

In this article, we will discuss how to resolve I/O problems that is a very important point for the SQL Server troubleshooting. The storage subsystem is one of the significant performance factors for the databases. Detecting and identifying I/O problems in SQL Server can be a tough task for the database administrators (DBAs). Generally, the underlying reasons for the I/O problems can be:
- Misconfigured or malfunctioning disk subsystems
- Insufficient disk performances
- Applications that generate redundant I/O activities
- Poor designed or unoptimized queries
Analyzing the symptoms should be a major principle to clarify the underlying reason that causes the I/O issues on SQL Server. Otherwise, we can waste time dealing with irrelevant issues or discussing the issues with system or storage administrators unnecessarily. Wait types give very useful information for SQL Server troubleshooting. The following wait types can indicate I/O problems, but these wait types do not suffice to decide any problem on the disks.
- PAGEIOLATCH_*
- WRITELOG
- ASYNC_IO_COMPLETION
At first, we will briefly describe these wait types and their relations to the I/O problems.
PAGEIOLATCH_*
SQL Server reserves an area on the memory to itself, and this area uses to cache data and index pages to reduce the disk activities. This reserved memory area is called Buffer Pool. The working mechanism of the buffer pool is very simple; the data loads from the disk to the memory when any request has been received for reading or changing, and they process in the buffer pool. The data is written to the disk again when it is modified. In light of this information, PAGEIOLATCH_* occurs when transferring data from disk to buffer pool. It is very normal to detect some PAGEIOLATCH_* however, it indicates a problem when we see this wait type frequently and more than the other wait types. PAGEIOLATCH_* does not indicate disk problems by oneself because this wait type can occur for a variety of reasons. For example:
- Outdated statistics or poorly designed indexes can cause to PAGEIOLATCH_* waits because these types of problems cause redundant disk activities
- Enabling CDC (Change Data Capture) option can cause extra I/O workload
- Insufficient memory can cause PAGEIOLATCH_* problems because SQL Server does not keep the data pages long enough in the buffer cache. The other sign of this problem is the Page Life Expectancy metric
WRITELOG
When any modification is performed in the database, SQL Server writes this modification to log buffer, and then it writes this buffer data to disk. Therefore, this wait type is related to the physical disk that contains the log file (ldf). Placing log files (ldf) on as fast and dedicated disks as possible will be the right approach to overcome these problems. At the same time, performance statistics of physical disks that store ldf files should be considered when this problem occurs. The log data is written into the disk sequentially, and the reading process is also performed sequentially. Due to this working principle, the disks selected for the log files must perform well for the sequential read and write throughput along with the minimum latency.
ASYNC_IO_COMPLETION
This wait type occurs when the SQL Server processes backup and restore operations; however, when this operation takes more time than usual, it might be a warning for the I/O problems. The BACKUPIO can be seen with the ASYNC_IO_COMPLETION so we can consider about any disk problem.
I/O Stalls
I/O stall time is an indicator that can be used to detect I/O problems. The dm_io_virtual_file_stats is a dynamic management function that gives detailed information about the stall times of the data and log files so it will simplify the SQL Server troubleshooting process. This dynamic management function takes two parameters first one is database id, and the second one is the database file number.
|
1 2 3 4 5 |
SELECT * FROM sys.dm_io_virtual_file_stats ( { database_id | NULL }, { file_id | NULL } ) |
We can execute this dynamic management function like the below for all databases.
