
In this article, we will learn how to use the features of pgAdmin for tasks like schema comparison and schema management.
Introduction
A database management system hosts a variety of database objects. These database objects serve in different ways to process, host, and consume the data. While the nature, syntax, definition, operation, and different aspects of these database objects may differ, one common aspect between all these database objects is the schema. Every database object in any database management system has a schema related to it. When these database objects are promoted from one environment to another, they are often compared for the schema. With time, different database objects may evolve their schema, which is versioned and cataloged. During data migration, the schema is a very important factor to consider as the source and target databases may or may not support identical schema due to the difference in support for specific data types. In summary, schema comparison and schema management is important aspect of any database management system. Azure provides Azure Database for PostgreSQL as its Postgres offering on Azure cloud. pgAdmin is the most popular management toolkit for working with Azure Database for PostgreSQL instances. pgAdmin offers a reasonable level of features for schema management and comparison.
Using Schema Diff Tool in pgAdmin
Before we start with the actual exercise, certain pre-requisites are assumed to be in place. The first pre-requisite is an Azure Database for PostgreSQL instance set up on Azure account and the second is the pgAdmin tool already installed on the local machine and connected to the Azure instance. It is assumed that these are already set up and configured.
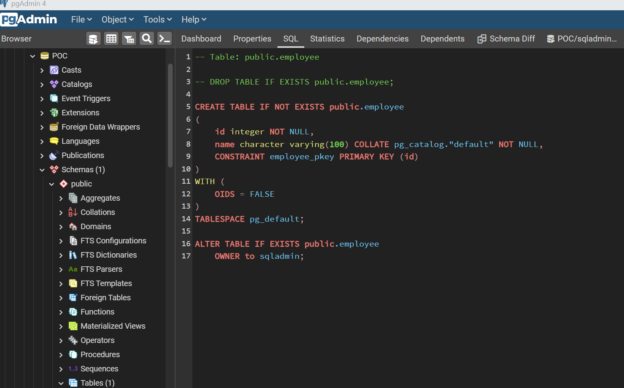
