
It has been a while since the last transaction log article has been published, so I hope you do remember where this series is heading to. In the former posts, we have examined the Log Structure and Write-Ahead Algorithm (part 1) and the Top Reasons for Log Performance Problems (part 2). Taking into consideration this knowledge, we will review some best-practices for transaction log configuration in order to decrease the chance of experiencing log bottlenecks.
Initial Size
As a first and very important step, the transaction log file must be created with a rational initial size. This will help you to avoid to frequent automatic growths which might lead to a delay in your queries and large number of VLFs.
Well this sounds intuitive but it is not easy at all. Good capacity planning is required for the sake of being as precise as possible in your estimations. If you fail badly in this task you could end up with an earnestly undersized or oversized log with detrimental effect on your SQL Server. I have seen, on many occasions that DBAs are now pre-allocating their log files using some generally accepted numbers – log size is set to 10 – 30 % from the size of the data, for example. On one hand, this could work fine for the majority of the databases but on the other hand, with the contemporary requirements for instantaneous data access, a more customized approach should be used.
The following factors have the biggest impact on the size of the transaction log:
- Type and frequency of the activities – the more frequent the insert, update and delete statements are, the more rapidly the log will grow
- Frequency of the log backups (if the database is not in Simple recovery model) – large databases with very frequent log backups might need very small transaction log
- Recovery model of the database
- High Availability solution used
After you have taken all of the above aspects into consideration, you should have a rough estimation of the transaction log’s size. The next step is to set this size and closely monitor how your database is handling the workload coming against it. Unless you have a suitable pre-production SQL where you can test whether your calculations are good enough, you are directly configuring the estimated size in the real, utilized environment. The easiest way to keep an eye on your log is to use the related performance counters exposed from SQL Server. This can be achieved with a similar query:
|
1 2 3 4 5 |
select * from sys.dm_os_performance_counters where counter_name in ('Log Growths','Log Shrinks','Percent Log Used','Log Flush Waits/sec','Log Bytes Flushed/sec','Log Flushes/sec','Log Truncations') and instance_name='your_database' |
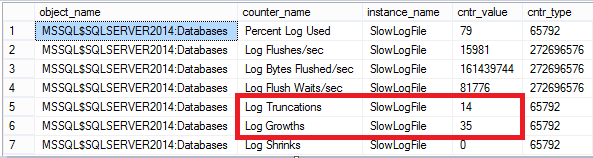
Probably the most important numbers here are the “Log Truncations” and “Log Growths”. In the perfect situation you should not be seeing any “Log Growths” and the “Log Truncations” should be increasing frequently. If your log is not getting truncated properly, you can check what is preventing this:
|
1 2 3 4 5 6 |
SELECT [log_reuse_wait_desc] FROM sys.databases WHERE [name] = N'your_database' GO |
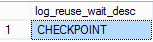
Depending on the result, you have to re-assess the situation and choose what your next steps will be: you might need to change the recovery model of your database, the frequency of the log backups or the size of the transaction log.
Too Many VLFs
As we have already covered this in part 1, the transaction log is split into portions called Virtual Log Files (VLFs).
The calculation is taking place whenever you are creating or extending your log file regardless this being performed manually or automatically. Here is the formula which is currently being used:
Under 1 MB – 2 new VLFs (roughly 1/2 of the new size each)
Above 1 MB and under or equal to 64 MB – 4 new VLFs (roughly 1/4 of the new size each)
Above 64 MB and under or equal to 1 GB – 8 new VLFs (roughly 1/8 of the new size each)
Above 1 GB – 16 new VLFs (roughly 1/16 of the new size each)
This is important to be considered as too many VLFs can lead to:
- Long recovery time when SQL is starting up
- Long time for a restore of a database to complete
- Attaching a database runs too slow
- Timeout errors when trying to create a new mirroring session
TempDB Log
The log of the “tempdb” database is behaving like the logs of any other databases in terms of growing. However it has a very nasty glitch: when a SQL Server is being restarted, the log of the “tempdb” is reverted to the size it has been most recently set to. If the log has grown to endure the regular utilization, it will most probably need to grow again (this might happen many times) which can lead to performance problems.
Let’s perform a small test.
Check the current size of the “tempdb” files and make sure you have an autogrowth enabled:

