
Azure SQL Database is a popular choice for migrating your database from on-premises to cloud infrastructure. It enables you to move to a fully managed Platform as a Service (PaaS) with desired performance and cost-effectiveness.
Azure SQL Databases has two pricing models – DTUs and vCores.
DTUs based purchasing model
The Database Transaction Unit (DTU) combines the compute (CPU), memory, IOPS. You cannot increase individual resources such as memory or CPU. However, you can increase the number of DTUs to increase the resources for the Azure database. This solution is suitable for clients who look for a predefined resource configuration with a balanced CPU, Memory, and IO.
x Azure SQL Databases provides Basic, Standard, and Premium service tiers for different ranges of compute, storage. You can easily migrate to another service tier; however, it requires minimal downtime during the switch-over period.
The following table compares the Basic, Standard, and Premium service tiers.
Basic | Standard | Premium | |
Uptime SLA | 99.99% | 99.99% | 99.99% |
Maximum storage size | 2 GB | 1 TB | 4 TB |
Maximum DTUs | 5 | 3000 | 4000 |
IOPS (approximate)* | 1-4 IOPS per DTU | 1-4 IOPS per DTU | >25 IOPS per DTU |
Maximum backup retention | 7 days | 35 days | 35 days |
Columnstore index | Not supported | Supported for S3 and above | Supported |
In-memory OLTP | Not supported | Not supported | Supported |
vCore based purchasing model
The term vCore refers to the Virtual Core. In this purchasing model of Azure SQL Database, you can choose from the provisioned compute tier and serverless compute tier.
- Provisioned compute tier: You choose the exact compute resources for the workload.
- Serverless compute tier: Azure automatically pauses and resumes the database based on workload activity in the serverless tier. During the pause period, Azure does not charge you for the compute resources.
The vCore model has the following service tiers.
General Purpose
The general purpose is the default service tier for the generic workload. It offers 99.99% SLA and storage latency between 5 to 10 milliseconds.
- Note: All images in this article are referenced from Microsoft documentation
The general-purpose service tier has two layers.
- Stateless compute layer that runs sqlserver.exe process. It contains transient and cache data such as plan cache, buffer pool, column store pool. The Azure Service Fabric operates this stateful layer and includes tasks such as initialization, controlling the health of compute nodes and failover whenever required
- The Stateful compute layer stores database files ( MDF, LDF) on the Azure blob storage. Azure storage has its in-built features for data availability and redundancy
- It supports 5 GB to 4 TB SQL Database in the provisioned and 5 GB to 3 TB in serverless computing
Business-critical
The business-critical layer is suitable for critical applications that require the highest resilience and highest database IO performance per replica. It offers 99.995% availability in the Multi-AZ configuration and low storage latency of 1-2 milliseconds.
The business-critical service tier also offers a guaranteed RPO of 5 seconds and RTO of 30 seconds using geo-replication. In addition, you can use 5 GB to 4 TB storage in the business-critical tier.
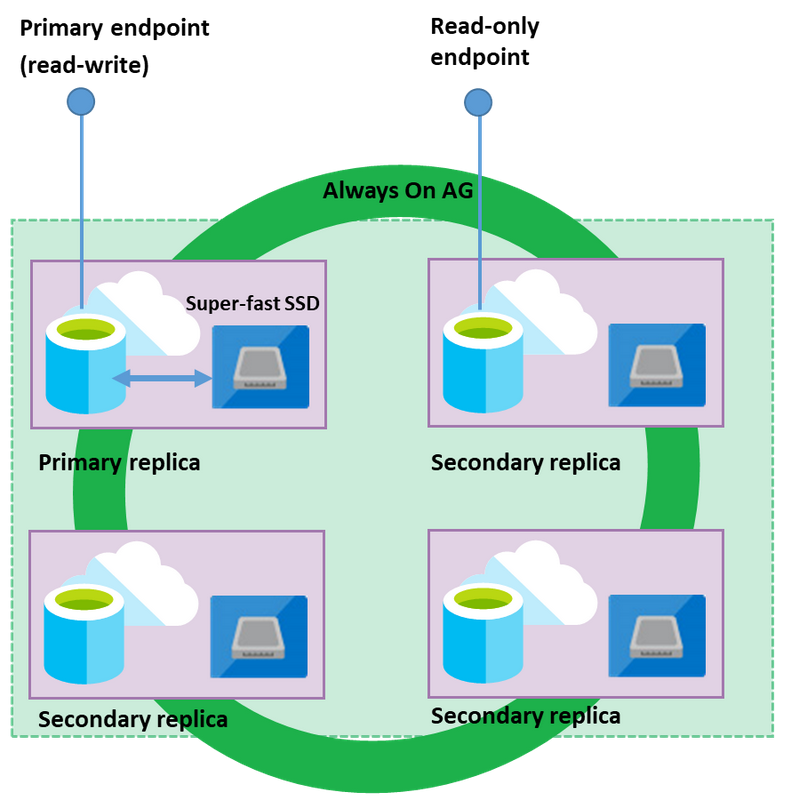
In this model, both the SQL Server process (sqlserver.exe) and the underlying database files (MDF, LDF) exists on the same node. It uses the locally attached super-fast SSD for the very low latency for the database workload. It also uses Always On Availability Groups for maintaining a cluster of database nodes. Three secondary replicas receive data from the primary node. In case of failure of the primary node, the secondary replica takes over the role as a primary replica and starts responding to database queries. The primary endpoint always points to the current active replica.
