
As a part of a Big Data project, we are often asked to find the best way to track the changes applied to the database tables, so that, no requirement is created to load all the huge tables to the data warehouse database at the end of the day, if not all of the data was changed.
The first available option in SQL server for tracking the changes are the After Insert, After Update and After Delete triggers, that requires coding effort from your side in order to handle these changes or added data, in addition to the performance impact of the triggers on the system.
Change Data Capture
Another tracking and capturing solution introduced in SQL Server 2008 Enterprise, that tracks any Insert, Update or Delete operation applied to the user tables , with What , When and Where these changes applied, without any extra coding effort and keep it in system tables that can be easily accessed using normal queries. This new feature is called SQL Server Change Data Capture, or CDC.
When Change Data Capture is enabled on a user table, a new system table will be created with the same structure of that source table, with extra columns to include the changes metadata.
SQL Server Change Data Capture uses the SQL Server transaction log as the source of the changed data using asynchronous capture mechanism. Any DML change applied to the tracked table will be written to the transaction log. The CDC capture process reads these logs and copy it to the capture table and finally adding the associated changes information as the change metadata to the same table.
Below we will have a small demo showing how to configure the CDC on one of the SQLShackDemo database tables. As recommended by Microsoft, we will create a separate Filegroup and database file to host the Change Data Capture change tables:
First we will create a new Filegroup using the ALTER DATABASE ADD FILEGROUP SQL statement:
|
1 2 3 4 5 6 |
USE [master] GO ALTER DATABASE [SQLShackDemo] ADD FILEGROUP [CDC] GO |
Once the Filegroup is created, a new database file will be created in this filegroup using ALTER DATABASE ADD FILE SQL statement:
|
1 2 3 4 |
ALTER DATABASE [SQLShackDemo] ADD FILE ( NAME = N'SQLShackDemo_cdc', FILENAME = N'D:\CDC File\SQLShackDemo_cdc.ndf' , SIZE = 2048MB , FILEGROWTH = 128MB ) TO FILEGROUP [CDC] GO |
As the cdc.lsn_time_mapping system table will grow to a significant size and will have many I/O operations due to the table’s changes, it is also recommended to change the default filegroup for the database before you execute sys.sp_cdc_enble_db to the CDC filegroup created previously and change it back to the Primary filegroup once the metadata tables are created.
To make the CDC Filegroup as the default filegroup, we will use the MODIFY FILEGROUP statement below:
|
1 2 3 4 5 6 |
USE [SQLShackDemo] GO ALTER DATABASE [SQLShackDemo] MODIFY FILEGROUP [CDC] DEFAULT GO |
In order to enable the Change Data capture on the tables that you need to track and capture its DML changes, you need first to enable it on the database level. This can be done by executing the sys.sp_cdc_enable_db system stored procedure as follows:
|
1 2 3 4 5 6 |
USE [SQLShackDemo] GO EXEC sys.sp_cdc_enable_db GO |
We can change back the default FileGroup now to the PRIMARY filegroup as follows:
|
1 2 3 4 5 6 |
USE [SQLShackDemo] GO ALTER DATABASE [SQLShackDemo] MODIFY FILEGROUP [PRIMARY] DEFAULT GO |
To make sure that the CDC is enabled in the SQLShackDemo database, we will query the sys.databases table as below:
|
1 2 3 4 5 6 7 8 |
USE master GO SELECT [name], database_id, is_cdc_enabled FROM sys.databases WHERE is_cdc_enabled = 1 GO |

