
In this article, I’ll provide some useful information to help you understand how to use Unicode in SQL Server and address various compilation problems that arise from the Unicode characters’ text with the help of T-SQL.
What is Unicode?
The American Standard Code for Information Interchange (ASCII) was the first extensive character encoding format. Originally developed in the US, and intended for English, ASCII could only accommodate encoding for 128 characters. Character encoding simply means assigning a unique number to every character being used. As an example, we show the letters ‘A’,’a’,’1′ and the symbol ‘+’ become numbers, as shown in the table:
ASCII(‘A’) | ASCII(‘a’) | ASCII(‘1’) | ASCII(‘+’) |
65 | 97 | 49 | 43 |
The T-SQL statement below can help us find the character from the ASCII value and vice-versa:
|
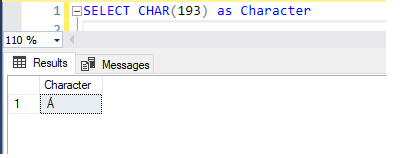
1 |
SELECT CHAR(193) as Character |
Here is the result set of ASCII value to char:
|
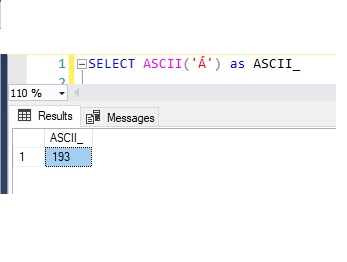
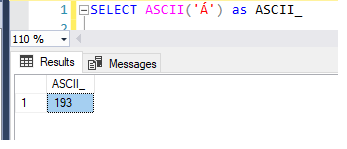
1 |
SELECT ASCII('Á') as ASCII_ |
Here is the result set of char to ASCII value:
While ASCII encoding was acceptable for most common English language characters, numbers and punctuation, it was constraining for the rest of the world’s dialects. As a result, other languages required different encoding schemes and character definitions changed according to the language. Having encoding schemes of different lengths required programs to figure out which one to apply depending on the language being used.
Here is where international standards become critical. When the entire world practices the same character encoding scheme, every computer can display the same characters. This is where the Unicode Standard comes in.
Encoding is always related to a charset, so the encoding process encodes characters to bytes and decodes bytes to characters. There are several Unicode formats: UTF-8, UTF-16 and UTF-32.
- UTF-8 uses 1 byte to encode an English character. It uses between 1 and 4 bytes per character and it has no concept of byte-order. All European languages are encoded in two bytes or less per character
- UTF-16 uses 2 bytes to encode an English character and it is widely used with either 2 or 4 bytes per character
- UTF-32 uses 4 bytes to encode an English character. It is best for random access by character offset into a byte-array
Special characters are often problematic. When working with different source frameworks, it would be preferable if every framework agreed as to which characters were acceptable. A lot of times, it happens that developers perform missteps to identify or troubleshoot the issue, and however, those issues are identified with the odd characters in the data, which caused the error.
Unicode data types in SQL Server
Microsoft SQL Server supports the below Unicode data types:
- nchar
- nvarchar
- ntext
The Unicode terms are expressed with a prefix “N”, originating from the SQL-92 standard. The utilization of nchar, nvarchar and ntext data types are equivalent to char, varchar and text. The Unicode supports a broad scope of characters and more space is expected to store Unicode characters. The most extreme size of nchar and nvarchar columns is 4,000 characters, not 8,000 characters like char and varchar. For example:
N’Mãrk sÿmónds’
All Unicode data practices the identical Unicode code page. Collations do not regulate the code page, which is being used for Unicode columns. Collations control only attributes such as comparison rules and case sensitivity.
This T-SQL statement prints the ASCII values and characters for the ASCII 193-200 range:
|
1 |
SELECT CHAR(193), CHAR(194), CHAR(195), CHAR(196), CHAR(197), CHAR(198), CHAR (199), CHAR (200) |
CHAR(193) | CHAR(194) | CHAR(195) | CHAR(196) | CHAR(197) | CHAR(198) | CHAR(199) | CHAR(200) |
Á | Â | Ã | Ä | Å | Æ | Ç | È |
Get a list of special characters in SQL Server
Here are some of the Unicode character sets that can be represented in a single-byte coding scheme; however, the character sets require multi-byte encoding. For more information on character sets, check out the below function that returns the ASCII value and character with positions for each special character in the string with the help of T-SQL statements:
Function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE FUNCTION [dbo].[Find_Unicode] ( @in_string nvarchar(max) ) RETURNS @unicode_char TABLE(id INT IDENTITY(1,1), Char_ NVARCHAR(4), position BIGINT) AS BEGIN DECLARE @character nvarchar(1) DECLARE @index int SET @index = 1 WHILE @index <= LEN(@in_string) BEGIN SET @character = SUBSTRING(@in_string, @index, 1) IF((UNICODE(@character) NOT BETWEEN 32 AND 127) AND UNICODE(@character) NOT IN (10,11)) BEGIN INSERT INTO @unicode_char(Char_, position) VALUES(@character, @index) END SET @index = @index + 1 END RETURN END GO |
Execution:
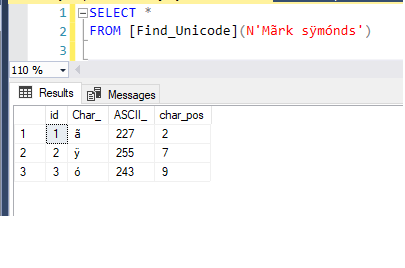
|
1 2 |
SELECT * FROM [Find_Unicode](N'Mãrk sÿmónds') |
Here is the result set:
Remove special characters from string in SQL Server
In the code below, we are defining logic to remove special characters from a string. We know that the basic ASCII values are 32 – 127. This includes capital letters in order from 65 to 90 and lower case letters in order from 97 to 122. Each character corresponds to its ASCII value using T-SQL. The “RemoveNonASCII” function excludes all the special characters from the string and sets up a blank of them:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE FUNCTION [dbo].[RemoveNonASCII] ( @in_string nvarchar(max) ) RETURNS nvarchar(MAX) AS BEGIN DECLARE @Result nvarchar(MAX) SET @Result = '' DECLARE @character nvarchar(1) DECLARE @index int SET @index = 1 WHILE @index <= LEN(@in_string) BEGIN SET @character = SUBSTRING(@in_string, @index, 1) IF (UNICODE(@character) between 32 and 127) or UNICODE(@character) in (10,11) SET @Result = @Result + @character SET @index = @index + 1 END RETURN @Result END |
Execution:
|
1 |
SELECT dbo.[RemoveNonASCII](N'Mãrk sÿmónds') |
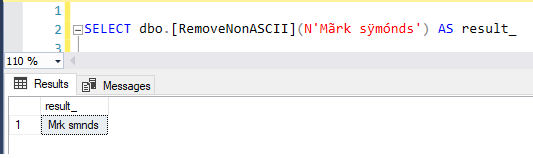
These SQL functions can be very useful if you’re working with large international character sets.

View all posts by Jignesh Raiyani
- Page Life Expectancy (PLE) in SQL Server - July 17, 2020
- How to automate Table Partitioning in SQL Server - July 7, 2020
- Configuring SQL Server Always On Availability Groups on AWS EC2 - July 6, 2020