
Introduction
Following best practices, we should apply principles like segregation of duties. This implies the segregation of application environments. In particular, we might see for a given application that it incorporates at least two environments: a production environment and a non-production environment that exists for testing, Q/A, training, etc
The value we give to each of these environments could be different, depending on multiple factors. For that reason, amongst other aspects, we won’t apply the same backups for each of these environments. For instance, the default strategy for production databases could be to take a FULL backup every night and a log backup every 3 hours. In contrast, we could decide that we won’t take backups at all for non-production environments except those related to development tasks. For these development databases, we could take a FULL backup once a week (but it should be more frequently).
Depending on the need for backup operations, we should adjust the Recovery Model option of each database so that we are able to only do the expected operations and there is no side effect with this setting. Let me explain.
In order to take a LOG backup for a given database, we need to define its recovery model either to FULL or BULK_LOGGED.
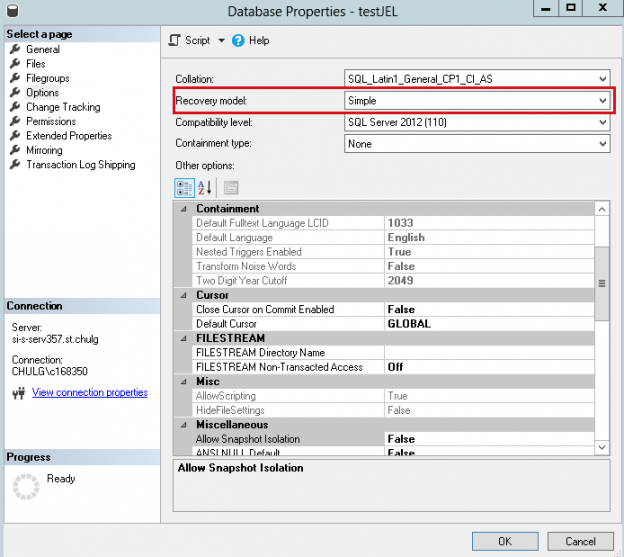
Let’s prove this assumption simply by taking a database called [testJEL] which is in SIMPLE recovery model:
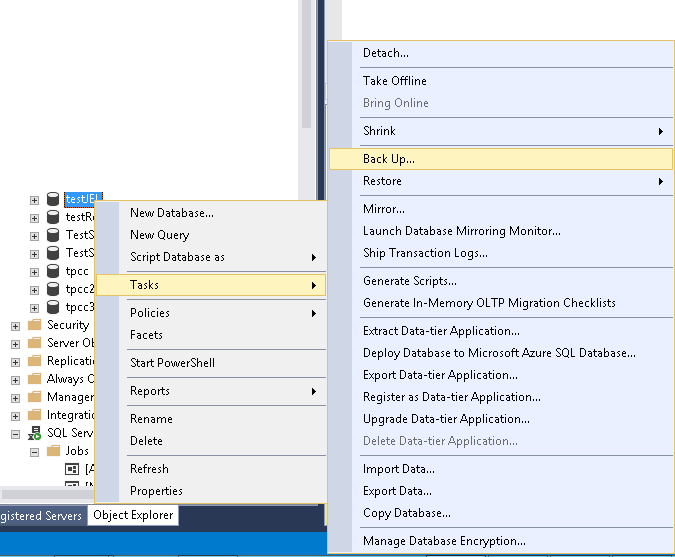
Using SQL Server Management Studio (SSMS), let’s try to take a LOG backup for that database.
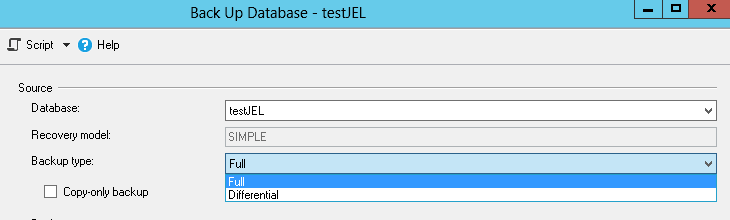
We can see that the LOG backup type is not on the list…
So, for environments where LOG backups are mandatory, we should ensure that databases are not in SIMPLE recovery model.