Now that we intend to explore features related to schema management, first, we need to create some schemas so that we can compare them with others. Let’s start with the creation of a few database objects of different types to populate our Azure Database for PostgreSQL instance with a variety of database objects. We can start with the creation of a domain object. Domains in Azure Database for PostgreSQL can be thought of as structures that can be used as a data type with fields definition in tables. Shown below is an example of a domain that validates the zip code by using a regular expression pattern. One can either use the code below and execute it directly in the query editor or use the wizard to create a new domain by right-clicking on the domain and selecting the menu option to create a new domain.
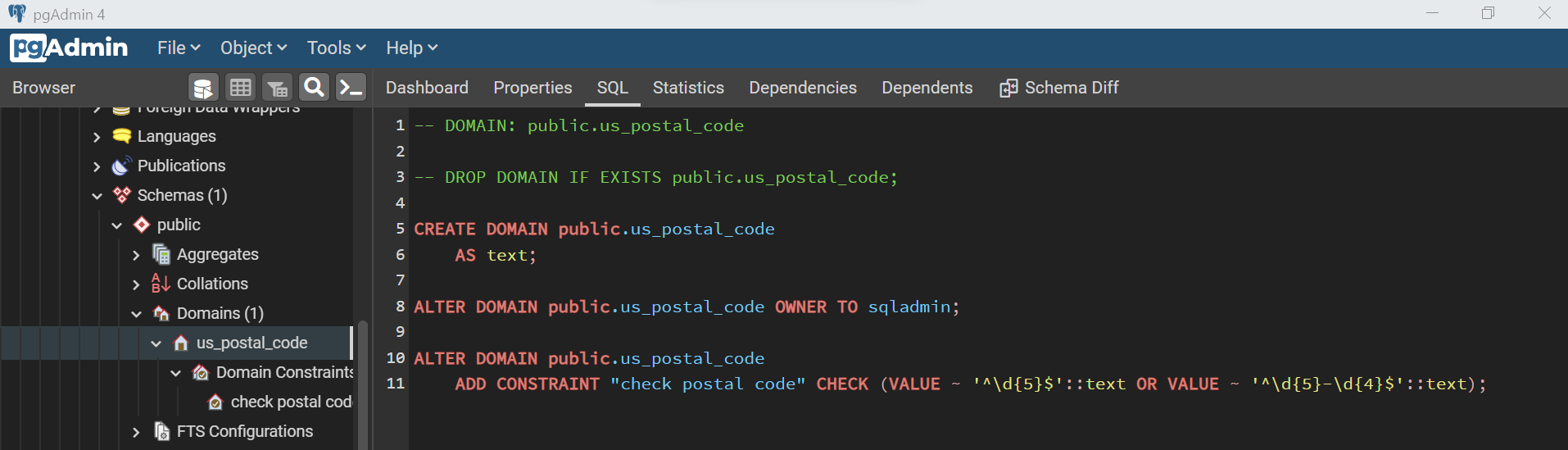
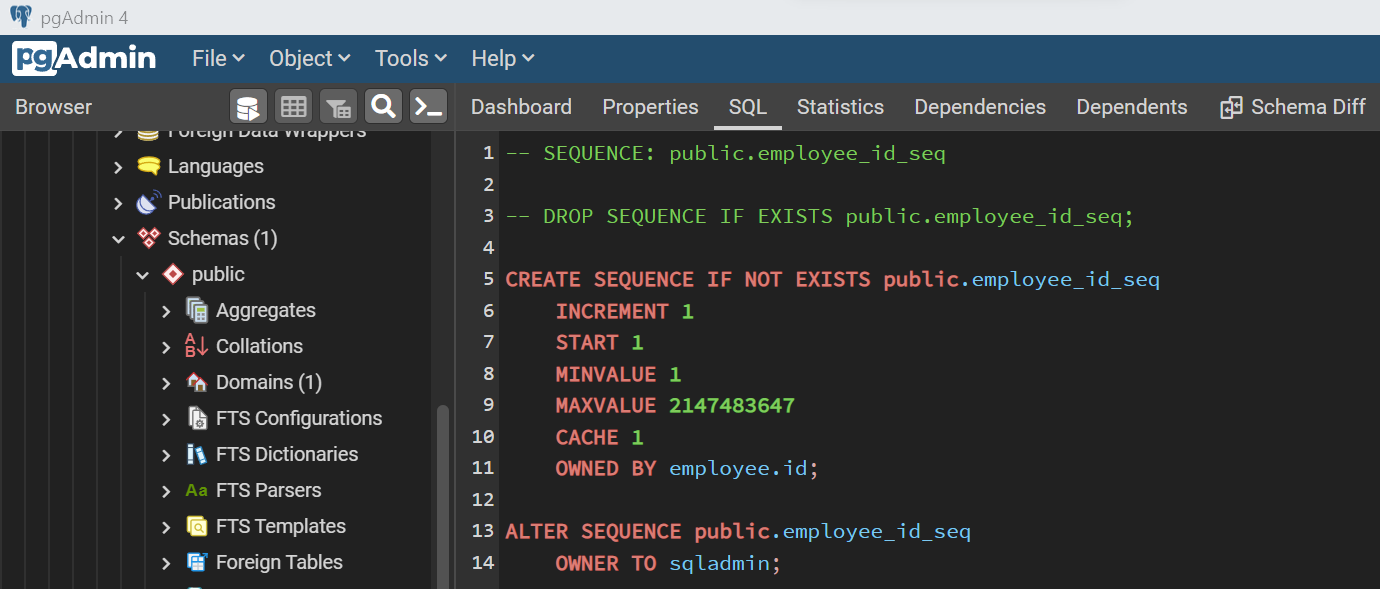
Let’s create a sequence now. A sequence in Azure Database for PostgreSQL is a database object that manages the order in which numeric sequences should be generated. This sequence is used to auto-incrementing values in fields that need this functionality. Shown below is a simple example of a sequence that starts the sequence with one and increments the value by one.
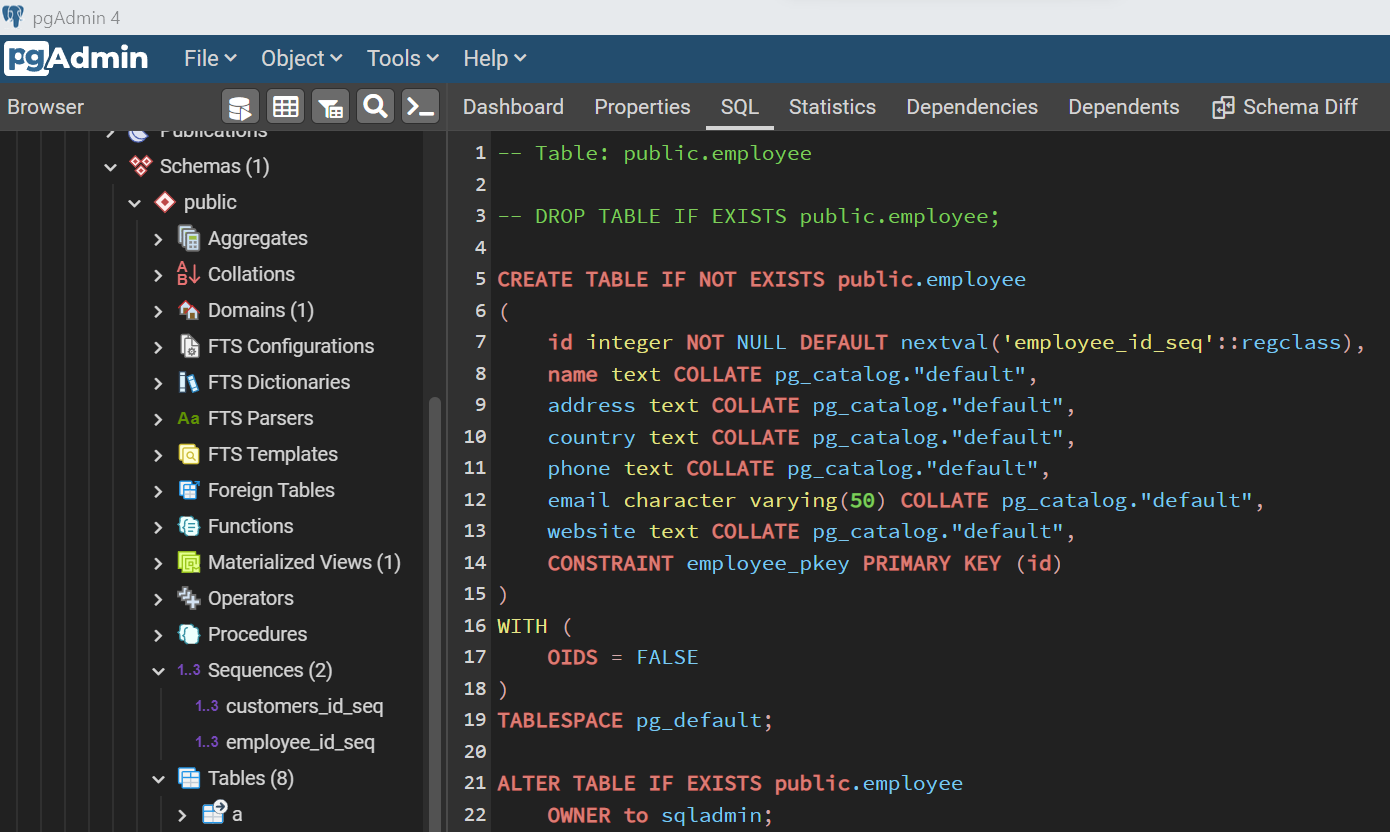
Now that we have some database objects that complement the field definition while creating tables or views, now it’s time to create a table itself. We will create a table now which uses the sequence database object that we created earlier. The intention behind creating objects in this manner is to add variety and interdependency among database objects which are typically found in production environments. Shown below is an example of a table that uses a sequence, with few fields and a primary key constraint. We do not need to have an identical schema as shown below. This is just for demonstration purposes; one can use any table schema desired.
