
Background
In multi-user environments, changes may occur frequently to the architecture, data, or overall structure that creates work for other users. In this series, we look at some ways that we can track changes on the data and architecture layer for pin-pointing times, changes, and using the information for alerting, if changes should be kept to a minimum. SQL Server comes with some built-in tools that allow us to monitor changes, and depending on the architecture, we can create tools that allow us also to monitor and identify changes near the time that they occur.
Discussion
In this article, we’ll look at adding change data capture to a specific table, as well as how we can track the changes with meaningful queries, along with some useful considerations when enabling this feature.
First, let’s create a simple table:
|
1 2 3 4 5 6 7 |
CREATE TABLE [dbo].[tblMyNewTable]( [ID] [smallint] IDENTITY(1,1) NOT NULL, [Name] [varchar](50) NULL, [OtherID] [tinyint] NULL ) |
We’re not going to populate data yet, but we will in a second. We want to first create the table and from there check to see if change data capture is enabled on the database level:
|
1 2 3 4 5 |
SELECT is_cdc_enabled FROM sys.databases WHERE name = 'OurDatabase' |
If the above returns a 0, it means that it is not enabled and we want to enable it. Once we enable change data capture, we want to verify that it’s enabled by running the above query again (we should see a 1).
|
1 2 3 |
EXEC sys.sp_cdc_enable_db |
In the below image, I ran change data capture check before, enabled it, then ran it again and as we see, it changed from 0 to 1.
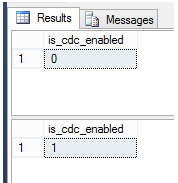
Now, we will specifically enable tracking data changes on the table level. Because many architecture problems begin with poor naming convention, this is a step where we want to consider what other names we may develop for other objects; I’ve solved numerous problems where the simple problem was poor naming convention. For this reason, my naming convention includes change data capture (cdc) – or what it is – along with its purpose – auditing – and the table name – tblMyNewTable. In essence, I’m answering three questions in this naming convention:
- The name answers what the object is.
- The name answers what the purpose of the object is.
- The name answers what the target object is. In the case of change data capture in this example, the target is a table.
Anytime you hear a colleague or co-worker suggest that, “This is the one time we should make an exception,” recognize that this mentality often leads to more work and often is the cause of problems – often, people forget why or what the exception was!
|
1 2 3 4 5 6 |
EXEC sys.sp_cdc_enable_table @source_schema = 'dbo' , @source_name = 'tblMyNewTable' , @role_name = NULL , @capture_instance = 'cdcauditing_tblMyNewTable' |
When we enable this, we should see a confirmation message stating that two jobs were started successfully – a capture and cleanup job. We can confirm this by looking through the SQL Server agent jobs and see the two jobs enabled – keep this in mind when disabling it and wanting to make sure that the jobs are removed. Up to this point, we haven’t populated any data in the table, but let’s do that now so that we can see how we’ll track our changes and how our changes will appear in the tracking information:
|
1 2 3 4 5 6 7 8 9 10 |
INSERT INTO tblMyNewTable (Name,OtherID) VALUES ('John',1) , ('Jane',2) , ('Sarah',3) , ('Sean',4) SELECT * FROM tblMyNewTable |
When we select from the table, we should see the following:
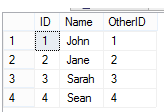
We must recall that change data capture monitors the change through the log, so we must know the LSNs in order to monitor the changes. In this case, we’ll be retrieving the minimum LSN to identify what’s been changed to the maximum LSN. We have two functions that help us retrieve the minimum and maximum LSN that we can save to variables, so that we can pass in the necessary parameters to monitor changes. Think of this as similar to a where clause when we’re looking from a begin date to an end date:
|
1 2 3 4 5 6 |
DECLARE @begin binary(10), @end binary(10); SET @begin = sys.fn_cdc_get_min_lsn('cdcauditing_tblMyNewTable'); SET @end = sys.fn_cdc_get_max_lsn(); SELECT * FROM cdc.fn_cdc_get_all_changes_cdcauditing_tblMyNewTable(@begin, @end, N'ALL') |

The output from the above query.
