
Introduction
In our previous article on the introduction to SQL Server business intelligence we covered the general structure of an enterprise business intelligence solution. The tools needed to build these solutions were briefly mentioned. The purpose of this article is to provide you with a deeper understanding into the creation of an ETL (Extract, Transform and Load) dataflow. To do this one needs to use SQL Server Data Tools – Business Intelligence (previously known as BIDS or Business Intelligence Development Studio). In this article we’ll take a look at the basic functionality of SQL Server Data Tools and how to use it to keep your data warehouse up to date. It’s worth noting that there are many different ways to go about building your ETL solution. This article gives sound advice and pointers as to how to approach the problem.Feeding the Data Warehouse
This article presumes that you have already created a de-normalized data warehouse. If you need more information as to how to create a star-schema based database you can read more here
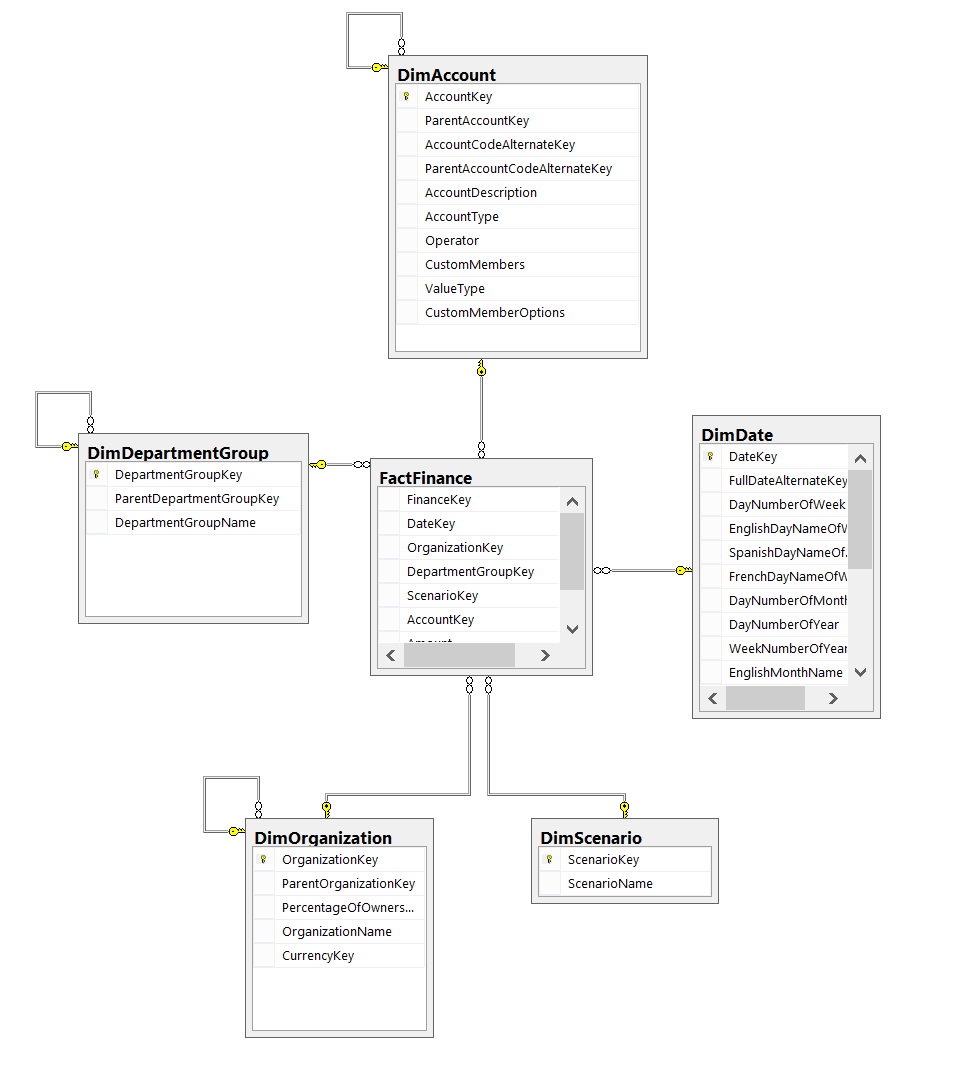
Once you have created a de-normalized database model for your data warehouse you will need to fill it with data and schedule regular updates to keep your SQL Server business intelligence data up to date. Depending on your version of SQL Server you will be able to do this with either BIDS or SQL Server Data Tools.
