
Introduction
When customers used to ask for advice to solve some T-SQL Problem, they would show me their scripts, stored procedures and cursors. I saw horrible things doing that job, some things I do not want to remember, and even some I cannot tell you about 😉 In this article, we will talk about performance problems when using while loops in T-SQL. We will also talk about problems with UNIONsand finally the use of JOINS of two or more tables using the where clause (ANSI 89) instead of using INNER, LEFT or RIGHT JOINS using the from clause (ANSI 92).
We will also learn how to create a table with random values for our test.
Requirements
- SQL Server installed.
- The AdventureWorks Database (for the last example only)
Getting Started
We will talk about the following topics:
- Avoid the use of the WHILE LOOP
- Use UNION ALL instead of UNION whenever is possible
- Avoid using the joins of multiple tables in the where and join in the from clause.
Avoid the use of the WHILE loop whenever is possible
T-SQL was designed to work with sets of data. That is why is not usually a good idea to work with sequences and loops that usually iterate row by row. The WHILE loop is sequential and does not work with sets of data.
In this example, we will show how to create a table with a million rows using the while loop and another example using CTE. We will compare the results and show the difference.
We will first create a temporary table named myTable and then we will insert a million rows using a while:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
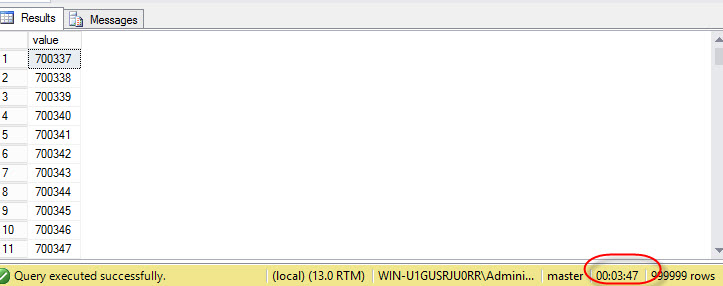
create table #myTable (value int) Declare @init int=1, @end int=1000000 while @init<=@end begin insert into #myTable values(@init) select @init= @init+1 end select * from #myTable |
The query will show values from 1 to 1 million. To create and show the table takes 3 minutes and 47 seconds:
Instead of using while for these tasks, you can use Common Table Expressions (CTEs).
The Common Table Expressions started in SQL Server 2005 and they can be used to replace cursors or the while loop. It is also used for recursive queries and to reference the result table multiple times.
The following example shows how to create a table with a sequence of values:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
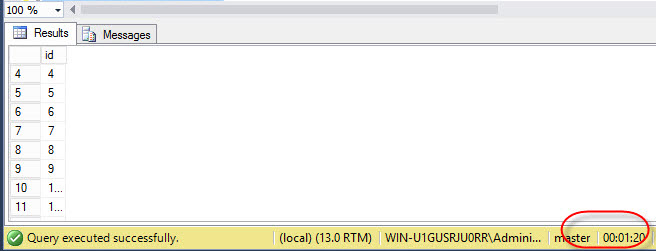
with ctesequence as( select 1 id union all select id + 1 from ctesequence where id < 1000000 ) select * from ctesequence OPTION(MAXRECURSION 0) |
When we execute CTE, the average execution time is just 1 minute 20 seconds:
As you can see, CTEs is an alternative in many situations to replace the WHILE loop. We could also use Sequences, but CTE covers and substitutes the while in more situations than the sequences.
Use UNION ALL instead of UNION whenever is possible
A Union combines the results of two or more queries, however a UNION also verifies if there are duplicate values and removes them in the query results. If you did not know, that aspect can slow down a query. If possible, we always try to avoid it.
That is why UNION ALL is faster. Because it does not remove duplicated values in the query. If there are few rows (let’s say 1000 rows), there is almost no performance difference between UNION and UNION ALL. However, if there are more rows, you can see the difference.
The following example will create two tables with random values from 1 to 1,000,000 and then we will test UNION and UNION ALL with the tables created.
