
This article will show how to source data from Azure SQL Database into Azure Machine Learning.
Introduction
In a typical data life cycle, data is generated and stored in transactional systems or relational databases by front-end applications. This data makes its way to different repositories like master data management, data warehouses, data lakes, and eventually in operational reports. Reporting used to be typically considered the extreme end of the data life cycle with reporting tools as the end consumers of the data. With the rise of systems like machine learning and artificial intelligence, there is a need to provision data from operational data stores to these systems. Data scientists typically explore data from these systems to create a balanced dataset that is fed to the models built using machine learning systems. On the Azure platform, Azure SQL Database is one of the primary relational data stores that is employed to host operational data from transactional systems. Azure also provides services like Azure Machine Learning to build machine learning models. This service sources data from a variety of data repositories like Azure Data Lake Storage, Azure SQL Database, and others. In this article, we will learn sourcing data from SQL Database into Azure Machine Learning and we will explore the profile of the sourced data as well in Azure Machine Learning.
Pre-requisite
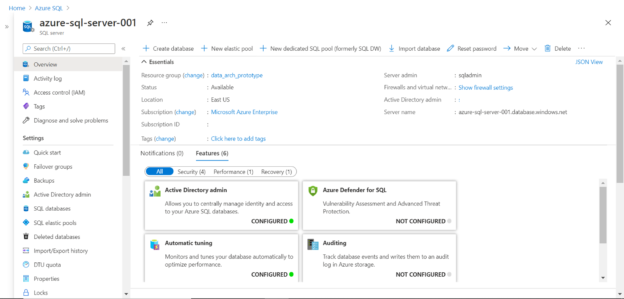
As we intend to source data from Azure SQL Database, the first thing we need in place is setting up an Azure SQL Server instance with some sample data in it. Navigate to Azure portal, search for Azure SQL, and create a new instance of Azure SQL Server. After the instance is set up, one can create Azure SQL Database which can be hosted on it. Once it is in place, the dashboard of the Azure SQL Server instance will look as shown below.
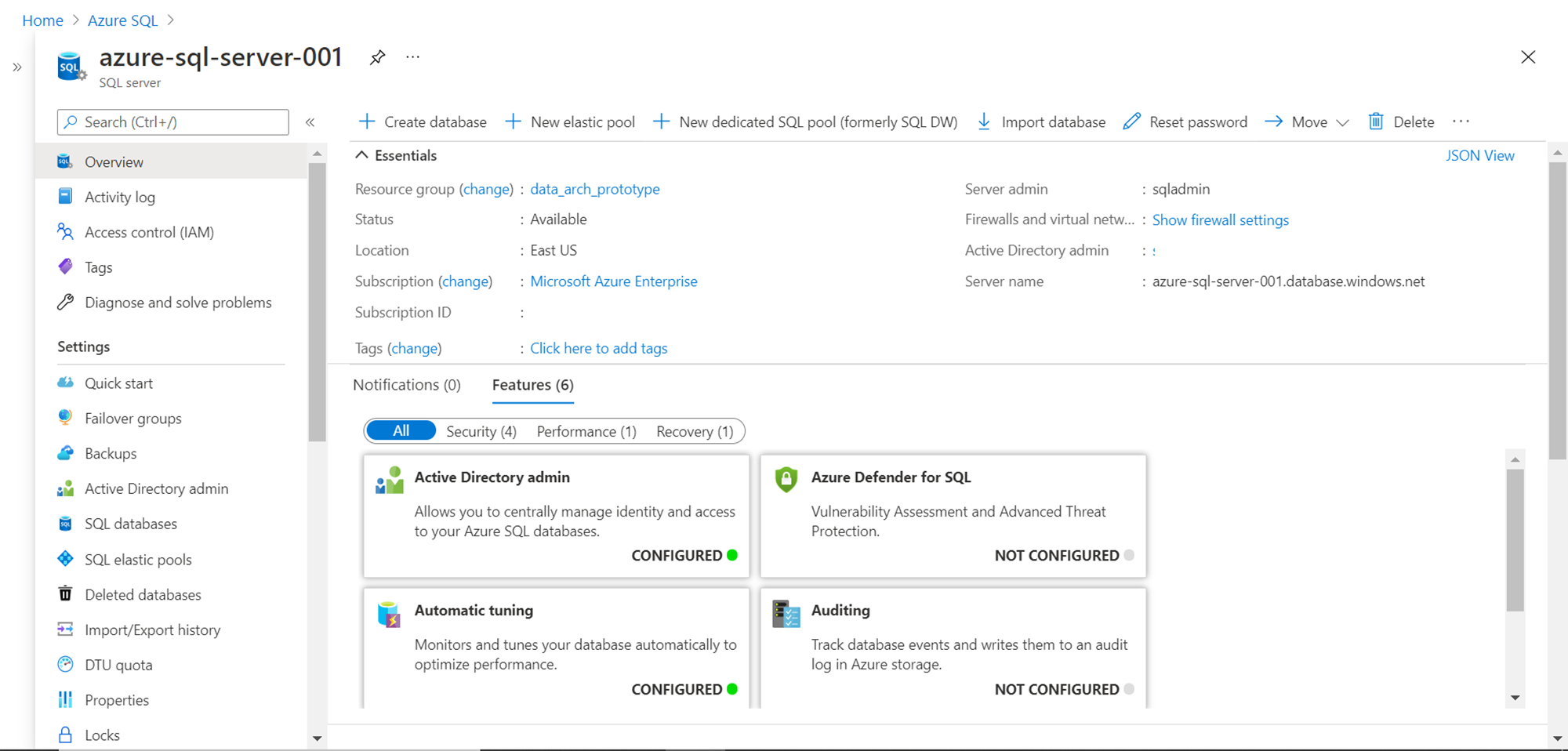
Once the server instance, as well as Azure SQL Database, is in place, the next step is to create Azure Machine Learning Workspace, so that using the same, we can access the machine learning studio, which allows us to configure the objects that let us consume the datasets hosted in SQL Database. Navigate to the Azure portal, search for Azure Machine Learning service, and create a new workspace from the dashboard page. Once the machine learning workspace is created, it looks as shown below.
Creating Azure SQL datastores and datasets in Azure Machine Learning
Now that we have the pre-requisites for this exercise in place, we can start the process of integrating Azure SQL with Azure Machine Learning. Click on the Launch Studio button from the Azure Machine Learning workspace, and a new screen and portal will open. On the Machine Learning Studio portal, click on the Datastores tab as shown below.