One the CDC is enabled on the database level, a new schema will be created in that database with the “CDC” name:
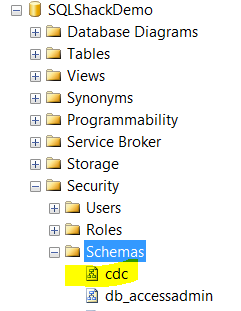
Also, new system tables will be created under the CDC schema:
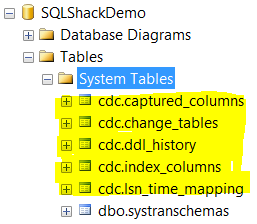
The role of these tables are as each table’s name indicates. The cdc.captured_columns contains the list of captured columns. The cdc.change_tables contains list of database tables with CDC enabled on it. The cdc.ddl_history contains the history of the DDL changes applied on the tracked table. The cdc.index_columns contains the tracked table’s indexes. And the cdc.lsn_time_mapping that maps LSN number.
Now we will enable the Change Data Capture on the table’s level. As the CDC is a table-level feature, you need to enable it on each table you need to track and capture its DML changes.
To enable the CDC on the AWBuildVersion table from the SQLShackDemo database, we will run the sys.sp_cdc_enable_table system stored procedure:
|
1 2 3 4 5 6 7 8 9 |
EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'AWBuildVersion', @role_name = NULL, @filegroup_name = N'CDC', @supports_net_changes = 0 GO |
It is better to limit the number of columns to be captured by the CDC to only the ones you really need to track. You can use the @captured_column_list parameter of the sys.sp_cdc_enable_table system SP to specify the list of columns that will be included in the change table to be tracked.
Once the change data capture is enabled on the table level, a new capture instance associated to that source tables is created to support the propagation of the source table’s changes. This capture instance contains the change table. By default, the name of this change table is SchemaName_SourceTableName_CT.
To make sure that the CDC is enabled in our table successfully, we will query the sys.tables system tables for the is_tracked_by_cdc property as below:
|
1 2 3 4 5 6 |
SELECT [name], is_tracked_by_cdc FROM sys.tables WHERE is_tracked_by_cdc=1 GO |

Also you can check the tracked tables by querying the [cdc].[change_tables]
CDC table with the result same as follows:

And the list of columns captured in that table can be viewed by querying the [cdc].[captured_columns] CDC table. The output will be like:

You should make sure that the SQL Server Agent Service is enabled before enabling the CDC at the table level, as the CDC will create two new SQL Server jobs for each CDC- enabled database as follows:

The capture job will run the sys.sp_MScdc_capture_job. System SP to capture the changes, and the cleanup job will call the sys.sp_MScdc_cleanup_job system SP to clean up the change table.
The default retention period is three days, this means that the data will be kept in the change table for three days before removing it. You can override this value by executing the sys.sp_cdc_change_job system SP specifying a new retention value in minutes:
|
1 2 3 4 5 |
EXECUTE sys.sp_cdc_change_job @job_type = N'cleanup', @retention = 2880; |
Now we reach to the point where the change data capture is enabled on the AWBuildVersion table from the SQLShackDemo database. This means that any change that will be applied to that table will be captured and written to the CDC capture table. If you perform INSERT operation, then the new value after the INSERT operation will be written in the capture table as one record. If you perform DELETE operation, the value before the DELETE operation will be written to the capture table as one record. Any UPDATE operation performed on the tracked table, two records will be written to the capture table, one for the value before the UPDATE and one for the value after UPDATE.
The _$operation column from the CDC change table contains the DML operation type, where 1 indicates DELETE operation, 2 indicates INSERT operation, 3 indicates the value before the update process and 4 the value after the update process.
For example. If we apply the below insert statement on the SQLShackDemo database, and try to query the dbo_ AWBuildVersion_CT change table, we will find a new record written on it showing the new inserted value:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE [SQLShackDemo] GO INSERT INTO [dbo].[AWBuildVersion] ([Database Version] ,[VersionDate] ,[ModifiedDate]) VALUES ('11.0.2100.60','2012-03-14 00:00:00.000','2016-03-02 00:00:00.000') GO |

On the other hand, if we apply the below update query on the same table, a new two records will be written to the capture table showing the value before the update with _$operation =3 and the value after the update with _$operation =4:
|
1 2 3 4 5 |
UPDATE [SQLShackDemo].[dbo].[AWBuildVersion] SET [Database Version] ='11.0.2100.80' WHERE [SystemInformationID]=5 |

It is good to know that enabling change data capture in your SQL Server database table will not prevent you from applying any DDL changes on that table. But will this new change be reflected to the CDC change table? The answer depends on the change type; if you change the data type of a CDC- enabled table’s column, the new data type will be reflected to the change table and the tracking and capturing process will not be affected.
If you drop a CDC- enabled table’s column, NULL values will be inserted for that column for each change entry in the change table. But if you add new column to the CDC- enabled table, this change will not be reflected to change table and any change on this column will not be captured.
Let’s add a new column to our AWBuildVersion table, that we enabled the CDC on it:
|
1 2 3 4 5 |
ALTER TABLE dbo.AWBuildVersion ADD TS datetime NULL GO |
To check if this change is reflected to the CDC change table, we will query the cdc.captured_columns system table, which unfortunately shows that the change is not reflected to the CDC change table:

And if we try to insert a new value to our table, using the insert statement below, the new column will not be shown:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE [SQLShackDemo] GO INSERT INTO [dbo].[AWBuildVersion] ([Database Version] ,[VersionDate] ,[ModifiedDate] ,[TS]) VALUES ('11.0.2100.80','2016-01-01 00:00:00.000','2016-03-02 00:00:00.000',Getdate()) GO |

As you can see, the CDC will keep tracking the changes applied on the table but ignoring the new added column.
To overcome this issue without losing the old captured data, we can create a new capture instance for the same source table that will reflect the new structure for that source table, where a new change table will be created associated with that new capture instance, then copy the change data from the old change table to the new one and finally disable the old capture instance. You can create up to two capture instances associated with the same source table at the same time.
In order to disable the CDC on the database level, you should disable it on all the tables that you enabled the CDC on it, then disable it on the database level as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
EXEC sys.sp_cdc_disable_table @source_schema = N'dbo', @source_name = N'AWBuildVersion', @capture_instance = N'dbo_AWBuildVersion' GO USE SQLShackDemo GO EXEC sys.sp_cdc_disable_db GO |
Change Tracking
Another lightweight tracking solution introduced in SQL Server 2008 is the Change Tracking or CT. What makes it light is that it only captured that this row in that table is changed, without capturing the data that is changed or keeping historical data for the value before the change, with the least storage overhead. CT works in all SQL Server editions such as Express, Workgroup, Web, Standard, Enterprise and DataCenter.
Change Tracking uses a synchronous tracking mechanism to track the table changes. The only information provided by the CT about the tracked table is the changed record’s primary key. To obtain the new data after the change, coding effort required from the application side to join the source table with the tracking table using the primary key value.
Same as the CDC, in order to enable the change tracking on the table level, you should enable it at the database level first:
|
1 2 3 4 5 |
ALTER DATABASE SQLShackDemo SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) |
Change tracking information that is older than Retention Period value specified previously will be removed automatically. The AUTO_CLEANUP option is used to enable or disable the cleanup task that delete the old CT information.
To make sure that the CT is enabled at the database level, you can browse the Change Tracking tape of the database properties window. You can also enable the CT from here:
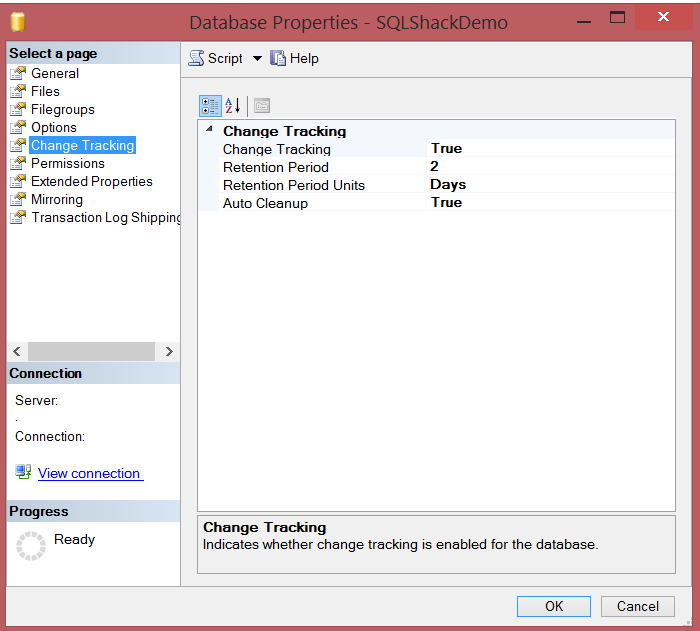
Again, the CT is a table-level feature, you need to enable it on each table you need to track and capture its DML changes. In order to enable the CT on the table level, the table should have primary key constraint defined previously. If you try to enable the CT on a table without primary key, you will get the error below:
Cannot enable change tracking on table ‘XXX’. Change tracking requires a primary key on the table. Create a primary key on the table before enabling change tracking.
Enabling the CT on the table level is achieved by running the ALTER TABLE ENABLE CHANGE_TRACKING
|
1 2 3 4 5 6 7 |
USE SQLShackDemo GO ALTER TABLE CountryInfo ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON) |
Or using the SQL Server Management Studio, from the Table Properties window:
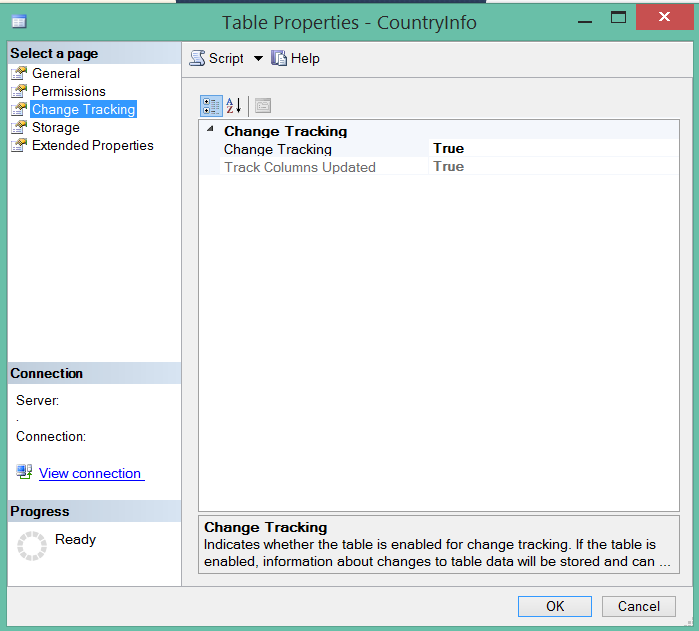
For example, if we apply the below insert statement to our table, we will find that the tacking current version value is changed from 0 to 1:
|
1 2 3 4 5 6 7 8 9 10 |
USE [SQLShackDemo] GO INSERT INTO [dbo].[CountryInfo] ([CountyCode]) VALUES ('AMM') GO |
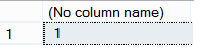
In order to get the value that is changed, we will query the CHANGETABLE system table that will return the primary key for the inserted value:
|
1 2 3 4 |
SELECT * FROM CHANGETABLE (CHANGES CountryInfo,0) as CT ORDER BY SYS_CHANGE_VERSION |
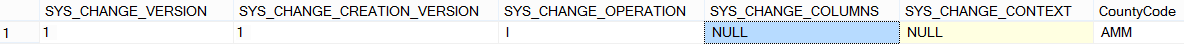
To get the complete changed record, it is easily to join the CHANGETABLE with the source table:
|
1 2 3 4 5 6 |
SELECT CI.* FROM CHANGETABLE (CHANGES CountryInfo,0) as CT JOIN CountryInfo CI on CT.CountyCode=CI.CountyCode |

