

In this article, we will read and import data from a PDF file using the R scripts SQL Server.
Introduction
In today’s digital world, data is available in many formats such as Excel, CSV, PDF, HTML, JSON, XML, TXT. We use SQL Server Integration Services for data imports and exports in SQL Server. It can read data from various data sources, databases, transform them in the required format.
You cannot import or export data in PDF format from the SSIS package directly. The PDF is a popular format for all useful documents such as agreements, contracts, policy documents, research. Generally, we use Microsoft word for preparing the documents and later converts into PDF formats.
In the article, Importing data from a PDF file in Power BI Desktop, we explored the Power BI Desktop feature for the data import from a PDF file.
SQL Server Machine Learning Language provides various functionality in the SQL Server. You can directly run your external R script from the SQL Server console. In this 4th article on SQL Server R script, we will use the R functionality to read and import data from a portal file format (PDF) file.
Environment details
You need the SQL Server environment as specified below for this article.
- Version: SQL Server 2019
- Installed Feature: R Machine learning Language
- SQL Server Launchpad and Database engine service should be in running state
- SQL Server Management Studio
Read data from PDF files using R Scripts SQL Server
We can use the external libraries to use the required functions in the R Scripts SQL Server. For this article, we use pdftools external library.
Launch the administrative R console from the C:\Program Files\Microsoft SQL Server\MSSQL15.INST1\R_SERVICES\bin and install the PDFTools library using the below SQL Server R Script.
install.packages(“pdftools”)
It downloads the PDFTools and installs for your R scripts SQL Server.
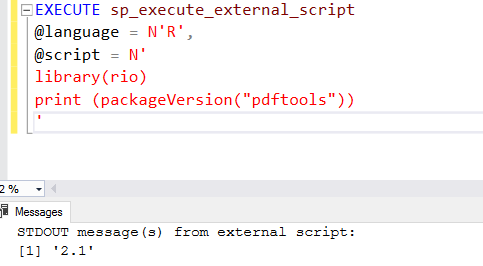
Once installed, you can use sp_execute_external_script stored procedure and print the pdftools package version.
|
1 2 3 4 5 6 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(rio) print (packageVersion("pdftools")) ' |
You get the package version, it shows that you can use PDFTools for your scripts.
For this article, I download the sample PDF file from the URL. The File content is as below.

Import the library in your R script session. If we want to check the PDF files available in our current R directory, you can use the list.files() function in R Scripts SQL Server and filter the results for PDF files.
> library(pdftools)
> files <- list.files(pattern = “pdf$”)
As shown below, It returns the PDF file name. In my case, the file name is MyData.pdf
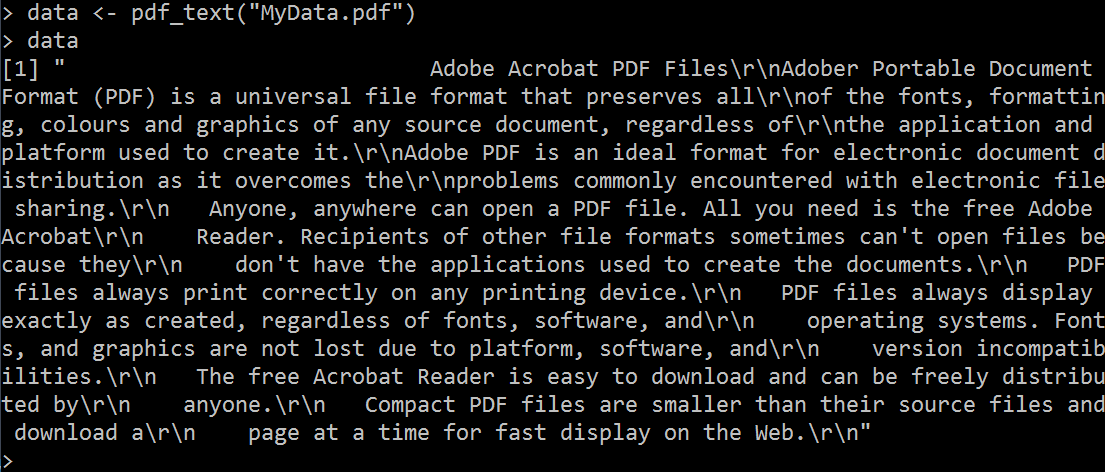
Now, to read the PDF file content, we use the function pdf.text() in the SQL Server R script.
data <- pdf_text(“MyData.pdf”)
data
In the output, you get file contents. You can compare the output with your original PDF document to verify the contents.
