
A database recovery process is an essential requirement for database systems, It can be a tedious job and the process of recovery varies on lot of scenarios. The desire to improve recovery results has resulted in various procedures, but understood by few and prone to errors. In this article, I’ll illustrate the impact of stopping the database instance in the middle of a large transaction that was running and discuss several techniques and tools that are available for faster and successful recovery.
Introduction
Let’s discuss a scenario where we have a SAN disk issue and latency is really high and think many jobs on the data warehouse systems started running indefinitely without a success.
The owner of the server felt this might be a server issue and decided to restart the server but from that point he’s invited trouble. Everything comes back but he’s nw not able to query the database because of a block generated by the system process on the user sessions during the recovery process. This leads to an involvement of senior DBA to troubleshoot the problem.
The server came back and databases were up and running, however, they were able to query the other objects but not the one which took part in the recovery process.
After brainstorming sessions, they came to know that the SQL job was purging 25 Million rows from the database. A general rule of thumb is that it will take about the same amount of time, or more, for an aborted transaction to rollback as it has taken to run. The rollback can’t be avoided even with the SQL Server stops and starts. There might be chances of corruption if you try to restart multiple times.
Now, we have to address two issues
- Work with network team to fix poor I/O subsystems which directly impacting the disk latency
- The disk latency has a direct impact on the recovery process
The first and foremost important thing is that checking the status of each database
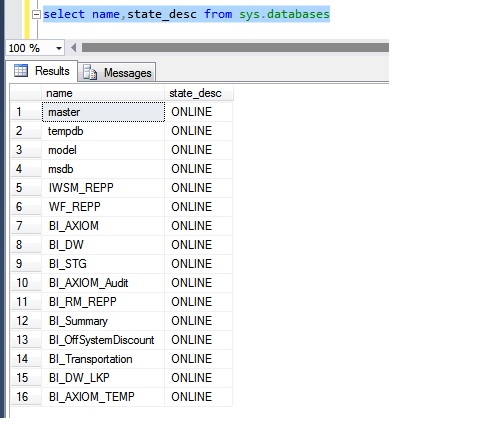
Though the database came online, it doesn’t mean that the recovery of each database is done and it’s available for further operations that are what happened in this case.
One of the most commonly used SQL by any DBA to determine the cause of any problem would be sp_who2. It shows all the session details that are currently established with the database. The first 50 sessions are system processes. The general purpose of sp_who2 is to diagnose
- Blocking
- CPU
- I/O bottleneck
- WaitTypes
sp_who2
The key information from the below figure is the command type [database STARTUP] and the session_id that indicates this is a system task performing the startup recovery

The advantage of using the enterprise edition leads to the database to come online in the second phase of the database recovery i.e. is the database is available after the REDO phase and also at certain instance during UNDO, the last part of recovery but the data involved in the rollback is locked i.e. is any access to object being recovered would be blocked. This process sometimes referred as “fast recovery”. As we were able to query the other objects but not the one which took part in recovery process
SQL Server Error log
The error log comes very handy when troubleshooting any issues with references to database recovery. This can be very helpful to detect/troubleshoot any current or potential problem areas, including automatic recovery messages (particularly if an instance of SQL Server has been stopped and restarted), kernel messages, or other server-level error messages. In this case, the error log clearly reveals the recovery stages of the BI_DW data warehouse database.
