
If you are maintaining a very large database, you might be well aware of the pain to perform update statistics on a very large table.
This article introduces incremental statistics which is available from SQL Server 2014 highly simplifies statistics management on very large partitioned tables.
SQL Server Incremental Statistics
Accurate statistics are essential to allow query optimizer to generate a good enough query plan. In a very large partitioned table, updating table statistics requires to sample rows across all partitions and the statistics reflects the data distribution of the table as whole. Update statistics takes a lot of I/O and CPU resources not to mention the duration can be very lengthy.
Imagine the data distribution remain the same for all previous partitions, and you only need SQL Server to know the changed data distribution for a newly created\loaded partition. This sounds like a common scenario and now you can manage this scenario efficiently using Incremental Statistics which is built-in on SQL Server 2014 and onwards.
Prior to SQL Server 2014, the similar workaround to maintain partition specific statistics is to create filtered statistics for each partition manually and update the specific partition statistics.
This article will utilize WideWorldImporters database on SQL Server 2016 Developer Edition Service Pack 1 to understand the utilization of Incremental Statistics.
Brief on partitioned tables
WideWorldImporters is a great sample database as it comes with 2 partitioned tables – Purchasing.SupplierTransactions and Sales.CustomerTransactions.
For simplicity, we will just focus on table Purchasing.SupplierTransactions in this article.
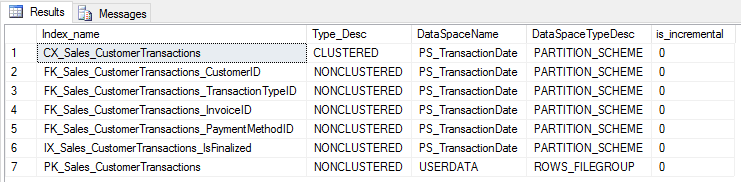
Incremental statistics will only work on statistics which the index definition uses the same partition scheme as the partitioning column on the table to be able to set STATISTICS_INCREMENTAL = ON.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
USE WideWorldImporters GO SELECT i.name AS Index_name , i.Type_Desc AS Type_Desc , ds.name AS DataSpaceName , ds.type_desc AS DataSpaceTypeDesc , st.is_incremental FROM sys.objects AS o JOIN sys.indexes AS i ON o.object_id = i.object_id JOIN sys.data_spaces ds ON ds.data_space_id = i.data_space_id JOIN sys.stats st ON st.object_id = o.object_id AND st.name = i.name LEFT OUTER JOIN sys.dm_db_index_usage_stats AS s ON i.object_id = s.object_id AND i.index_id = s.index_id AND s.database_id = DB_ID() WHERE o.type = 'U' AND i.type <= 2 AND o.object_id = OBJECT_ID('Sales.CustomerTransactions') |
If you try to update partition level statistics on an index statistics which has not been set to use incremental statistics, it will prompt an error.
|
1 2 3 4 |
UPDATE STATISTICS [WideWorldImporters].[Sales].[CustomerTransactions] (CX_Sales_CustomerTransactions) WITH RESAMPLE ON PARTITIONS(1) |
Msg 9111, Level 16, State 1, Line 34
UPDATE STATISTICS ON PARTITIONS syntax is not supported for non-incremental statistics.
Note that argument RESAMPLE is required (argument FULLSCAN or SAMPLE number PERCENT is not supported) when updating partition level statistics. RESAMPLE reads the leaf-level statistics using the same sample rates and merge this result back into the main statistics histogram.
A different partition sampling rate cannot be merged together and the syntax constraints made sure this does not occur as well.