We will first create a table named #table1 with sequential IDs from 1 to 1 million and random values from 1 to 1 million.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
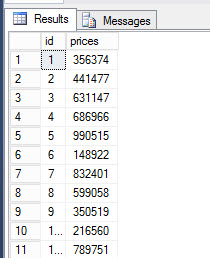
with listprices as( select 1 id, CAST(RAND(CHECKSUM(NEWID()))*1000000 as int) prices union all select id + 1, CAST(RAND(CHECKSUM(NEWID()))*1000000 as int) prices from listprices where id <= 1000000 ) select * into #table1 from listprices OPTION(MAXRECURSION 0) |
The example with CTEs creates a temporary table named table1 with a million values:
Select * from #table1
We will use the same code to create a table named #table2 with different random values:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
with listprices as( select 1 id, CAST(RAND(CHECKSUM(NEWID()))*1000000 as int) prices union all select id + 1, CAST(RAND(CHECKSUM(NEWID()))*1000000 as int) prices from listprices where id <= 1000000 ) select * into #table2 from listprices OPTION(MAXRECURSION 0) |
CAST is used to convert the random value to integer. RAND(CHECKSUM(NEWID)) returns a random value from 0 to 1. For example, 0.4566.
Let’s test the UNION ALL first and see the results:
|
1 2 3 4 5 |
select * from #table1 UNION ALL select * from #table2 |
UNION ALL takes 47 seconds approx.:
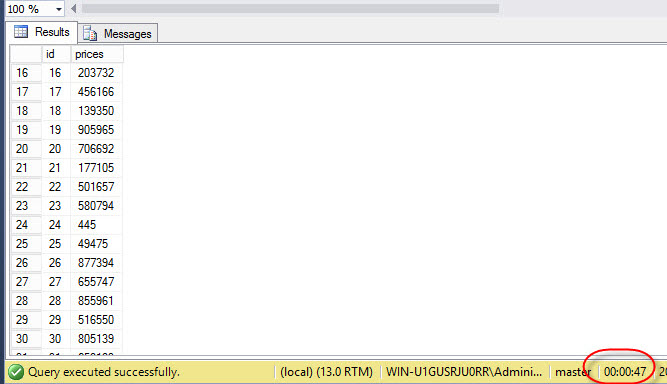
If we compare with UNION, the results are different:
|
1 2 3 4 5 |
select * from #table1 UNION select * from #table2 |
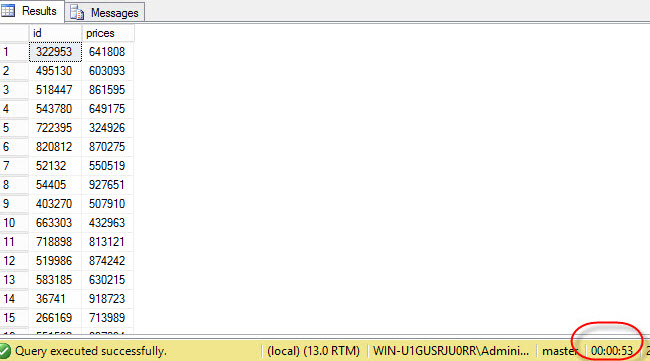
As you can see, the execution time is 53 seconds. It takes longer to execute than UNION ALL.
If we check the execution plan, we can see that the UNION spends a lot of time in the Hash Match to verify duplicated values. Press the Actual execution plan icon:

Run the query and go to the execution plan tab:
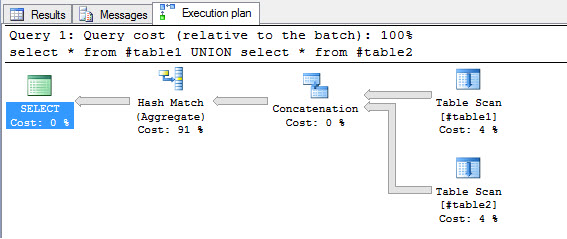
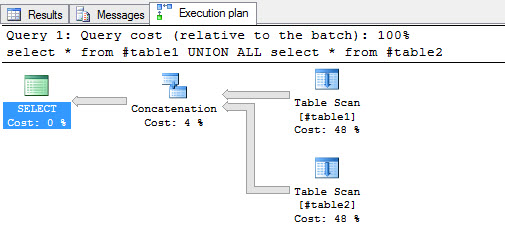
UNION ALL instead does not use a Hash Match to verify duplicated values:
Avoid using the joins of multiple tables in the where and join in the from clause
A typical problem that I still see is the join of tables using the ANSI 89 standard. This standard had the following syntax:
Select value1, value2, value3
From table1 t1, table2 t2
Where t1.id=t2.id
This standard is very intuitive, and is still used by many developers. The new standard is the ANSI 92 and the syntax is the following:
Select value1, value2, value3
From table1 t1
inner join t2
ON t1.id=t2.id
To include more details about the execution time, we will enable statistics time and Input Output statistics:
|
1 2 3 4 5 |
SET STATISTICS io ON SET STATISTICS time ON GO |
Let’s test a query using the ANSI 92. The following table is from the AdventureWorks database mentioned in the requirements:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
SELECT p.[ProductID] ,[Name] ,[ProductNumber] ,[MakeFlag] ,[FinishedGoodsFlag] ,[Color] ,[SafetyStockLevel] ,[ReorderPoint] ,[StandardCost] ,[ListPrice] ,[Size] ,[SizeUnitMeasureCode] ,[WeightUnitMeasureCode] ,[Weight] ,[DaysToManufacture] ,[ProductLine] ,[Class] ,[Style] ,[ProductSubcategoryID] ,[ProductModelID] ,[SellStartDate] ,[SellEndDate] ,[DiscontinuedDate] ,[OrderQty] FROM [Production].[Product] p inner join [Purchasing].[PurchaseOrderDetail] po on p.ProductID=po.ProductID |
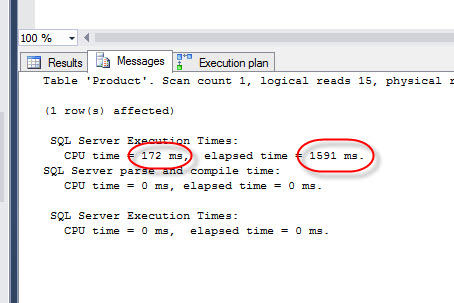
This is a query between the table products and purchaseOrderDetail using the JOINs of the ANSI 92. If we check the Execution time, we notice that it takes 110 ms and the enlapsed time =1597 ms:
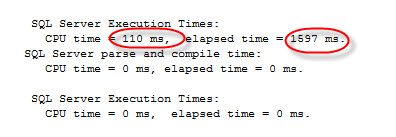
If we check the execution plan, we will see the following plan:
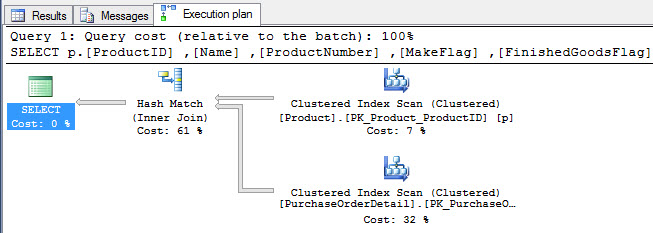
Now we will run the ANSI 89 equivalent:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
SELECT p.[ProductID] ,[Name] ,[ProductNumber] ,[MakeFlag] ,[FinishedGoodsFlag] ,[Color] ,[SafetyStockLevel] ,[ReorderPoint] ,[StandardCost] ,[ListPrice] ,[Size] ,[SizeUnitMeasureCode] ,[WeightUnitMeasureCode] ,[Weight] ,[DaysToManufacture] ,[ProductLine] ,[Class] ,[Style] ,[ProductSubcategoryID] ,[ProductModelID] ,[SellStartDate] ,[SellEndDate] ,[DiscontinuedDate] ,[OrderQty] FROM [Production].[Product] p,[Purchasing].[PurchaseOrderDetail] po where p.ProductID=po.ProductID |
The elapsed time is the same and the CPU time is slightly different, but after executing several times you will notice, that there is no difference in time:
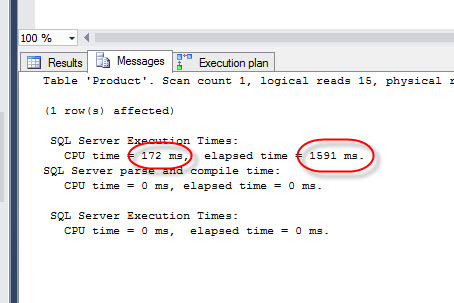
If we check the Execution plan, you will notice that it is the same plan for the ANSI 89:
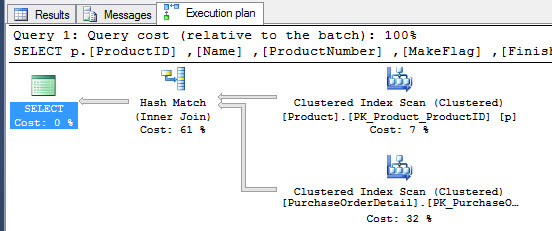
If there is no difference in performance, what is the main advantage of the ANSI 92? Why should I use it?