When using the function cdc_get_all_changes, we pass in begin, end, and row filter parameters – ALL in this case. In the latter parameter we can specify either ALL, which will return all changes with updates being shown with their new values only, or all update old, where both the previous and new value of an update is shown (later in the article, we see an image comparing these two differences side-by-side). Because we have not updated any data so far, running ‘all update old’ as a parameter won’t show us anything different than our current output:
|
1 2 3 4 5 6 |
DECLARE @begin binary(10), @end binary(10); SET @begin = sys.fn_cdc_get_min_lsn('cdcauditing_tblMyNewTable'); SET @end = sys.fn_cdc_get_max_lsn(); SELECT * FROM cdc.fn_cdc_get_all_changes_cdcauditing_tblMyNewTable(@begin, @end, N’all update old') |
Let’s update a record, add a new record, and remove a record:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
UPDATE tblMyNewTable SET Name = 'Jane Doe' WHERE Name = 'Jane' DELETE FROM tblMyNewTable WHERE Name = 'John' INSERT INTO tblMyNewTable (Name,OtherID) VALUES ('Jason',5) |
And let’s run our check from the above changes – this time we will be querying both the :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @begin binary(10), @end binary(10); SET @begin = sys.fn_cdc_get_min_lsn('cdcauditing_tblMyNewTable'); SET @end = sys.fn_cdc_get_max_lsn(); SELECT * FROM cdc.fn_cdc_get_all_changes_cdcauditing_tblMyNewTable(@begin, @end, N'ALL') DECLARE @begin2 binary(10), @end2 binary(10); SET @begin2 = sys.fn_cdc_get_min_lsn('cdcauditing_tblMyNewTable'); SET @end2 = sys.fn_cdc_get_max_lsn(); SELECT * FROM cdc.fn_cdc_get_all_changes_cdcauditing_tblMyNewTable(@begin2, @end2, N'all update old') |
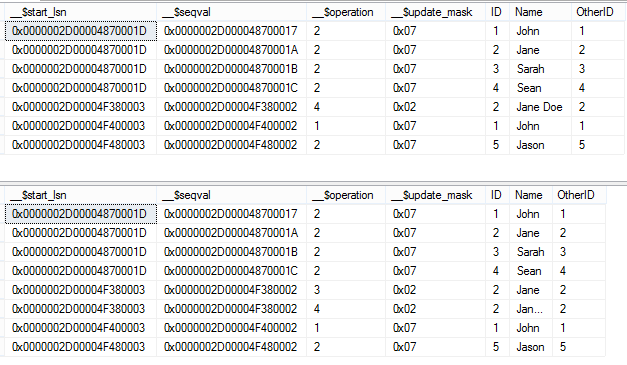
Finally, to make the output more meaningful as far as what transactions happened, we can use the below query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @begin binary(10), @end binary(10); SET @begin = sys.fn_cdc_get_min_lsn('cdcauditing_tblMyNewTable'); SET @end = sys.fn_cdc_get_max_lsn(); SELECT __$start_lsn --, __$seqval , CASE WHEN __$operation = 1 THEN 'DELETE' WHEN __$operation = 2 THEN 'INSERT' WHEN __$operation = 3 THEN 'PRE-UPDATE' WHEN __$operation = 4 THEN 'POST-UPDATE' ELSE 'UNKNOWN' END AS Operation --, __$update_mask , ID , Name , OtherID FROM cdc.fn_cdc_get_all_changes_cdcauditing_tblMyNewTable(@begin, @end, N'all update old') |
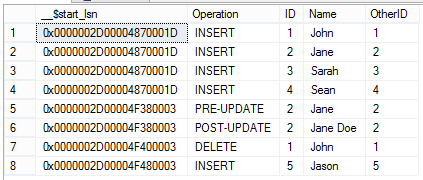
We can see the translated information shown, which our inserts, update and delete performed on the table. When looking at the data changes in a table, we’ll may want to filter for specific operations – such as deletes in some cases, so keep in mind that we can apply filtering as well (such as filtering where the operation equals delete). In addition, we might want to use some of the information for time-based monitoring, or column-based monitoring; for an example, in the above image, we may not care what OtherID is added, removed, or changed – the name may be the only value we want to monitor.
Some useful tips and questions
Some cautions about enable change data capture:
- Like all auditing, change data capture increases overhead on a server. We should heavily scrutinize the reason that we’re adding it in the first place.
- Keep an eye on SQL Server job agent, as it uses this. If this goes offline, or restarts, this will have an effect.
- Stick to consistent naming conventions so that you can quickly identify if it’s enabled and on what objects; otherwise, when you’re troubleshooting problems, you may miss on identifying the issue related to change data capture.
- Similar to point one, some objects – due to their nature – should not have this feature enabled, such as a fully replicated table (audit the publisher table), or adding it to an automated ETL process (audit the application). With every architecture structure, identify where the best place to audit the data is – and with the exception of many changes – it’s often early in the process.
Final Thoughts
In this article we looked at enabling the change data capture on a table and experimented with obtaining the changes. This is one way that we can track data changes on the table-level and query what’s been changed. While this feature is useful, we should also consider architecting it in a way that allows us to make sure it doesn’t create disruptions and that we can identify the objects being monitored quickly.
References

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020