Enabling Incremental Statistics
There is a database level setting to enable incremental statistics. When the option INCREMENTAL is turn on at the database level, newly auto created column statistics will use incremental statistics on partitioned tables by default.
|
1 2 3 4 5 6 |
USE [master] GO ALTER DATABASE [databaseName] SET AUTO_CREATE_STATISTICS ON (INCREMENTAL = ON) GO |
Existing index or column statistics will not be affected by this database option. You will have to manually set the existing statistics to be an incremental statistics on the partitioned table. The command is quite straight-forward as below.
|
1 2 3 4 |
UPDATE STATISTICS [WideWorldImporters].[Sales].[CustomerTransactions] (CX_Sales_CustomerTransactions) WITH RESAMPLE ON PARTITIONS(3) |
Once incremental statistics is enabled for an index statistics, the is_incremental value will be set to 1 on DMV sys.stats.
|
1 2 3 4 5 6 7 8 9 10 11 |
USE WideWorldImporters GO SELECT OBJECT_NAME(object_id) TableName , name , is_incremental , stats_id FROM sys.stats WHERE name = 'CX_Sales_CustomerTransactions' |

Now that incremental statistics is enabled on CX_Sales_CustomerTransactions, we can update the index statistics at the partition level.
From SQL Server 2014 SP2 and SQL Server 2016 SP1, you can leverage a documented DMF sys.dm_db_incremental_stats_properties to view properties of the incremental statistics
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
USE [WideWorldImporters] GO UPDATE STATISTICS Sales.CustomerTransactions(CX_Sales_CustomerTransactions) WITH RESAMPLE ON PARTITIONS(3) GO SELECT OBJECT_NAME(a.object_id) TblName , a.stats_id , b.partition_number , b.last_updated , b.rows , b.rows_sampled , b.steps FROM sys.stats a CROSS APPLY sys.dm_db_incremental_stats_properties(a.object_id, a.stats_id) b WHERE a.name = 'CX_Sales_CustomerTransactions' |
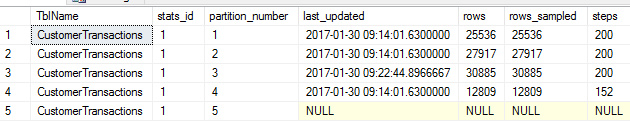
There are 5 partitions and each partition indicates it has its own statistics with a maximum of 200 steps for each partition that contains data. We have only updated the statistics for partition 3 and this is reflected by newer date and time stamp in the last_updated column.
Incremental statistics are not used by CE
It is great to know each partition can contain up to 200 steps to form a histogram. However, SQL Server do not use this partition level statistics in Cardinality Estimate (CE). The main statistics which get updates from partition level statistics is the statistics that SQL Server will use. CE refers to an estimated prediction of the number of rows in query result and primarily derived from histograms that are created when indexes or statistics are created.
To prove this statement, we will use DBCC SHOW_STATISTICS to get the statistics histogram of the main statistics and the incremental statistics and test the CE with a simple query.
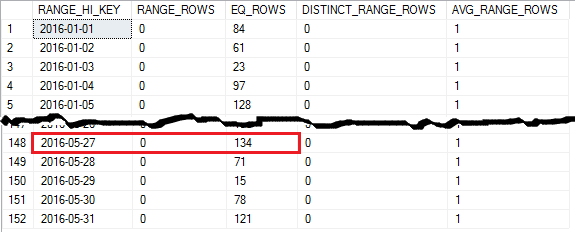
Main statistics
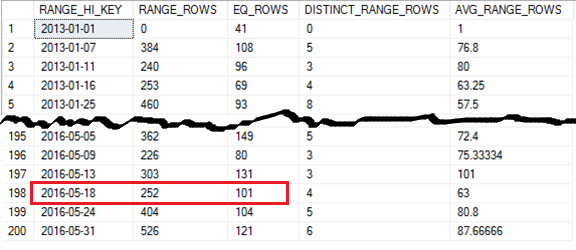
At the time of this article, the only way to get detailed content of statistics histogram is to use DBCC SHOW_STATISTICS. Index statistics CX_Sales_CustomerTransactions has 200 steps and the screen shot is cut short to show the beginning and the end of the statistics histogram.