But that’s not all! What happens if there are databases set with FULL recovery model in an environment which is not backed up? It’s pretty easy to understand that, sooner or later, either the transaction log or file system hosting this transaction log will be full.
To prevent it from happening, we should ensure that every database in such an environment uses the SIMPLE recovery model.
This article will present a solution that monitors if the recovery model for each database on a given SQL Server instance is adequate with the backup policy defined for that server.
To do so, we will first define some pretty common software environments and the backup policy that should be applied. Once it’s done, we will define a (simple) way to keep track of current server’s environment. Then, we will discuss a stored procedure that we will use in order not only to detect abnormal database settings (regarding its recovery model) but also to correct them.
Defining environments and a sample backup policy
Here is a table with some common environments and an example backup policy.
| Environment Name | Backup Policy (default) | Acceptable Recovery Models |
| Production |
FULL backup every day LOG backup every 3 hours |
|
| Test | FULL backup once a week |
|
| Evaluation | No backup |
|
| Training | No backup |
|
| Development | FULL backup every day |
|
| Teaching | No backup |
|
In summary, with this kind of backup policy, only production environments should be using a recovery model different from SIMPLE.
How to keep track of server environment variables
In the most standardized environments, we might use different drive letters. For instance, we could use the D:\ drive for system databases, the P:\ drive for actual production ones and the E:\ drive for non-production data. But it’s not an absolute rule that everybody can use…
For that reason, we will keep it simple and store this information in a table, in a database dedicated to DBA tasks and tools. This table should help to answer two questions:
- which environment are we in?
- which databases should I ignore? (i.e. which databases are considered as system databases)
Storage description
We will use a table called [Common].[ApplicationParams] that I already introduced in an article entitled How to report on SQL Server deadlock occurrences. As indicated by its name, it’s a table that holds parameters for applications. Here is its structure:
|
1 2 3 4 5 6 7 8 9 10 11 |
[ApplicationName] [varchar](128) NOT NULL, [ParamName] [varchar](64) NOT NULL, [ParamValue] [varchar](max), [DefaultValue] [varchar](max), [ValueCanBeNULL] [bit] DEFAULT 0 NOT NULL, [isDepreciated] [bit] NOT NULL, [ParamDescription] [varchar](max) NULL, [creationdate] [datetime] NOT NULL, [lastmodified] [datetime] NOT NULL |
Its primary key is defined using [ApplicationName] and [ParamName] columns. You will find the code for this stored procedure in the Downloads section at the end of this article.
This table comes with a stored procedure called Common.getApplicationParam that will return the value for a given application parameter. The code to create this stored procedure will also be attached to this article.
Now we have a place to store the information, it’s time to define how this information will be stored. This, once again, will be pretty simple. We will actually define an application whose name is built based on two server properties which are:
- ServerName
- InstanceName
So, the value for ApplicationName column will be defined using following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
select @ApplicationName = CAST( SERVERPROPERTY('ServerName') AS VARCHAR(256)) + CASE WHEN SERVERPROPERTY('InstanceName') IS NULL THEN '' ELSE CHAR(92) /* backslash*/ + CAST( SERVERPROPERTY('InstanceName') AS VARCHAR(256)) END ; |
Storage of the information regarding software environment
The parameter corresponding to the software environment will be called “Environment”.
