
With this article, we continue part 1 of common best practices to optimize the performance of Integration Services packages. As mentioned in the previous article “Integration Services (SSIS) Performance Best Practices – Data Flow Optimization“, it’s not an exhaustive list of all possible performance improvements for SSIS packages. It merely represents a set of best practices that will guide you through the most common development patterns.
#6 Use the FastLoad option
This tip only applies when you are using the OLE DB Destination and if your destination supports the fast load option. It’s very common though to have SQL Server as the destination. In that case, use the fast load option. If not, you are inserting records row by row which has a devastating impact on the transaction log.
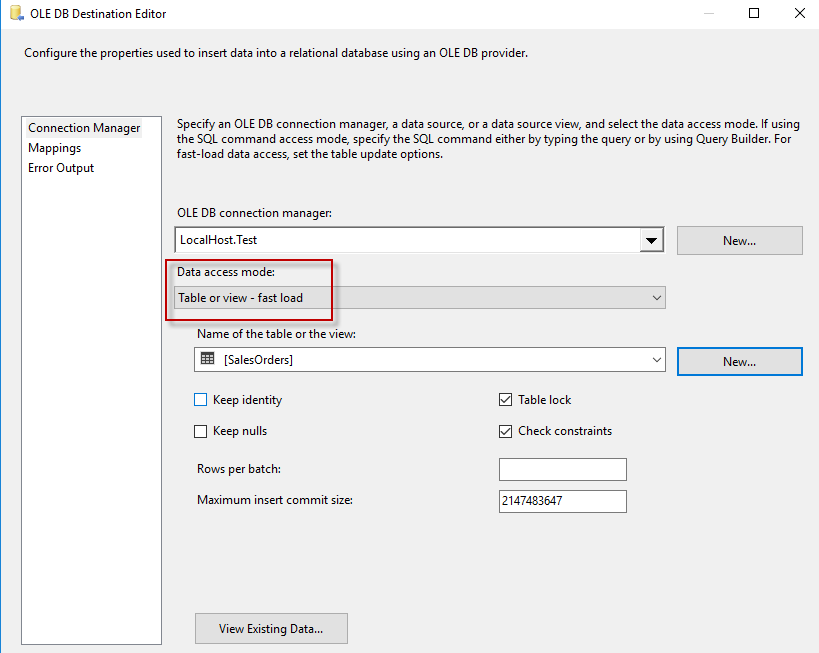
The default settings work fine in general. You can tweak them a bit for a specific need though. A good use case is when loading data to a clustered column store index. Here you want that only batches of at least 102,400 rows (preferably over a million) are sent to SQL Server. In this case, the batches end up immediately in a compressed row group instead of the delta store (which is row based and thus slower). More info can be found at Clustered Columnstore Indexes – part 51 (“SSIS, DataFlow & Max Buffer Memory”) and Loading Data into Clustered Columnstore Index with SSIS.
In most cases, the OLE DB Destination – when writing to SQL Server using the Native Client – outperforms all other alternatives. The SQL Server Destination is supposed to be faster (at least in 2005), but it has some limitations and nowadays the OLE DB Destination is the best option. OLE DB is deprecated though by Microsoft. This means you can still use the OLE DB connection managers, but there are no new features being released. For example, AlwaysEncrypted is supported by ADO.NET but not by OLE DB.
#7 Prepare your Destination
Just as you need to prepare your source (for example by putting the right indexes into place to speed up reading), you need to prepare your destination. Here are some examples of how you can make your destination go faster (most apply when the destination is SQL Server):
-
Put the destination on a fast disk. SSDs are preferred.
-
For large loads, you can disable constraints on the table and re-enable them after the load. The same applies for indexes: you can drop them first and recreate them after the SSIS package has finished. This avoids fragmentation of your indexes.
-
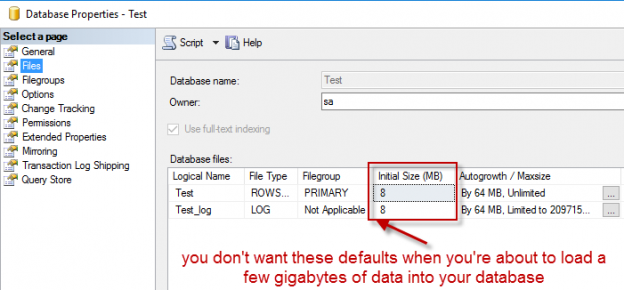
If you write to a database, make sure the database files have the appropriate size. You don’t want them to be automatically growing all the time (especially not with the default settings). Estimate what your total data volume is and how it is going to grow in the coming months. Then size your files accordingly.