Typically, tables are not directly exposed for consumption in production environments. To decouple the source of data from data consumers, a façade is introduced in the form of views or procedures. These facades are extremely important and inevitably found in almost every production database. So, let’s create a view as well. From the definition of the view, it may seem like the view is a mirror of the actual table as it returns all the records and fields. The definition of the view in our case is not important as the focus is to have a database object of type view so that we have a view in the mix of the variety of database objects that we are creating for schema comparison.
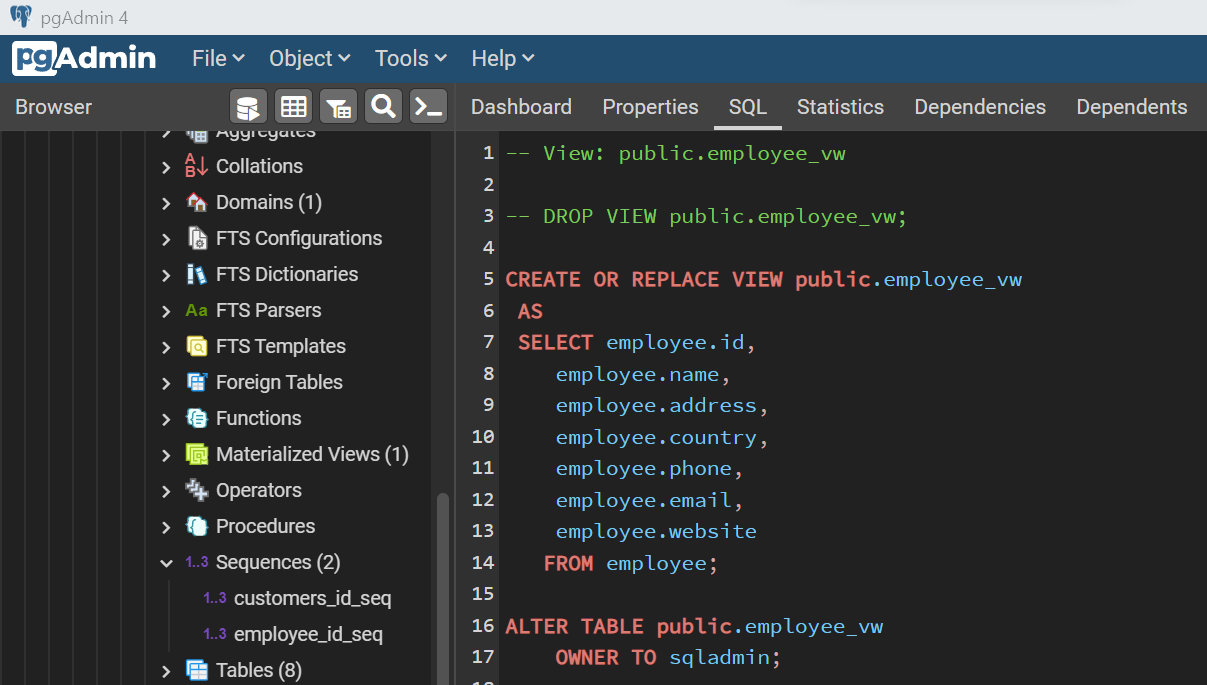
One another type of specialized database object that is found typically in most production databases is a materialized view. When the database is moved to production it may consist of regular views. Based on usage-based performance assessment, certain views may not perform up to the expectation due to the nature of the data model or the volume of data in the base tables that make up the view. To mitigate this, data is joined, processed, and physically stored in a database object called materialized view. Let’s add one materialized view too in the mix of the variety of database objects that we are creating. Shown below is an example of the materialized view.