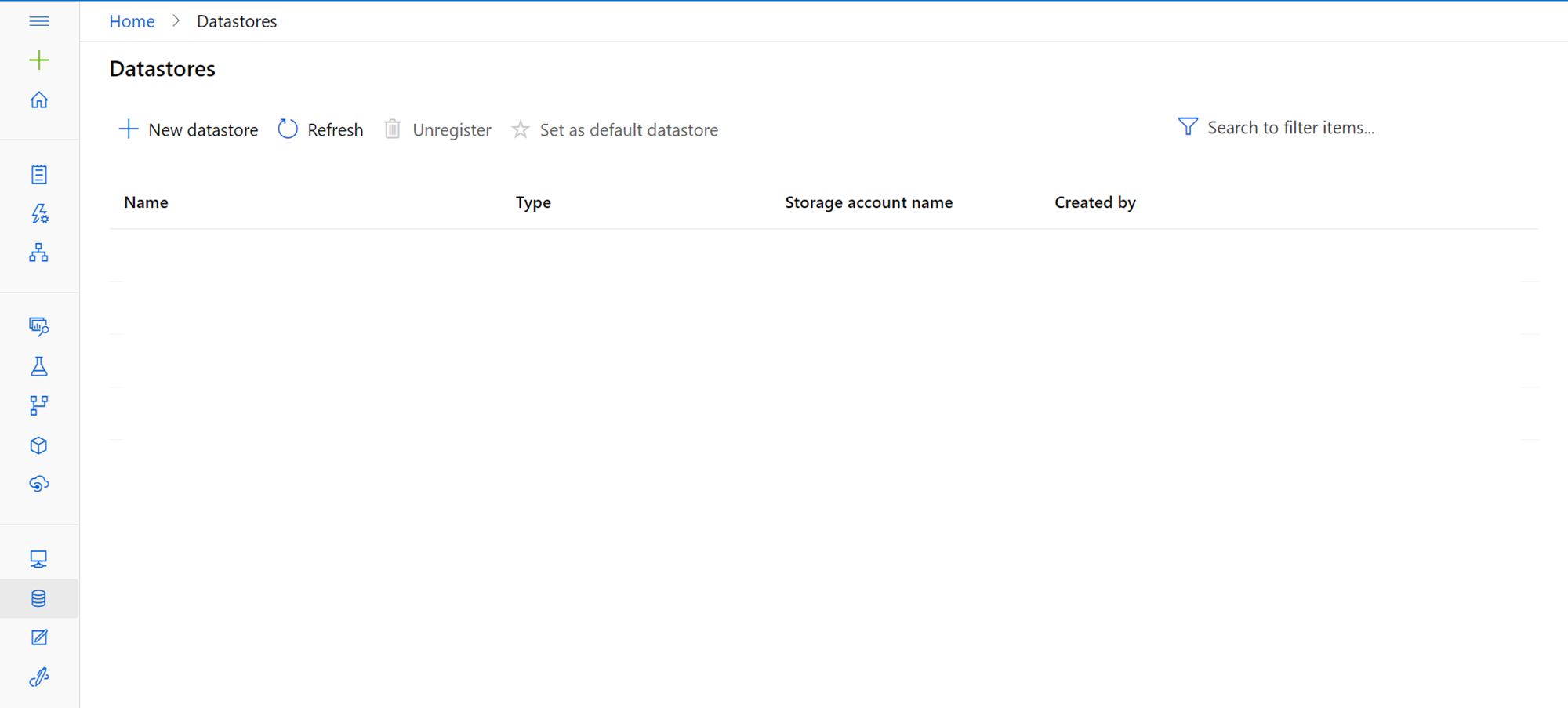
The first step toward sourcing data from Azure SQL Database is registering it as a data store in the machine learning studio. Click on the New datastore button and it will open a screen as shown below. Provide the name for the new datastore and expand the Datastore type drop-down to view the list of supported data stores which are – Azure Blob Storage, Azure file storage, Azure Data Lake Storage Gen 1, Azure Data Lake Storage Gen 2, Azure SQL Database, Azure PostgreSQL Database, and Azure MySQL Database. We intend to source data from SQL Database, so select the same.
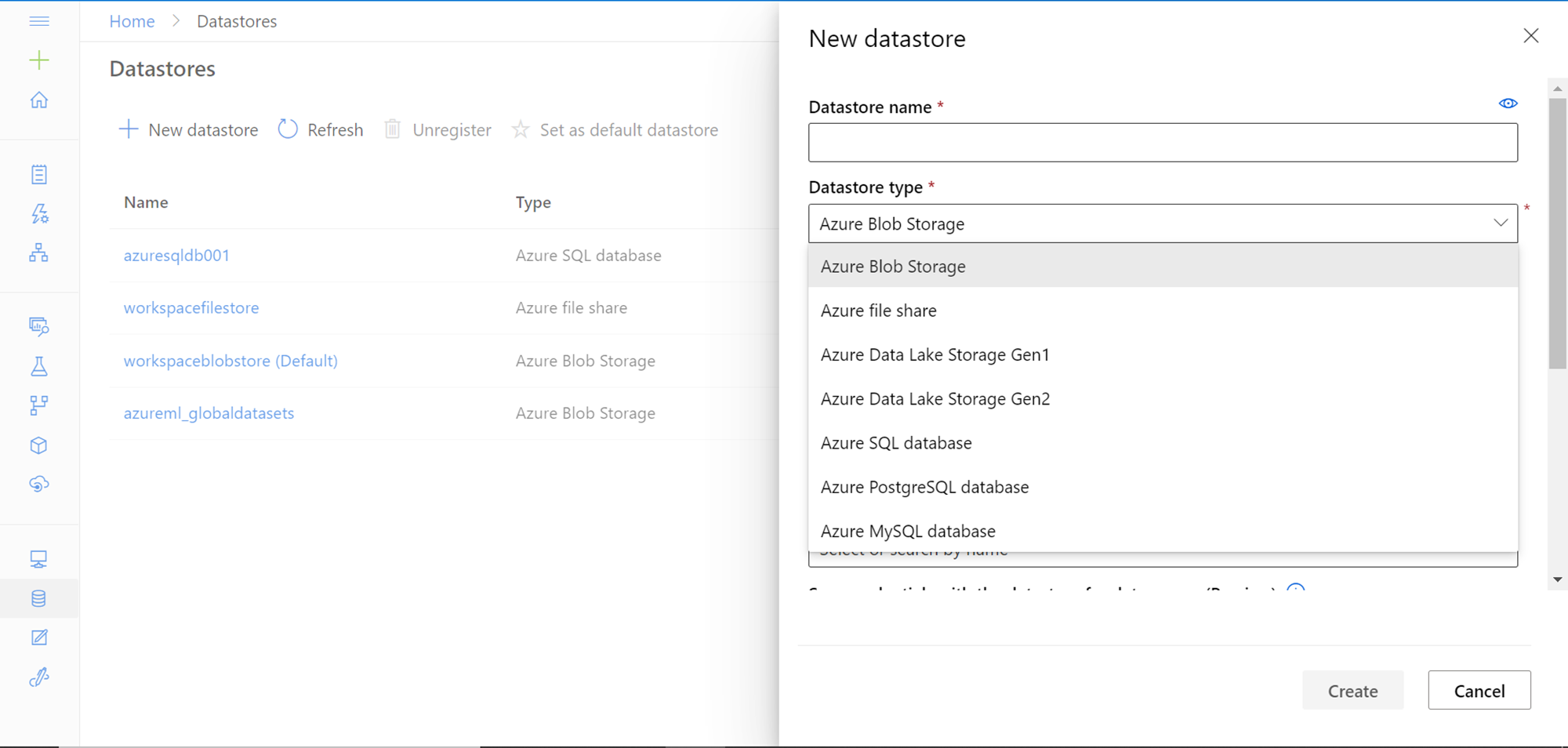
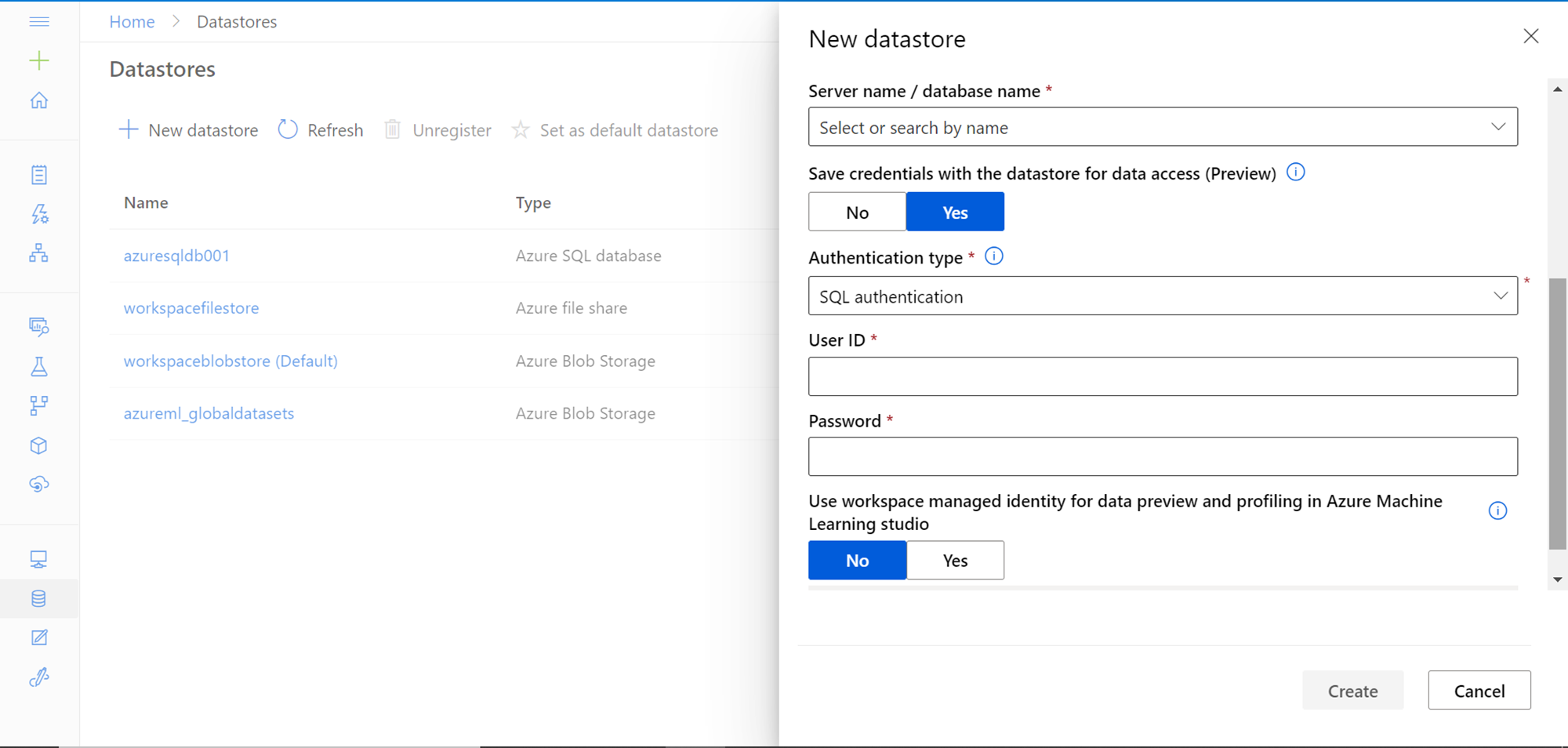
Next, we need to provide the authentication mechanism for connecting to the Azure SQL Database instance. By default, SQL Authentication would be selected. Provide the database credentials using which Azure Machine Learning can connect to this database. It’s recommended to not use the admin credentials and instead, use a service credential here. But for demonstration purposes, any credential that has the required access to the data will work.
By default, the “Use workspace managed identity for data preview and profiling in Azure Machine Learning studio” is set to “No”. In case, if we intend to use managed identity, we need to provide privileges to managed identity in the Azure SQL Database for connectivity. In that case, we won’t need to provide credentials here. Once these details are provided, click on the Create button and it would register the data store successfully.
