
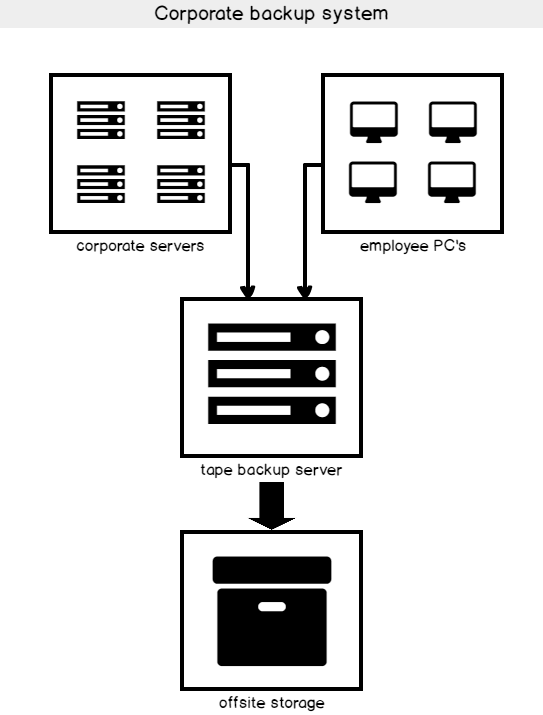
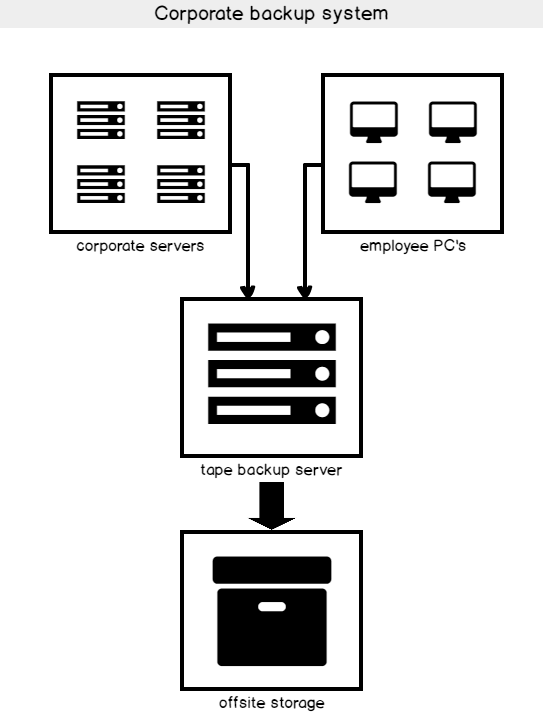
The methodology or paradigm, related to SQL Server disaster recovery has definitely changed in recent years. In the past, database administrators were just hopeful if they had any backup at all. Nowadays software is more complicated, and there are more integrated moving parts involved.
Disasters can be caused by power outages or natural disasters such as earthquakes, flooding, or tornadoes. Disasters can also be human-made such as a computer virus and hacking or even human errors or simply server failure.
There are two types of disaster. One involves pure manual error. The other type of disaster is when the physical hardware is actually affected or damaged because of natural disaster or fire. The manual error would require reverting the entire database or specific tables within the database back to a specific point in time depending on the severity of the error.
The ability to recover from human error has little to do with actual periodic backups taken and more to do with the transactional log, which is enabled in full recovery mode. If companies have full recovery mode enabled, they can restore from the transactional logs up to a specific point in time.
From an organizational standpoint, the employee in charge of the disaster recovery plan could be database administrator or a dev ops engineer. The employee could also specifically have the title of disaster recovery specialist and have that be their sole job description and focus.
Disaster recovery paradigms usually involve five to seven levels that outline the degree of data recovery that is possible. Level zero usually means that there is no off-site data backup and recovery might not even be possible. The highest level involves having an automated failover with little or no data loss. If individual servers in the cluster are unavailable due to maintenance or patching, the database will be available because other servers in the instance will acquire the traffic.
A lot of money is budgeted for disaster recovery plans in order to prevent bigger losses later on. It’s necessary for corporations, including disaster recovery specialists, to identify what applications or systems need to be protected. Usually, these applications are revenue generating ones while secondary applications don’t need to be included in business contingency requirements. A disaster plan per database or application is desirable.
The reason the recovery plan is more important now is that, in the event of a full disaster, companies need to get their business applications up and running as quickly as possible and with as minimal manual effort as possible. Delays here can be very costly for corporations. The old adage time is money definitely applies in these cases, and longer downtime usually means bigger losses.