There are two reasons:
- It separates the joins between tables from filters using the where clause.
- It is easier to read and detect to apply later indexes if necessary.
The other problem is that in with ANSI 89, it is easier to generate a Cartesian product.
What is a Cartesian product?
The name comes from the French mathematician René Descartes (Renatus Cartesius in Latin). He invented the Cartesian product, which demonstrates the combination of values between sets.
In tables, it returns all the possible combinations between two tables.
When you use the ANSI 89, it is very easy to inadvertently generate a Cartesian product and create long running queries by mistake. The following example shows how to create a Cartesian product by mistake:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
SELECT p.[ProductID] ,[Name] ,[ProductNumber] ,[MakeFlag] ,[FinishedGoodsFlag] ,[Color] ,[SafetyStockLevel] ,[ReorderPoint] ,[StandardCost] ,[ListPrice] ,[Size] ,[SizeUnitMeasureCode] ,[WeightUnitMeasureCode] ,[Weight] ,[DaysToManufacture] ,[ProductLine] ,[Class] ,[Style] ,[ProductSubcategoryID] ,[ProductModelID] ,[SellStartDate] ,[SellEndDate] ,[DiscontinuedDate] ,[OrderQty] FROM [Production].[Product] p,[Purchasing].[PurchaseOrderDetail] po |
The following query is the ANSI 89 query, but without the WHERE clause which was omitted to simulate the Cartesian product problem.
If you check the Actual execution plan, you will notice that a Nested Loop is created (a nested loop, always means low performance):
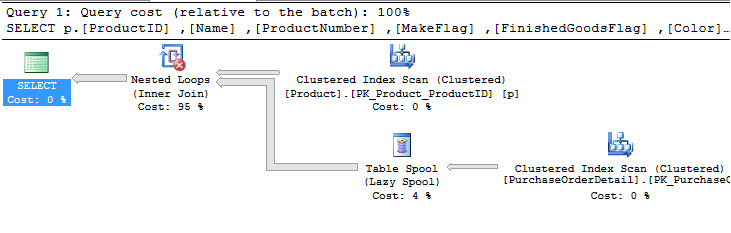
The Cartesian product takes 7 minutes and 46 seconds:
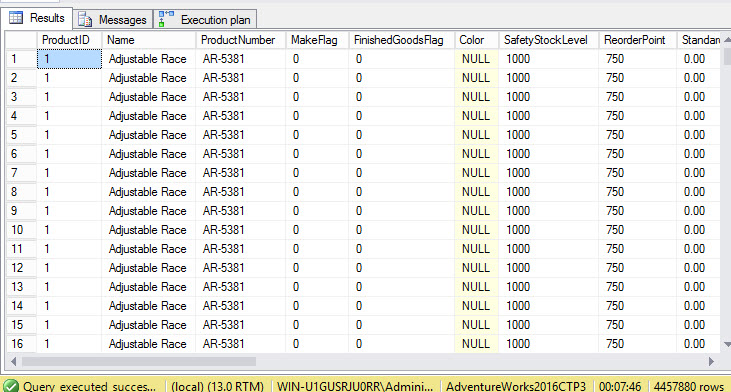
It is a best practice to use the ANSI 92 in your code to avoid these Cartesian products and to have a simpler code.
Conclusions
In this article, we learned that:
- We should work with sets of data and avoid to work row by row using WHILE Loops and cursors. In many scenarios, you can use Common Table Expression.
- We also learned that UNION ALL is faster than UNION because it does not need to detect and remove repeated values.
- ANSI 92 is necessary to have a more organized code and avoid Cartesian results by accident.

He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
He also helps with translating SQLShack articles to Spanish
View all posts by Daniel Calbimonte
- PostgreSQL tutorial to create a user - November 12, 2023
- PostgreSQL Tutorial for beginners - April 6, 2023
- PSQL stored procedures overview and examples - February 14, 2023