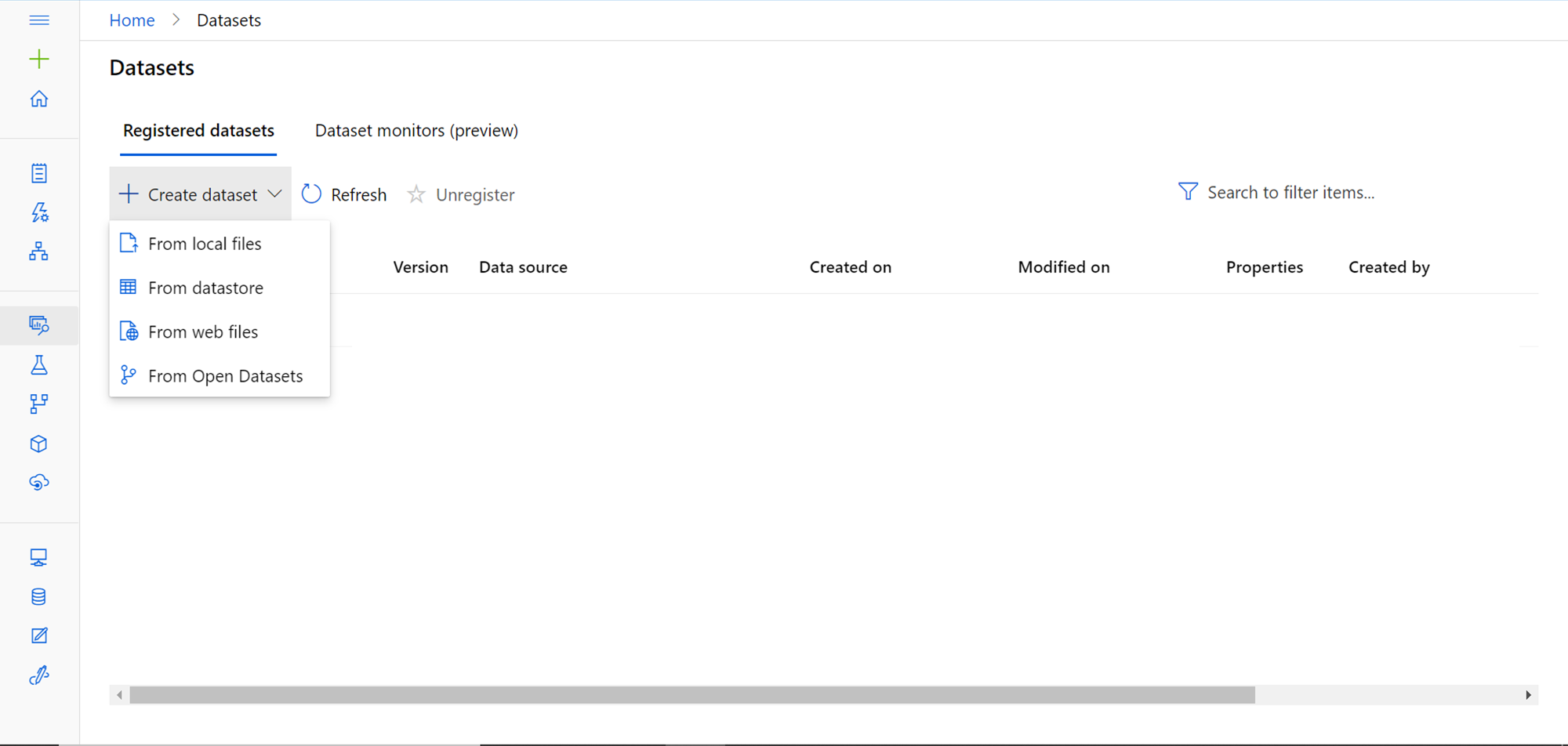
Once the datastore is created successfully, the next step is to create a Dataset using the newly registered datastore. Click on the Datasets tab, and it will look as shown below. As we do not have any registered datasets, click on the Create dataset button and it provides four options – From local files, From datastore, From web files, and From Open Datasets. We will select the “From Datastore option”.
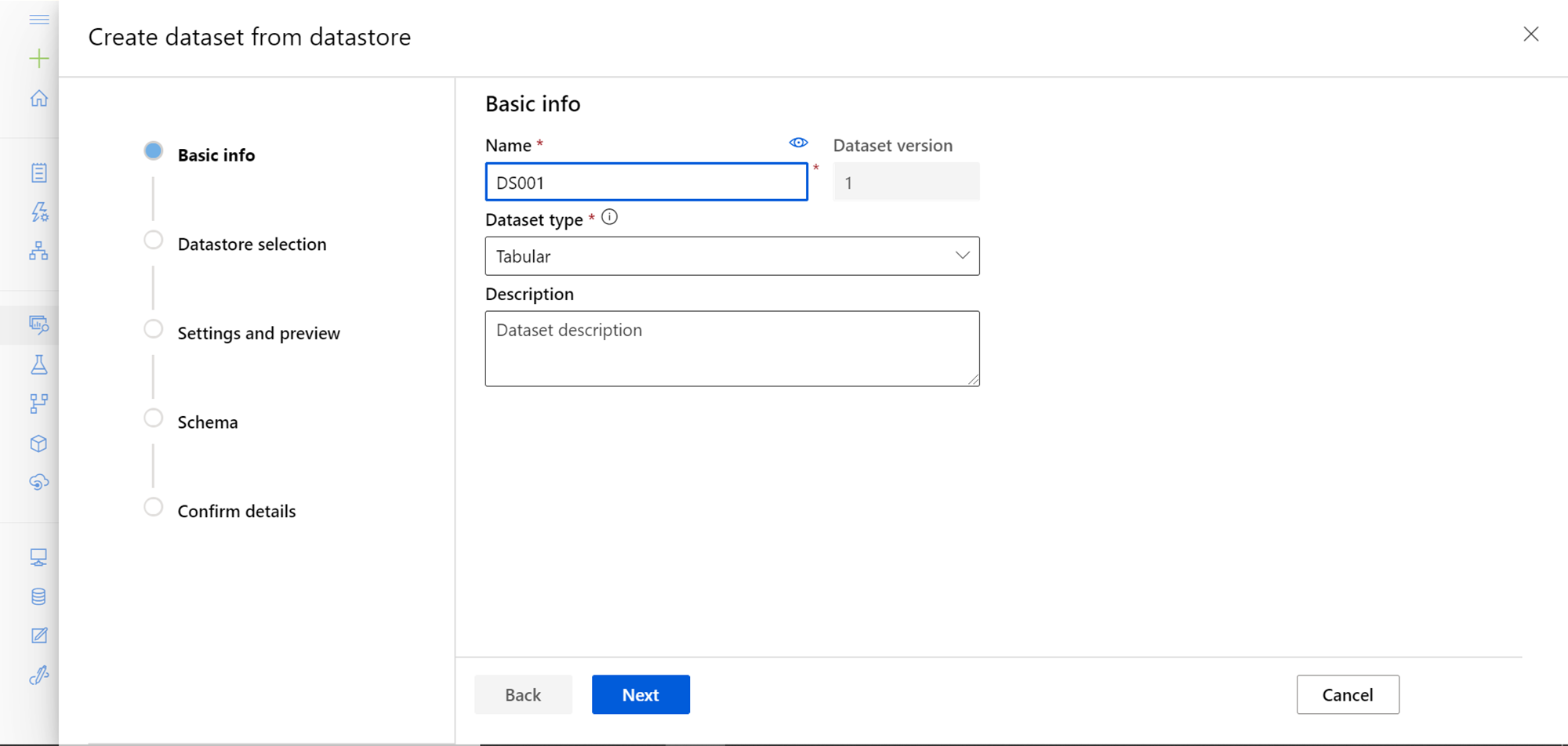
This will open a new wizard as shown below. The first step is to provide basic information like dataset name, dataset type and optionally a description. Two types of dataset types are supported – Tabular and file-based. As we are sourcing data from Azure SQL Database, we would continue with the default option i.e. Tabular.