Run this script to expand it:
12345678910111213141516171819create table #x (col1 int, col2 char(5000) not null)godeclare @x intset @x = 0while (@x < 10000)begininsert into #x values (@x, '1')set @x = @x + 1endgobegin tranupdate #x set col2 = '0' where col1 = 1gorollback trangoCheck the size again:
Restart you SQL Server and see what is the situation with “tempdb”:
- How to perform backup and restore operations on SQL Server stretch databases - September 7, 2016
- SQL Server stretch databases – Moving your “cold” data to the Cloud - August 18, 2016
- Tips and tricks for SQL Server database maintenance optimization - January 11, 2016



The funny thing is that the data and log file have been reverted to their size before they have grown to accommodate our query. Be careful with this behavior!
Regular File Shrinking
I keep seeing SQLs with a regular log shrinking configured. In general, log shrinking is not as bad as data file shrinking but this means that your log had grown at a specific previous moment and in this case it is very likely that it will happen again if you decrease its size via the shrink operation. If this occurs, your transactions will wait while the new space is being zero-initialized and you need to prevent this. Large transaction log file is not problematic, of course if you have enough space on the drive, so you can just accept the new size as the normal one and disable these shrink operations.
Multiple Log Files
SQL performance is not benefiting at all from multiple log files. It may be necessary to add an additional log file, if you do not have space on the drive where the original log is located. You have to use this option as a last resort and also plan to remove this additional file as soon as possible! Additional log files are affecting the disaster recovery and can significantly increase the time to bring your database online again. Imagine that you need to restore your database from scratch: the first, in this case, would be the creation of the files (data and log) and this can possibly run forever if you have several, large log files due to the zero-initialization.
Reverting from Database Snapshot
Next thing on the list is another bug in SQL that might have consequences in critical production environment. The opportunity to revert your database from a snapshot, which can save the day for you as it is very fast, has one great drawback: the transaction log of your database will be recreated with the VLFs (0.25 MB each):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
--create a small test database CREATE DATABASE [Snapshot_Restore] ON PRIMARY ( NAME = N'Snapshot_restore', FILENAME = N'D:\Snapshot_Restore.mdf' , SIZE = 77MB , FILEGROWTH = 1024KB ) LOG ON ( NAME = N'Snapshot_restore_log', FILENAME = N'D:\Snapshot_restore_log.ldf' , SIZE = 20MB , FILEGROWTH = 30%) GO --create a snapshot CREATE DATABASE Snapshot_Restore_now ON ( NAME = Snapshot_Restore, FILENAME = 'D:\Snapshot_Restore_now.ss' ) AS SNAPSHOT OF Snapshot_Restore GO --revert from snapshot USE master GO RESTORE DATABASE Snapshot_Restore from DATABASE_SNAPSHOT = 'Snapshot_Restore_now' GO --check the log USE Snapshot_Restore GO DBCC loginfo |

Now we need to grow our log again to the previous size – it is not that problematic when we are aware of this behavior and definitely the fast revert that we can do is outweighing the discomfort of the need to expand the transaction log again. However if we miss to do it or we are simply not familiar with this insidious SQL behavior, our queries would potentially be experiencing slowness due to the many upcoming log autogrowth events.
Physical Location
Something that is fairly easy and intuitive but it is included for completeness. The importance of the logs’ location should not be underestimated. Always place your transaction logs on a separated, dedicated drive. This will allow you to separate the random operations (data files) from the sequential writes (log files).
This concludes the SQL Server Transaction Log series – one of the most critical and in the same time misunderstood part of our database. I hope everyone can find something useful that will be brought into play 🙂

In the last years, he is working on a great variety of customers' environments and involved in complex transitions and transformation projects.
Miroslav is also leading courses at Sofia University and participated as a speaker at various events.
View all posts by Miroslav Dimitrov