

Deleting and updating data is very common, but if performed without taking care, which could lead to inconsistent data or data loss. Today, we’ll talk about SQL best practices when performing deletes and updates. We’re not talking about regular/expected changes, but rather about manual changes which will be required from time to time. So, let’s start.
Data Model
We’ll use the same data model we’re using in this series.

Still, we’ll focus only on one table and that is the customer table. We’ll create table backup and update a few rows in this table.
Maybe the most important SQL Best Practice – Create Backups
Creating a backup is not only SQL best practice but also a good habit, and, in my opinion, you should backup table(s) (even the whole database) when you’re performing a large number of data changes. This will allow you two things. First, you’ll be able to compare old and new data and draw a conclusion if everything went as planned. And second – in case something went wrong, you can easily revert everything. If you need a simple way to back up a table, except options on the GUI (which are specific to different tools), you have a very simple SQL command at your disposal.
|
1 2 3 4 |
-- backup table using SELECT ... INTO ... SELECT * INTO customer_backup FROM customer; |
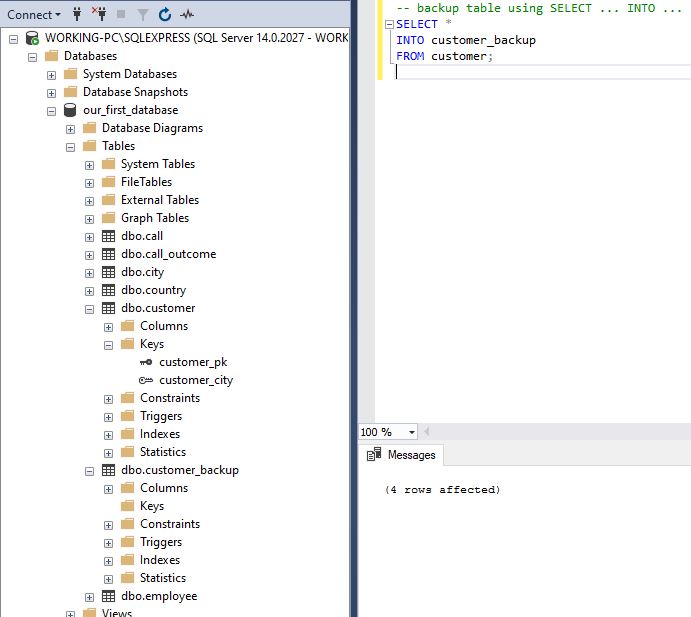
Please notice here that the keys were not backed up and therefore if you’ll need to recreate the original customer table from the customer_backup table, you’ll need to do one of the following (this is not only SQL best practice but required to keep the referential integrity):
-
Completely delete the customer table (using the command DROP TABLE customer;), and re-create it from the customer_backup table (the same way we’ve created backup). The problem here is that you won’t be able to drop the table if it’s referenced in other tables. In our case, the call table has attribute call.customer_id related to customer.id. The system won’t allow you to perform the DROP statement because this way, you would impact the referential integrity of the database

-
Delete all records from the customer table and insert all records from the customer_backup table. This approach again won’t work if you have records referenced from other tables (as we do have)
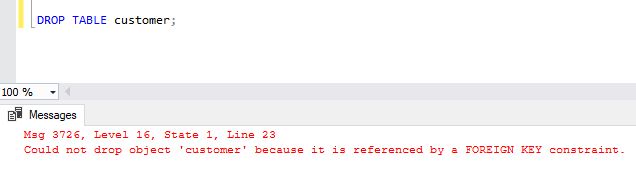