The next step is datastore selection. As we have not selected any datastore, it will show that the currently selected datastore is None. In the second option, it would show the list of previously created datastore, which would also have the newly created datastore. Select the datastore that we created and click on the “Select datastore” button. There is an option to skip data validation, which will generally connect to the datastore to test the connectivity and data access. Generally, it’s not advisable to skip this data validation and it provides an opportunity to validate datastore access upfront during the configuration process itself.
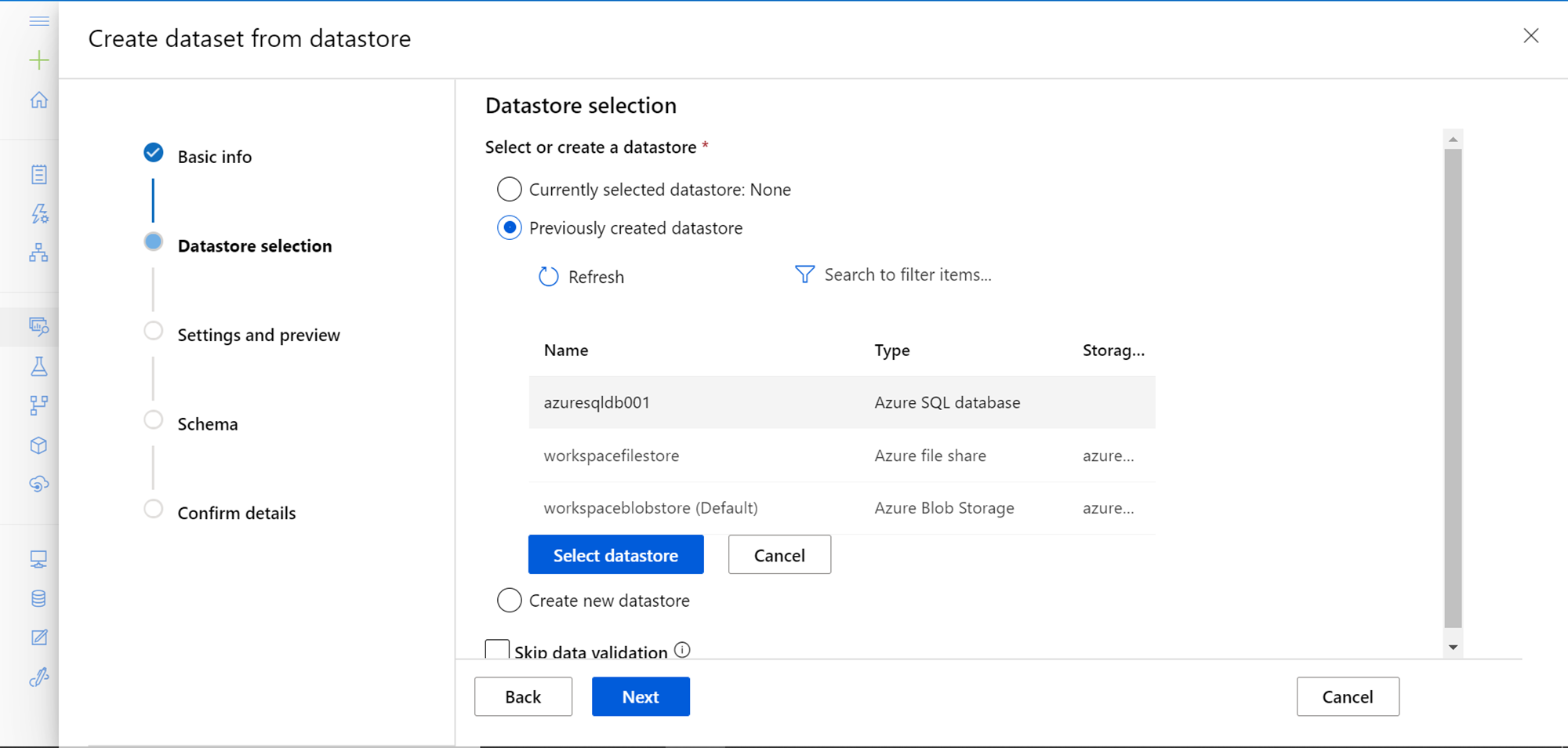
After selecting the data store, it will ask for the SQL Query that forms the dataset. This forms the scope of data and also provides a means to shape, filter, format, and do any other in-query processing on the data, to form a dataset that would be made available to the Azure Machine Learning service for immediate use.
