
This is in continuation of the previous articles How to monitor internal data structures of SQL Server In-Memory database objects and SQL Server In-Memory database internal memory structure monitoring.
This article describes the concepts of In-memory-optimization and design principles.
In this article, we will cover:
- Details of the In-Memory OLTP evolution
- Provides samples to demonstrate In-Memory optimized tables
- Create In-Memory Optimized tables using templates
- Explain In-Memory memory usage considerations
- And more…
In-Memory technologies in SQL Database can improve the performance of the application and it is the right choice for the workloads such as data ingestion, data load, and analytical queries.
The business’s ability to adapt quickly driven innovation and meet new competition is a challenge. The challenging task of DBA always tends to adopt the changing needs and formulate the right design strategy to meet the needs of your services, and enterprise. Many of us will have a question about the factors for tradeoffs for seamless integration of scale-out options and to design High-Performance Computing System is massively rely on the better hardware configuration. The era of hardware, surging the hardware trends such as declining memory costs, multi-core processors, and stalling CPU clock rate increase—prompted the architectural design of in-memory computing.
The system where performance is the key and the system should work on the near real-time data then the In-Memory technology solution is a choice. The way technology is trending leads to the evolution of such new features.
Introduction
In-Memory OLTP is a specialized, memory-optimized relational data management engine and native stored procedure compiler, integrated into SQL Server. Microsoft designed In-Memory OLTP to handle the most demanding OLTP workloads. In many cases, the memory-optimized tables can be created with DURABILITY = SCHEMA_ONLY option to avoid all logging and I/O.
In-Memory OLTP introduces the following concepts:
- In-Memory optimized tables and indexes
- Non-durable tables, traditional temp tables
- Natively compiled stored procedures and UDF’s
- Memory-optimized table type for table variable – This can be used as a replacement for temporary objects
- And more…
Implications of In-Memory OLTP systems
- Low latency, high throughput, faster response time
- High efficiency
- High performance
- Zero or no lock escalation management is through an optimistic concurrency model, better concurrency management
In-Memory OLTP recommended?
If the system with one or more of the following condition is “Yes” then seriously consider the potential benefits of migrating to In-Memory OLTP:
- Existing SQL Server (or other relational databases) applications that require performance and scalability gains
- RDBMS that is experiencing database bottlenecks – most prevalently around locking/latching or code execution
- Environments that do not use a relational database in the critical performance path due to the perceived performance overhead
Benefits
- Eliminate contention
- Minimize I/O logging
- Efficient data retrieval
- Minimize code execution time
- CPU efficiency
- I/O reduction/removal
Limitation
- The table should have at least one index
- No concept of HEAP
- Except for an application lock, In-Memory OLTP does not offer the ability to lock records like standard SQL Server queries
- Memory Limitations
As mentioned earlier, data structures that make up memory-optimized tables are all stored in memory, and unlike traditional B-tree objects are not backed by durable storage. Scenarios, where sufficient memory is not available to store the memory-optimized rows, can be problematic. When evaluating migration, determine the size of the memory required. It is also critical to consider the workload that may produce multiple versions of rows, which requires additional memory allocations.
In-Memory OLTP Design Considerations
Reducing the time for each business transaction can be an important goal in terms of overall performance. Migrating the Transact-SQL code into natively compiled stored procedures and reducing the latency of transaction executions are critical factors in improving the overall user experience.
Getting started
- Create a filegroup with memory_optimimized_data option
- Implement logical file to the group
- Create a table with memory_optimization options
- Note: In Azure SQL Database, in-memory technologies are only available in the Premium service tier. I will discuss more about it in the next article.
Create filegroup
|
1 2 3 4 5 6 7 8 |
ALTER DATABASE AdventureWorks2014 ADD FILEGROUP InMemAdventureWorks2014FG CONTAINS MEMORY_OPTIMIZED_DATA ; ALTER DATABASE AdventureWorks2014 ADD FILE ( NAME=InMemAdventureWorks2014File, FILENAME='f:\PowerSQL\InMemAdventureWorks2014File') TO FILEGROUP InMemAdventureWorks2014FG; |
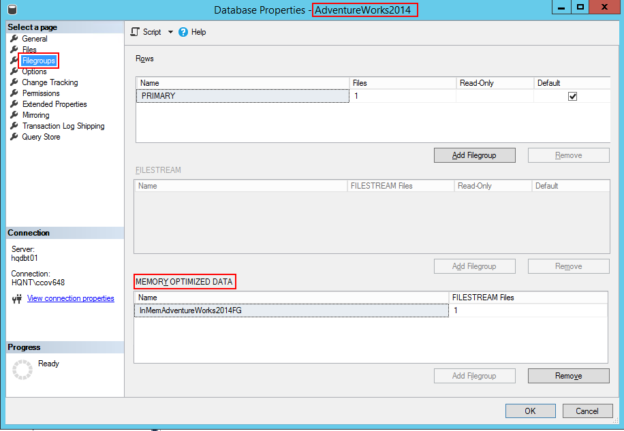
Now, let us verify MEMORY_OPTIMIZED_DATA option is enabled for the database.