If you compare this with the original PDF document, you can easily see that all of the information is available even if it is not ready to be analyzed. What do you think is the next step needed to make our data more useful?
In the above image, the R Scripts SQL Server displays PDF text without any formatting. It does not consider any space or line break between the sentences. We might want to display all characters in a single line. We can use the strsplit() function, and it breaks down the extracted text in multiple lines using the new line character(\n).
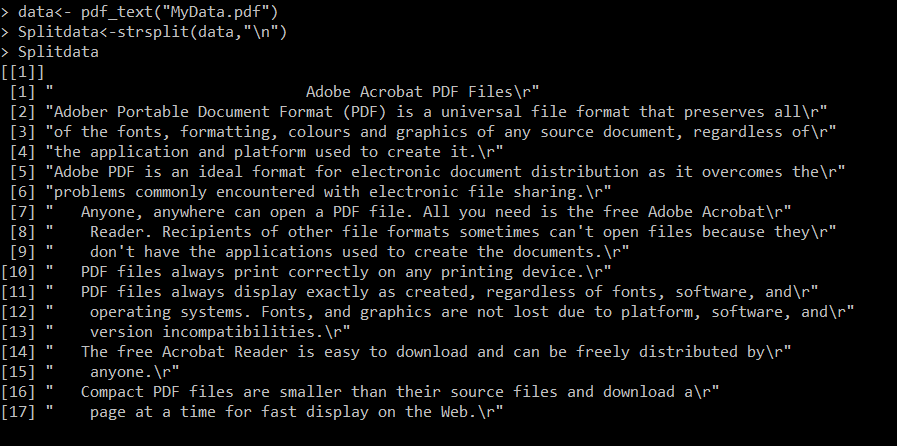
> data<- pdf_text(“MyData.pdf”)
> Splitdata<-strsplit(data,”\n”)
> Splitdata
Look at the following screenshot. Here, we get the extracted characters in separate lines similar to the original PDF document.
Let’s convert the script into the SQL Server R script format using the sp_execute_external_scripts stored procedure.
In the below script, we use the following arguments:
- @language: Specify the machine learning language R
- @Script: In the script section, we specify the R script that we want to execute from SQL Server
-
We convert the texts into lower case. It makes the words look similar. For example, the PDF and pdf will be the same words for analysis purposes
extracteddata <- tm_map(extracteddata , content_transformer(tolower))
-
The below command removes the common words for the English language from the extracted PDF data
extracteddata <- tm_map(extracteddata , removeWords, stopwords(“english”))
-
Remove any punctuation marks from the extracted text
extracteddata <- tm_map(extracteddata , removePunctuation)
-
Remove the numbers from the extracted text