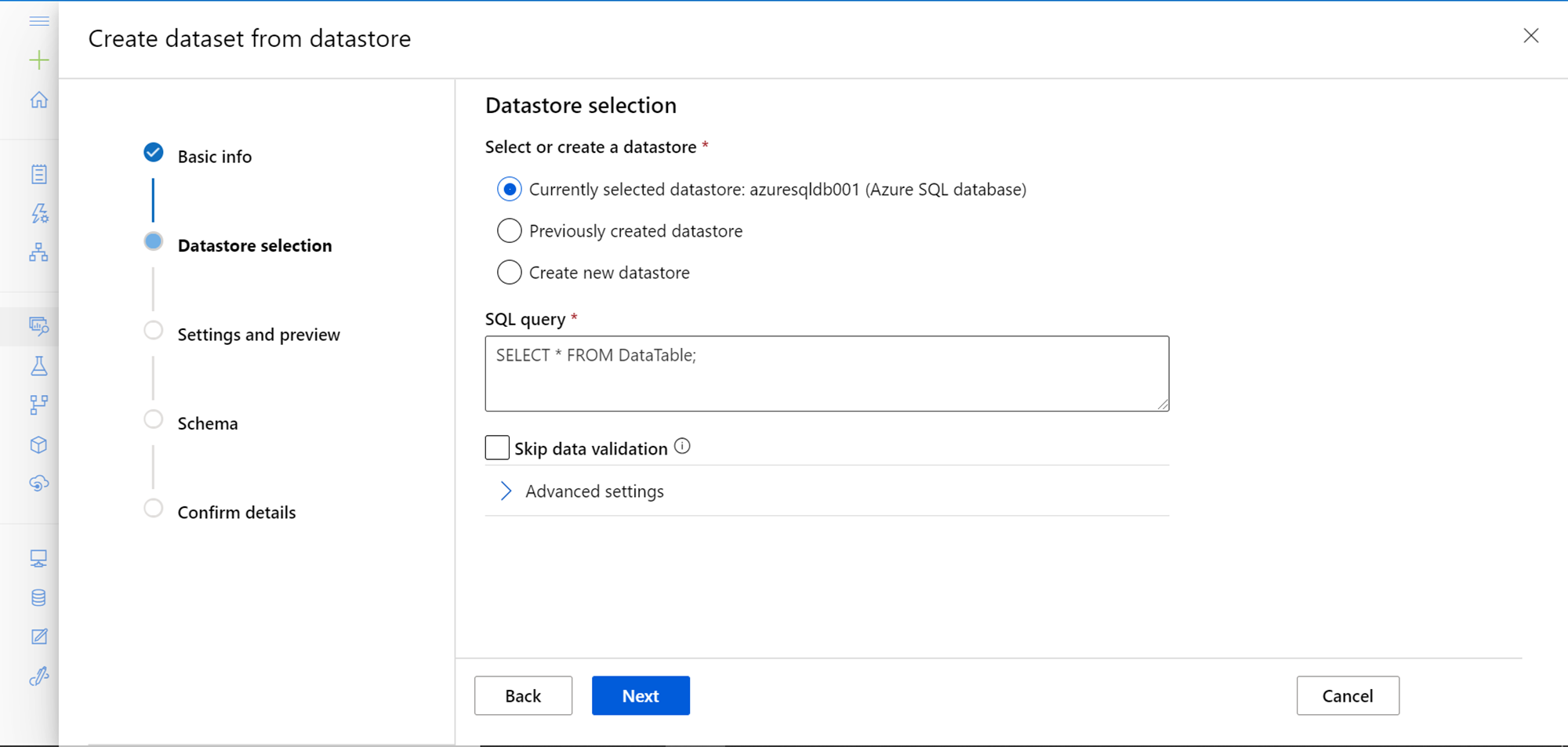
Once the query is provided, click on the Next button and it would show the preview of the data as shown below. A sample of data would be shown for preview, and the field names would have a label that shows whether the field is numeric or categorical. After reviewing the data and the field types, click on the Next button to move to the next step.
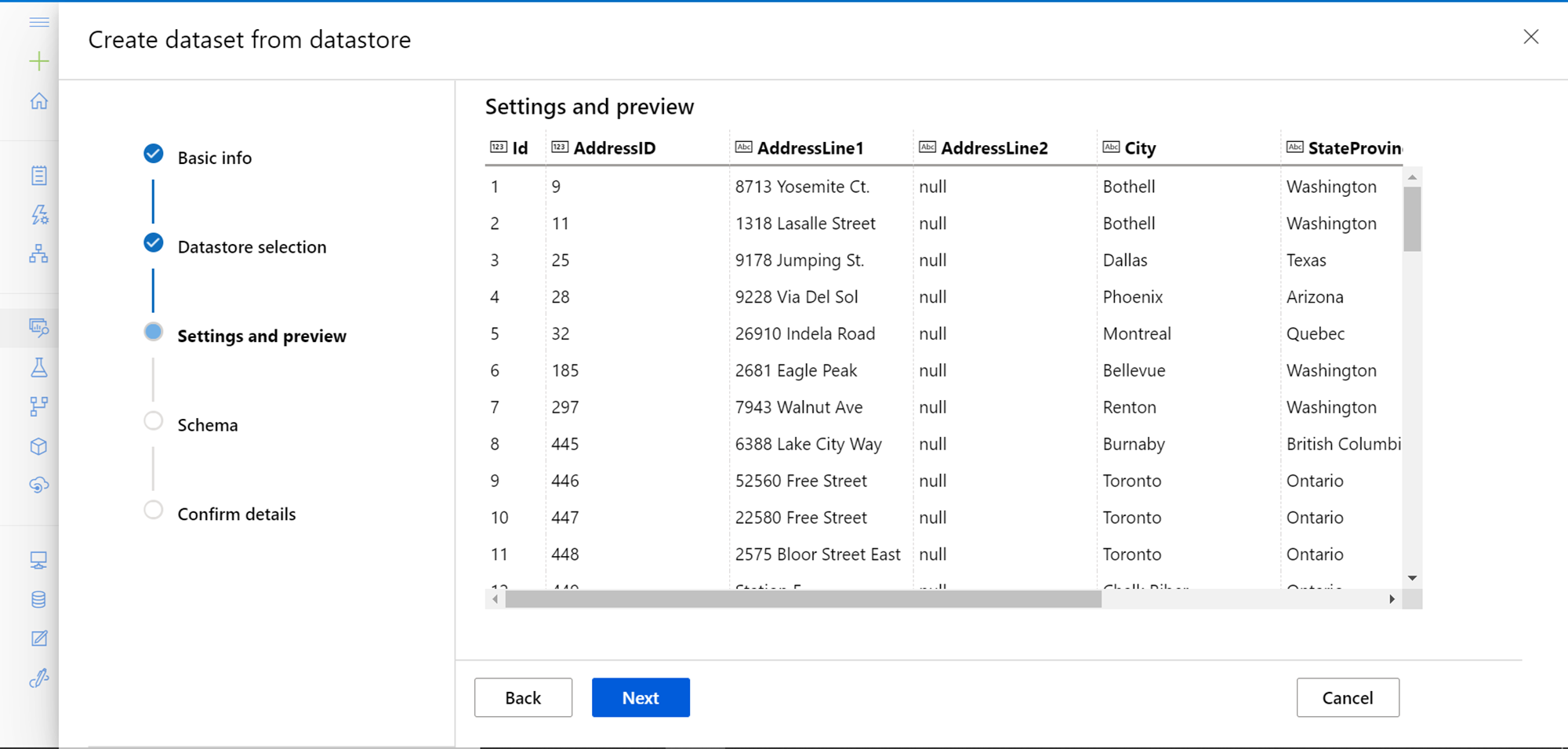
In the next step, we have the option to configure as well as modify the schema. As shown below, we have the option to include or exclude the fields from the schema. Then we can modify the data type of the schema as well. The properties and format settings are also shown on the same page. Here we are not able to modify the same as it’s not applicable in our case depending on the type of data and data object that we have selected. Configure the schema as per the requirement and then click on the Next button.