Typically, the safest place for data backups is offsite at a different location than where the main data is stored. The overall goal is business continuity. Depending on the nature of their business, companies’ level of business continuity will vary. Business continuity involves the goal of having little or no interruption.
Why geography matters when it comes to SQL Server disaster recovery
Global companies often take advantage of different geographic regions in their disaster recovery plan. US companies have other considerations to take into account. When data is stored offsite in potentially a different country there may be specific legal issues that need to be taken into consideration. This should be addressed before database administrators pick the remote location where data backups will be stored.
Companies would not want to send any data to a country that might result in issues. If a company is in the US and they have a backup in Japan, the US government might not care much. However, storing a backup in a country where diplomatic relations are not quite as cordial such as China might present a different legal qualm.
It’s not advisable for a company to have all their SQL Server database instances physically located in the same geographic location. Some companies mistakenly isolate their SQL Server database instances to one geographic location because it simplifies implementation initially. Plus, the associated costs of data transfer fees can be prohibitive.
Just a few years ago, a major cloud provider had a complete outage for one region for multiple days. Customers of this cloud provider that had implemented databases in multiple regions were effectively able to continue their operations are usual. Companies that had relied on only one geographic region in their database architecture had to wait for this cloud provider to restore access in the affected region.
Disaster planning involves understanding the two main objectives of data recovery: recovery point objective and recovery time objective. Recovery point objective refers to the space of time between the last backup and the point in time when the outage occurred. Recovery time objective refers to the absolute latest length of time that a company can go with their system being down. Database administrators need to keep these fundamental concepts in mind when devising a disaster recovery plan.
There are two primary ways to implement SQL Server disaster planning:
- active/passive
-
active/active
Active/Passive
In the active/passive model, the data is mirrored but a database administrator would have to break the database mirroring and failover the database to the passive database cluster.
Active/Active
In the active/active model, the data is also mirrored AND available on all servers. For active/active, SQL Server AlwaysOn is a necessary setting. If using AlwaysOn, database administrators will create what is called a virtual listener IP that their applications will point to.
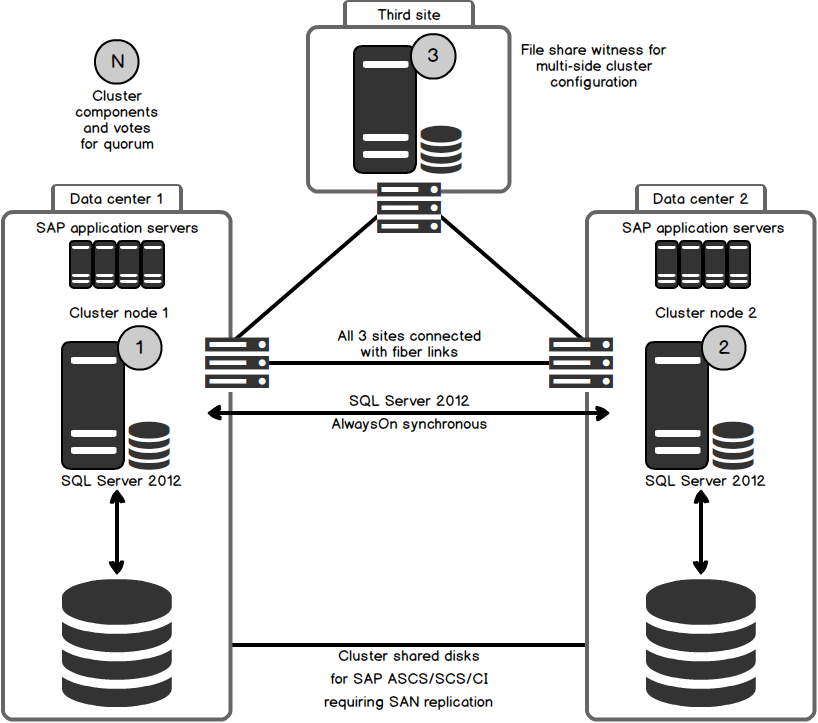
The availability features that are part of SQL Server do not eliminate the need to have a well-rehearsed disaster recovery plan in place. Using AlwaysOn is not a substitute for a well thought-out, well-planned disaster recovery process.
SQL Server disaster recovery rehearsal
The key to successful disaster recovery is that companies need to do a planned disaster recovery rehearsal. It is a best practice to have a disaster recovery plan that specifies how often companies want to conduct a rehearsal. In corporations with multiple applications that are business critical, dress rehearsals occur more often because they will need to do one rehearsal for each database or application.

Writing is her hobby. She enjoys finding a solution to a difficult problem and then sharing that solution through her writing.
View all posts by Kandi Humpf
- A high level look at SQL Server disaster recovery planning - February 5, 2018