
A database
A SQL Server database can be thought of, in and of itself, as a data dictionary. It is self-describing, in that objects can be scripted into Data Definition Language aka DDL scripts to view all attributes, quickly and easily.

SQL Server has functions like sp_helptext to further help describe database objects as well as system views to present views of the database and object collections in a variety of ways. The self-describing nature of a database can be enhanced with Extended properties, which allow user defined descriptions to be attributed to objects at various levels in the database.
Advantage:
- Nothing has to be done to take advantage of the self-describing properties of a database. You get all of this out-of-the-box
Disadvantage:
- Not in a format that can be easily read, viewed by non-database professionals. Requires knowledge of SQL, functions, system views etc.
- Is only a snapshot in time, contains no historical information, changes or context.
Database documentation
Documentation can be referred as a single instance, or snapshot, the database rendered in an easily readable, user friendly format like HTML or compiled HTML (e.g. chm) that any user can view, even without database experience.
Disadvantages:
- Is only a snapshot in time, contains no historical information, changes or context.
- Requires additional software or programming skills to extract the data and turn it into information, the documentation
- Impossible to query and report on directly as it is information rendered for humans, not computers
- The large file size makes it time-consuming to create and voluminous to archive
Advantages
- Easy to read and understand by anyone, regardless of skill or experience
- Certain advantageous features of the database itself, like Extended properties and can be directly leveraged in the documentation
- Portable; documentation can be emailed, FTP, printed or otherwise distributed
Click here to learn more about SQL Server database documentation.
Database version control
A database, itself, and database documentation are great, but they are one dimensional snapshots in time. Neither can provide the context of changes or history. Version (or source) control provides a solution for that in that all objects can be versioned over time, allowing a user to browse any version of an object or even the entire database in time
Additionally, version control allows users to revert to any previous object version or the entire database itself
Disadvantages:
- Requires source control software for repository like Git or Subversion
- Requires setup time and configuration both for the repository and to get the data loaded into the repository
- Impossible to query and report on directly
Advantages:
- Full version control and history of all versioned objects with all of the features offered from popular source control systems like labels and version history.
- Portable in that documentation can be emailed, FTP, printed or otherwise distributed
- Immutable, once created, at least in formats like PDF and CHM, the documentation can’t be changed, which is helpful for auditing purposes
- Allows for iterative checking in and checking out of objects, so that a source control archive isn’t just a collection of snapshots but a close-to-real-time rendering of the database status
- Comments can be associated with changes to provide additional context
Click here to learn more about SQL Server source control.
A Data Dictionary
A data dictionary combines elements of the database, as
- it is itself (usually) stored in the database,
- and documentation, as it attempts to render the information is a view that is easier to consume, query and view,
- but also version control, as it stores versioned snapshot of the database schema.
But since a database dictionary exists, itself, in a database, unlike version control, it lends itself to being easily queried and reported against
Disadvantages:
- Requires initial setup and creation of a job to periodically load the data dictionary with information
- Not portable, like documentation. Information must be queried to be viewed
Advantages:
- Full version control and history of all versioned objects
- Although not immutable, can be made tamper resistant with security, permissions etc.
- Leverages the power of an RDBMs with querying, filtering, sorting, grouping etc.
- Efficient storage of information with easy retrieval, backup etc.
- Can be used as a basis to easily create reports with a variety of technologies like SSRS
- Would be faster to update than documentation
What exactly is a data dictionary?
A simple data dictionary is a repository of information about the database, usually in a database itself, that stores object information and attributes, versioned over time.
A data dictionary can contain the following information about a particular object:
- Datetime the current object was created or changed
- Object name
- Object owner
- User who created or update the object
- Data definition language script
- List of data element (column) names and details
- Key order for all the elements (which can be possible keys)
- Information about indexes and other attributes
- Relationships
- Changes
- Extended properties
“Dumb” vs “Smart” data dictionaries
Dumb dictionaries are repository of schema snapshots, regardless of what if any data changed. Such dumb dictionaries can be created by simply scripting the schema to a table nightly.
This raw data provides a true representation of the database state but since most of the records are duplicates, versions of the same unchanged objects, much of the value of a data dictionary can’t be unlocked. A version history could be easily created from a dumb dictionary, but most of the “versions” would be duplicates. As most of the objects are static versions of what existed, vs what changed, it wouldn’t be possible to query the data for information about change transactions like the number of objects a user changed each month
“Smart” data dictionaries start with a baseline and write only data that has changed. This allows users querying the data to mine real information, knowing that each new version of an object, represents an actual change. In this way, a version history of an object would show only versions that actually changed, making this feature as powerful as version history in source control.
Knowing that each object record reflected an actual change, we can layer on lots of value added reports that instantly tell the transactional history of the database e.g. changes per day/month/year, changes by user, the object with the most changes etc.
By unlocking the potential to see a true object change history and isolate specific changes without having to sort through duplicates, coupled with the ability to run investigative queries, would transform even the simplest “smart” data dictionary into a powerful tool for forensic auditing and even recovery, as any changes could be easily reverted to a previous version
Uses
The primary purpose of a data dictionary is to be an auditing archive of changes that is easy to query and report on. Large amounts of data can be stored efficiently leveraging the power of a RDBMS. Data can be easily filtered, extracted, sorted and grouped into meaningful reports.
A data dictionary provides information that can easily be converted into other views. For example, you could query your data dictionary to see the full history of changes for a particular object
A data dictionary can be used for version control and auditing purposes, even without using a source control repository, clients or having developers even know changes were being logged. In this way, setting up such a “poor man’s” version control system is a straightforward task of creating the data dictionary
Data dictionaries provide a great medium for transactional and aggregate reporting. Since the data dictionary is a repository of all changes, it can be used to create reports to track the count of transactions over time, by user, by object and produce a series of reports, that provide great insight into the transactional changes of a database over time, like shown below:
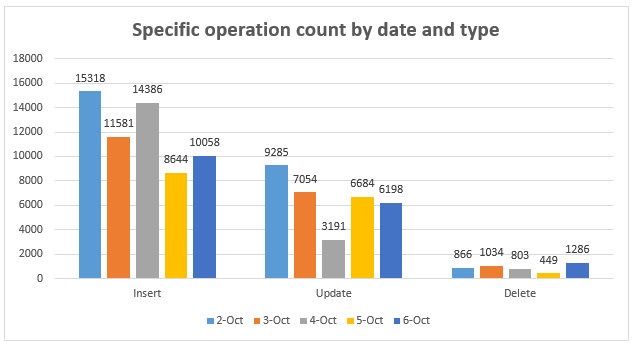
Examples of reports include:
- Total transactions – Count of changes by hour/day/week/month/year
- Total transactions by type – Count of changes by hour/day/week/month/year by Type e.g., Update, Insert, Delete
- Busiest day – Top days of the week by the most changes
- Most productive developer report – top users by the most changes
- Most dynamic object report – top objects by the most changes
- etc.
In the next part of this series, How to build a “smart” SQL Server Data dictionary, I’ll explore How to create a Smart SQL Server data dictionary and in the final article in the series, I’ll explore how to leverage it to its full advantage for object history and change auditing as well as transactional reporting. Stay tuned!

Alen is currently working for ApexSQL LLC as a Software Sales Engineer where he specializes in SQL and BI documentation and database Analysis.
View all posts by Alen Gubicak
- What is a SQL Server Data Dictionary and why would I want to create one? - December 26, 2016
- How to configure reporting services (SSRS) for Native mode - September 21, 2016