This program is an extremely handy ETL and automation tool. You can do anything from executing systems processes and PowerShell scripts, running raw T-SQL and custom C# scripts to sending e-mails or connecting to FTP servers or Web Services. However, the most commonly used tool is the Data Flow Task.
Keeping track of updates
A data warehouse does not need to be updated often. As the business intelligence is about analyzing historical data the data of the current day is not critically important. It is also obvious that one should not empty and refill a database every day. It is therefore necessary to keep a log table for the processing history of the data warehouse.
|
1 2 3 4 5 6 7 |
CREATE TABLE [dbo].[ProcessingLog]( [ProcessingLogID] [int] IDENTITY(1,1) NOT NULL, [ProcessingTime] [datetime] NOT NULL, [Object] [sysname] NULL ) |
Connection managers

Allowing for connections between one or many sources and/or one or many destinations, a connection manager is very often the starting point of an ETL package. There are ordinary database connections (ODBC, OLEDB, ADO.NET etc.), connections to HTTP, FTP and SMTP servers and connections to various file types like CSV, flat-file or even Excel. For a simple BI data flow however two OLE DB connections would suffice: one for the data warehouse and another for the OLTP/Production database. You can set them up in the following way.
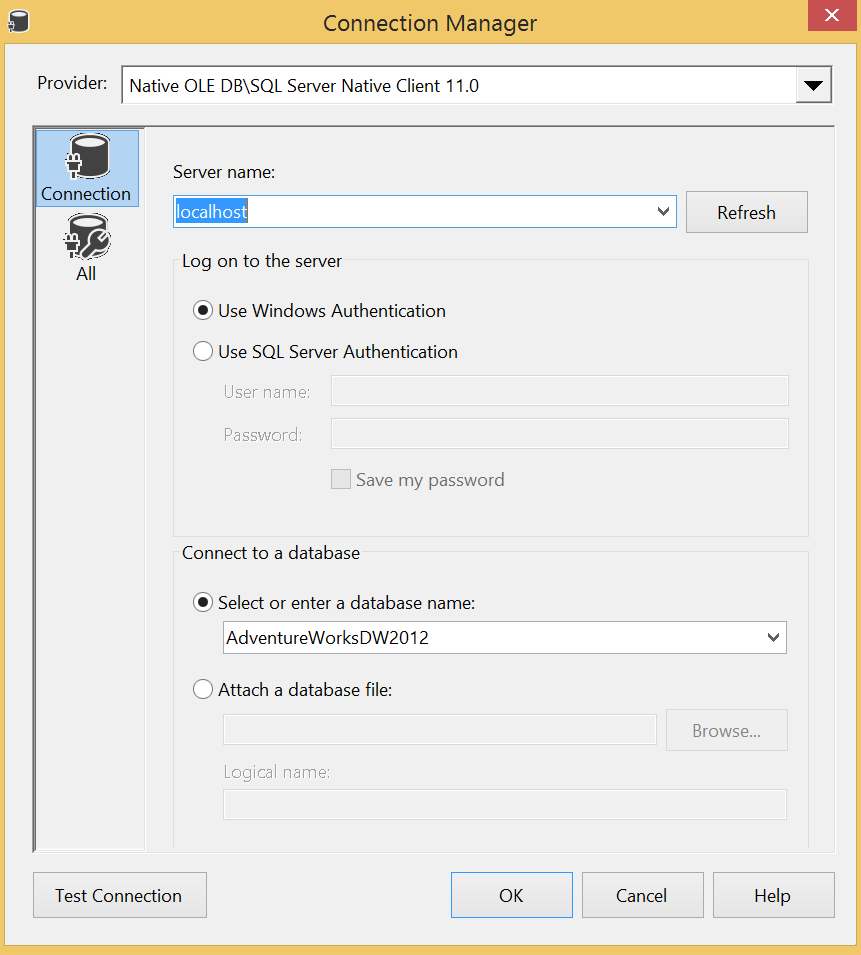
(Note that this connection is on the local machine and uses Windows Authentication. You can always connect directly to an instance in IP_ADDRESS\INSTANCE format and you may use SQL Server authentication if the instance does not support Active Directory accounts.)