extracteddata <- tm_map(extracteddata, removeNumbers)
- PDF – 7 times
- Files – 6 times
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023
|
1 2 3 4 5 6 7 |
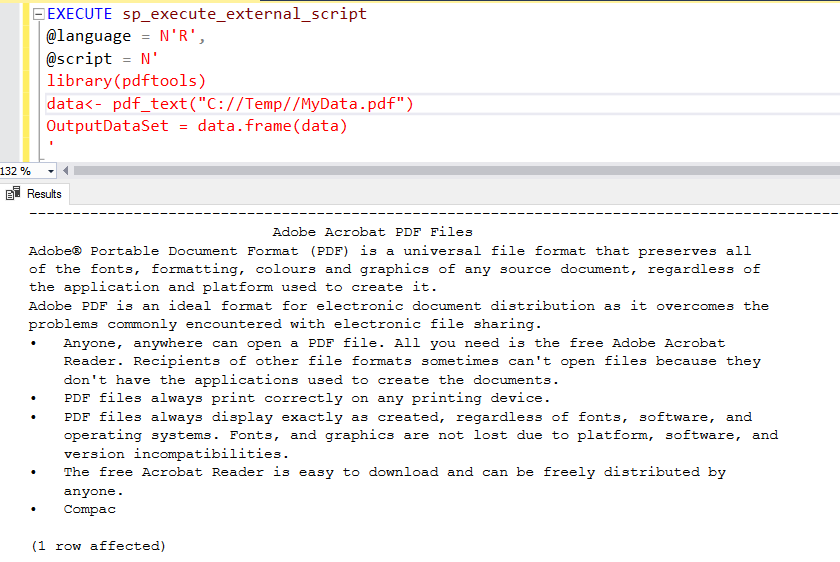
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(pdftools) data<- pdf_text("C://Temp//MyData.pdf") OutputDataSet = data.frame(data) ' |
In the Grid format, the PDF text appears in a single block.

In the above screenshot, we do not get any column heading. To display the heading, we can specify it using the WITH RESULT SET in R Scripts SQL Server and define the column header name with its data type.
|
1 2 3 4 5 6 7 8 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(pdftools) data<- pdf_text("C://Temp//MyData.pdf") OutputDataSet = data.frame(data) ' with result sets (("Extracted Text from PDF" varchar(max))) |

If you display result in the text ( Result to text – CTRL+T) in SSMS, it gives you formatted data because it reads whole data in a text format ( 1 row affected).
Similarly, you can modify the R Scripts SQL Server with the strsplit() function and split the extracted text into multiple lines.
|
1 2 3 4 5 6 7 8 9 |
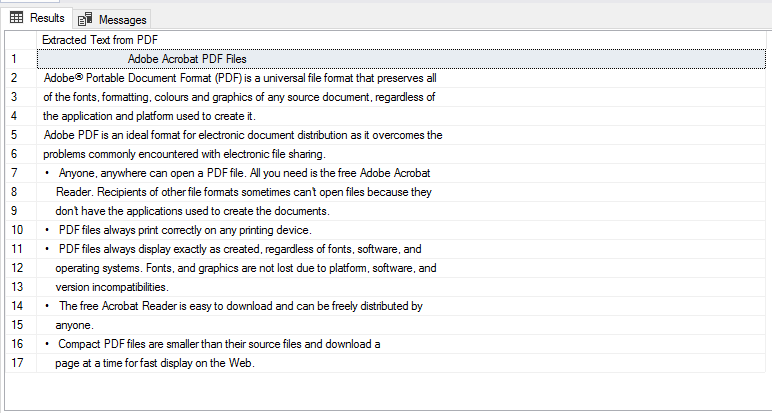
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(pdftools) data<- pdf_text("C://Temp//MyData.pdf") Splitdata<-strsplit(data,"\n") OutputDataSet = data.frame(Splitdata) ' with result sets (("Extracted Text from PDF" varchar(max))) |
Now, we have 17 lines in the SSMS grid result as per our original document.
Read data from a PDF file and Insert data into SQL Server table
Till now, we have read data directly from the PDF file using the SQL Server R script. Most of the time, we want to import into SQL tables as well.