Now, we just need to insert a record in that table using following query template:
|
1 2 3 4 5 6 7 8 9 10 11 |
INSERT INTO Common.ApplicationParams ( ApplicationName, ParamName, ParamValue, DefaultValue, ValueCanBeNULL, isDepreciated, ParamDescription ) VALUES ( @ApplicationName, 'Environment','CHANGEME','CHANGEME', 0,0,'Defines the software environment in which this server is' ) |
Storage of the information regarding database exclusion list
We will simply use the same pattern as above but the value for ParamName column will be called “SystemDatabases” and the value of ParamValue column will be a comma separated list containing at least following databases:
- master
- msdb
- model
- tempdb
- <Your DBA Toolkit database>
Security concerns
There is an important thing to notice about this solution: it highly depends on the contents of Common.ApplicationParams table. One could modify this value without notifying you about this… For that reason, consider adding triggers that disallow the changes to these parameters or that keep track of any modification in that table, or both of them!
Design of the checkup stored procedure
In this section, we will use the Common.ApplicationParams and its records discussed above. We will call this stored procedure [Administration].[CheckRecoveryModelToEnvAdequation]. It will be able to run in 3 modes:
- Report – an interactive mode that sums up databases that do not comply to the rules we defined.
- Monitoring – designed to fail if any non-compliant database is found. Ideal for a SQL Server Agent Job with enabled notification when the job fails.
- Correct – finds the databases that do not comply with the rules we defined, tries to set enforce compliance and reports about its execution. This mode will need a parameter that allow user to set a default recovery model to use in case of non-conformity.
Note: We could also add other checks, like checking all databases uses CHECKSUM page verification, which we did using a parameter called @WithPageVerifyCheck.
In summary, here is the interface for our stored procedure:
|
1 2 3 4 5 6 7 8 9 |
ALTER PROCEDURE [Administration].[CheckRecoveryModelToEnvAdequation] ( @ExecutionMode VARCHAR(64) = 'REPORT', -- Possible values: REPORT, MONITORING, CORRECT @WithPageVerifyCheck BIT = 1, @DefaultRecoveryMode4Production VARCHAR(256) = 'FULL', @Debug SMALLINT = 0 ) |
Its algorithm is pretty straight forwards:
- Check parameters are valid
- Get back environment related information from Common.ApplicationParams table
-
Transform the comma-separated value for SystemDatabases parameter to a string that can be used in a dynamic T-SQL query
This means:- Adding leading simple quote
- Replacing any occurrence of comma character to escaped ‘,’
- Adding trailing simple quote
- Create a temporary table #dbs
- Build a dynamic T-SQL query that stores into #dbs temporary table
- Run this dynamic query
-
Take appropriate action depending on the value for @ExecutionMode parameter
- If ‘MONITORING’ -> Fail if #dbs table has records
- If ‘REPORT’ -> Return records in #dbs table
- Else -> Loop on each record in #dbs table and try to solve the problem. Then show execution report
You will find below part of the code for the operation 7.c:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
WHILE (1 = 1) /* in order to simulate a DO … WHILE*/ BEGIN SET @CurrentDbName = NULL; SET @tsql = NULL; SET @CurOutcome = NULL; SELECT TOP 1 @CurrentDbName = DatabaseName, @tsql = CorrectiveStatement FROM #dbs WHERE CorrectionOutcome IS NULL ; IF(@CurrentDbName IS NULL) /* = Loop Condition */ BEGIN BREAK; END; BEGIN TRY EXEC @ExecRet = sp_executesql @tsql ; IF(@ExecRet <> 0) /* Check success*/ BEGIN RAISERROR('An error occurred …',12,1); END; SET @CurOutcome = 'SUCCESS'; END TRY BEGIN CATCH SELECT @ErrorNumber = ERROR_NUMBER(), @ErrorLine = ERROR_LINE(), @ErrorMessage = ERROR_MESSAGE(), @ErrorSeverity = ERROR_SEVERITY(), @ErrorState = ERROR_STATE() ; /* Keep track of error message in @LogMsg */ SET @CurOutcome = 'ERROR'; END CATCH ; /* To be able to get out of this infinite loop! */ UPDATE #dbs SET CorrectionOutcome = @CurOutcome, CorrectionLog = @LogMsg WHERE DatabaseName = @CurrentDbName ; END; |
The T-SQL code to create the [Administration].[CheckRecoveryModelToEnvAdequation] stored procedure can be found in the ZIP file attached at the end of this article.
