
This article provides for a roadmap to continuous integration and delivery best practices, and along the way demonstrates how to apply these with ApexSQL tools and technologies. In some sections this article is aspirational, as no solution yet exists, but demonstrates our plan, direction and roadmap. As the tools that apply these best practices are released this article will be updated accordingly.
The article will be color coded to separate the policies from the implementation. This will allow you to read through the policies quickly, to get a good understanding of some baseline expectations, then, if you have ApexSQL tools, work through the list again to implement them.
Everything should be in source control
Everyone will assume that all database objects are in source control but we want to make sure static data and the database itself is too. The goal is to ensure that whatever will be built in the QA environment should be in source control.
A true build starts with just a SQL Server with nothing else outside of our automation environment, including and especially, the database itself. Therefore, we want the database creation script versioned in source control and dropped and re-created with each new build.
Static data is a critical part of our database build process as well, as in many cases database and business logic is tightly coupled with specific data in static tables. To read more about what static data is and why it needs to be versioned in source control, read Understanding SQL Server database static data and how it fits into Database lifecycle management.
Start with the data model
When designing and developing a database, most developers don’t create tables by writing script, but rather they edit them in a data modeling tool. Ideally, the ERM tool will allow the user to check out a table, make changes, and check in all from within the IDE.
If the changes would break dependencies, the developer could isolate those objects that would change, manually check them all out, and then run the change script to update them, and check them all back in.
ApexSQL Refactor, offers a feature, Safe rename, that will create a script to update all referencing objects, based on renaming of any object.
Even better, if the ERM tool would automatically execute the process of checking out all referencing objects, updating them, and checking them back in.
IDE integrated with SQL source control
If your ERM isn’t integrated directly with source control, then your IDE should be. This will allow you to check out objects, edit them and check them back in all in the same IDE you are developing in. This has been a given in client development for years, but less so in the database development world.
With tools like ApexSQL Source Control, you can integrate SQL Source control directly into your development process in either SQL Server Management Studio or Visual Studio, without. ApexSQL Source Control allows integrated check-in, check-out processes so you can update your source control repository as you are developing your database.
Mandatory check-in comments
We expect the code itself to have comments but too often, check ins are committed silently, with no means to quickly see what was changed other than compare to the last version. If a change was significant to require a commit, it should require a comment.
Even better, configure your IDE to require comments on commits via custom check-in policies. A good example in Visual Studio is How To: Create Custom Check-in Policies in Visual Studio Team Foundation Server. This script will require the user to add a comment, prior to allowing the check-in to proceed. Setting minimum character requirements may be a helpful mod.
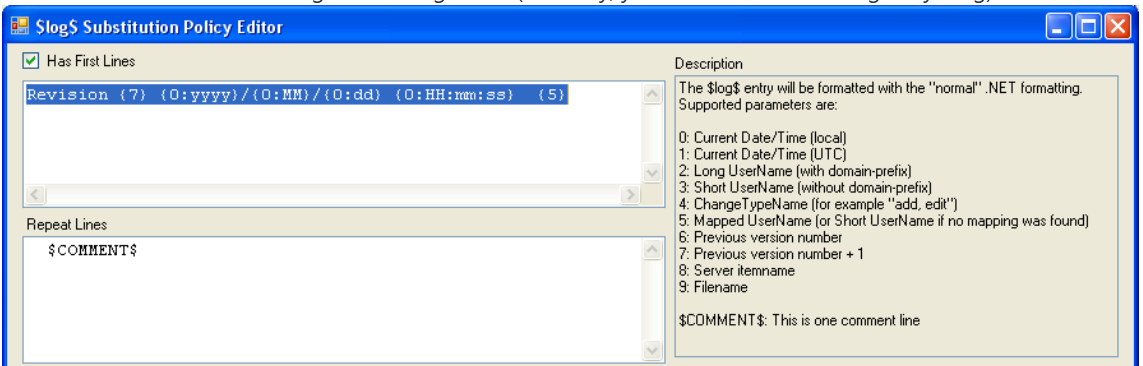
If forcing manual, custom comments for each commit is overkill (which I don’t think it is), then consider automating them with tags. By creating a template with simple tags like Type “Edit” or “New”, Datetime, User, Version number, last Version number etc and having that template be applied to each commit would provide a baseline for use full information, as shown in the following image.
The below example, is a custom Visual Studio add-in demonstrating how to implemented, automated, tag based comments. See $log$ / Keyword Substitution / Expansion for more information.
In-object comments
To ensure a full version change documentation trail, it is important to include changes in the header of the scripts, objects as well. Most developers are accustomed to quickly checking the version history of an object by Date, in ascending order, and change history.
A neat trick to both automate comments (from the previous best practice) and to append the check-in comment to the source code header stub itself. $log$ / Keyword Substitution / Expansion Check-In Policy Using a tag based system to generate a comment block, it also appends it to the code block header itself as in the following image.

Mandatory locks
A “conflict” in the course of source control occurs when the user is working in the dedicated model (on a local copy of a database) with a version of an object that is not the latest one from the repository.
Since most CI processes will start in source control, we can assume there are no conflicts, as all objects will have been successfully checked in, but even so, on scheduled builds that run nightly or event based builds e.g. “Build day”, conflicts can prove time consuming to resolve and may result in the build window being missed. Even though such scheduled or event-based builds don’t meet the criteria of true continuous integration, they do at least classify as build automation and are pre-cursors to CI, so I’ll still address them in this best practices article.
We may have a case where builds are done nightly at midnight. The onus is for all developers to commit their changes to the repository prior to leaving for the night. One developer, staying late, is checking in his changes and notes a conflict with a developer who made changes on the same object earlier in the day, and has subsequently left. With no means to discuss the conflict resolution with the other developer and not willing to overwrite his changes, the developer flags the build system to skip the nightly run and leaves. A conflict was avoided, but at the cost of a missed build. Now QA will be working on a day old build and will miss the opportunity to work with fresh changes.
Policies should exist that provide not only a visual indication that another developer has checked out an object but that it has already been edited. If those signals are ignored, then an explicit message can be shown when the user attempts to check out an object that has already been checked out.
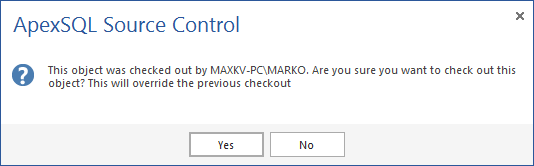
This is helpful but not stringent enough to avoid conflicts. The next layer of protection would be a policy that didn’t simply nag at the user to follow correct procedure but enforced the requirement to check out an object before editing it. The back door in such a “Permissive” policy is that even with the warning and the requirement to check out the object, the other developer could do just that, and override the original check out.
The best policy IMHO, is one that leaves nothing to chance and not only requires checkouts but allows them to be locked, preventing any chance of a conflict. Should the developer in our example who has successfully navigated through all of the other obstacles to prevent conflicts, attempt to edit an object, they would hit a roadblock.
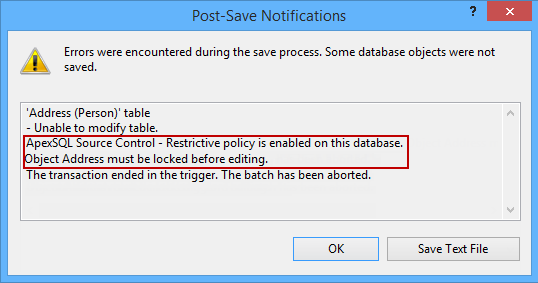
ApexSQL Source Control allows for the granular setting of Policies to enforce the level of adherence to source control best practices suitable for your team.

Have a mechanism to detect if any objects are still checked out
In a true CI/CD process, checked out objects are a reality for almost every build, since a build is triggered on every commit, it would be impossible for all other objects to be checked-in prior to each developer checking in their object.
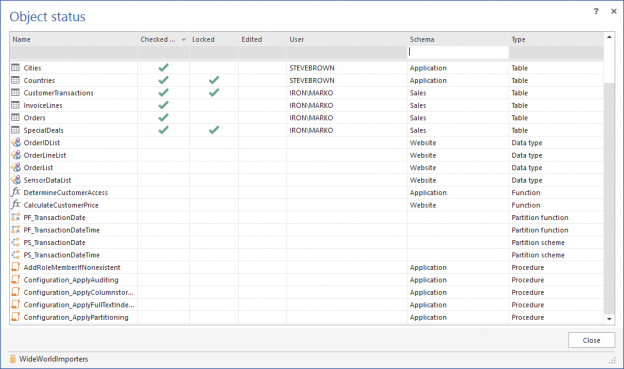
But I always get nervous when I start a scheduled build and see objects still checked out. In a team where daily check ins are the norm, if not the requirement (see next), pending check ins, near the end of the day, are often an indication of some sort of problem. Being able to visually scan the project via a source control client to identify checked out objects is critical. Developers can be contacted to remind them that they may have forgotten to check code in.
ApexSQL Source Control provides a project view to show all objects by status.
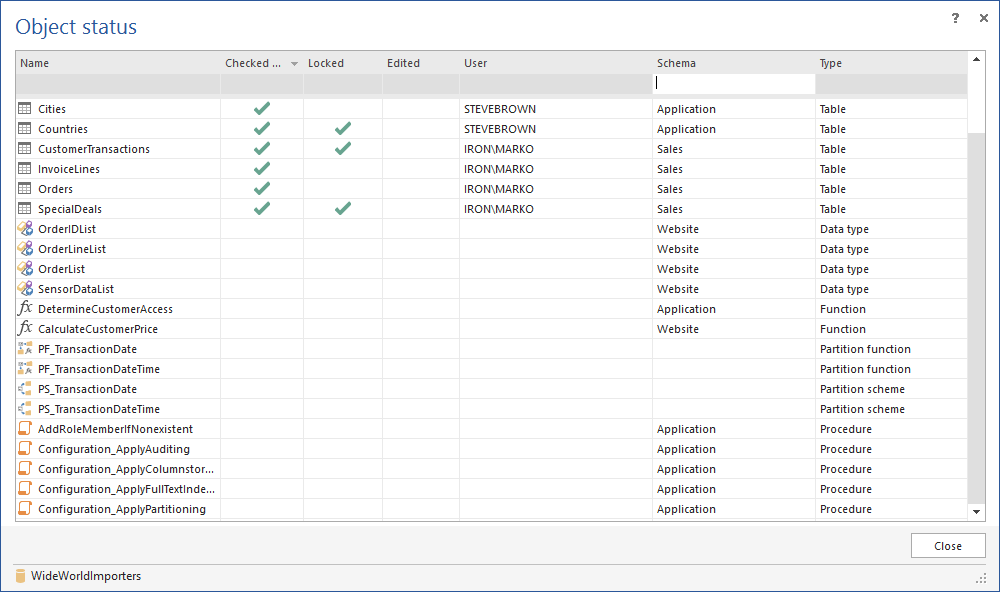
For ad hoc synchronizations where the source control repository is the “Source” and a database is the “Target” and the goal is to move changes from the repository to the database, having database change control software that is source control aware, is an important feature. This would show visual indicators on each object for checked out, checked out and edited as well as locked.
A policy driven approach to address this problem is to simply mandate nightly check-ins of all code (see next).
Nightly check ins
A key tenet of continuous integration isn’t checking in faster, but testing faster, which is the end, that drives the means. Closing the time from creating bugs to finding them, is critical for improving quality. The longer bugs exist, then the higher the chance of destabilizing more code, other modules, as more code is layered upon it. Also, the more time between development and testing, the harder it is for the developer to double back, remember what he/she was coding and fixing it.
To this end, forcing more iterative check-ins reduces the latency in software development that can degrade agility and quality.
Open check-outs can be problematic for nightly builds, as there can be code in development that relies on the checked-out module to perform properly but won’t be included in the new build of QA. If the build fails, the open check-outs become the unknown variable that have to be researched.
Furthermore, open check-outs can be symptomatic of developers working on units of work that are too large and weren’t broken down more atomically in a way that ensures good communication and feedback.
For all of these reasons and more, dev teams should encourage a policy of check-in before you check-out, meaning check-in all of your code before you leave for work that day.
The next article in this series:

He uses his spare time on tuning and styling of his car, playing video games, and fishing.
Nemanja is currently working for ApexSQL LLC as a Software sales engineer. He’s specialized in SQL database schema and data comparison and synchronization, and he helps customers with technical issues, providing DEMO presentations, and does the quality assurance for ApexSQL Data Diff and ApexSQL Diff.
View all posts by Nemanja Popovic