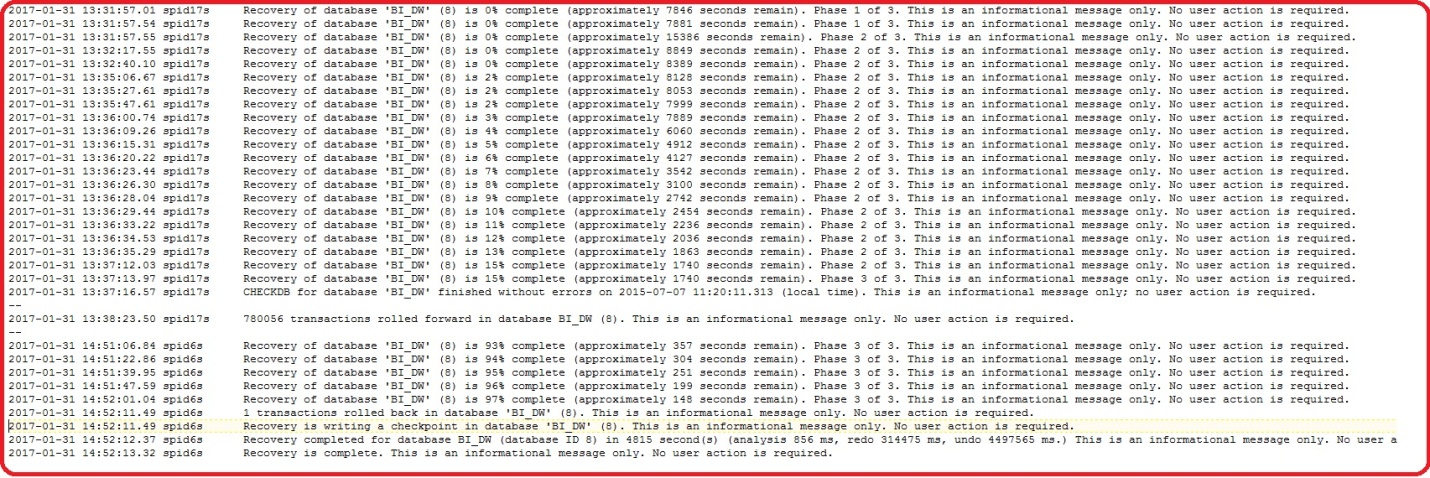
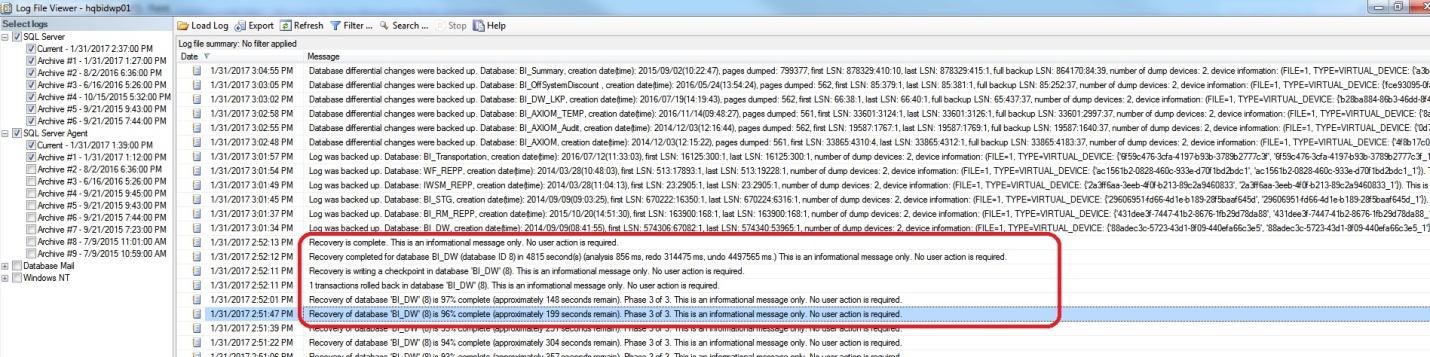
SQL Server 2008 onwards, the two DMV’s sys.dm_exec_requests and sys.dm_tran_database_transactions provides an insight on the different recovery states of the database startup.
