
In continuation to our hybrid deployment series, we will check few more options in order to integrate on-premises and Azure, using of course SQL Server.
In the last article we talked about Azure Blob Storage and how to use this service to store a SQL Server database entirely there. Meaning that we can have our instance in our datacenter, see the server in front of you, and still have your database stored in the cloud, with your data and log files out of your disks.
As I said in the other article, this would be a good idea for databases with not too many concurrent sessions and/or not critical in the performance point of view. Remember that you will be working in a database that is mounted in the “local” server, but to access the data you will need to travel across the network/internet and this may bring a lot of small challenges, as you are adding the network connection between your instance and your files.
Looking to this feature as is, discourages a lot of people, however we can take advantage of this in another way… As soon as we can have files in the cloud the fun begins! So I will present two awesome options to make your environment really hybrid, providing a good service without spend much money.
Hybrid database as archival solution
The Hybrid Database Archival solution is nothing more than an old strategy under a new possibility: store database files in Azure! But what is this?
Well, let’s pretend that you have a very large database, with a lot of historical data and you want to get rid of this. But… yes, there’s always a but… The application owner said that this data needs to stay there for some special reason, even if not too much people is using it.
This old and ugly data is already causing problems, your disk is full, the performance is not acceptable as before, the backups are huge, etc… What to do here?
Normally in situations like that, the strategy is create a new Filegroup and either create a historical table, to move that old data, or implement partitioning in the table and send all the old data to the newly create Filegroup.
Let’s take the second option: Use table partitioning. The strategy will be create two partitions: Current Data and Historical Data. The partition with Current Data will be stored in SSD drives, with an excellent response time. In other hands the historical data will be stored in an old disk, with poor performance and lots of storage capacity – as the performance is not the goal here.
By implementing this we will be able to solve part of the problem: The performance and costs to maintain a good disk to store both current and old data. However there are other factors here:
- The backup is still huge
- The maintenance operations are still taking a lot of time
- The old disk may fail and compromise the database availability
About the backup and maintenance, we can workaround by adapting the backup plan and index maintenance to the new Filegorup strategy. There’s another option for this, but we will approach this more ahead.
What about the possible disk issues? Here is where I want to reach. We can use Azure for it. How? By simply creating a file stored in the Azure Blog Storage service. This way you will have part of your database on-premises and the historical data in the cloud. Like described in the following picture:

The concept is simple and is already used, but adapted to be a Hybrid solution. This way you will have the current data with the best performance and the old data will be store in Azure, with a not so good performance, but in a place where the cost per GB is very low, the allocated size limit is very high, the data is geo-replicated and there’s no physical disk to be maintained.
Looking to the table perspective, we will have the following:
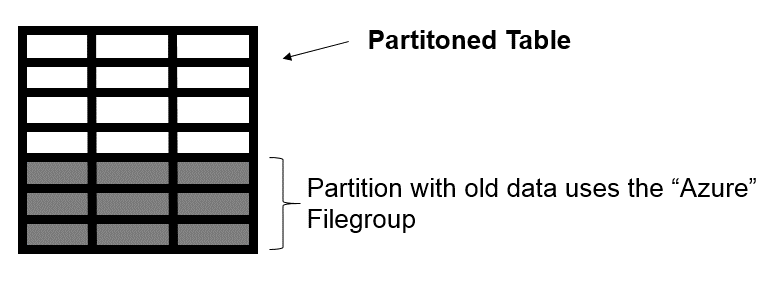
The white area represents the current data, in the partition where the respective files are stored on-premises. The gray area represents the historical data stored in a file in Azure Blob Storage.
We can easily replicate this scenario…First of all we need to make sure that the credentials are created, as explained in the previous article. Having this, we are good to go ahead and create the database with a file store in the cloud:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE DATABASE [HybridTableDemo] ON PRIMARY ( NAME = N'HybridTableDemo', filename = N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\HybridTableDemo.mdf' ), filegroup [FGAzure] ( NAME = N'HybridTableDemoAzure', filename = N'https://tdcspdemo.blob.core.windows.net/dbfiles1/HybridTableDemoAzure.ndf' ) log ON ( NAME = N'HybridTableDemo_log', filename = N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\HybridTableDemo_log.ldf' ) go |
Now that we have the database, with the Azure file creates, we can create the partition function, partition scheme and the partitioned table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
-- Create partition function CREATE partition FUNCTION pfbirthdate(int) AS range LEFT FOR VALUES ( 2000 ) go -- Create partition scheme CREATE partition scheme psbirthdate AS partition pfbirthdate TO ([FGAzure], [PRIMARY] ) go CREATE TABLE dbo.birthdaytable ( NAME VARCHAR(50) NOT NULL, birthdate INT NOT NULL ) ON psbirthdate(birthdate) go ALTER TABLE dbo.birthdaytable ADD CONSTRAINT pk_birthdaytable PRIMARY KEY NONCLUSTERED ( NAME, birthdate ) WITH( statistics_norecompute = OFF, ignore_dup_key = OFF, allow_row_locks = on , allow_page_locks = on) ON [PRIMARY] go |
This is a very simple example, where we have a table to store a “Name” and a birthday date as an integer. This birth date is the partition column, and all the rows with a birth day before 2000 will be “archived” in Azure.
Now we need to test, so let’s add some data (Download the file and execute into the created database):
Running the following query, we can verify that the data is, in fact, spread into Azure and local drive.
|
1 2 3 4 5 6 7 |
SELECT $partition.Pfbirthdate(birthdate) AS PARTITIONID, Count(*) AS ROW_COUNT FROM dbo.birthdaytable GROUP BY $partition.Pfbirthdate(birthdate) ORDER BY partitionid |
With this simple strategy we were able to take advantage of Azure, saving cost with disk maintenance and stored data costs, as well as accomplish the requirement of keep the historical data, without compromise the performance.
In the continuation of this article, we will see another feature that Microsoft implemented for the next version of SQL Server, to do more or less the same but in another way, with even more advantages!
Thank you for reading 🙂

With experience working in Portugal, Holland, Germany and United Kingdom, he's always available to learn and share his knowledge, in order to contribute to SQL Server community,
View all posts by Murilo Miranda
- Understanding backups on AlwaysOn Availability Groups – Part 2 - December 3, 2015
- Understanding backups on AlwaysOn Availability Groups – Part 1 - November 30, 2015
- AlwaysOn Availability Groups – Curiosities to make your job easier – Part 4 - October 13, 2015