
Introduction
Most people that work with Microsoft SQL Server will have at least heard talk of cursors and often, even if people know on a basic level what SQL Server cursors do, they are not always certain when to use them and how to write the code behind them. So this article takes a step back and provides an explanation as to what SQL Server cursors can be used for as well as a basic example that you can run for yourself to test.Transactional versus Procedural Programming
SQL Server is a relational database management system (RDBMS), and T-SQL is a transactional programming language. This means that it is designed to execute its work in all-or-nothing runs. The database engine is optimized to work in this manner and, in general, it is more than sufficient to execute simple all-in-one type transactions.
Many other programming languages including C# and Visual Basic are iterative or procedural programming languages whereby the general flow of things is to treat each instance of an object separately and when dealing with many objects one would tend to loop over the same code until the stack is diminished and processed.
Cursors however, like WHILE loops, break away from the transactional nature of T-SQL and allow for programmers to treat each result of a SELECT statement in a certain way by looping through them.
In the IT Engineering world it is common place for people to learn languages like C#, VB, java, C++ or any other the other iterative-type languages before having to deal with SQL in any real/advanced way. It is for this reason, and sadly so, that SQL Server cursors are often very prolific in some applications. It is a common trap that developers fall into and for good reason. The logic behind cursors can be perfect and the idea of writing one can seem good but one runs into real problems when it comes to performance because SQL Server is no longer about to treat whole chunks of data at once and instead has to repeat reads and writes for each result (which can be catastrophic for I/O performance)
Therefore, as a general rule of thumb, and for good performance do not use cursors.
However, there are some situations in which cursors can be lifesavers. I can think of a couple right off the bat:
- Concurrent queries: Sometimes, in OLTP (OnLine Transaction Processing) systems, there are just too many users actively querying a specific table. This is OK for small transactions as they are lightning fast and do not require locks on large chunks of the underlying tables. But in order to be able to update the entire table SQL Server often has to create a huge lock that blocks all other activity on the same table. This is in order to protect data consistency. If it was not the case a concurrent use could come along and SELECT rows from the table that are half updated and half not updated. There are server level options to handle the type of read commitments, these are called transaction isolation levels and they are outside of the scope of this article. However, if one has a READ COMMITTED transaction isolation level which is the case by default, SQL Server cursors or while loops can be helpful to break full table updates into multiple smaller batches.
- The second case where cursors may be useful is to create a “for each” type logic in T-SQL scripts. For example, if one would like to handle the deployment of individual tables to another database one could use a cursor and sp_executeSql to run a chunk of T-SQL for each table in a give list.
In the example below we will loop through the contents of a table and select the description of each ID we find.
Take this simple table as an example:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE #ITEMS (ITEM_ID uniqueidentifier NOT NULL, ITEM_DESCRIPTION VARCHAR(250) NOT NULL) INSERT INTO #ITEMS VALUES (NEWID(), 'This is a wonderful car'), (NEWID(), 'This is a fast bike'), (NEWID(), 'This is a expensive aeroplane'), (NEWID(), 'This is a cheap bicycle'), (NEWID(), 'This is a dream holiday') |
Here are the results of a SELECT * FROM #ITEMS query:
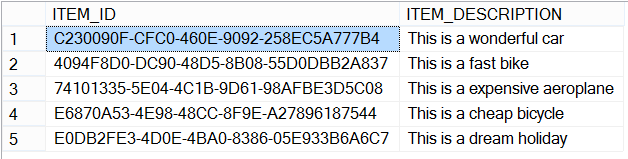
Now say we want to cut the selection of each description into 5 separate transactions. Here is the basic T-SQL cursor syntax to do that.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
DECLARE @ITEM_ID uniqueidentifier -- Here we create a variable that will contain the ID of each row. DECLARE ITEM_CURSOR CURSOR -- Here we prepare the cursor and give the select statement to iterate through FOR SELECT ITEM_ID FROM #ITEMS OPEN ITEM_CURSOR -- This charges the results to memory FETCH NEXT FROM ITEM_CURSOR INTO @ITEM_ID -- We fetch the first result WHILE @@FETCH_STATUS = 0 --If the fetch went well then we go for it BEGIN SELECT ITEM_DESCRIPTION -- Our select statement (here you can do whatever work you wish) FROM #ITEMS WHERE ITEM_ID = @ITEM_ID -- In regards to our latest fetched ID FETCH NEXT FROM ITEM_CURSOR INTO @ITEM_ID -- Once the work is done we fetch the next result END -- We arrive here when @@FETCH_STATUS shows there are no more results to treat CLOSE ITEM_CURSOR DEALLOCATE ITEM_CURSOR -- CLOSE and DEALLOCATE remove the data from memory and clean up the process |
Running the basic SQL Server cursor above will loop through each ID in the #ITEMS table and SELECT its corresponding ITEM_DESCRIPTION in 5 separate transactions. You should get the following results after executing the cursor:
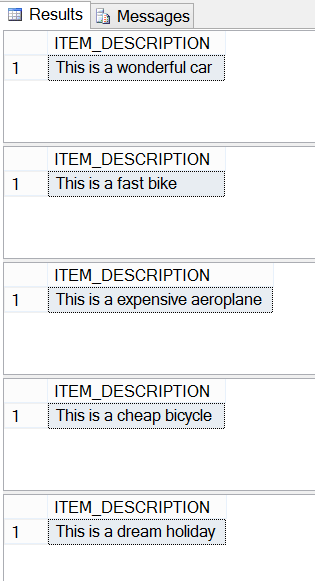
This example may see pointless but consider the fact that you can write any T-SQL you like in between
|
1 2 3 4 5 |
WHILE @@FETCH_STATUS = 0 BEGIN …and… FETCH NEXT FROM [CursorName] |
You can certainly imagine many possible usages.
Conclusion
This article is not meant to be used to proliferate the use of SQL Server cursors even more throughout your applications. As a general rule of thumb one should always think twice, even three times whether the use of a cursor is acceptable for their current problem. 99% of the time the same problem can be dealt with in a purely transactional manner, as is the norm in T-SQL. However, as mentioned above, there are certain exceptions to that rule when it becomes perfectly acceptable to sacrifice performance to avoid blocking the application or just because there is no other option (this is very rarely the case in IT)
So, if you have determined that you absolutely need to use a SQL Server cursor, go ahead and build on the example above.

View all posts by Evan Barke
- SQL Server Commands – Dynamic SQL - July 4, 2014
- SQL Server cursor performance problems - June 18, 2014
- SQL Server cursor tutorial - June 4, 2014