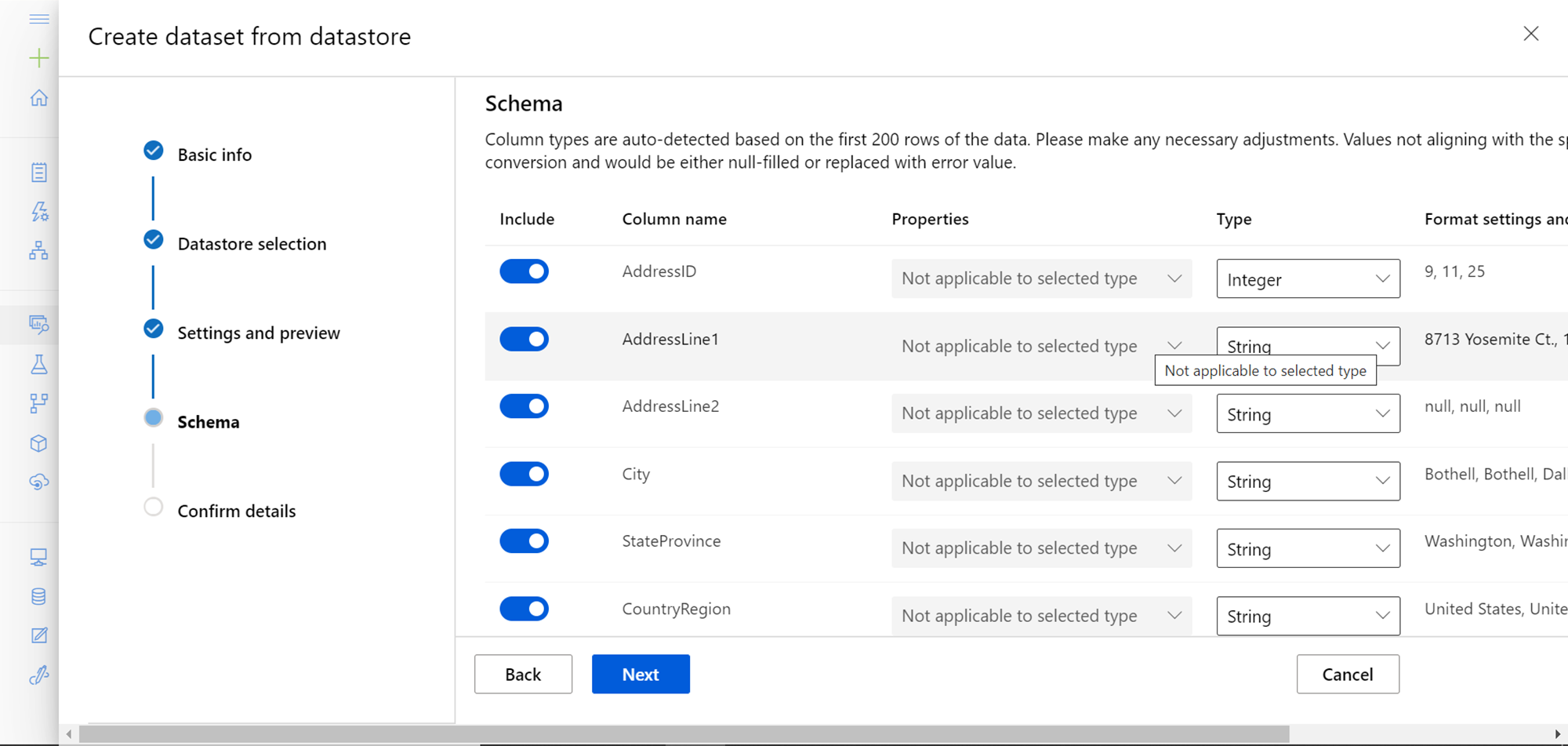
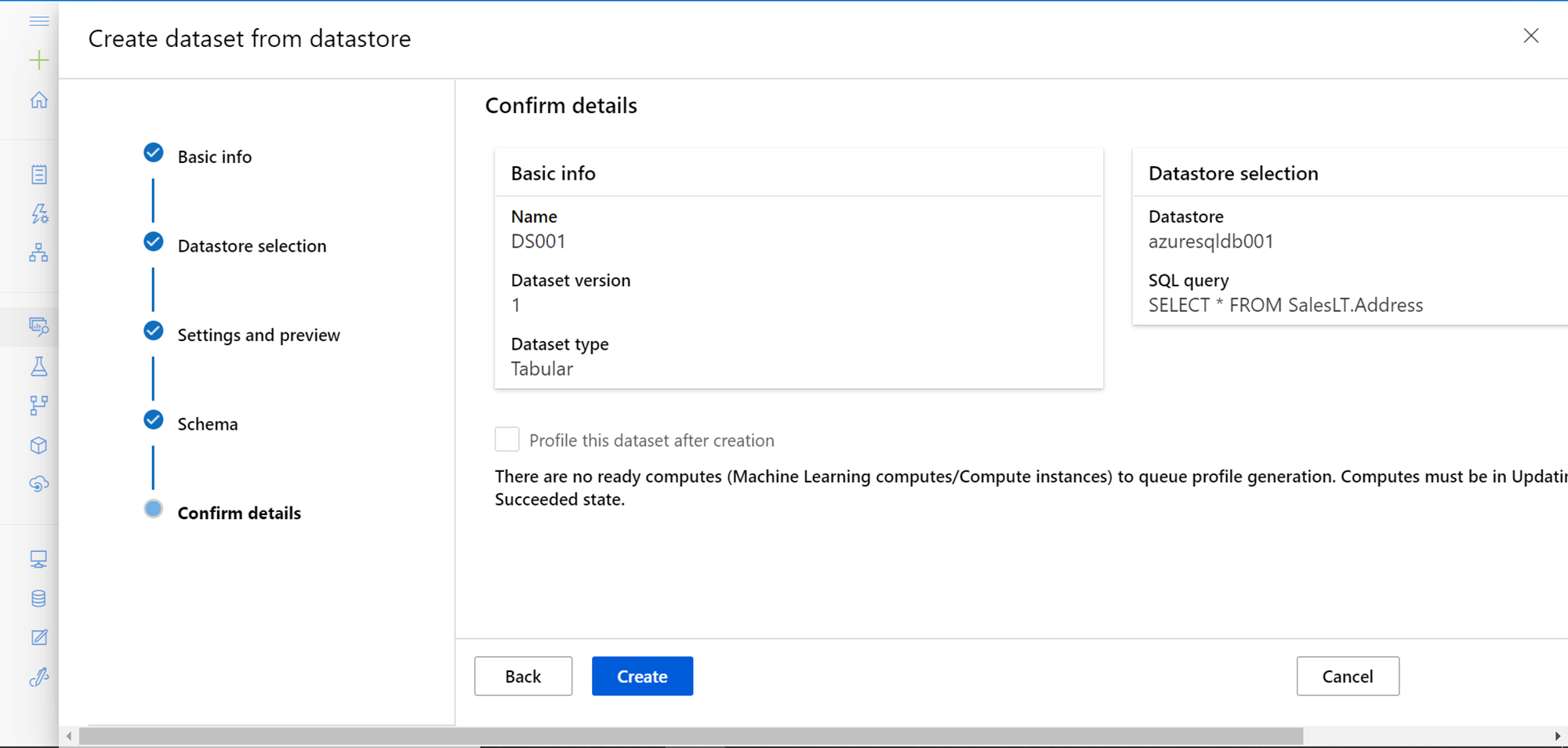
In the final step, we can confirm the details we have configured so far. Here we have the option to profile the data as well using the compute instances in Azure Machine Learning Studio. As we have not created any instances so far, this option is disabled. Click on the Create button to create the dataset.