|
1 2 3 4 5 6 7 |
SELECT sfg.name Name, sdf.name logicalFileName, sfg.type_desc, sdf.physical_name FROM sys.filegroups sfg JOIN sys.database_files sdf ON sfg.data_space_id = sdf.data_space_id WHERE sfg.type = 'FX' AND sdf.type = 2 |

OR
Browse the database properties, select Filegroups option; in the right pane, you can see the memory_optimized_data.
This section deals with creating a table and use of various parameters required for in-line memory optimization techniques
- MEMORY_OPTIMIZED=ON : The table is memory-optimized
-
DURABILITY = SCHEMA_ONLY: Schema and data available until the time of the server reboot. After the restart, the only schema will be in-Memory
- Maintain session state management for an application
- Commonly used as staging tables in an ETL scenario
- Temp table
- DURABILITY = SCHEMA_AND_DATA: Schema and Data available all the time in-Memory. The data is persistent in the memory and it is the default setting when creating memory-optimized tables
SCHEMA_ONLY
The following example creates an in-memory optimized table named InsertInMemDemo with Durability option SCHEMA_ONLY.
|
1 2 3 4 5 6 7 |
CREATE TABLE InsertInMemDemo ( Id INT NOT NULL, data varchar(25) constraint pk_id_1 primary key nonclustered(id)) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY) |
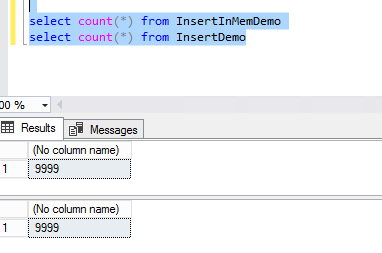
Next, insert some dummy data from the InsertDemo table into the In-Memory optimized table and validate the number of records between the tables. This is just an example. You can insert the records in many ways.
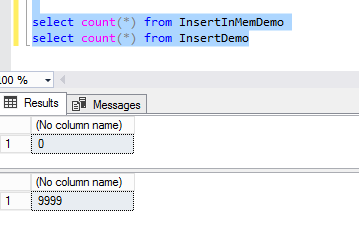
Now, let us restart the SQL instance. This is to test the persistence of the newly created in-memory table. You can see from the below image, the newly created in-memory optimized table persistence is temporary and it’s bound to memory. Whenever the instance restarts, the data is flushed out of the memory.
SCHEMA_AND_DATA
The following example created in-memory optimized table with data persistence and high performance:
|
1 2 3 4 5 |
CREATE TABLE InsertInMemDemo (Id INT NOT NULL, data VARCHAR(25) CONSTRAINT pk_id_1 PRIMARY KEY NONCLUSTERED (id) ) WITH(MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); |
The following T-SQL statement is an example to demonstrate the performance implication of traditional objects against the in-memory optimized table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
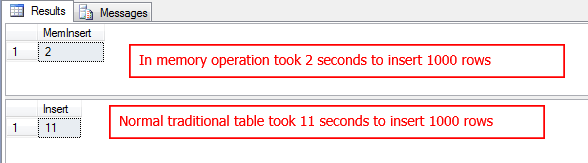
SET NOCOUNT ON; DECLARE @start DATETIME= GETDATE(); DECLARE @id INT= 1; WHILE @id < 10000 BEGIN INSERT INTO InsertInMemDemo (id, data ) VALUES (@id, 'SQLShackDemo' ); SET @id = @id + 1; END; SELECT DATEDIFF(s, @start, GETDATE()) AS [MemInsert]; GO DECLARE @start DATETIME= GETDATE(); DECLARE @id INT= 1; WHILE @id < 10000 BEGIN INSERT INTO InsertDemo (id, data ) VALUES (@id, 'SQLShackDemo' ); SET @id = @id + 1; END; DATEDIFF(s, @start, GETDATE()) AS [Insert]; DROP TABLE InsertInMemDemo; DROP TABLE InsertDemo; |
The sample output proves that it’s 37 times faster than traditional non-memory optimized objects.