|
1 2 3 4 |
DBCC SHOW_STATISTICS('Sales.CustomerTransactions', CX_Sales_CustomerTransactions) WITH HISTOGRAM |
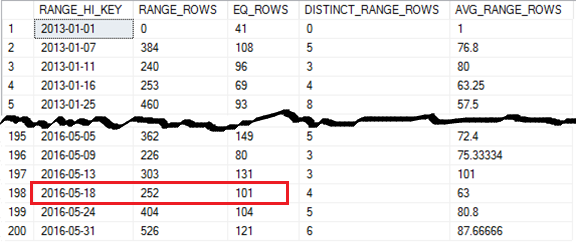
Executing a simple query filtering on a TransactionDate = 2016-05-18 which has an equal EQ_ROWS in the statistics histogram returns with an accurate 101 rows in the Actual Number of Rows and also matches the Estimated Number of Rows in the query plan.
|
1 2 3 4 5 |
SELECT TransactionDate FROM [Sales].[CustomerTransactions] WHERE TransactionDate = '2016-05-18' OPTION (RECOMPILE) |

Partition Level incremental Statistics
We will use an undocumented trace flag 2309 to view the incremental statistics histogram. This trace flag allows an additional node_id parameter to be specified as an input into DBCC SHOW_STATISTICS command.
The node_id for a particular partition can be obtained using an undocumented DMF [sys].[dm_db_stats_properties_internal].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE [WideWorldImporters] GO SELECT node_id , last_updated , steps , next_sibling , left_boundary , right_boundary , partition_number FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('Sales.CustomerTransactions'),1) ORDER BY [node_id]; |
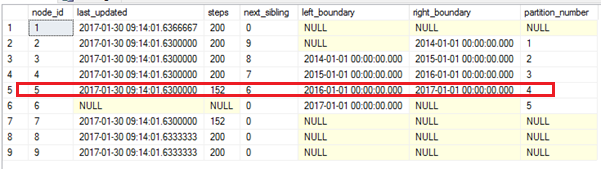
We will pick partition 4 which has 152 steps to display the incremental statistics histogram as an example.
|
1 2 3 4 5 |
DBCC TRACEON(2309); GO DBCC SHOW_STATISTICS('Sales.CustomerTransactions','CX_Sales_CustomerTransactions', 5); |
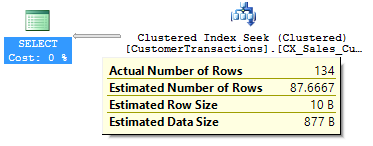
Re-executing the SELECT query filtering on TransactionDate = 2016-05-27 indicates the Estimated Number of Rows is 87.6 whereas the actual number of rows read is 134 (134 is accurately reflected in the incremental statistics EQ_ROWS but is not used by SQL Server CE).
If you refer to the main statistics histogram, 87.6 is the AVG_RANGE_ROWS value for TransactionDate = 2016-05-31. So, SQL Server uses the main statistics histogram to get the CE and not the incremental statistics histogram.
|
1 2 3 4 5 |
SELECT TransactionDate FROM [Sales].[CustomerTransactions] WHERE TransactionDate = '2016-05-27' OPTION (RECOMPILE) |
Incremental Statistics in Action
We will insert 10 rows each into partition 1 and partition 5. The INSERT will not kick off automatic update statistics since the number of rows inserted are very small relative to the total number of rows in the table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
USE [WideWorldImporters] GO INSERT INTO [Sales].[CustomerTransactions] (CustomerTransactionID, CustomerID, TransactionTypeID, InvoiceID, PaymentMethodID, TransactionDate, AmountExcludingTax, TaxAmount, TransactionAmount, OutstandingBalance, FinalizationDate, LastEditedBy, LastEditedWhen) SELECT TOP 10 CustomerTransactionID + 1000000, CustomerID, TransactionTypeID, InvoiceID, PaymentMethodID, '20 Jan 2017', AmountExcludingTax, TaxAmount, TransactionAmount, OutstandingBalance, FinalizationDate, LastEditedBy, LastEditedWhen FROM [Sales].[CustomerTransactions] UNION ALL SELECT TOP 10 CustomerTransactionID + 2000000, CustomerID, TransactionTypeID, InvoiceID, PaymentMethodID, '2 Jan 2013', AmountExcludingTax, TaxAmount, TransactionAmount, OutstandingBalance, FinalizationDate, LastEditedBy, LastEditedWhen FROM [Sales].[CustomerTransactions] |
The index statistics CX_Sales_CustomerTransactions is not updated and hence the query plan below will not reflect the additional 10 rows inserted for TransactionDate = 2017-01-20.