Let’s run this stored procedure against a SQL Server instance which has one non-compliant database:
-
In REPORT mode:

-
In MONITORING mode:
-
In CORRECT mode:



Automating procedure execution
The [Administration].[CheckRecoveryModelToEnvAdequation] stored procedure won’t run without being called. We need a process that will call it regularly. To do so, we could create a PowerShell script that uses Invoke-SQLCmd commandlet and schedule it using Windows Tasks Scheduler… Or, we could create a SQL Server Job as SQL Server Agent is very handy!
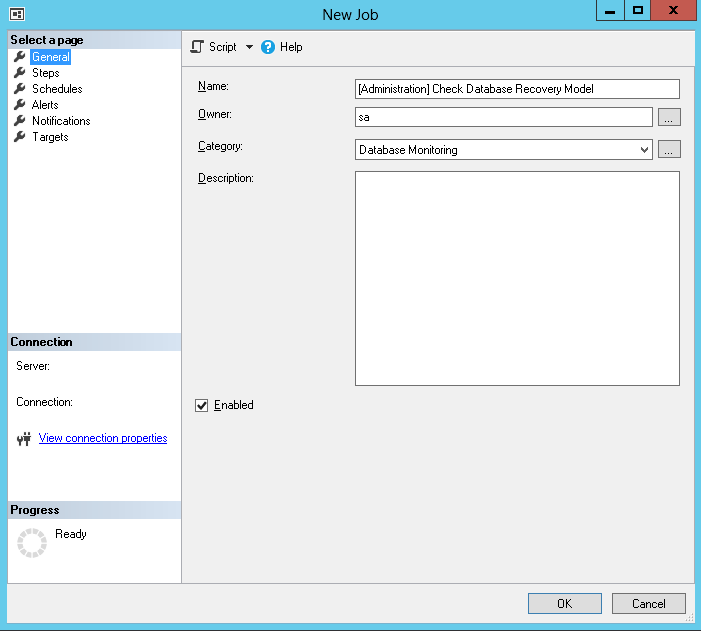
Here is the procedure for the creation of a SQL Server Agent Job called “[Administration] Check Database Recovery Model”.
Note: The following procedure assumes that a Database Mail Operator “The DBA Team” has already In SQL Server Management Studio (SSMS), connect to a SQL Server instance.
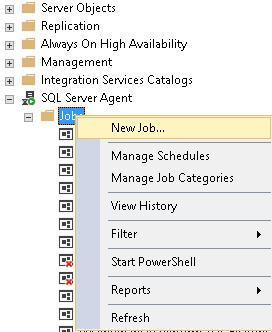
- Go down to SQL Server Agent Node and expend it.
-
Right-click on Jobs node and select New Job.
-
This opens a New Job dialog. Fill in the General step then go to the Page step.
-
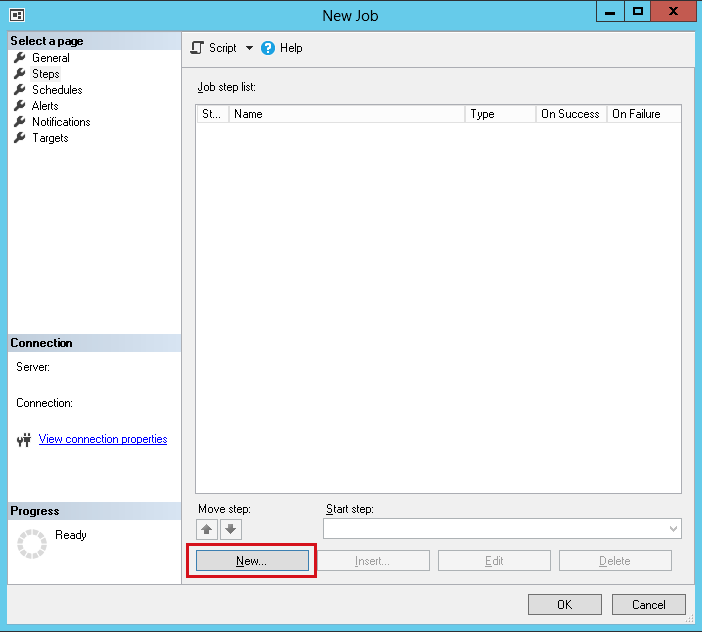
Click on the New button at the bottom. It will open a dialog called New Job Step.