Memory Sizing Consideration
Each delta file is sized approximately to 16MB for computers with memory greater than 16GB, and 1MB for computers with less than or equal to 16GB. Starting SQL Server 2016, SQL Server can use large checkpoint mode if it deems the storage subsystem is fast enough. In large checkpoint mode, delta files are sized at 128MB.
In-memory optimized table—data is stored in the data and delta file pairs. It is also called a checkpoint-file-pair (CFP). The data file is used to store DML commands and the delta file is used for deleted rows. During DML operations many CFPs will be created, this causes increased recovery time and disk space usage.
In the following example, the sample table dbo.InMemDemoOrderTBL is created and loaded with some dummy values using a piece of T-SQL code and then followed with the memory calculation.
|
1 2 3 4 5 6 7 |
CREATE TABLE dbo.InMemDemoOrderTBL (Order_ID INT NOT NULL, CustomerName VARCHAR(25), Order_Date DATETIME DEFAULT GETDATE(), Description NVARCHAR(100), CONSTRAINT PK_ID PRIMARY KEY NONCLUSTERED(Order_ID) ) WITH(MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); |
The following T-SQL is code is used to generate sample rows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SET NOCOUNT ON; DECLARE @start DATETIME= GETDATE(); DECLARE @id INT= 1; WHILE @id < 500 BEGIN INSERT INTO InMemDemoOrderTBL(Order_ID, CustomerName, Description) VALUES(@id, 'SQLShackDemo', 'Table and Row Size Computation example'); SET @id = @id + 1; END; SELECT * FROM InMemDemoOrderTBL; |
The string function DATALENGTH is used to generate the size of the description column.
|
1 |
SELECT AVG(DATALENGTH(Description)) AS TEXTFieldSize FROM InMemDemoOrderTBL |

Size is calculated as SUM ([size of data types]).
- Bit: 1
- Tinyint: 1
- Smallint: 2
- Int: 4
- Real: 4
- Smalldatetime: 4
- Smallmoney: 4
- Bigint: 8
- Datetime: 8
- Datetime2: 8
- Float: 8
- Money: 8
- Numeric (precision <=18): 8
- Time: 8
- Numeric(precision>18): 16
- Uniqueidentifier: 16
The following table defines the key metrics that are needed to estimate the size of data and indexes.
|
Header Type |
Data Structure |
Bytes |
|
RowHeader |
32 |
|
|
Begin TS |
8 |
|
|
End TS |
8 |
|
|
StmtID |
4 |
|
|
IdxLinCount |
2 |
|
|
IndexPointerArray |
8 |
|
|
Row Data |
Payload(=4(Order_ID)+24(CustomerName)+8(Order_Date)+76( average length of Description)) |
106 |
To estimate the size data and index size, use the following formula.
|
Data Size |
[RowHeaderBytes+Index*(8 bytes Per Index)+RowData]*No_Of_Rows |
|
|
{[(32+(1*8)+113]*499}/1024 |
74.55762 |
|
|
Index Size |
[PointerSize(idxLinCount+IndexPointArray)+sum(keyColumnDataTypes)]*No_of_Rows |
|
|
((2+8+4)*499)/1024 |
6.822266 |
|
|
Table Size |
DataSize+IndexSize |
81.39355 |
- Note: The calculated data and index sizes are near exact values. For row version, we need an extra 75 kb and for additional growth its better to reserve 30%(~25 kb). In total, we need a memory of 180 kb to process the in-memory optimized tables efficiently.
|
1 2 3 |
SELECT * FROM sys.dm_db_xtp_table_memory_stats WHERE object_id = OBJECT_ID('dbo.InMemDemoOrderTBL'); |

Summary:
In this article, we covered various concepts of the In-Memory optimized table and its features. I have included the important piece to understand the implication of memory consideration and requirements. I would recommend you to know the limitation. I will discuss this in more detail in the upcoming article. In today’s world, the techniques matter a lot and are measured in terms of performance. The In-Memory OLTP is a highly memory-centric feature introduced in SQL 2014. It’s a high performance, memory-optimized engine integrated into the SQL Server engine and designed for modern hardware.
The traditional OLTP systems with an overhead of huge transactions lead to the evaluation of managing the transactions in a volatile space and it gives a great performance boost to the application execution. The right usage of this feature could see a great improvement in the performance.
Let me know what you think…

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021