
When I configured my first Always-On Availability Group, I setup a Windows Cluster and started with SQL Server Management Studio’s New Availability Group Wizard, scripting out the steps along the way. This entire process took only a matter of minutes. The minimum required steps for configuring the cluster and getting a database into an Availability Group (AG) are very few. This process, however, is deceptively simple. What some don’t realize is that the majority of work required for setting up an AG needs to occur in the planning phase, before a server is even requisitioned. Let us examine the questions that you should ask before implementing an AG.
How will you connect to SQL Server?
When it comes to fail-over technologies, one critical aspect is how you will connect to the database instance after the fail-over occurs. Whether it is the application configurations, DNS aliasing, or cluster resources, something must identify where to route new connections. When using an Availability Group you may choose to handle this routing separate from SQL Server or manually reconfigure connection strings, but that is not necessary. The AG Listener is a wonderful tool for connection routing that is fail-over aware.
- Here is a quick overview of the feature.
- Here is a detailed breakdown of the MultiSubnetFailover and ApplicationIntent parameters.
- Here are procedures for connecting with SQL Server Management Studio.
The concern with this feature is that, in many architectures, you need the use of the MultiSubnetFailover and / or ApplicationIntent parameters. Unfortunately, these parameters are not supported with certain drivers, such as, OLEDB and the .NET framework versions below 3.5 with SP1 missing hotfix KB2654347 . See this blog post for more details. There is also additional connection overhead, if you are using ApplicationIntent for read-only routing.
| Provider | Multi-Subnet Failover | ApplicationIntent | Read-Only Routing |
| SQL Naïve Client 11.0 ODBC | Yes | Yes | Yes |
| SQL Native Client 11.0 OLEDB | No | Yes | Yes |
| ADO.NET w/ .NET Fx 4.0 Up. 4.0.3 | Yes | Yes | Yes |
| ADO.NET with .NET Fx 3.5 | No | Yes | Yes |
| Microsoft JDBC 4.0 for SQL Server | Yes | Yes | Yes |
Can you off-load your reads?
Availability Groups allow you to off-load some reads to secondary replicas, but can you use this feature? The first concern has already been mentioned above. Are your clients using drivers that support the ApplicationIntent parameter? Often the core of a system is easy enough to identify. Your application might be written with .NET 4.0 or later but the investigation cannot end there. Integration points, both current and future, must be considered. For example, at the time of publishing, this article OLEDB is still a commonly used driver for SQL Server connections from SQL Server Integration Service packages. If ETL processes are going to induce heavy read loads on your server, it is ideal to have them read from a secondary replica. Driver usage must be considered for these auxiliary connections.
The second aspect to consider is whether your application and processes are designed in a manner which can take advantage of the read operation off-loading. Taking advantage of off-loaded reads requires the ApplicationIntent parameter which means that a separate connection string must be used. In addition to the connection string, your transactions will behave differently.
As per MSDN , “read-only workloads for disk-based tables use row versioning to remove blocking contention on the secondary databases. All queries that run against the secondary databases are automatically mapped to snapshot isolation transaction level, even when other transaction isolation levels are explicitly set. Also, all locking hints are ignored. This eliminates reader/writer contention.”
With the mandate of snapshot isolation being used on your secondary replicas, it is critical that the business, and the application doing the reads, are OK with the potential for phantom inserts and transactions which do not guarantee repeatable reads.
Can you off-load your backups?
The idea of off-loading your backups to a secondary replica is particularly enticing. When I first heard about this feature I was already spending server resources in my mind to get backup times reduced. However, there are a couple of very important caveats with backup off-loading.
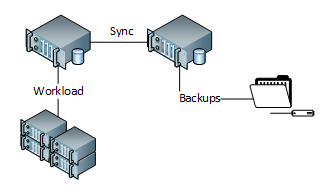
The most disappointing caveat is that only COPY_ONLY full backups are allowed on the secondary replicas. See Microsoft’s explanation here . The reason for this is that writes cannot occur on the read-only replica. This means that the log chain can’t be impacted and the differential bitmap cannot be cleared. This spoils backup off-loading for me because your full backups are likely to be your most resource intense, run the longest, and are required for point-in-time recovery and for the ability to append differential and/or log backups. The final caveat is that differential backups cannot be taken on secondary replicas, leaving us with only log backups which can be taken in a normal manner.
