
Introduction
I work for a large, multinational financial institution. Like most companies in this field, ours is conservative and subject to much regulatory oversight. The first has meant that we’re slow to adopt new technologies. We need to be really, really, really sure things won’t break, customer accounts won’t vanish or lose their balances and that the regulators will not raise any red flags. Everything we do is subject to the scrutiny of our internal auditors, even something that seems simple, like rerunning a production job that failed because the host compute was down. I really mean everything!
As just one example of our conservatism, we just began rolling out SQL Server 2012 a year ago. That was in 2016 and just before SQL Server 2016 was RTM’d. What has this to do with table partitioning? Good question! Hang on just a bit while I fill in just a little more background.
Partitions and Indexes
The department where I work is concerned with computing risk and giving those results to internal managers to understand and cover that risk with appropriate investments (usually called hedge funds). That means we pull in very large amounts of data every day to understand things like outstanding mortgages, loans and credit cards, among many other things. To manage that data, we partition our tables by month. To satisfy the regulators, we have to save that data for up to seven years. (Thank you, Sarbanes Oxley!)
When we ETL data every day, we follow a pretty common practice:
- Disable the indexes on the target table (at least the non-clustered indexes, or NCIs)
- Insert the new data
- Rebuild the NCIs
Working this way is usually optimal, since SQL Server does not have to update the NCIs while the data is being imported. However, imagine that you have seven years of data. That means 7 * 12 = 94 partitions, of which only one partition is active. So, for us, that index rebuild would be almost 99% redundant! Fortunately, you can write:
|
1 2 3 |
ALTER INDEX ALL ON REPORTS REBUILD PARTITION = n |
For partition n. No more redundant index rebuilds! We’ll get into a real example in a moment, but first, what about those pesky auditors and regulators?
Keep those auditors and regulators happy!
I used to work for a company that employed some very smart accountants who devised a clever – and illegal – accounting practice that they used to provide inflated results. Good for the shareholders, for a while, until the SEC discovered the hack and sent those too-clever-by-half accountants up the river.
Given the scrutiny financial institutions are under, reporting correctly and maintaining the data to back up that reporting is critical. What has this to do with table partitioning? Simple, really. We need a way to ensure that partitions containing historical data – which we must retain for up to seven years – will not be changed inadvertently. The company is also responsible for criminal attempts to mess with the data.
There’s a mechanism built-in to SQL Server to satisfy even the most particular of auditors: Make the historical partitions read only.
Read Only Partitions
In actuality, you cannot make a partition read only. However, what you can do, is make the filegroup that contains the partition read only. It’s really very simple:
|
1 2 3 |
ALTER DATABASE database_name MODIFY FILEGROUP filegroup_name READ_ONLY |
Of course, there are a couple of big caveats here. First, you need to be sure that you really do not what to write to those partitions again. That’s really the point, actually. The whole strategy is useless if you need to continue to update the historical data (and what will you say to your auditors?)
Second, and this is really important to keep in mind, a filegroup is a database-level object. So, you are affecting all tables that reside in that filegroup. In our case, that’s fine, since the tables have the same type of monthly processing. Your mileage may vary.
Try it!
I’m not going to put a partitioning tutorial in this article. Milica Medic did an excellent job in a previous article on SQL Shack. (See the references section.) I’m simply going to leverage her examples to create a partitioned table on my test database.
To create my test database, I used the following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
CREATE DATABASE PartitioningDB ON PRIMARY (NAME = PartitioningDB, FILENAME = 'C:\SQLShack\PartitioningDB.mdf'), FILEGROUP January (NAME = January, FILENAME = 'C:\SQLShack\PartitioningDB_Jan.ndf'), FILEGROUP February (NAME = February, FILENAME = 'C:\SQLShack\PartitioningDB_Feb.ndf'), FILEGROUP March (NAME = March, FILENAME = 'C:\SQLShack\PartitioningDB_Mar.ndf'), FILEGROUP April (NAME = April, FILENAME = 'C:\SQLShack\PartitioningDB_Apr.ndf'), FILEGROUP May (NAME = May, FILENAME = 'C:\SQLShack\PartitioningDB_May.ndf'), FILEGROUP June (NAME = June, FILENAME = 'C:\SQLShack\PartitioningDB_Jun.ndf'), FILEGROUP July (NAME = July, FILENAME = 'C:\SQLShack\PartitioningDB_Jul.ndf'), FILEGROUP August (NAME = August, FILENAME = 'C:\SQLShack\PartitioningDB_Aug.ndf'), FILEGROUP September (NAME = September, FILENAME = 'C:\SQLShack\PartitioningDB_Sep.ndf'), FILEGROUP October (NAME = October, FILENAME = 'C:\SQLShack\PartitioningDB_Oct.ndf'), FILEGROUP November (NAME = November, FILENAME = 'C:\SQLShack\PartitioningDB_Nov.ndf'), FILEGROUP December (NAME = December, FILENAME = 'C:\SQLShack\PartitioningDB_Dec.ndf') LOG ON (NAME = PartitioningDB_Log, FILENAME = 'C:\SQLShack\PartitioningDB_.ldf') |
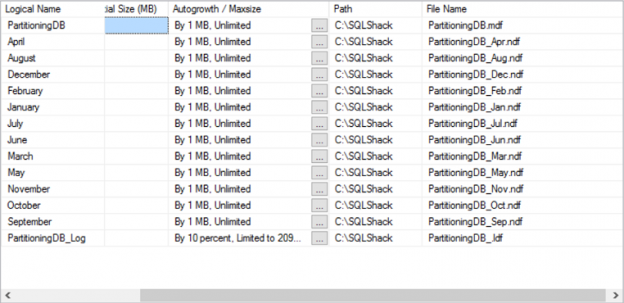
If I look at the files in SSMS for this database now, I see:
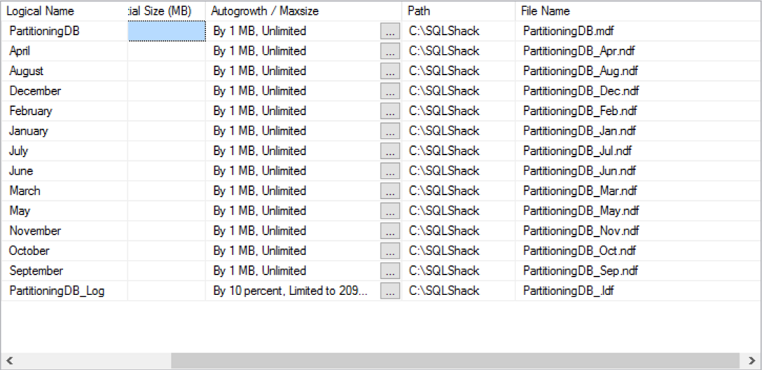
Using this database, I create a table:
|
1 2 3 4 5 6 7 |
CREATE TABLE Reports (ReportDate datetime CONSTRAINT PK_Reports_ReportDate PRIMARY KEY, MonthlyReport varchar(max)) ON PartitionBymonth (ReportDate); GO |
Now, I can do a standard index rebuild like this:
|
1 2 3 |
ALTER INDEX ALL ON REPORTS REBUILD |
To satisfy the auditors and regulators though, I need to mark the file group read only:
|
1 2 3 |
ALTER DATABASE PartitioningDB MODIFY FILEGROUP January READ_ONLY |
(January is behind us now.)
Now, what happens when I want to rebuild my indexes?
|
1 2 3 |
ALTER INDEX ALL ON REPORTS REBUILD |
Gives me:
Msg 1924, Level 16, State 2, Line 100
Filegroup ‘January’ is read-only.
Oops! Well, I wanted the read only filegroup, so now I have to rebuild my indexes specifically:
|
1 2 3 |
ALTER INDEX ALL ON REPORTS REBUILD PARTITION = 2 |
Unfortunately, I cannot say “REBUILD PARTITION = February” I have to use the partition number here. But that’s OK. Milica’s article, Database table partitioning in SQL Server, has a query that I can use to get the partition numbers:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT p.partition_number AS PartitionNumber, f.name AS PartitionFilegroup, p.rows AS NumberOfRows FROM sys.partitions p JOIN sys.destination_data_spaces dds ON p.partition_number = dds.destination_id JOIN sys.filegroups f ON dds.data_space_id = f.data_space_id WHERE OBJECT_NAME(OBJECT_ID) = 'Reports' |
Which gives me:
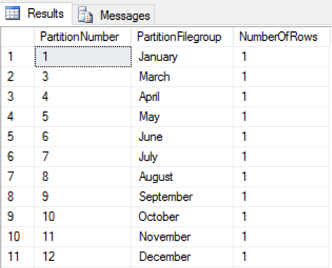
That tells me that February is partition number 2, so I can write:
|
1 2 3 |
ALTER INDEX ALL ON REPORTS REBUILD PARTITION = 2 |
Which gives me the reassuring result:
Command(s) completed successfully.