|
1 2 3 4 |
select Db.name ,vfs.* from sys.dm_io_virtual_file_stats(NULL, NULL) AS VFS JOIN sys.databases AS Db ON vfs.database_id = Db.database_id |
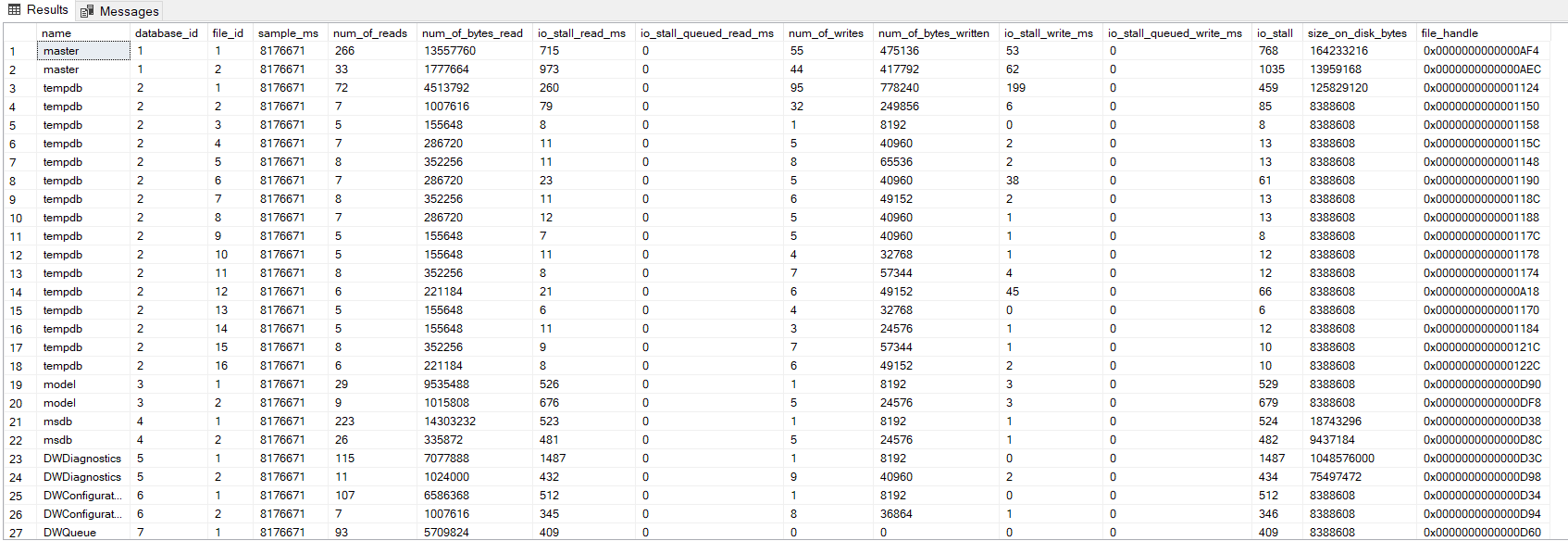
database_id: This column represents the id number of the database, and we can use sys.databases table to obtain all database id numbers.
file_id: This column represents the id number of the file, and we can use sys.master_files table to obtain all database id numbers.
sample_ms: This column shows the duration of the since server restarted.
num_of_reads: This column shows the number of physical reads that occurred since the server restarted.
num_of_bytes_reads: This column shows the total amount of physical reads in bytes that occurred since the server restarted.
io_stall_read_ms: This column shows total latency for the read operations in a millisecond.
num_of_writes: This column shows the number of writes that occurred since the server restarted.
num_of_bytes_written: This column shows the total amount of reads in bytes that occurred since the server restarted.
io_stall_write_ms: This column shows total latency for the write operations in a millisecond.
io_stall: This column shows the total latency time for the I/O operations in a millisecond.
The high stall times indicate I/O problems and busy disk activities. With the help of the following query, we can find out the read, write, and total latency of the database files so that we can diagnose any storage problems.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT DB_NAME(vfs.database_id) AS database_name ,physical_name AS [Physical Name], size_on_disk_bytes / 1024 / 1024. AS [Size of Disk] , CAST(io_stall_read_ms/(1.0 + num_of_reads) AS NUMERIC(10,1)) AS [Average Read latency] , CAST(io_stall_write_ms/(1.0 + num_of_writes) AS NUMERIC(10,1)) AS [Average Write latency] , CAST((io_stall_read_ms + io_stall_write_ms) /(1.0 + num_of_reads + num_of_writes) AS NUMERIC(10,1)) AS [Average Total Latency], num_of_bytes_read / NULLIF(num_of_reads, 0) AS [Average Bytes Per Read], num_of_bytes_written / NULLIF(num_of_writes, 0) AS [Average Bytes Per Write] FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS vfs JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id AND vfs.file_id = mf.file_id ORDER BY [Average Total Latency] DESC |
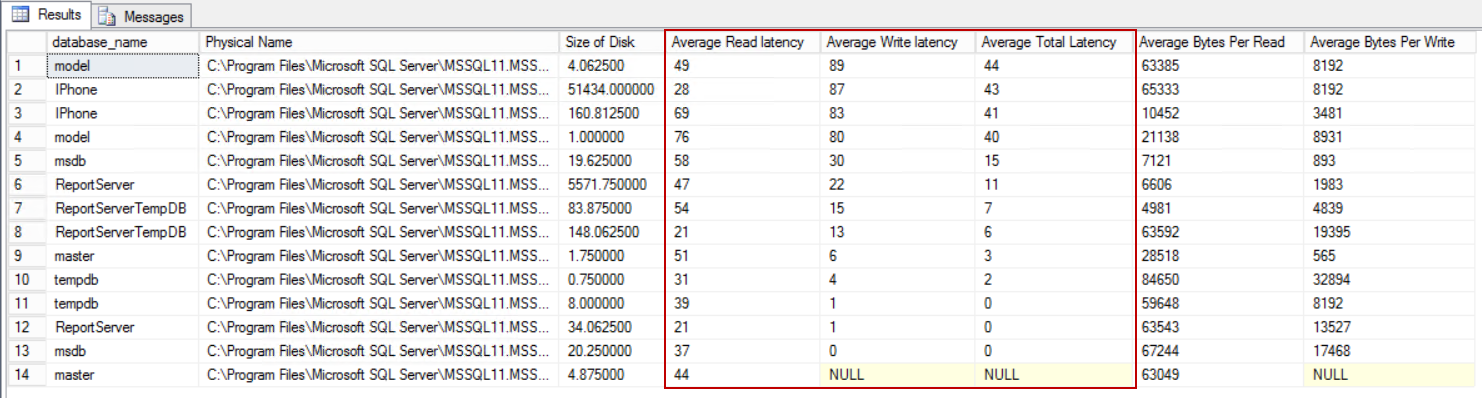
The Average Total Latency column represents the total latency about the database files, and we can use the following table as reference to evaluate the disk performance against latency.
Excellent | <1 ms |
Very good | <5 ms |
Good | <5 – 10 ms |
Poor | < 10 – 20 ms |
Bad | < 20 – 100 ms |
Very Bad | <100 ms -500 ms |
Awful | > 500 ms |
Using Performance Monitor to Analyze I/O Issues
Performance Monitor is also known as Perfmon and this tool helps to track metrics about computer resources or installed applications. Particularly, Perfmon assists in analyzing and troubleshooting SQL Server performance problems because It includes some particular counters for SQL Server beside the general resource counters. We can understand that Perfmon plays a key role in the SQL Server troubleshooting according to this explanation. When we focus on the I/O counters of the Perfmon, some of them come to the forefront. First of all, we should keep on eye to latency metrics because these values can tell everything about the disk performance.
Latency is a performance metric that measures the time gap between requests and responses for the disks. We can use the following counters to measure the disk latency.
- Avg. Disk sec/Transfer counter shows the total latency, and these values should be under the 10 milliseconds
- Avg. Disk sec/Read counter shows the read latency
- Avg. Disk sec/Write counter shows the write latency
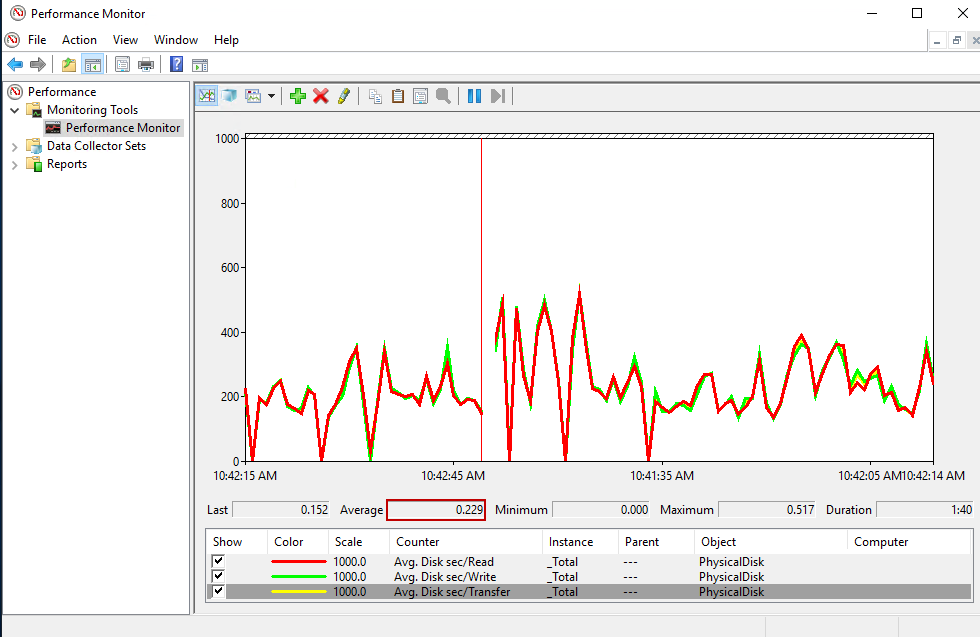
When we analyze the image above, this box performs an awful performance. The average latency is 0.229 seconds, so it equals 0.229*1000=229 milliseconds.