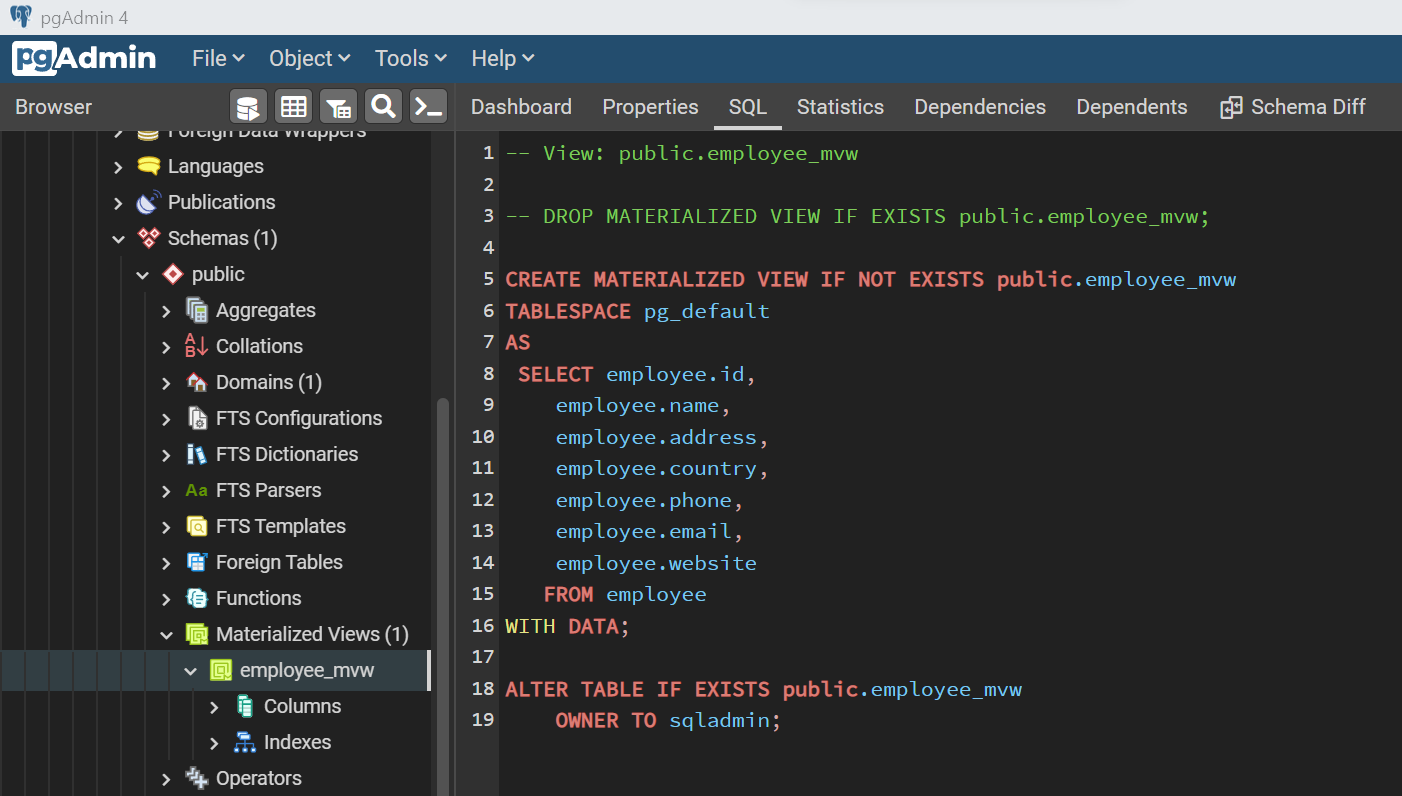
Now that our Azure Database for PostgreSQL is populated with a variety of database objects, we are ready to compare the schema of these database objects with others. The question that arises now is what we compare it against. We can compare it with some other database/schema/objects in another server. But for simplicity, we can just create another database in the same server and then use it for comparison. Let’s create a new database either using the wizard or using the code shown below.
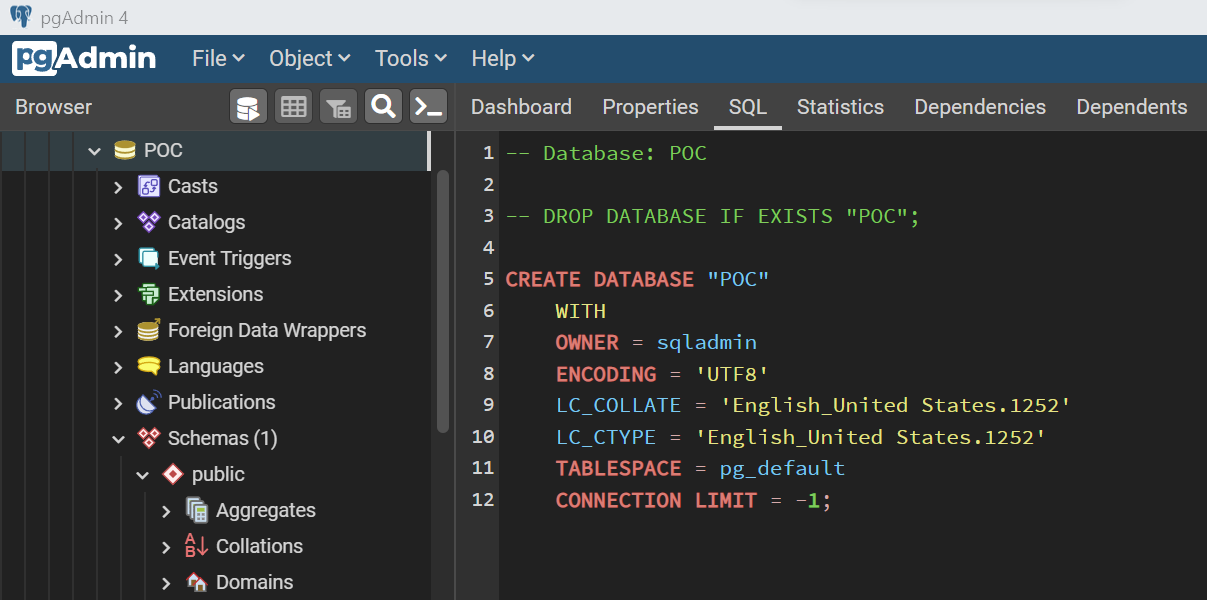
Now that we have enough variety of database objects and two databases as well, we can click on the Tools menu and open the Schema Diff tool. It would open a new pane as shown below. Let’s say that the database in which we created the database objects is the source and the new empty database is the target. Select these data sources accordingly as shown below and click on the Compare button. The results would look as shown below. If we analyze the results carefully, we will find that each database object is identified as expected as the target database is empty. The results highlight whether in each category, are there any identical or different database objects found, and in case if the database object is completely missing, then whether it is present in the source or the target database.