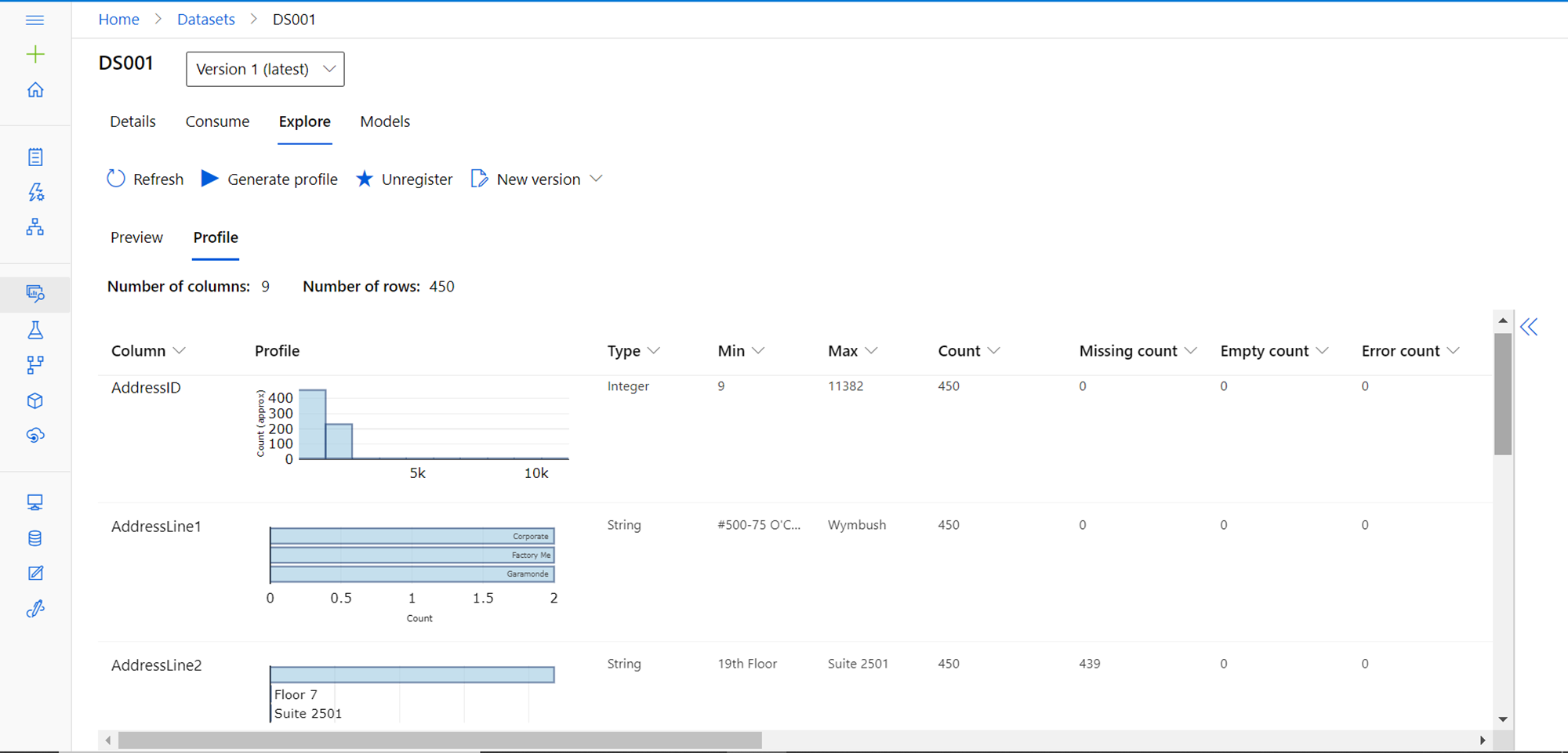
Once the dataset is created, we can explore the newly created dataset by clicking on the line item that shown the dataset. Once opened, it would show the details as shown below. It would provide basic details, the way to consume this dataset using various methods supported by Azure Machine Learning, Preview the data as and well as explore the data profile, as shown below. This data profile is created out-of-box and provides a quick way for a data scientist to explore the data before it’s consumed in the machine learning workflow.
In this way, we can create data stores and datasets from Azure SQL Database and source them in Azure Machine Learning for use in the Machine Learning Workflow.
Conclusion
In this article, we learned how to create an Azure Machine Learning workspace, register Azure SQL as a data store, create a curated dataset out of database objects hosted in Azure SQL Server instance, and explore the data profile of the registered datasets to finally use these datasets in the Machine Learning workflow.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023