IOPS (Input/Output operations per second) is a performance metric for the disks that measures the total input and output operations performed by the disk in one second.
- Disk Reads/sec counter indicates write IOPS
- Disk Writes/sec counter indicates read IOPS
- Disk Transfers/sec counter indicates the total number of the IOPS this value equals to summing Disk Reads/sec and Disk Writes/sec counters
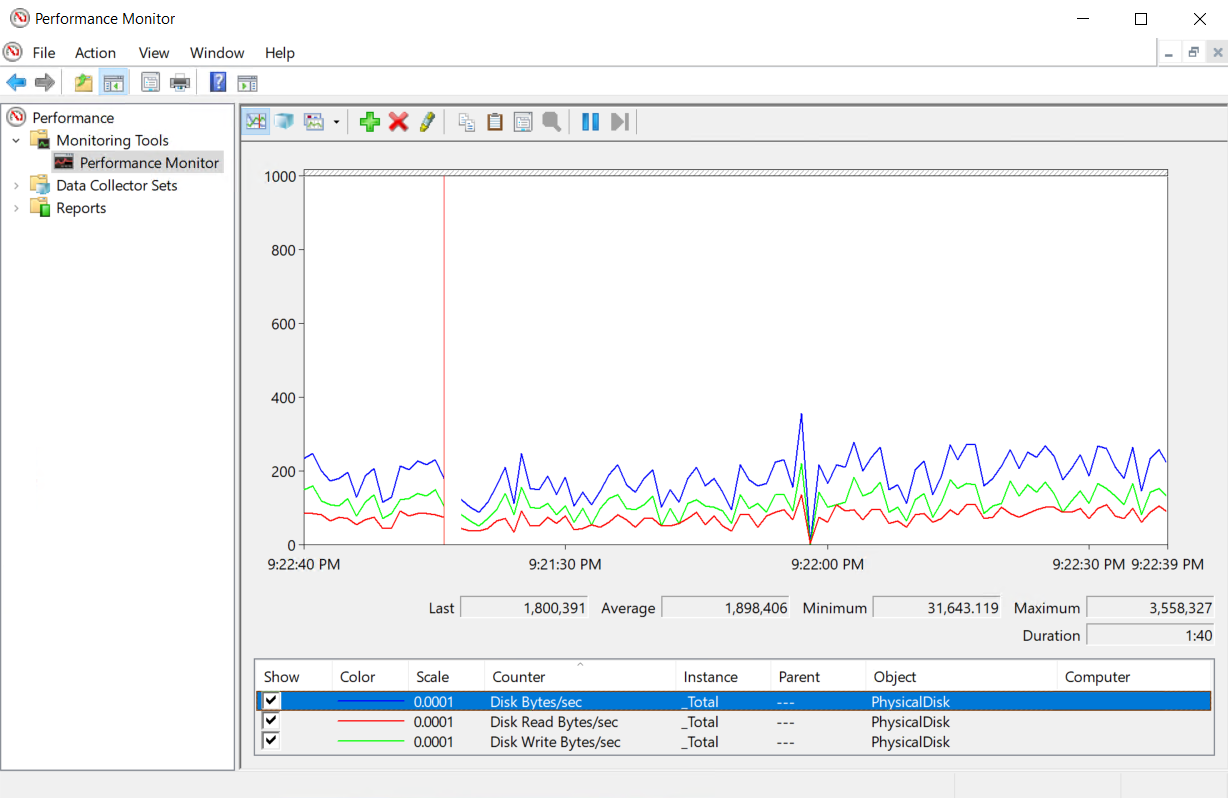
The throughput metric indicates how much MB can be read or written by the disk subsystems per second. The throughput value will be changed according to our disk infrastructure, types, and vendors. For this reason, the exact value could not be given for this counter.
- Disk Bytes/sec counter shows the total throughput of the disk per second
- Disk Read Bytes/sec counter shows the read throughput
- Disk Write Bytes/sec counter shows the read throughput
Conclusion
In this article, we learned the basic methods that help to diagnose and troubleshoot SQL Server I/O problems. To overcome this type of problem, we need to observe all metrics that can be helped to figure out the main problem. Understanding the main problem is a very significant point for the SQL Server troubleshooting.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023