How will you manage server objects?
Availability Groups establish mirroring which is scoped to the database. If you are using contained databases and do not use the SQL Agent, linked servers, credentials, proxies, or any other server level object, then jump down to the next question. For the rest of us, these server objects are important and must be synchronized between the replicas manually. This can be a management challenge if not planned well.
One company that I worked with was using SSDT database projects for deployment. What we ended up doing was creating a PowerShell script which first deployed a T-SQL script to all nodes which included all of the server object creation statements wrapped in a large number of IF NOT EXISTS and DROP / CREATE statements. Then the dacpac would deploy to the primary node since all of the server dependencies had just been created. However it gets accomplished, it is a process which you will have to establish yourself and it is required. The last thing that you want is for an automatic fail-over to occur and you learn that the secondary replica didn’t have your service account logins on it. Suddenly the illusion of high-availability disappears.
Is my secondary the same as my primary?
Your secondary replicas are transactionally consistent (exact copies) of the primary. But exact might not be as exact as you think. Take the asynchronous commit mode for a moment. This mode means that the transactions will be asynchronously sent from the primary replica to all secondary replicas. At any given moment, your secondary replicas might be different due to latency. When it is small, delay can be understood and easily accepted for most applications. However, a 1 second latency in data replication can play tricks on any application that is designed to perform reads and writes and is instructed to use two different replicas for these operations. This small difference between replicas can cause unintentional reprocessing of records. Process flow should be examined and not all read workloads should be pushed to a secondary replica.
Statistics stored in the database are technically identical to the primary as well. Statistics created on the primary will replicate over to the secondary replicas and all statistic maintenance will have to occur on the primary. However, it is best practice to allow auto update and auto creation of statistics based on the queries that a SQL Server instance receives. If the secondary replicas could not create statistics, then performance of read-only workloads could suffer or you would have to spend additional time manually identifying missing statistics and creating them. To mitigate this issue, SQL Server will create statistics in tempdb.
As per MSDN , “the secondary replica creates and maintains temporary statistics for secondary databases in tempdb. The suffix _readonly_database_statistic is appended to the name of temporary statistics to differentiate them from the permanent statistics that are persisted from the primary database.” This behavior can put your system into a condition where statistics are different on each secondary replica which can complicate query performance tuning.
With tempdb statistics the database is still a mirror of the primary but its behavior may not be, hopefully for the better. Another slight difference that might occur is with the file structure of your database. As noted in, Troubleshooting a Failed Add-File Operation , all file operations executed with T-SQL on the primary will be replicated to the secondary replicas. These operations send over the literal file path that is used on the primary, without transformation. Therefore, if the file structures do not match between the replicas, then a synchronization failure occurs. This operation succeeds on the primary but the secondary’s failure stops data traveling to that replica, causes the primary to begin stock piling transaction log records, and must be re-initialized from backup or removed from the AG. When initializing an Availability Group replica with different file structures (including drive letter) you will need to utilize the RESTORE command’s MOVE clause and follow the procedures for Manually Prepare a Secondary Database for an Availability Group (SQL Server). I highly recommend avoiding this problem, if you can, by making sure the drive letters and folder structures match on all replicas of an AG.
Why do I need a cluster and how does that affect me?
A Windows Fail-over Cluster was not a requirement for Database Mirroring, the feature that serves as the foundation for Availability Groups. With AGs, a typical multi- data center architecture might look like this.
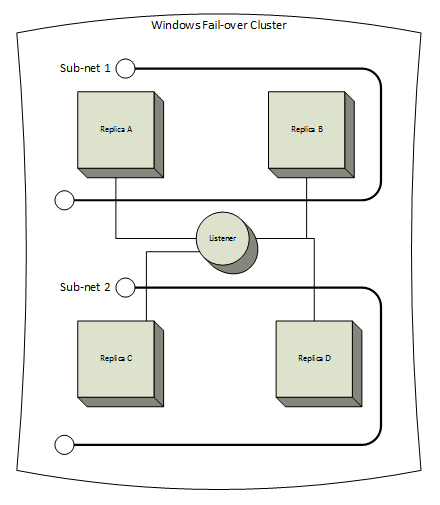
The most important aspect of this change in requirements is how you configure quorum. With Database Mirroring, your database was either available or not, and your witness either could communicate with the replicas or could not. Clustering provides advanced configurations for various servers, file shares, or disks to vote on who has quorum but also can be unforgiving. Misconfigured quorum can cause a complete cluster outage even when normal events take place. Using the example image above, this architecture crosses into two sub-nets because replicas A and B are in data center 1 and replicas C and D are in data center 2. If connectivity between the data centers is less than ideal, a minor blip in the connection could cause a loss of heartbeat singles. When quorum is configured correctly there will also be an odd number of votes still online but, if not planned out thoroughly, this normal event could cause the cluster service on all nodes to shut down. This is a safety feature designed to prevent a split-brain effect where two halves of the cluster each think that they are the real cluster.