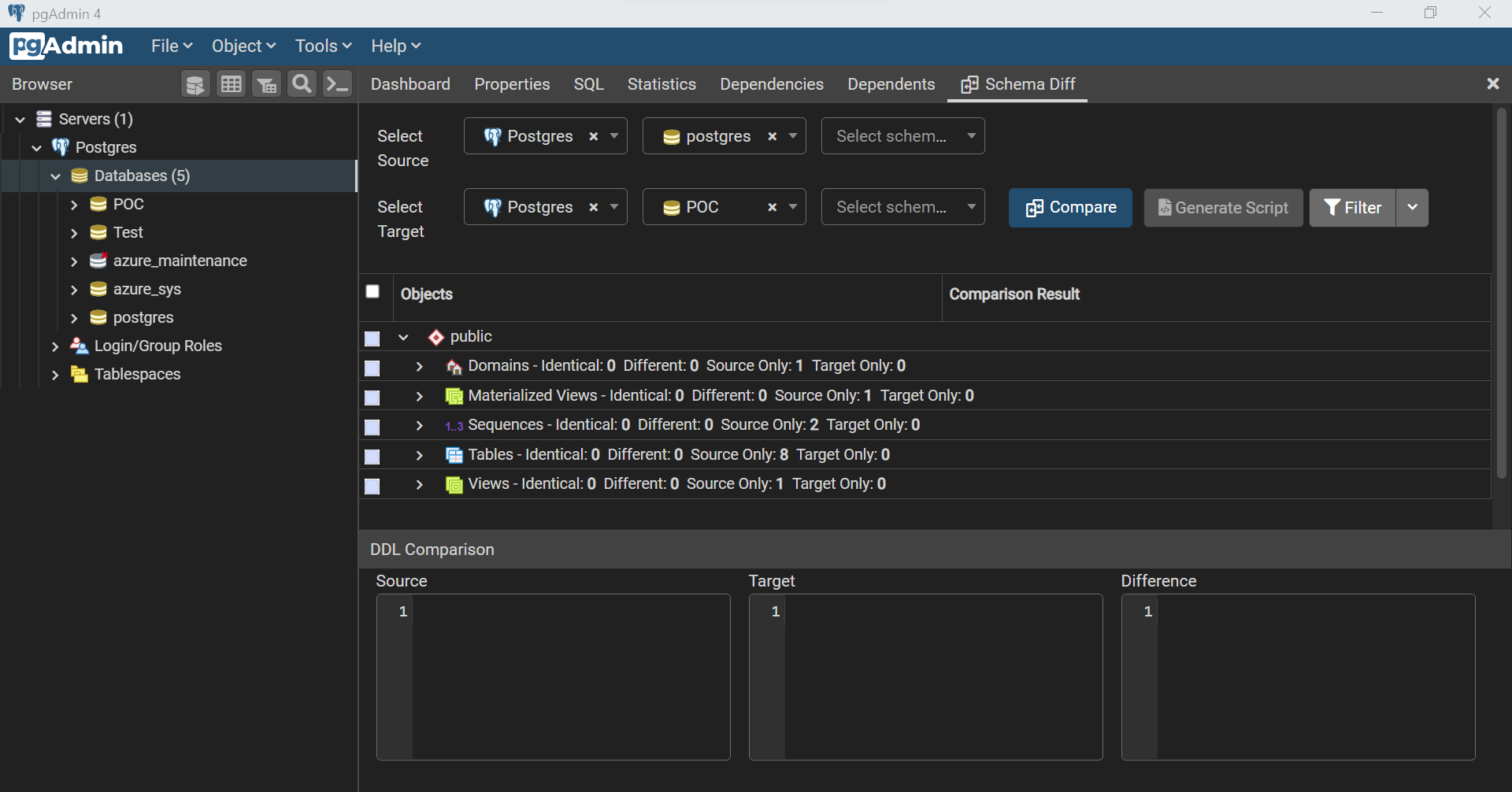
If we select the database object, we would be able to view the script of the database object as well as shown below. As the database object is present in the source and absent in the target, the script block for respective sections is shown accordingly, and the script to add it to the target is shown below.