The Business-critical service tier also uses the read-scale out feature for offloading the read-only workloads to one of the secondary replicas. Again, it might improve primary database performance because you can offload your work, such as reporting queries to the secondary. Again, this feature is available in the business-critical service tier without any additional cost.
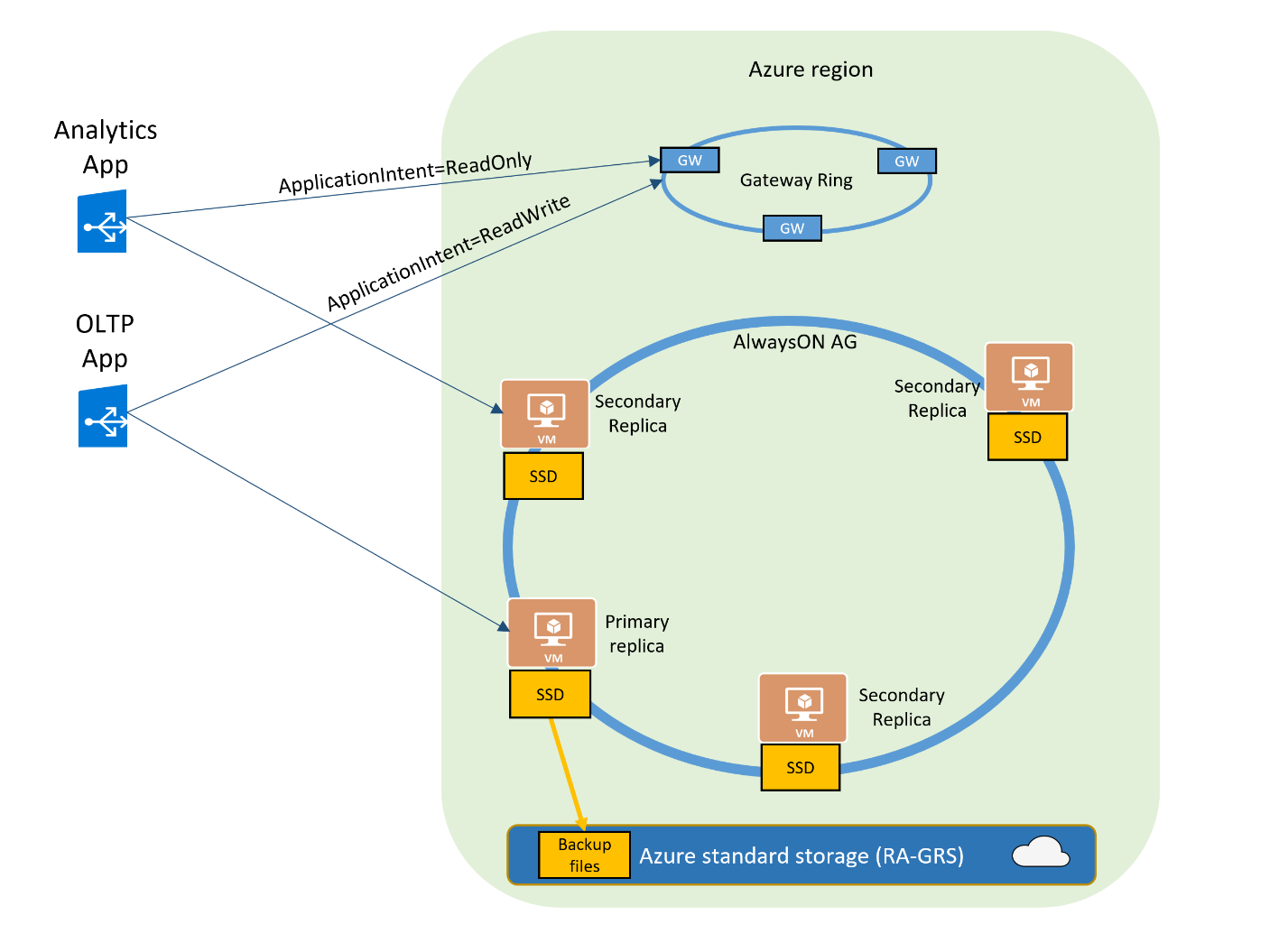
You can specify the parameter in the connecting string to connect with a primary or secondary read-only replica.