The next consideration is operating system versions. Naturally, making sure that you can comply with supported versions is required. Windows Server 2008 and above all support AGs but, for versions below 2012, you will need to install service packs and hotfixes in order to move forward. See this table of prerequisites for more details. Also, with Database Mirroring, it is not a requirement that all OS’s match. With AGs you need a cluster, and with a cluster you need matching OSs. This, alone, might throw a wrench in your plans, but if it doesn’t, you still need to pre-plan your upgrade paths and make sure that you are OK with the limitations. At some point a new OS version will release and you will, eventually, want to upgrade. You should plan in advance how this can happen. Would you attempt in-place upgrades? I probably wouldn’t but there is still the choice between side-by-side installations with database migrations or Cross-cluster Migration of AlwaysOn Availability Groups for Operating System Upgrades .
Finally we come to a decision around data duplication and SQL Server Fail-over Cluster Instances (FCI). My preferred architecture for an AG is to have stand-alone instances using locally attached storage. In that case, the SQL Server services would not be a part of a cluster resource, only the AG and its listener. However, I have had clients who have very large databases (VLDB) and they do not want to spare the expense of having data duplicated within a single data center. In that case, a hybrid approach of AGs and FCIs can be configured so that shared storage is used within each datacenter but AG replication is used to synchronize the other data center. That architecture would look something like this
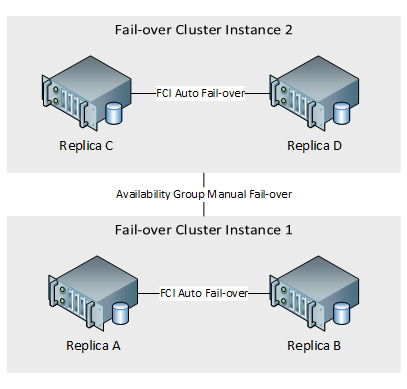
Using a hybrid approach of this type adds much complexity. Beyond the manageability of a more complicated architecture, AG automatic fail-over is not possible in this configuration. The only automatic fail-over that is supported will be at the instance level, performed by the FCI. This means that automatic fail-over cannot be configured to move different AGs from the same instance to separate instances. The whole instance will move. Another concern is that only a single instance with an AG can ever reside on a node of the cluster. To state it another way, if you have more than one instance in the cluster with an AG, then they must be configured to only move between nodes which are not possible owners of the other. To achieve automatic fail-over in a cluster with two FCIs, you will need a minimum of four nodes which might make a strong case for simply splitting them into two separate clusters to begin with.
Where to go from here
After asking all those questions, it is now clear that the T-SQL commands or the SSMS wizard to configure an Availability Group are only a small part of the process required to be successful with this technology. Building out an AG is about paying a man hour cost for planning up-front in exchange for long-term stability. When thought through thoroughly, AGs provide faster recovery times then log shipping, far less maintenance than replication, no dependency on shared storage unlike FCIs, and can fail-over database groups unlike Database Mirroring.
Use these questions and the issues addressed to augment your research and planning before implementing an Availability Group. Then you should do full tests in a non-production environment. This includes building out the full cluster and having some nodes at your disaster recovery site with fail-over tests under load.

Derik thanks our #sqlfamily for plugging the gaps in his knowledge over the years and actively continues the cycle of learning by sharing his knowledge with all and volunteering as a PASS User Group leader.
View all posts by Derik Hammer
- SQL query performance tuning tips for non-production environments - September 12, 2017
- Synchronizing SQL Server Instance Objects in an Availability Group - September 8, 2017
- Measuring Availability Group synchronization lag - August 9, 2016