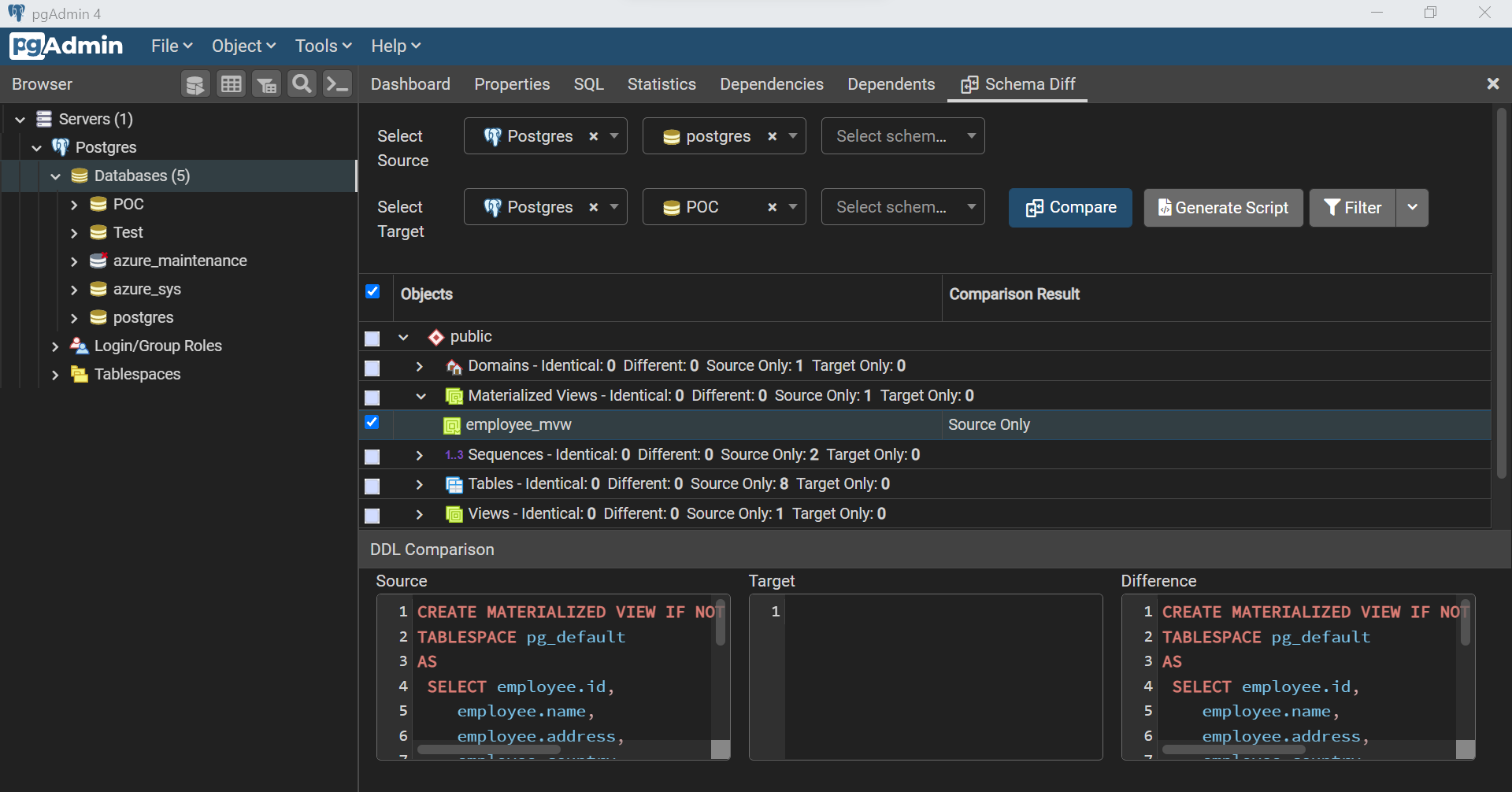
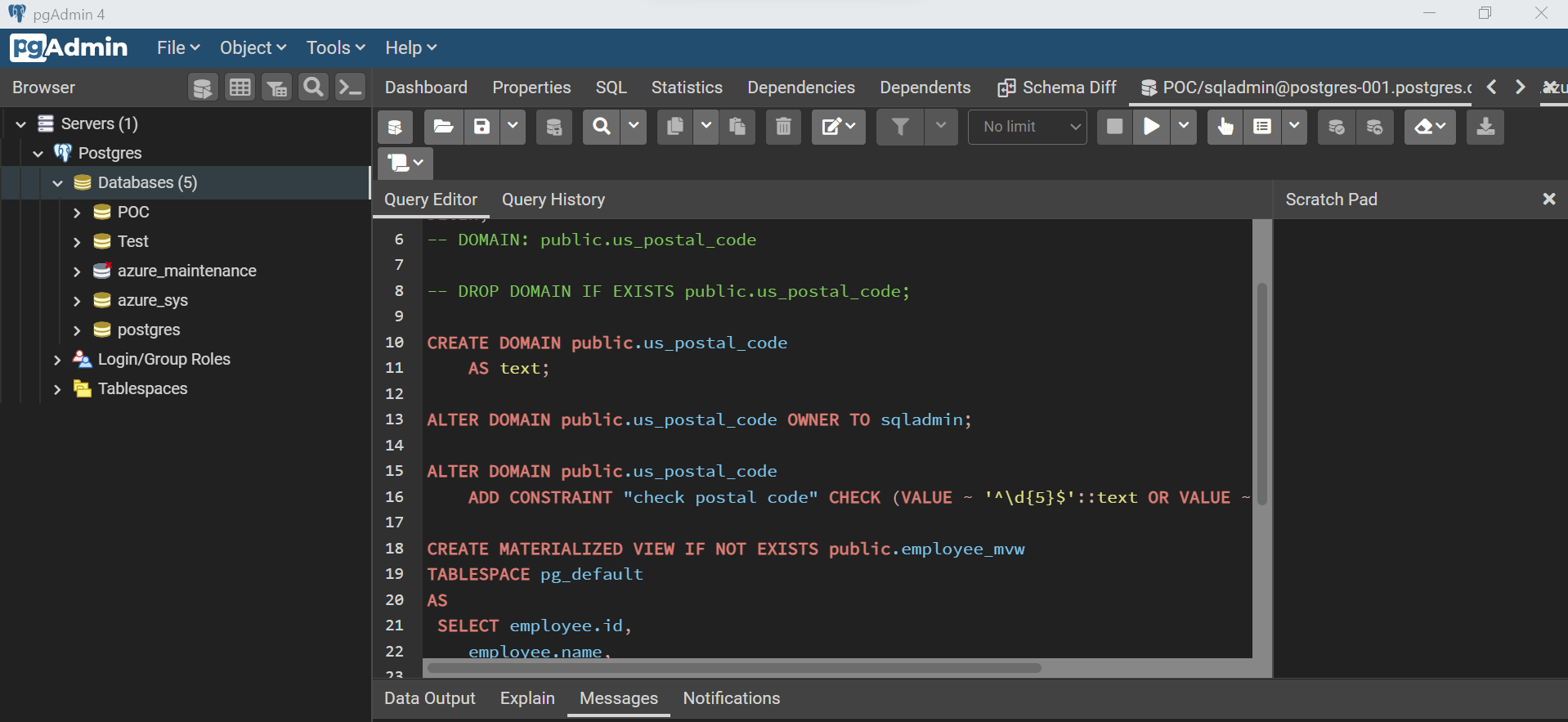
If we select the desired objects and click on the Generate Script button, it will generate a script as shown below, which can be executed on the target database to sync it with the source database.