-
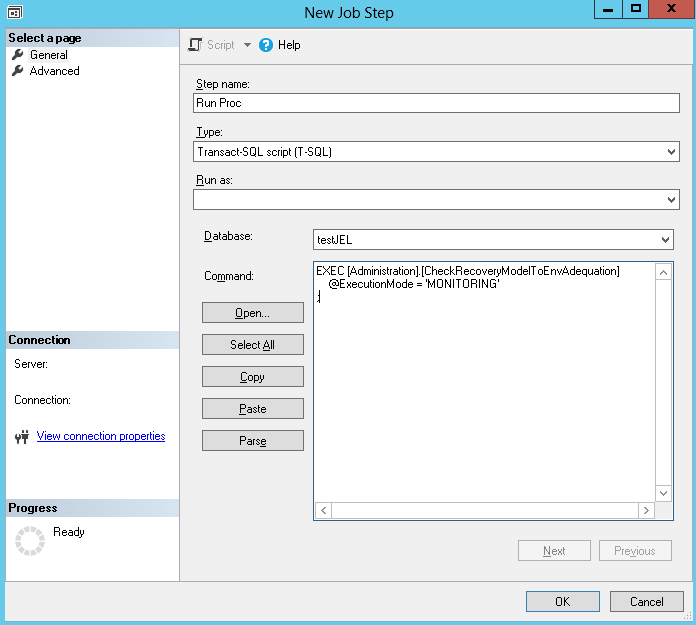
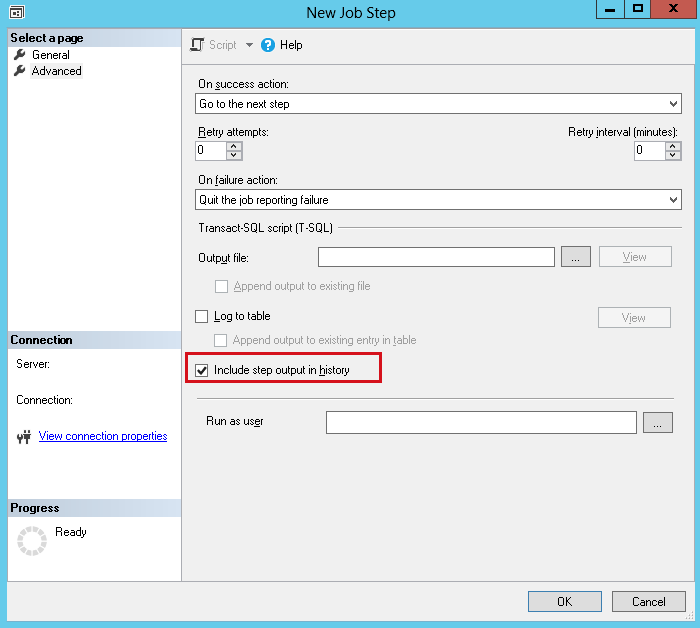
Fill in the General step as follows and go to the “Advanced” page.
-
Select the “Include step output in history” checkbox then click on the “OK” button.