|
1 2 3 4 5 |
SELECT TransactionDate FROM [Sales].[CustomerTransactions] WHERE TransactionDate = '2017-01-20' OPTION (RECOMPILE) |
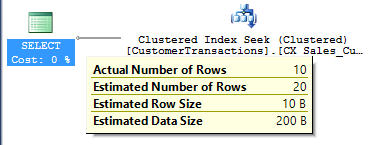
We now update the statistics for only partition 5 and check the main statistics
|
1 2 3 4 5 6 7 |
UPDATE STATISTICS Sales.CustomerTransactions(CX_Sales_CustomerTransactions) WITH RESAMPLE ON PARTITIONS(5) GO DBCC SHOW_STATISTICS('Sales.CustomerTransactions', CX_Sales_CustomerTransactions) WITH HISTOGRAM |
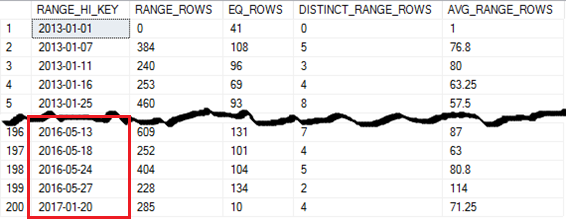
The main statistics now has reflected statistics on partition 5 only, and the statistics histogram between partition 1 and partition 4 remains the same.
Re-executing the same query on TransactionDate = 2017-01-20 would now reflect a more accurate estimation of rows returned.
|
1 2 3 4 5 |
SELECT TransactionDate FROM [Sales].[CustomerTransactions] WHERE TransactionDate = '2017-01-20' OPTION (RECOMPILE) |
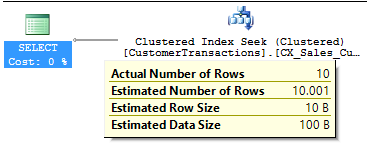
Since index statistics CX_Sales_CustomerTransactions is updated using FULLSCAN, updating partition level statistics with RESAMPLE will also use FULLSCAN.
Manually updating partition 1 and partition 5 statistics took 39 ms.
|
1 2 3 4 5 6 |
SET STATISTICS TIME ON GO UPDATE STATISTICS Sales.CustomerTransactions(CX_Sales_CustomerTransactions) WITH RESAMPLE ON PARTITIONS(1, 5) |
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 39 ms.
The conventional way without incremental statistics to update statistics using FULLSCAN on index statistics CX_Sales_CustomerTransactions took 82 ms. On this very small scale of testing, this update statistics is twice slower than just updating incremental statistics of 2 partitions.
It is easy to imagine the benefit if the rows in the table is of magnitude in scale.
|
1 2 3 4 5 6 |
SET STATISTICS TIME ON GO UPDATE STATISTICS Sales.CustomerTransactions(CX_Sales_CustomerTransactions) WITH FULLSCAN |
SQL Server Execution Times:
CPU time = 78 ms, elapsed time = 82 ms.
Summary
Incremental Statistics are only relevant for partitioned tables, and this feature is a clever way to allow more efficient statistics management for very large partitioned tables.
Whilst the partition level statistics are not used by SQL Server CE, allowing finer grain control to only update subset of the main statistics based on partitions which has changed data only helps tremendously with the performance of statistics maintenance.

Simon has over 15+ years of database design, implementation, administration and development in SQL Server. He is a Microsoft Certified Master for SQL Server 2008 and holds a Master’s Degree in Distributed Computing. Achieving Microsoft masters-level certifications validate the deepest level of product expertise, as well as the ability to design and build the most innovative solutions for complex on-premises, off-premises, and hybrid enterprise environments using Microsoft technologies.
View all posts by Simon Liew