-
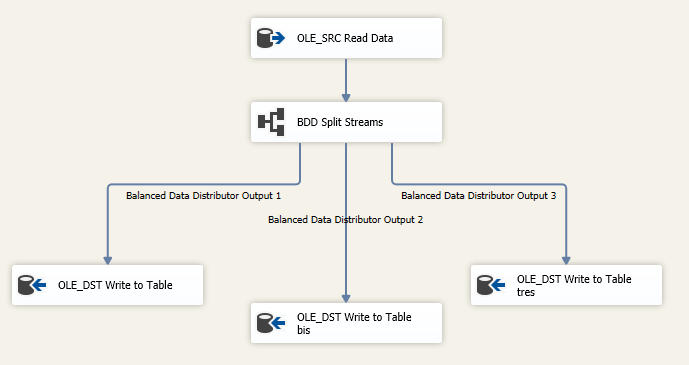
If possible, try to load in parallel. You’ll probably need to take precautions to avoid locking and blocking. Try to avoid a “hot spot” in your clustered index: all the load processes try to insert at the last page of the clustered index at the same time. The Balanced Data Distributor can help you to parallelize your data flow. This component is a separate download for SSIS 2012 and 2014, but is built-in into SSIS 2016.
-
Go for as minimal logging as possible. Set the recovery model to Simple, if your disaster recovery policy allows it. Do bulk inserts (using the fast load option) and configure them to be minimally logged. You can check the Data Loading Performance Guide on how to do this. The guide is from SQL Server 2008, but most information is still applicable today. As with data files, size your log files appropriately.
Remember if your destination is slow, your source will be slow as well due to backpressure in the data flow. In other words, if your destination can’t keep up with the source, SSIS will tell the source to slow down. You can easily test this by removing the destination and running the package. If suddenly your data flow is very fast, the destination is the problem.
#8 Know the difference between ETL and ELT
Integration Services is a great tool and if designed correctly, performance can be extraordinary. However, you don’t need to approach all problems with a hammer. For example, if the source and the destination are on the same destination, ELT (Extract – Load – Transform) probably will outperform SSIS. With ELT, the data is loaded into the destination (with SSIS or with stored procedures) and the transformations are done with stored procedures. Especially when SSIS resides on another server, ELT will be preferred because it will save you the network round trip between the servers. When you use the SSIS data flow, all data needs to be read into the memory of the server where the package is running. If the server is another one than the database server, you need to transfer all the data over the network. Twice.
Integration Services excels in transferring data from server A to server B. However, once the data is in the destination, ELT probably is the best option to move forward. This doesn’t mean you don’t need to use SSIS anymore. The SSIS control flow is ideal for visualizing and orchestrating the flows of your data. Furthermore, it has the additional advantage of easily running tasks in parallel (which is not so easy in a stored procedure).
Aside from data movement, some tasks are better done using SQL statements instead of using transformations in a data flow. The most obvious examples are sorting and aggregating data, as discussed in the section about blocking components. Updating data is also better done outside the data flow in an Execute SQL Task. Think about the transformations you want to do and where they will be the most efficient: in the data flow or in the database engine.
Conclusion
If you follow a couple of design principles, Integration Services packages will perform just fine in most scenarios. This article presented you these design principles along with some extra performance tips. As mentioned, it’s not an exhaustive list – I’m sure there are other performance tricks out there – but rather a collection of the top practices on my checklist when I audit packages.
Reference links
- Data Loading Performance Guide
- Loading Data into Clustered Columnstore Index with SSIS
- Balanced Data Distributor Transformation
- Difference between ETL and ELT

Koen has over 7 years of experience in developing data warehouses, cubes, and reports using the Microsoft BI stack. Somehow he has developed a particular love for Integration Services along the way.
He has a blog at http://www.sqlkover.com and he is a frequent speaker at local SQL Server events. You can find him on Twitter as @Ko_Ver.
View all posts by Koen Verbeeck