-
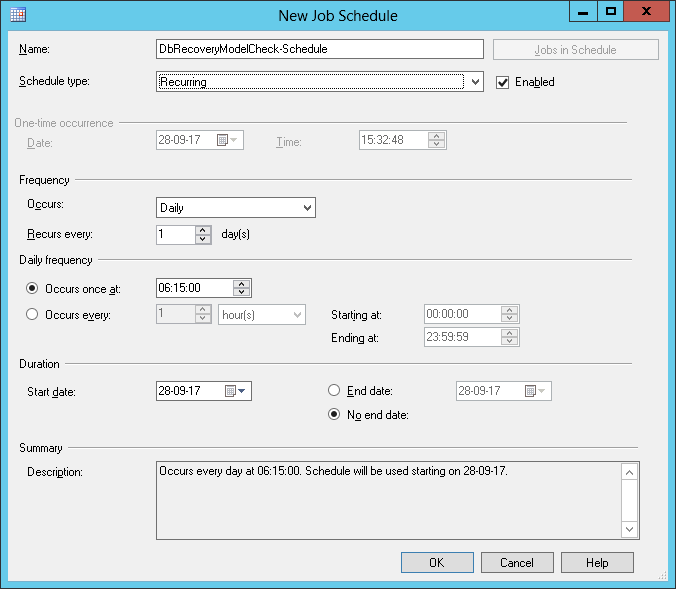
Create a dedicated schedule. Choose to preferably run it once a day. For instance:a.
-
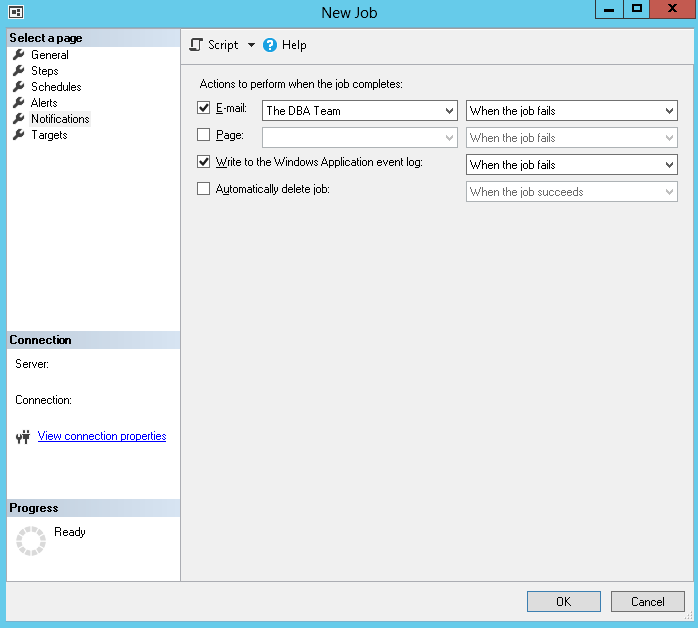
The most important part now, set the job to notify a Database Mail operator when it fails:
- Click on the OK button and the job is created.
- Test Job Execution
Downloads
You’ll find all resources to implement this check on your SQL Server boxes using following link:
In order to install it, open scripts one by one following ascending numbering (from 01 to 06). Be aware that the sixth file requires manual intervention for you to define both server environment and databases that should be ignored.
References
- Recovery Models (SQL Server)
- How to: Create a Job (SQL Server Management Studio)
- SERVERPROPERTY (Transact-SQL)

I'm one of the rare guys out there who started to work as a DBA immediately after his graduation. So, I work at the university hospital of Liege since 2011. Initially involved in Oracle Database administration (which are still under my charge), I had the opportunity to learn and manage SQL Server instances in 2013. Since 2013, I've learned a lot about SQL Server in administration and development.
I like the job of DBA because you need to have a general knowledge in every field of IT. That's the reason why I won't stop learning (and share) the products of my learnings.
View all posts by Jefferson Elias
- How to perform a performance test against a SQL Server instance - September 14, 2018
- Concurrency problems – theory and experimentation in SQL Server - July 24, 2018
- How to link two SQL Server instances with Kerberos - July 5, 2018