To perform any of the previous two actions, you should first drop constraints, then perform the desired action, and recreate constraints. Before doing that, we should determine all the constraints related to the customer table. I’ll use the query below to do that. You can check more regarding the INFORMATION SCHEMA database in the Learn SQL: The INFORMATION_SCHEMA Database article.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- primary key & foreign key used in this table (relation to another table) SELECT tc.CONSTRAINT_TYPE, tc.CONSTRAINT_NAME, tc.TABLE_NAME FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc WHERE tc.TABLE_CATALOG = 'our_first_database' AND tc.TABLE_NAME = 'customer' UNION -- another table referencing this table SELECT CONCAT('referenced in table: ', tc1.TABLE_NAME) AS CONSTRAINT_TYPE, tc1.CONSTRAINT_NAME, tc2.TABLE_NAME FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS rc INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc1 ON rc.CONSTRAINT_NAME = tc1.CONSTRAINT_NAME INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc2 ON rc.UNIQUE_CONSTRAINT_NAME = tc2.CONSTRAINT_NAME WHERE rc.CONSTRAINT_CATALOG = 'our_first_database' AND tc2.TABLE_NAME = 'customer'; |
You can see the query result in the picture below.

As you can see, we’ve identified 3 keys related to the customer table: customer_pk – primary key of the table, customer_city – relation between tables customer and city (city.id is referenced), and call_customer – relation between tables call and customer (customer.id is referenced).
One useful SQL Server procedure is sp_help. We can use it to get details about the table. For the customer table, the result returned would be like in the picture below.
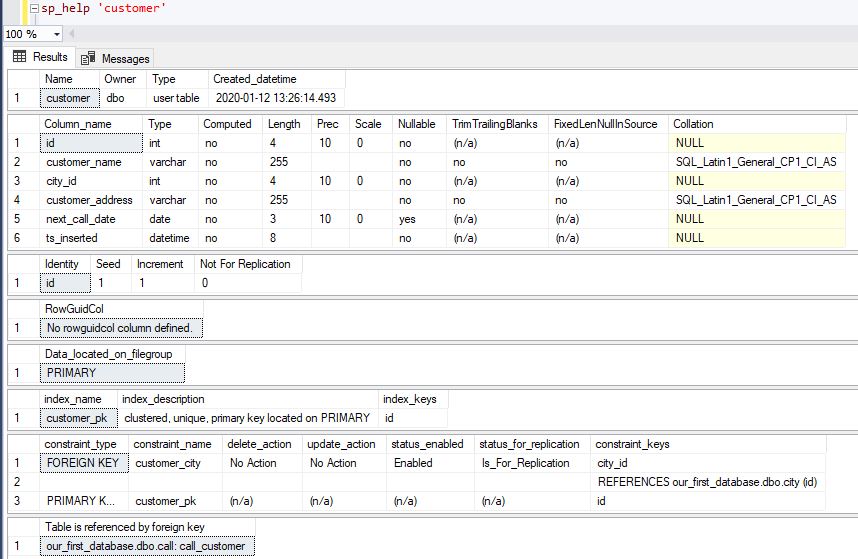
Since we have their names, we can easily drop all 3 constraints and recreate them later. To drop them, we can use the following statements:
|
1 2 3 4 |
-- drop constraints DROP CONSTRAINT customer_pk; DROP CONSTRAINT customer_city; DROP CONSTRAINT call_customer; |
But, before we drop them, we should “store” create commands, so we can use them after we recreate the customer table from the backup. We can do it by right-clicking on each constraint and export them to a new query window.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- customer PK ALTER TABLE [dbo].[customer] ADD CONSTRAINT [customer_pk] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO -- FK: customer.city_id = city_id ALTER TABLE [dbo].[customer] WITH CHECK ADD CONSTRAINT [customer_city] FOREIGN KEY([city_id]) REFERENCES [dbo].[city] ([id]) GO ALTER TABLE [dbo].[customer] CHECK CONSTRAINT [customer_city] GO -- FK: call.customer_id = customer.id ALTER TABLE [dbo].[call] WITH CHECK ADD CONSTRAINT [call_customer] FOREIGN KEY([customer_id]) REFERENCES [dbo].[customer] ([id]) GO ALTER TABLE [dbo].[call] CHECK CONSTRAINT [call_customer] GO |
Preparing statements
If you’re performing changes on just a few rows, that is something where you can “take a risk”, copy old data to Excel, change them manually and visually confirm if everything went OK. In that case, there is no point in applying SQL best practices mentioned in this article.
Still, from time to time, you’ll get a bunch of data that should be either updated with new values, either deleted from the system. These could be hundreds of rows, but also millions. Of course, in such cases, inspecting changes visually is not the solution, and such cases are good candidates to apply SQL best practices mentioned today.
One thing that you should do before performing mass updates or deletes is to run a select statement using conditions provided. In the ideal situation, you would have provided PK (primary key) or UNIQUE/AK (alternate key) values. This will list all the cases that shall be impacted and also give you a feeling of what shall happen.
When you’re sure these are truly the cases that should be updated/deleted, you’re ready to prepare statements to perform the desired operation. You can do it in 2 ways:
-
Every single update/delete is performed by the UNIQUE value and is limited to exactly one row (using TOP(1) in SQL Server or LIMIT 1 in MySQL). This is pretty safe because you’ll be sure that each command impacts exactly one row. Also, for updates, this is sometimes the only option, because you can expect that you’ll have different values you want to set for different rows
12UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 1;UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 2;
-
You could run one statement with all ids listed in it. This will work faster because you have only 1 statement. You have somehow less “control” here, but still, this is completely OK option to go with, especially in cases when you’re working with a really large number of rows. This will work well for deletes and should be considered SQL best practice. For updates, this method shall work only in case you’re updating all rows using the same values
1UPDATE customer SET next_call_date = '2020/08/01' WHERE id in (1, 2);