- ApplicationIntent=Readonly: The connection is redirected to the secondary read-only replica
- ApplicationIntent=Readonly ( default): The connection happens with the primary replica
Hyperscale
The Hyperscale service tier is suitable for highly scalable storage requirements. It offers high performance and scalability with an auto-scale up to 100 TB for Azure SQL Database.
The Hyperscale database contains the following components:
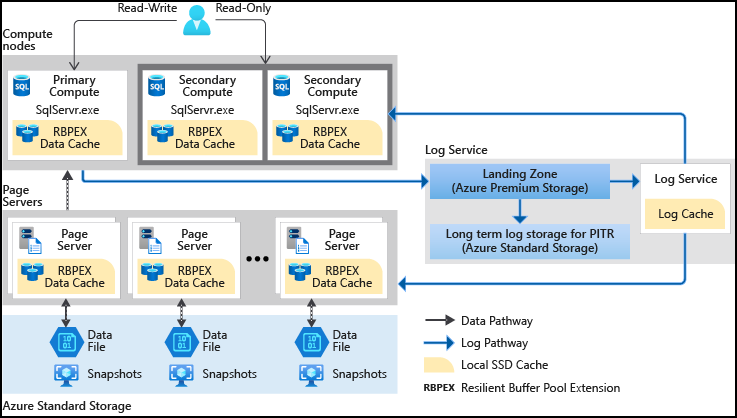
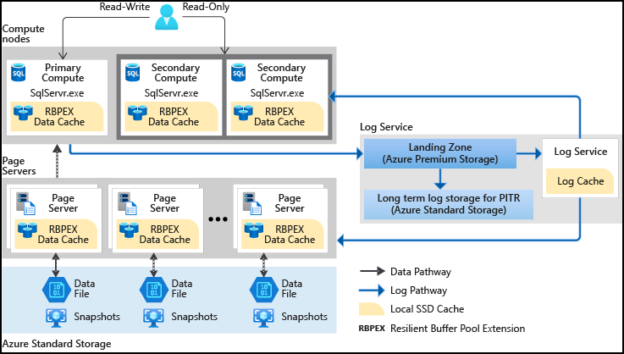
- Compute node: The compute node uses SSD based caching called Resilient Buffer Pool Extension (RBPEX). It ensures the minimum network roundtrips for fetching a data page. The primary compute node serves all read-write workloads. The secondary nodes work as hot standby nodes, and you can offload read workloads if required
- Page Server: The page servers are responsible for a subset of pages in the hyperscale database. Each page server controls up to 1 TB of data. The page server job is to serve database pages to the compute node whenever required. It also keeps the pages updated as the transaction updates its data. It uses a log service so that pages are updated. As shown in architecture diagram, these page server also uses RPBEX data cache for fast response
- Log Service: The log service receives the primary compute replica log records, persists them in the durable cache and transmits them to the secondary replicas. It also sends these logs to the relevant page server. Therefore, all secondary compute replicas and respective page servers receive the data changes. It also pushes log records to the Azure standard storage for long term retention. Thus, it eliminates the requirement of frequent log truncation
- Azure Storage: The Azure storage stores all data files of the hyperscale database. The page servers update these data files and keep them up-to-date. In addition, Azure uses storage snapshot of data files for backups and restoration
- Note:
- The vCore purchasing model is supported for both Azure SQL Database and Azure SQL Managed Instance
- The Hyperscale service tier is available for the v-Code based Azure single database
Migrate Azure SQL Databases from DTU to vCore purchase model
You can easily migrate from the DTU to vCore based purchase model similar to scaling out resources. It also requires minimal downtime for migration.