READ_ONLY is a SQL Server flag
You might think that making a filegroup read only would actually set the read only bit in the data file itself. I know I did the first time I did this. Here’s a screenshot from Explorer that proved me wrong:
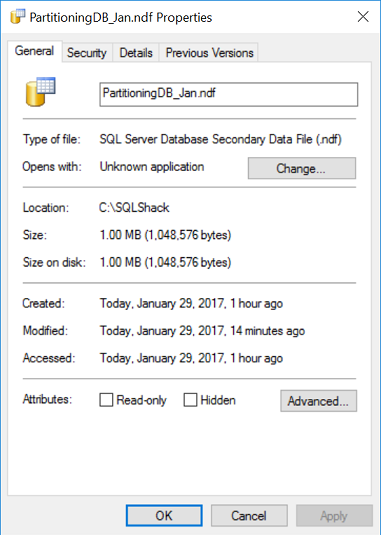
Even though I told SQL Server that January is now read only, the actual data file is still flagged read write. You can change that yourself if you like, just don’t expect SQL Server to do it for you!
Implementation Requirements
There’s no such thing as a free lunch, so let me be up front about the hoops you have to jump through to be able to use this strategy for rebuilding indexes in SQL Server.
When ALL is specified with partition number, this implies that the portion of the index that covers the rows in the partition must also reside in the same partition. Indexes like that are called aligned indexes. To create them you need to use the same partitioning function as for the rows covered by the index.
This is implicit in my example table, since the Primary Key is created with the table and is also a clustered index. Recall that a clustered index is the actual table itself, sorted according to the index order, with a B-tree built above it.
If, however, you are creating other indexes separately, you need to use the same partitioning function. So, say I wanted to add a non-clustered index on the MonthlyReport column. I need to remember to do it like this:
|
1 2 3 4 5 |
CREATE NONCLUSTERED INDEX IX_PK_Reports_MonthlyReport ON Reports(MonthlyReport) ON PartitionBymonth (ReportDate); GO |
Rebuilding Indexes Online
In a busy system, it can be a real drag if everything must stop while doing an index rebuild. That’s why SQL Server supports online index rebuilding. You simply add:
|
1 2 3 |
WITH (ONLINE = ON) |
to your index rebuild statement. Whether you really need it or not is another question. It depends on how your database is being used. In my case, I’m loading up a database for analysis, not real-time online queries during the ETL process. So, I’m perfectly happy to do my index rebuilding offline. I find that it is often a little faster that way.
For me (and other users of SQL Server 2012), there’s a second reason to rebuild indexes offline. You cannot use the ONLINE option when rebuilding by partition in SQL Server 2012. That’s a drag, though I can live with it – at least until we get to use SQL Server 2016, even if I have to wait until 2020!
Summary
I have two problems in my shop related to partitioned tables.
- I need to protect historical data for up to seven years.
- I need to have fast index rebuilding for daily ETL processing
I’ve been able to solve both by
- Marking filegroups containing historical data read only.
- Adding WITH PARTITION = n to my index rebuild statements.
Perhaps you can do the same.

Gerald specializes in solving SQL Server query performance problems especially as they relate to Business Intelligence solutions. He is also a co-author of the eBook "Getting Started With Python" and an avid Python developer, Teacher, and Pluralsight author.
You can find him on LinkedIn, on Twitter at twitter.com/GeraldBritton or @GeraldBritton, and on Pluralsight
View all posts by Gerald Britton
- Snapshot Isolation in SQL Server - August 5, 2019
- Shrinking your database using DBCC SHRINKFILE - August 16, 2018
- Partial stored procedures in SQL Server - June 8, 2018