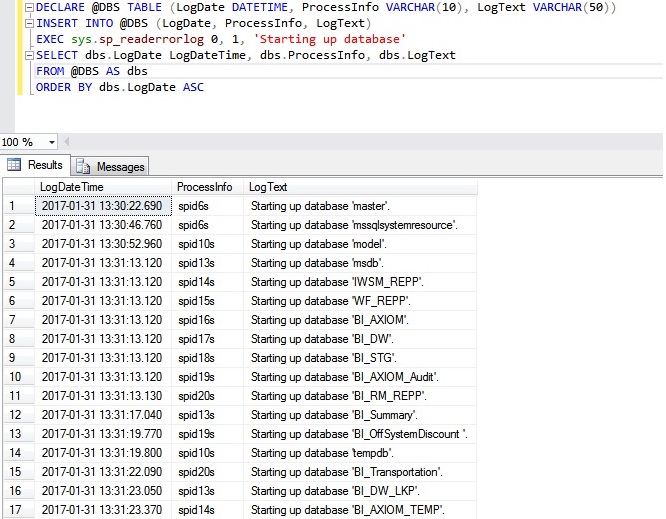
The other way is by executing the stored procedure “sp_readerrorlog” to get information about the progress of the database recovery.
The information presented in these DMV’s varies depending on the situation: recovery of databases during server startup, recovery of the database after a attach operation, recovery of the database after a restore operation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT db_name(database_id),percent_complete,estimated_completion_time, CASE WHEN estimated_completion_time < 36000000 THEN '0' ELSE '' END + RTRIM(estimated_completion_time/1000/3600) + ':' + RIGHT('0' + RTRIM((estimated_completion_time/1000)%3600/60), 2) + ':' + RIGHT('0' + RTRIM((estimated_completion_time/1000)%60), 2) AS [Time Remaining], percent_complete, * FROM sys.dm_exec_requests |
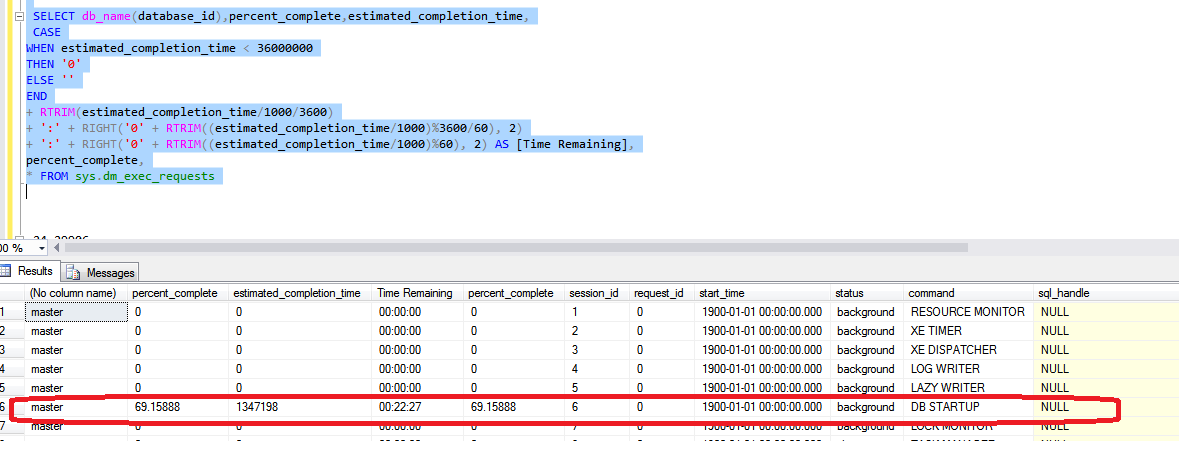
The percent_complete and estimated_completion_time shows the some value that the error log messages indicate about the progress within the stage of recovery. You can also refer other columns to understand other aspects about the recovery.
Database Recovery Phases
Different phases of the recovery are
- Analysis
- Redo
- Undo
Analysis In this phase the transaction log is analyzed and records the information about the last checkpoint and creates on Dirty Page Table, this might capture all the dirty pages details.
Redo It’s a roll forward phase. When this phase completes database becomes online so the database was online
Undo It’s rollback phase. It holds the list of the active transaction from the analysis phase basically undoing the transactions.