For this purpose, create a SQL table and define the data type as Varchar(). You should use the appropriate data length in the varchar(). For the demonstration purpose, I specified it as varchar(1000).
|
1 2 3 4 5 |
Create table DemoDB.dbo.ExtractedPDFData ( id int identity, ExtractedText varchar(1000) ) |
|
1 2 3 4 5 6 7 8 9 |
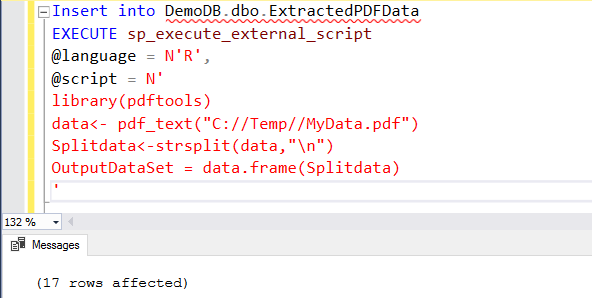
Insert into DemoDB.dbo.ExtractedPDFData EXECUTE sp_execute_external_script @language = N'R', @script = N' library(pdftools) data<- pdf_text("C://Temp//MyData.pdf") Splitdata<-strsplit(data,"\n") OutputDataSet = data.frame(Splitdata) ' |
Once you run the below T-SQL with the SQL Server R Script, it does not display the extracted text into the SSMS output. It inserts data into newly created [ExtractedPDFData].
You can query the SQL table, and it shows you the extracted data from the pDF file using SQL Server R Script.
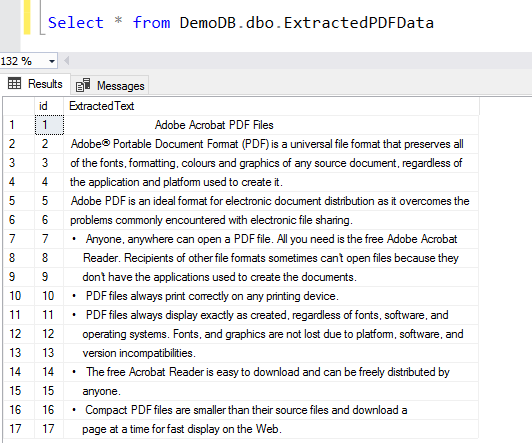
Text mining using Machine learning language R Scripts SQL Server for the PDF data
We can do text mining using the imported data from a PDF file using the SQL Server R script. Text mining means doing data analysis on input data.
You need to install the tm external package for this demonstration.
install.packages(“tm”)
library(“tm”)
Here, we do not cover text mining in detail, but this article gives you an overview of implementing it for your dataset. The Corpus is a collection of text documents so that we can apply text mining.
data <- pdf_text(“MyData.pdf”)
extracteddata <- Corpus(VectorSource(text))
Now, on the extracted data, we apply the following transformations:
Now, we want to prepare the term-document matrix for the top 3 used words. It displays the words and their frequency in the extracted data.
In the below script, we use the TermDocumentMatrix to construct a term-document matrix. We further sort the data and sort them in descending order of their frequency. Further, it displays the top 2 records using the head() function.
extracteddata_matrix <- TermDocumentMatrix(extracteddata)
m <- as.matrix(extracteddata_matrix)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
head(d, 3)
Let’s convert it to SQL Server R script and then execute the t-SQL. In the below R script, we embed the code into the @script argument.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(pdftools) library("tm") data<- pdf_text("C://Temp//MyData.pdf") extracteddata <- Corpus(VectorSource(data)) extracteddata <- tm_map(extracteddata , content_transformer(tolower)) extracteddata <- tm_map(extracteddata , removeWords, stopwords("english")) extracteddata <- tm_map(extracteddata , removePunctuation) extracteddata <- tm_map(extracteddata, removeNumbers) extracteddata_matrix <- TermDocumentMatrix(extracteddata) m <- as.matrix(extracteddata_matrix) v <- sort(rowSums(m),decreasing=TRUE) d <- data.frame(word = names(v),freq=v) print(head(d,2)) ' |
As per the below script output, we have the following word frequency.

To verify the same, open the PDF file and search for the keywords PDF and Files. As shown below, it matches the frequency of the words received in the SQL Server R script output.

Conclusion
In this article, we explored reading data from a PDF document using the SQL Server R script. Further, we saw an example of text mining on the extracted data. You can further explore more useful functions for text mining using the R service documentation.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta