
Introduction
How often are you working with multiple environments? For example, if you are a database administrator who is responsible for a production environment as well as another environment, it most likely that you will be working with both environments simultaneously. What is the probability that you will execute a script on production, which actually needs to be executed on the other environment? I would say it is high. To prove this point let me present you an example.
A novice dba was working in multiple database servers using same SQL Server Management Studio (SSMS) in which both instances are registered. In this case, the dba has registered with their development server and the production server and for both servers. The dba has system administrative privileges. The dba had wanted to truncate customer table in the QA environment but guess what? … this script was executed in production. I don’t think I need to describe to you the consequences.
In another incident, a database administrator in a popular hospital needed to modify the column name of the most commonly used table. The previous length of the varchar column was 15 and the requirement was to expand the length the 50. However, instead of making it to 50, it was changed to 5. This action, of course, resulted in lost data.
In both cases, the result was an accident and emergency help was required. Typically, you need your scheduled backups to restore your data to the point which you execute the incorrect script. However, you do not take backups every hour as that will negatively impact the performance of the system. If you are taking backups on daily basis and if you have to revert your database to the last backup, then you are talking about more data loss in order to capture latest data loss.
Before moving into how to recover data, let us briefly go through the architecture of the databases in SQL Server.
Every SQL Server database has at least two files. The first one is the data file or the mdf file and the second one is transaction log file or the ldf file. Like most database systems, SQL Server uses Write Ahead Logging (WAL) which means every transaction first written to the database log and then it will be written to the data file using a CHECKPOINT operation. This is mainly done to maintain the ACID properties of a transaction. More information can be seen at https://technet.microsoft.com/en-us/library/ms186259(v=sql.105).aspx
Recovery Models
In databases, there are recovery models such as SIMPLE, FULL, and BULK-LOGGED. This setting decides how log records of the database behave. This can be modified at the database option page. Please note that after modifying the recovery model you need to issue a full backup.
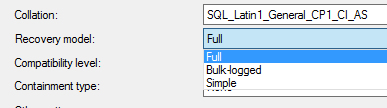
In the case of the FULL recovery model, log records will stay in the log file as inactive status. Log backups will clear the inactive records and those records will be backed up. In the case of the SIMPLE recovery model, as soon as the record is inactive, the record will be deleted from the log file. This means that with the SIMPLE recovery model, you do not have a record of the transaction. However, many novice database administrators choose SIMPLE recovery model as it won’t increase the log file size. BULK-Logged recovery model falls between SIMPLE and FULL recovery models. Apart from some commands, all the other transactions will be logged.
Point in Time Recovery
With the all the basic information we have, let us simulate in an incident where accidental data loss has occurred.
Let us assume that we have a database with full recovery model. For the demonstration purposes, let us create a table and populate a table.
Let us say that, there was a data delete on a specific time. Now your task is to recover them.
Immediately log backup needs to be executed either from T-SQL or from User Interface.
|
1 2 3 4 5 6 |
BACKUP LOG [DB] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Backup\DB_Log.bak' GO |
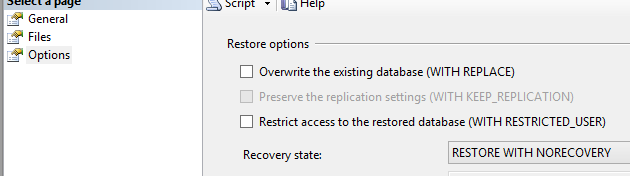
Next, restore the full backup to a different database, but make sure you have to set recovery state to NORECOVERY. If you are restoring log backups or differential backups over the existing database, the state should be NORECOVERY.
Similarly, you have the option of executing this using a T-SQL.
|
1 2 3 4 5 6 7 8 9 |
RESTORE DATABASE [DB2] FROM DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Backup\DB.bak' WITH FILE = 1, MOVE N'DB' TO N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\DB2.mdf', MOVE N'DB_log' TO N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\DB2_log.ldf', NORECOVERY, NOUNLOAD, STATS = 5 |
In case you have differential backups, you need to restore the latest differential backups.
The next step is to restore the log backup, stating the date/time to recover the data. Before that, a log backup should be selected. In case you have multiple log backups, you need to select all the log backups as every log backup has incremental data. In case you have a differential backup, you do not need to select log backups before the differential backups, instead, you can choose the last differential backups and the transactional log backup taken after the differential backups.
The next step is to select a time to which will be your point to which you want to recover your data. As shown in the below image, you need to select the Point in time option.
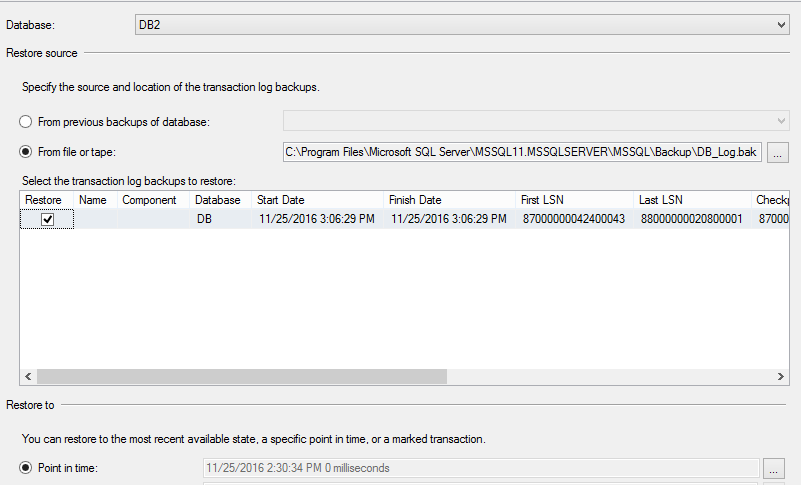
Then the time needs to be selected.
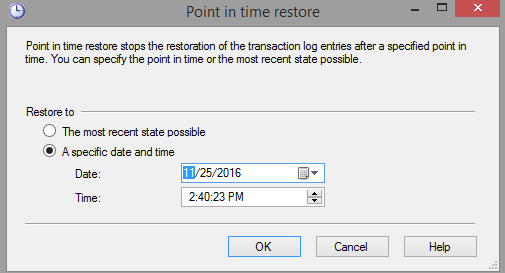
As usual this can be done using a T-SQL script as well which is shown below.
|
1 2 3 4 5 6 |
RESTORE LOG [DB2] FROM DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Backup\DB_Log.bak' WITH FILE = 1, NOUNLOAD, STATS = 10, STOPAT = N'2016-11-25T14:30:34' |
With this, data is recovered to a specific time, which can be verified by running query as it will retrieve the deleted data.
Improved User Interface
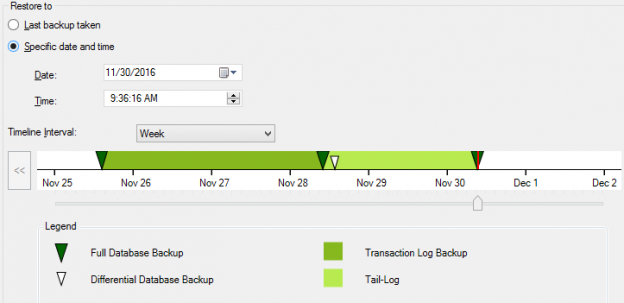
From SQL Server 2012 onwards, you have an improved user interface so that users simply need to point to the timeline. Also, it shows backup types with different symbols and different colors as shown in the below image.
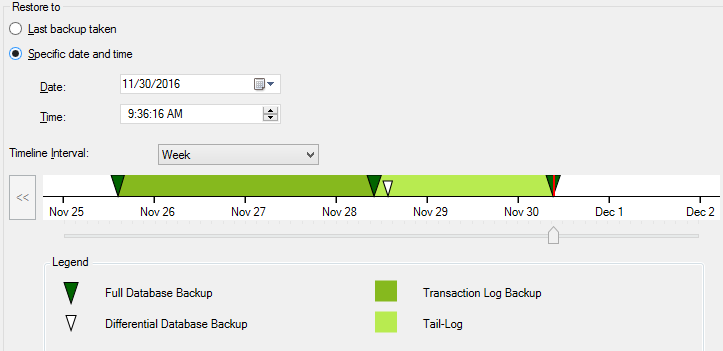
Full backups and differential backups are shown with pointed arrowheads. This means that from full backups and differential backups you can recover to a time which the backup was taken. In the case of Transactional log backups, it shows a range. This means that you can recover any point with the given range.
Best Practices
Many organizations have implemented Full backups and Transactional log backups as data backup in SQL Server. Though this mechanism is technically feasible, there are practical and implementation difficulties. Just imagine that you have implemented a weekly full backup and every 15 minutes, a log backup. This means there will be (4*24*7) 672 log backups per week. In a case of a disaster recovery, the number of files you need to implement is very large. This can be avoided by including differential backup for daily frequency. The introduction of differential backup means, that in the case of a disaster you can restore the last full backup, last differential backup, and the log backups which were taken after the last differential backup. This will reduce the restoration of number log backups. The maximum, you need are 96 log backup files. With this method, you are not only improving the restore time and operation easiness, but also you are also reducing the risk of file corruption.
Summary
Point in time recovery is very useful for database administrators in case of a need to recover of accidental data deletes or drops. By keeping the database recovery model with FULL or BULK-LOGGED, you will be able to recover data to point of a time.

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021