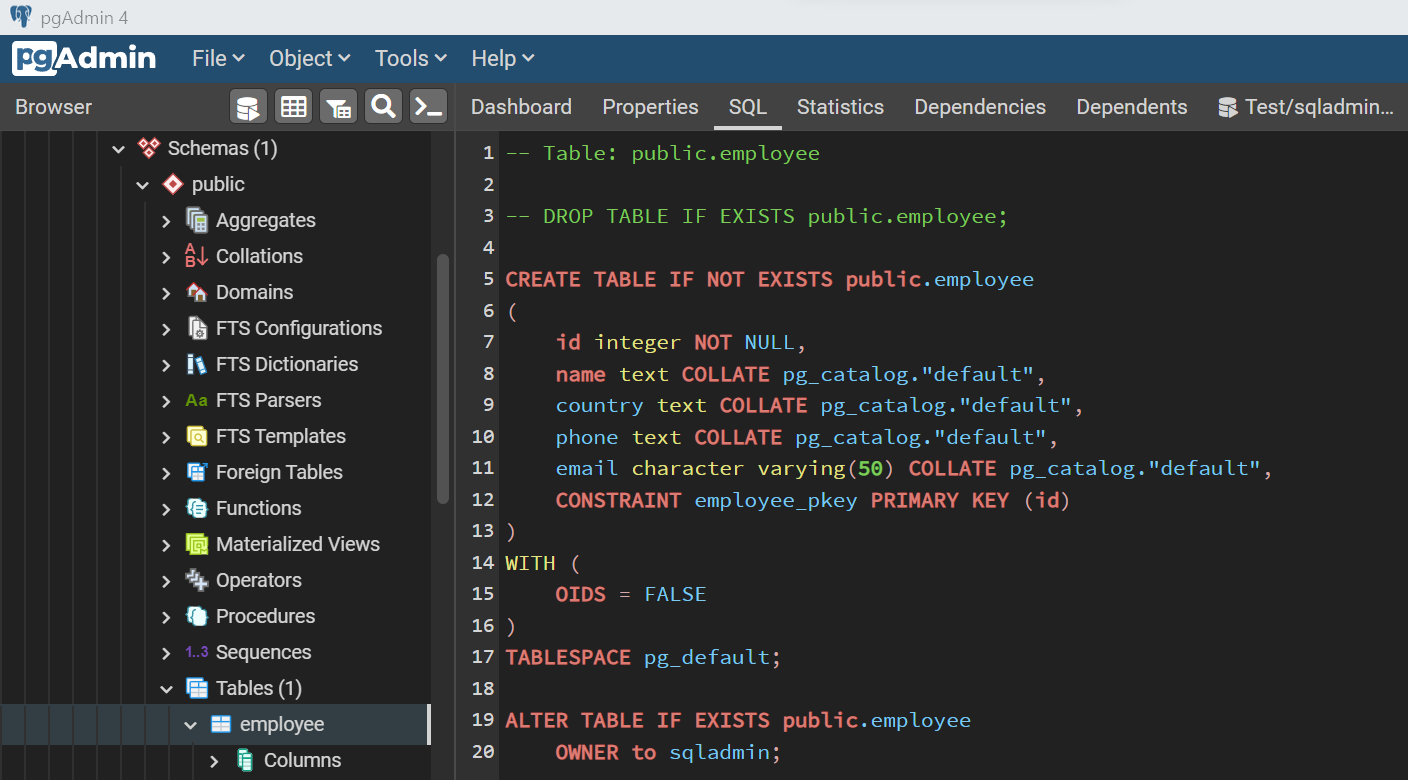
Let’s create an employee table in this empty database here but with a different schema. The field in this schema is a subset of the employee table in the Azure Database for PostgreSQL.
Now let’s create yet another new database and an employee table in it for another test scenario. Execute the code as shown below or use the table designer to create a new table with the fields as shown below.
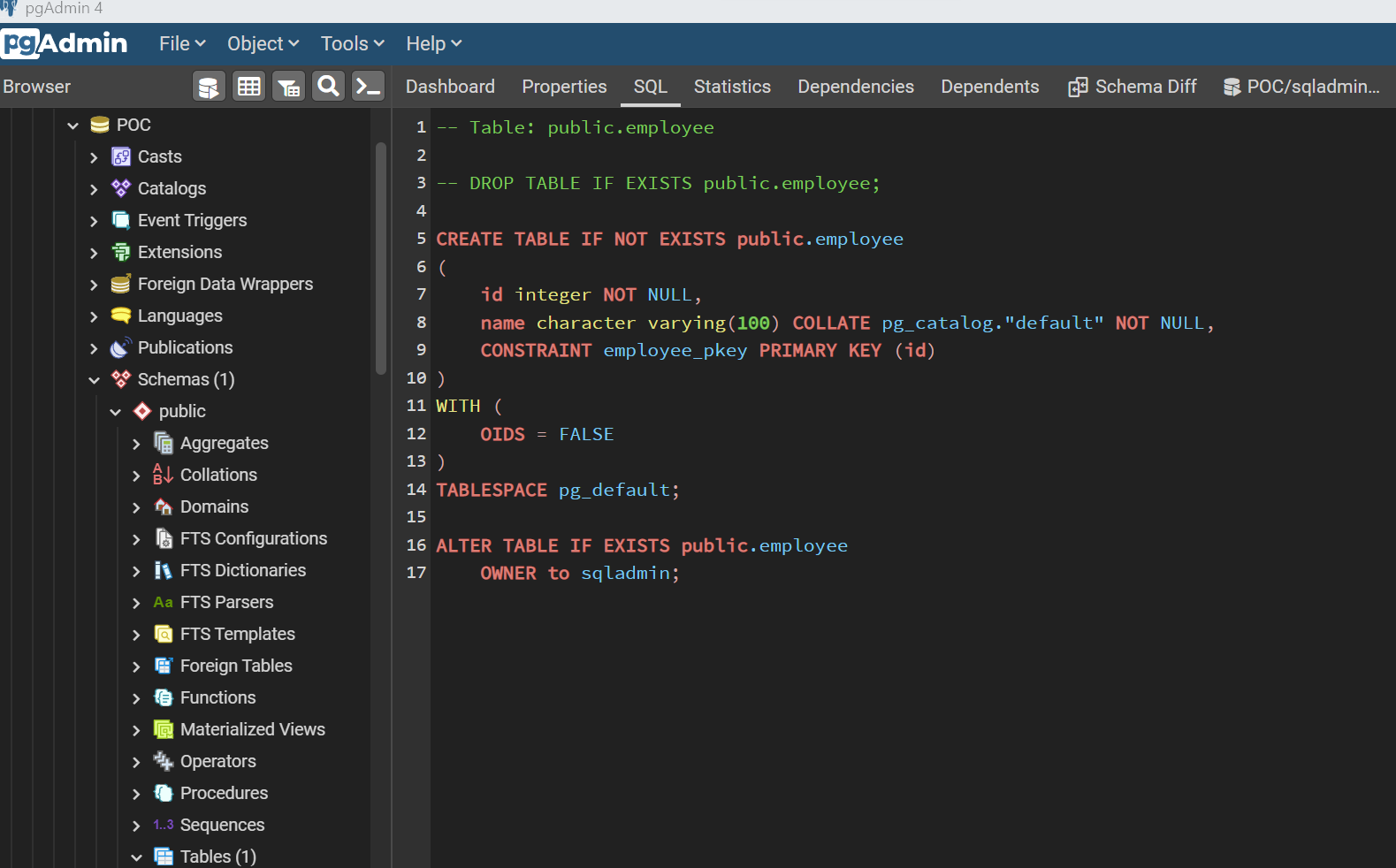
Now the scenario is that we have two databases with just one database object i.e., employee table, with the same name but different schema. This simulates a scenario where minor changes are made to a database in one environment, and it needs to be compared and synced with another database in a higher environment. After the table is created, compare these two databases and the results would look as shown below. Here it identifies the database object correctly, and as the target table has more fields than the source table, the script to sync database objects suggests dropping fields as shown below. Swap the source and target, and the sync script would have the commands to add columns.