Database Startup Sequence
There is an exact sequence that determines which user database will come online first. The error log is the reference to measure the database startup sequence but in any case
- Master database comes first as it stores system catalog details and configuration details of the user database
- Resource database comes next
- TempDb comes online only after model database comes online
The below SQL gives the order of database startups
|
1 2 3 4 5 6 7 8 |
DECLARE @DBS TABLE (LogDate DATETIME, ProcessInfo VARCHAR(10), LogText VARCHAR(50)) INSERT INTO @DBS (LogDate, ProcessInfo, LogText) EXEC sys.sp_readerrorlog 0, 1, 'Starting up database' SELECT dbs.LogDate LogDateTime, dbs.ProcessInfo, dbs.LogText FROM @DBS AS dbs ORDER BY dbs.LogDate ASC |
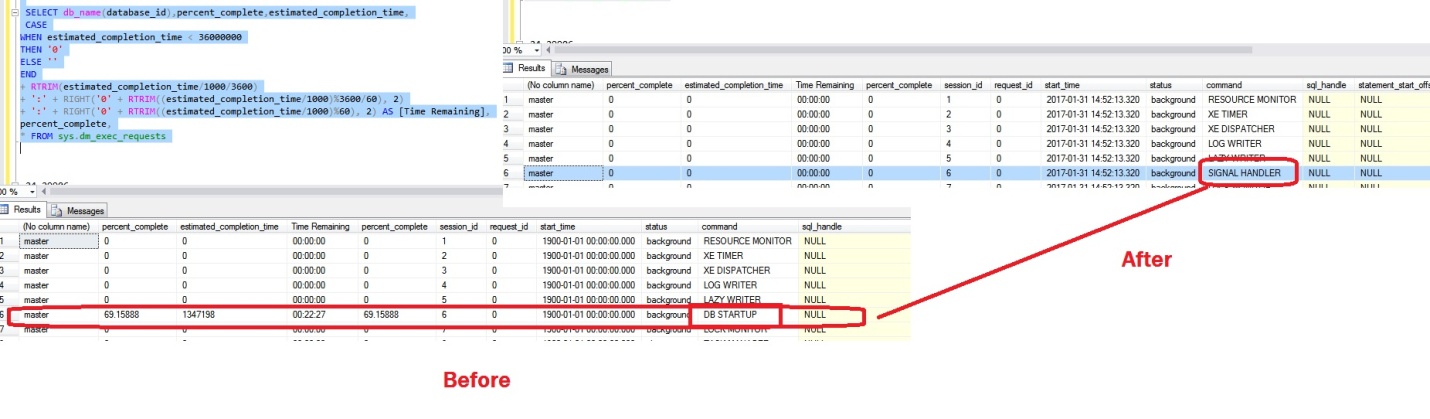
Conclusion
This is normal for SQL Server when there is an unexpected shutdown when there is an execution of long running transaction. A database goes through 3 phases of recovery and then comes online – Enterprise edition allows the database to come online after second phase. This means that there is a rollback running at the moment; need to wait for this to complete. Let the server finish the rollback process if a long-running transaction was terminated. Terminating the server process during the rollback of long-running transaction results in long recovery time.
Querying WITH (READUNCOMMITTED) hint to ignore the locks associated with the transaction that is rolling back. The results are considered unreliable, but ironically, the results are probably dirty reads since the blocking process is a rollback.
The best solution is to wait. It’s possible to kill the blocking process by restarting the instance, but then you should be concerned with database integrity. Many cases end up with restoring the database from the backup.
Summary
- Make sure to check for any active transaction before restarting the database server
-
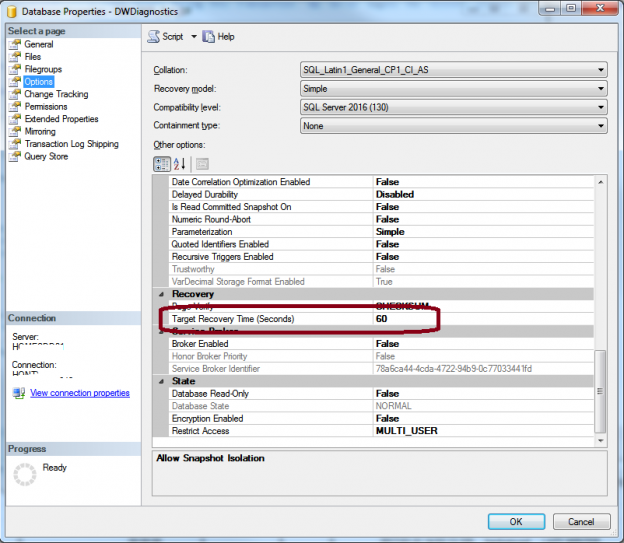
Setting Target Recovery Time of a Database but it’s not recommended for OLTP systems as it generates extra overhead to maintain that may degrade the performance.
