attribute in the satellite, but you exclude it for change detection.
Is it worth this sacrifice in order to be able to use temporal tables?
I don’t know, “it depends”. It feels like bending the Data Vault rules, but at least it can be done, keep that in mind.
Is using temporal tables for full auditing in an OLTP system a good idea?
When auditing is needed due to legislation or internal audit requirements, I certainly think it is a good idea to use temporal tables. They are transparent to front end applications that write to the database and the performance seems quite okay (see above). Obviously the performance will always be a bit worse than non-temporal tables in an OLTP scenario, but that is not unique for temporal tables. Every solution to track history will cost performance.
Conclusion / Wrap up
In this article I discussed some possible applications for the temporal table, a new feature in SQL Server 2016.
And it can be used for PSA (Persistent Staging Area) tables, Data Vault Satellites and tables in OLTP systems. If you know what you are doing, temporal tables can be of great value. That’s at least what I think.
Resources on the web
- Free ebook: introducing Microsoft SQL Server 2016 (on Microsoft web site)
- Temporal tables (MSDN).
- Changing the Schema of a System-Versioned temporal table (MSDN)
- Using a Persistent Staging Area: What, Why, and How (blog post)
- Stop being so precise! and more about using Load(end)dates (blog post)
- A Plug and Play Logging Solution (blog post)
And again. if you are interested you can download all scripts and SSIS Packages used for my test here, also the ones not published inline in this article.

He works in the software industry since 1996, with SQL Server since the year 2001, and since 2008 he has a primary focus on data warehouse and business intelligence projects using Microsoft technology, preferably a Data Vault and Kimball architecture.
He has a special interest in Data warehouse Automation and Metadata driven solutions.
* Certified in Data Vault Modeling: Certified Data Vault 2.0 Practitioner, CDVDM (aka Data Vault 1.0)
* Certified in MS SQL Server: MCSA (Microsoft Certified Solutions Associate) SQL Server 2012, - MCITP Business Intelligence Developer 2005/2008, MCITP Database Developer 2005/2008, MCITP Database Administrator 2005/2008
His web site and blog is at www.hansmichiels.com, where you can find other contact and social media details.
View all posts by Hans Michiels
- Executing your own .NET console application from SSIS - April 24, 2017
- How to mimic a wildcard search on Always Encrypted columns with Entity Framework - March 22, 2017
- Temporal Table applications in SQL Data Warehouse environments - March 7, 2017