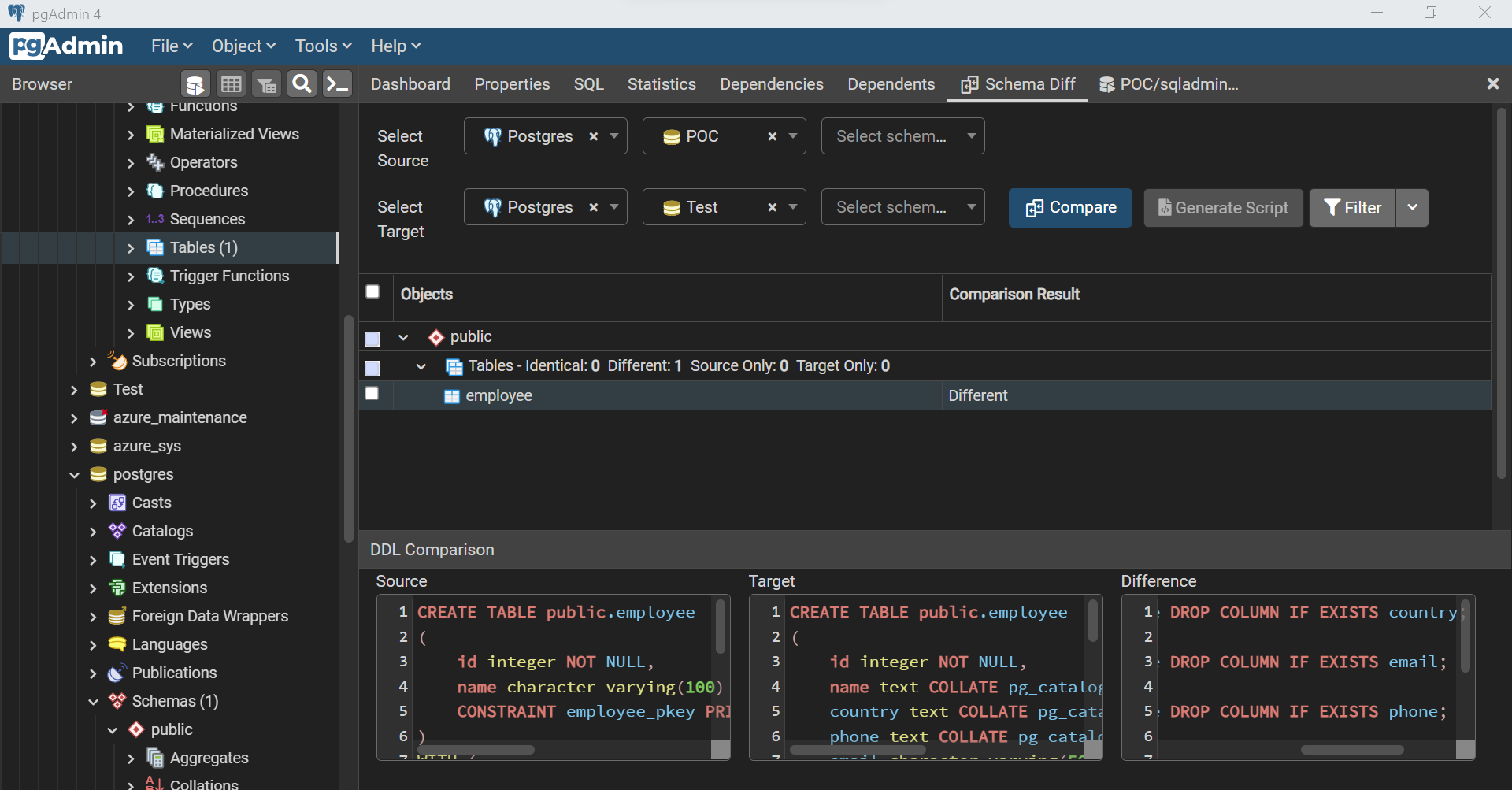
In this way, we can use the Schema Diff Tool in pgAdmin to perform a variety of such schema comparison and schema sync tasks. Consider exploring this tool in more depth to exploit its potential to its maximum.
Conclusion
In this article, we explore the features of the Schema Diff tool in pgAdmin to compare the schema of database objects and to generate a script to synchronize schema of database objects hosted on an instance of Azure Database for PostgreSQL.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023