-
Once TARGET_RECOVERY_TIME value is set to >0, the database starts to use it instead of using automatic checkpoint and it is called indirect checkpoint. The value can be specified in seconds or minutes and will define the maximum time to recover the database after a crash.

-
Once TARGET_RECOVERY_TIME value is set to >0, the database starts to use it instead of using automatic checkpoint and it is called indirect checkpoint. The value can be specified in seconds or minutes and will define the maximum time to recover the database after a crash.
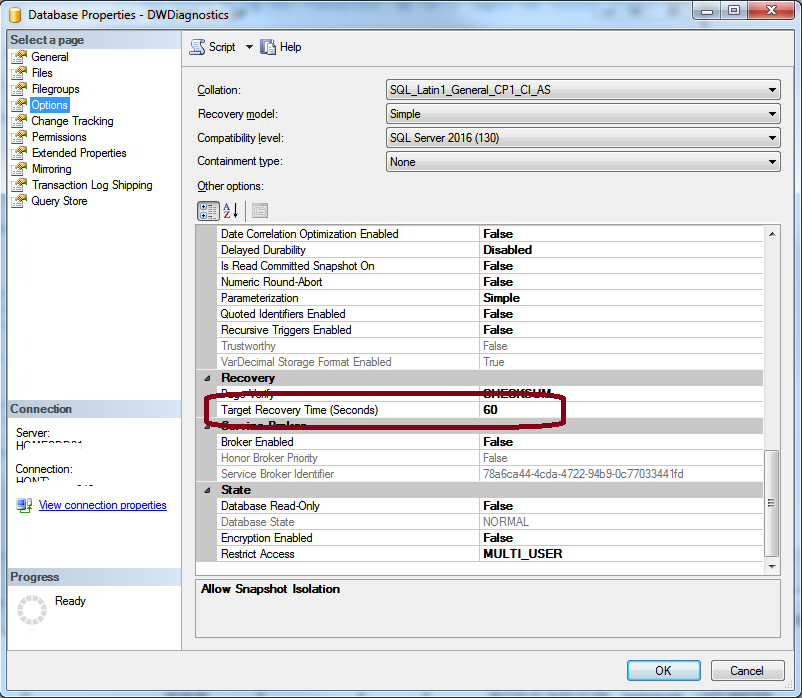
-
Reduce the recovery time is by managing the transaction log VLF
- Right sizing the transaction log and prevent SQL Server auto-grow it in an uncontrolled fashion, in small increments. This is going to prevent log fragmentation, which may speed up database recovery operations
-
The best solution is to wait
- Query the DMV’s and understand the implication
-
Check disk latency and I/O subsystem performance periodically
-
There are various methods available to measure the disk I/O based on the nature of the underlying hardware infrastructure. Make sure you work with the N/W team or Server admin to understand the implication.
The following is the DMV query that will tell us high level information of disk latency
1234567891011SELECT*,wait_time_ms/waiting_tasks_count AS 'Avg Wait in ms'FROMsys.dm_os_wait_statsWHEREwaiting_tasks_count > 0ORDER BYwait_time_ms DESC
- If you see startup command in the recovery process on sp_who2 which indicates that the database is not recovered completely. The Lock will be released automatically once database completely recovered.
I’m a Database technologist having 11+ years of rich, hands-on experience on Database technologies. I am Microsoft Certified Professional and backed with a Degree in Master of Computer Application.
My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth JayaramLatest posts by Prashanth Jayaram (see all)- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021
-
There are various methods available to measure the disk I/O based on the nature of the underlying hardware infrastructure. Make sure you work with the N/W team or Server admin to understand the implication.