Now that you have your connections you will need to make your first Data Flow Task.
The Data Flow Task

To describe this task very simply; it is a unit of work that links a data source with a destination and provides the possibility to transform the dataflow in a number of ways. Sorting, conversion, merging, counting aggregating are just some of the possible tools that can be used within the Data Flow Task.
For SQL Server business intelligence solutions it is usually about sourcing data from the OLTP database, converting it from its relational model and inserting it into the star or snowflake model of your data warehouse. A tidy approach, if you’re comfortable with writing T-SQL, is to write SELECT statements that could fill your destination fact and dimension tables based on your OLTP database tables and save them as views in the source database. This would allow you to have a direct mapping from an object in your OLTP database to an object in your data warehouse without having to create complex ETL packages.

For fact tables you will normally have date/time fields and you will be able to create a simple data flow from your data warehouse view in the OLTP database to the fact table in the data warehouse. You can do this by running an Execute SQL task just before your data task and mapping the result set to the a variable storing the last processing time for that table. You can use the following query for this
|
1 2 3 4 5 6 |
SELECT TOP 1 ProcessingTime FROM ProcessingLog WHERE object = 'YourFactTable' ORDER BY ProcessingTime DESC |
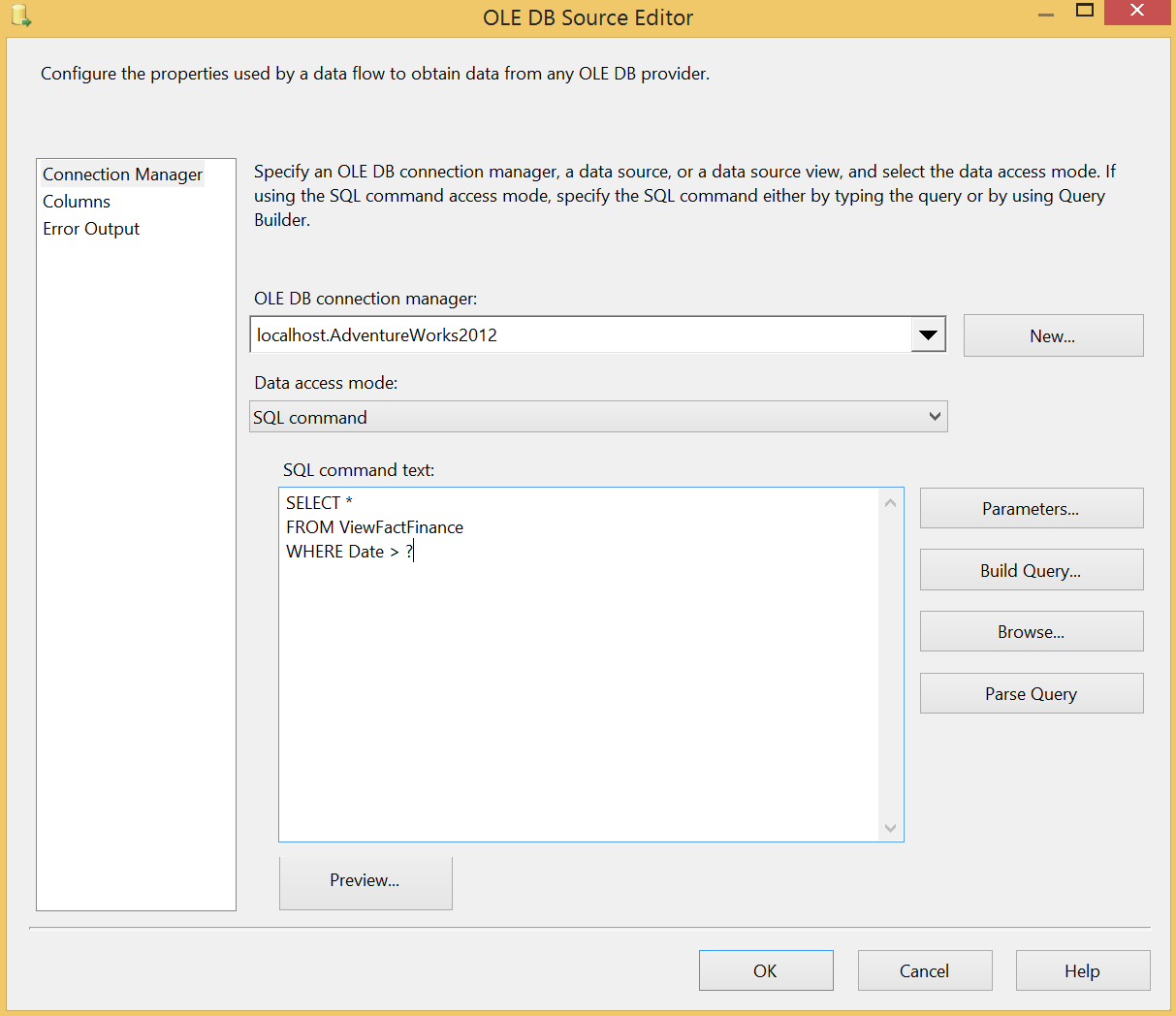
As you can see above you have added a “?” parameter to the source query. This allows you to add the last processed time to the query. You can do this by clicking on “Parameters…” and setting Parameter0 to you variable.
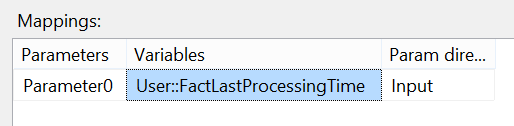
Once you have your source that pulls only the most recent data that is not in your data warehouse you can create your destination connection and map the fields to your fact table fields.
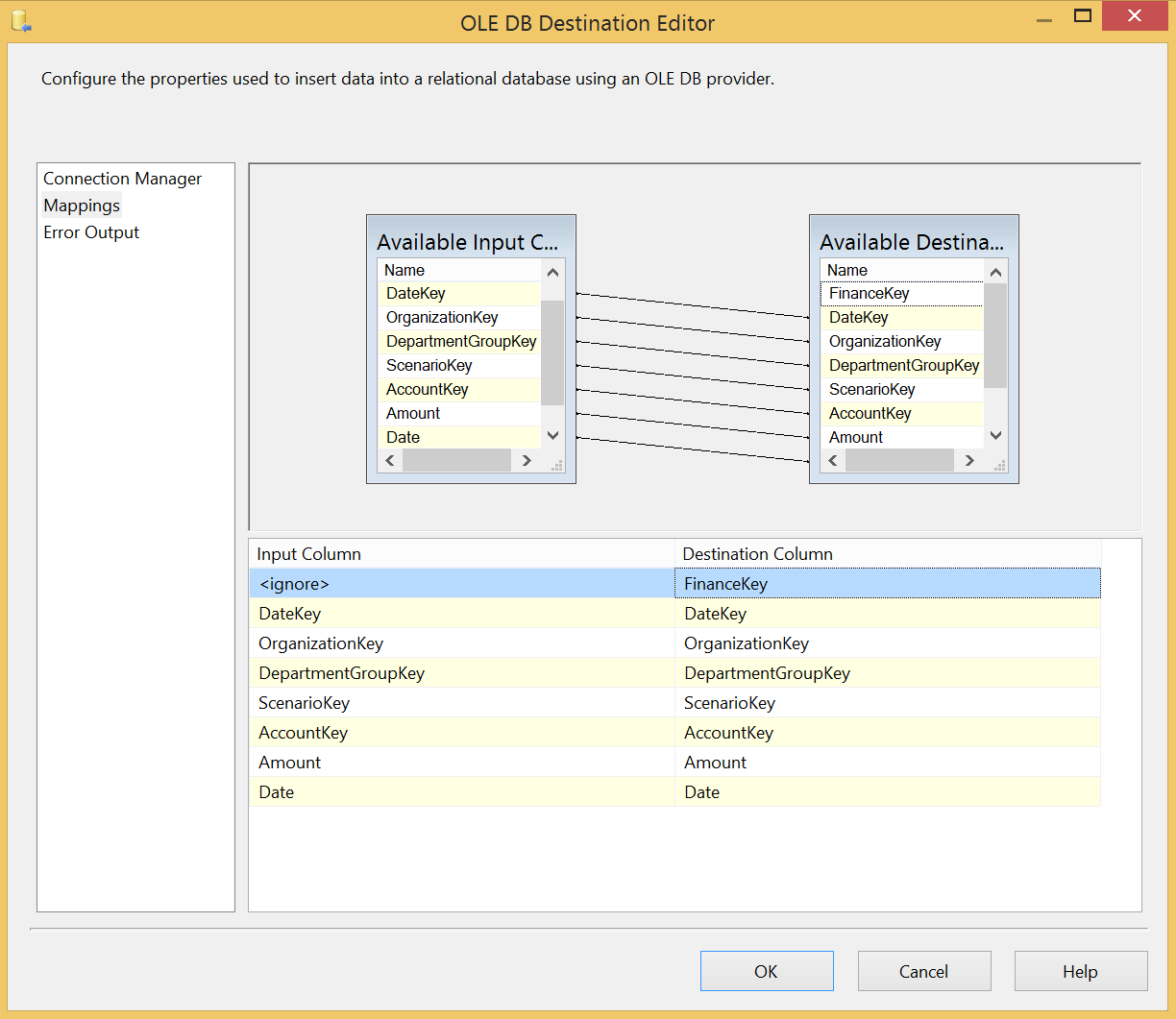
Once you have completed the data flow task you must add an Execute SQL task to update the log table to prepare for the next day’s ETL processing:
|
1 2 3 4 5 6 |
INSERT INTO [ProcessingLog] ([ProcessingTime], [Object]) SELECT GETDATE(), 'FactFinance' |
Dimension tables often have to be dealt with differently but two common options involve comparing the source and destination objects and transferring the difference. This can be down by using the Slowly Changing Dimension or an Execute SQL task and a MERGE statement if the two databases are in the same instance.
SQL Server agent
It may seem strange to mention the SQL Server agent when focusing on business intelligence, however, it is central to keeping the structure up to date. Once you have a functioning ETL package you need to automate it and run it regularly to make sure your data warehouse gets updated.
Where to from here?
Now that you have a running ETL solution that feeds your data warehouse with interesting, business intelligence data, you can take one of two routes. If, for any reason, you cannot use SSAS to build a multidimensional cube you can start building SSRS reports using SQL queries based directly on your new data warehouse system.
Resources
Designing the Star Schema Database
SQL Server Integration Services (SSIS) overview
Dimension Tables

View all posts by Evan Barke
- SQL Server Commands – Dynamic SQL - July 4, 2014
- SQL Server cursor performance problems - June 18, 2014
- SQL Server cursor tutorial - June 4, 2014