
SQL Server transaction log is one of the most critical and in the same time one of the most misinterpreted part. While being neglected, it can easily become a bottleneck to our SQL Server environment. We need to have this in mind and to take care of our transaction logs in order to streamline the performance of our queries and increase log’s throughput.
This sounds great but it is not as straightforward as it looks! In order to make our life easier and not to worry about the transaction logs, we should be aware what actually stands behind these *.ldf files sitting somewhere across our file system and how they are logging the information.
Log Structure
Every SQL database has a transaction log which maps over one or more physical files. The Database Engine divides each file into a specific number of virtual log files (VLFs) that are being used to hold the information about everything happening inside our databases. This number of VLFs is not some kind of magic but it is being chosen dynamically. The calculation is taking place whenever you are creating or extending your log file regardless this being performed manually or automatically. Here is the formula which is currently being used:
Under 1 MB – 2 new VLFs (roughly 1/2 of the new size each)
Above 1 MB and under or equal to 64 MB – 4 new VLFs (roughly 1/4 of the new size each)
Above 64 MB and under or equal to 1 GB – 8 new VLFs (roughly 1/8 of the new size each)
Above 1 GB – 16 new VLFs (roughly 1/16 of the new size each)
You can check how many VLFs and what their size is by using the undocumented “DBCC LOGINFO” command. Note that the size of the log file will be roughly the same but not exactly. Let’s create a simple database with this script:
|
1 2 3 4 5 6 7 8 9 10 |
USE [master] GO CREATE DATABASE [myTestVLF] ON PRIMARY ( NAME = N'myTestVLF', FILENAME = N'C:\myTestVLF.mdf' ,SIZE = 80 MB) LOG ON ( NAME = N'myTestVLF_log', FILENAME = N'C:\myTestVLF_log.ldf' ,SIZE = 300 MB) GO |
We can now use the DBCC command to check the result:
|
1 2 3 4 5 6 |
USE myTestVLF; GO DBCC LOGINFO; GO |
In the picture below we can see that the last VLF has a size that slightly differs from the others:
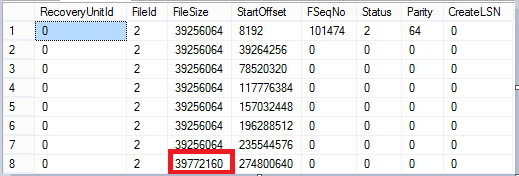
The transaction log file is with wrap-around nature. This means that whenever we reach the end of the file, the engine will try to reuse the first VLF. If this is not possible and an autogrowth is enabled, SQL Server will make an attempt to grow it:

Log Blocks
The next physical layer of the transaction log is the log blocks. Virtual Log Files are divided into blocks which are between 512 bytes and 60 kilobytes large. These are respectively the smallest and largest amount of data that can be flushed to disk. Log Blocks are acting as containers for the log records.
Log Records
In SQL Server, we have almost every operation logged somehow. This includes actions like data modifications (insert, update, and delete), page allocation or deallocation, the start and end of a transaction and etc. The database engine is recording the changes happening in it by generating log records. Each log record is identified by a unique number called LSN – Log Sequence Number. The LSN number is ever increasing so the next log record will always have a higher LSN than the previous one. This LSN is 10 bytes in length and it is consisting of three parts: VLF Sequence Number (4 bytes): Log Block Number (4 bytes): Log Record Number (2 bytes):
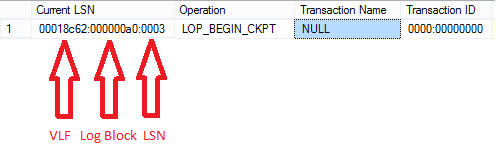
Log records are not always part of a transaction. We have specific LSNs like PFS free space change and Differential Bitmap changes that are not part of a transaction
Transactions are reflected into the log as a chain of log records. Furthermore records are stored in a serial sequence as they are created so the LSNs that are part of the same transaction are not necessarily located next to each other. Each transaction has an ID that is pointed in every log record. SQL Server is using this to create a chain using backward pointers in order to track all the LSNs that are part of a specific transaction and speed up the rollback process.
We can examine the log records by using the table-valued function “fn_dblog”. This is not in the scope of this article but if you are that curious you can check the documentation using sp_help:
|
1 |
sp_help 'sys.fn_dblog' |
Write-Ahead Logging (WAL)
Like the others contemporary Relational Database Management System, SQL Server needs to guarantee the durability of your transactions (once you commit your data it is there even in the event of power loss) and the ability to roll back the data changed from uncommitted transactions. The mechanism that is being utilized is called Write-Ahead Logging (WAL). It simply means that SQL Server needs to write the log records associated with a particular modification before it writes the page to the disk regardless if this happening due to a Checkpoint process or as part of Lazy Writer activity. It sounds natural but how is this affecting the logging operations in SQL?
There is a common misunderstanding of when the log records are being flushed to disk. The general understanding is that log records, the information about the modification we are doing in our databases, are being sent to the disk immediately and they are hardened to the log. Well this is not true! While we are making changes to our data, SQL is generating log records about every change. They are being stored in Log Blocks which are part of the Buffer Pool (grey areas are data pages):
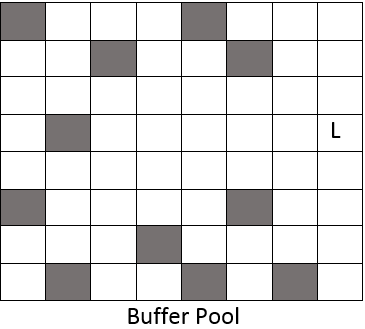
So the first step is to store the Log records in the Buffer Pool and then they are being flushed to disk in one of the following situations:
- When we commit/rollback a transaction
- When a log block hits its maximum size of 60 KB
- When a data page is being written to disk – all the log records up to including the last one affecting this page must be written to disk regardless of which transactions they are part of
I guess the last case is bringing up the following question (in case this is due to checkpoint): Why we are simply not flushing all the records when the checkpoint begins? The checkpoint operation might take a while and there could be modified pages after it was fired that could eventually be written to the file system before the log records. If this happens, we will not adhere to the WAL algorithm and SQL might not be able to roll back the changes performed by specific transactions.
The understanding of the Log Structure, a number of VLFs we have and WAL is essential to our work and can dramatically improve our effectiveness as SQL Server engineers. A journey is ahead of us through the top reasons for performance problems with the transaction log. Stay tuned!

In the last years, he is working on a great variety of customers' environments and involved in complex transitions and transformation projects.
Miroslav is also leading courses at Sofia University and participated as a speaker at various events.
View all posts by Miroslav Dimitrov
- How to perform backup and restore operations on SQL Server stretch databases - September 7, 2016
- SQL Server stretch databases – Moving your “cold” data to the Cloud - August 18, 2016
- Tips and tricks for SQL Server database maintenance optimization - January 11, 2016