Opposite to CDC, you can apply any DDL changes on the source table without affecting the CT except for the changes on the primary key will fail unless you disable the CT on that table.
If you try to change the primary key of the CountryInfo table, with the CT enabled on it, you will get the below error:
The primary key constraint ‘PK_CountryInfo_1’ on table ‘CountryInfo’ cannot be dropped because change tracking is enabled on the table. Change tracking requires a primary key constraint on the table. Disable change tracking before dropping the constraint.
In order to disable the CT on the database level, you should disable it on all the tables that you enablee the CT on it then disable it on the database level as follows:
|
1 2 3 4 5 6 7 8 |
ALTER TABLE [dbo].CountryInfo DISABLE CHANGE_TRACKING GO ALTER DATABASE SQLShackDemo SET CHANGE_TRACKING = OFF GO |
Conclusion
As you can see, there are many options available to track and capture the changes performed in your database. Choosing the suitable one depends on your requirements. You should compromise between the system performance, the IO load and the available storage to decide which one of the mentioned methods you will use. It is better to test these methods in your DEV environment applying a heavy load, so you will decide if it is suitable for your situation or not.
Useful Links:
- sys.sp_cdc_enable_table
- Tuning the Performance of Change Data Capture in SQL Server 2008
- Enable and Disable Change Data Capture
- About Change Tracking
- Comparing Change Data Capture and Change Tracking
- Enable and Disable Change Tracking

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021