Use Transactions
Transactions as concepts are extremely important in the database, but for the sake of this article, we’ll just tell that they allow us to perform all statements inside the transaction or none. If any statement fails for any reason, there will be no changes applied. This is not only SQL best practice (you should always use transactions when a whole batch of commands must run successfully), but also sounds very useful in cases we have a large batch of update/delete statements. Let’s take a look at the code that will do the trick.
|
1 2 3 4 5 6 |
BEGIN TRANSACTION; UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 1; UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 2; COMMIT TRANSACTION; |
Final SQL Best Practice – Check what happened
In case you’ve created a backup, you should compare old and new tables.
If you’ve deleted data, you’ll simply search for rows that are present in the old table, and we don’t have them in the new table, using LEFT JOIN. The total number should match what we’ve expected based on the input data and select a statement with the same conditions (if we’ve run it before).
|
1 2 3 4 |
SELECT cb.* FROM customer_backup cb LEFT JOIN customer c ON cb.id = c.id WHERE c.id IS NULL; |

Since we performed only updates and there were no deletions, the returned result is empty (all customers who are in the old table are also in the new table).
In case we’ve performed updates, you can compare old and new rows by joining them using INNER JOIN. Rows that have differences in any of the attributes are the ones that were impacted with update statements. Of course, you’ll need to compare all attributes that were affected by updates in any of the statements. E.g., if you know you’ve changed only the next_call_date, you can check using only that attribute. But if other attributes were also mentioned in any of the statements, you should incorporate all of them in your check. The example below will check all attributes for differences.
|
1 2 3 4 5 6 7 |
SELECT * FROM customer_backup cb INNER JOIN customer c ON cb.id = c.id WHERE c.customer_address <> cb.customer_address OR c.customer_name <> cb.customer_name OR c.next_call_date <> cb.next_call_date OR c.ts_inserted <> cb.ts_inserted; |

As expected, we have 2 rows in the final result, and these are exactly 2 ones we’ve updated using previous statements.
SQL Best Practices when performing Updates and Deletes
One of the most important things while working with databases is not to lose or “damage” your data. To avoid that, you should stick to SQL best practices. Before you decide to perform mass deletes/updates of data in your database, it would be good that you back up all tables where changes are expected. After changes are performed, you should compare the old and the new table. If everything went OK, you can delete the backup tables. If there were errors, you should revert things (replace the “live” table with the one previously backed up) and try again (with corrected code).
Table of contents

His past and present engagements vary from database design and coding to teaching, consulting, and writing about databases. Also not to forget, BI, creating algorithms, chess, philately, 2 dogs, 2 cats, 1 wife, 1 baby...
You can find him on LinkedIn
View all posts by Emil Drkusic
- Learn SQL: How to prevent SQL Injection attacks - May 17, 2021
- Learn SQL: Dynamic SQL - March 3, 2021
- Learn SQL: SQL Injection - November 2, 2020