As a general thumb rule, you can map the DTU to vCores using the following formula:
- Every 100 DTUs Standard tier = 1 vCore of General Purpose
- Every 125 DTUs Premium = 1 vCore of Business Critical
- Note: This rule gives an approximate mapping between DTU and vCore. It does not consider the hardware generations or elastic pool
DTU to vCore mapping
We can use the following T-SQL query for Azure SQL Database configured with DTU model to return possibly matching the number of vCores in Gen4 and Gen5 hardware.
- Note: Execute this query in the Azure SQL Database, not on the Master database

For example, in my lab environment with a basic service tier, it returns the following output.
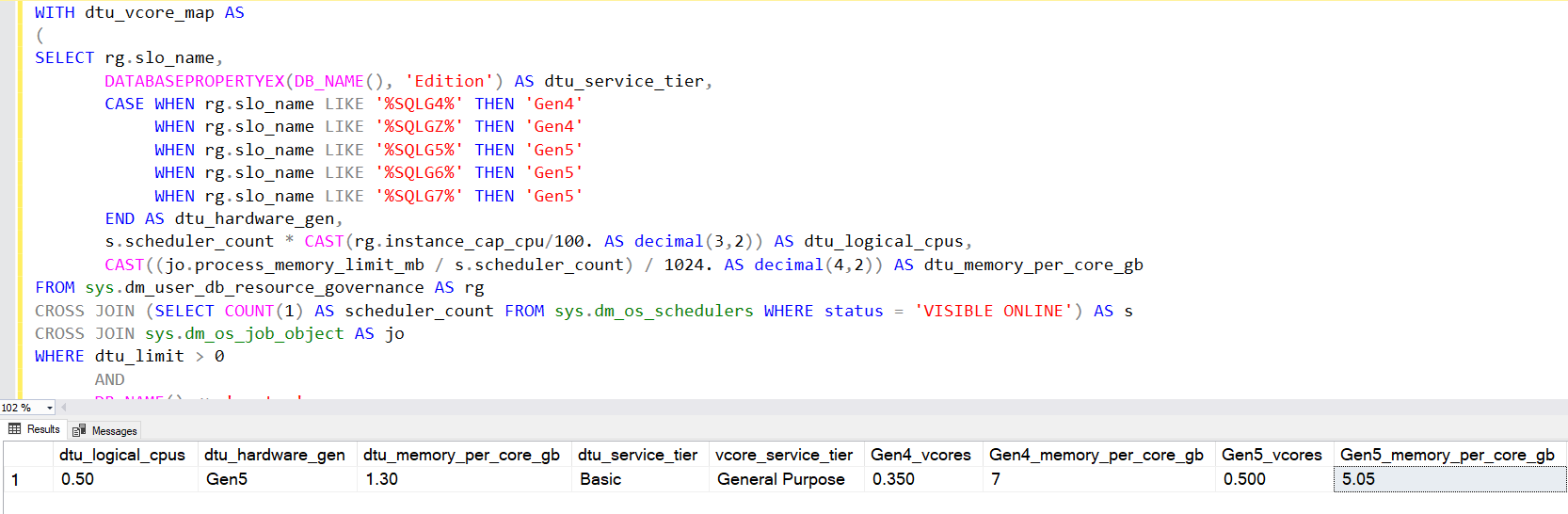
- The current DTU database has a 0.50 logical CPU with 1.30 GB memory per vCore on the Gen5 hardware
-
Approximate match:
- General-purpose service tier
- Gen4 hardware, 0.350 vCore, 7 GB memory per vCore
- Gen5 hardware, 0.500 vCores and 5.05 GB memory per vCore
You can refer to the article, Resource limits for single databases using the vCore purchasing model and choose the appropriate vCore model based on the recommended values.
Similarly, the following table refers to Migrating a Premium P15 database.
dtu_logical_cpus | dtu_hardware_gen | dtu_memory_per_core_gb | Gen4_vcores | Gen4_memory_per_core_gb | Gen5_vcores | Gen5_memory_per_core_gb |
42 | Gen5 | 4.86 | 29.4 | 7 | 42 | 5.05 |
- The current DTU database has 42 logical CPUs (vCores) and 4/86 GB memory per vCore on the Gen5 hardware
-
Approximate match
- General-purpose service tier
- Gen4 hardware, 29.4 vCores and 7 GB memory per vCore
- Gen5 hardware, 42 vCores and 5.05 GB memory per vCore
Conclusion
This article explored the DTU and vCore based purchasing model for Azure SQL Database and Azure SQL Managed Instances. The Azure managed instance supports only the vCores model. You should use the vCore model as it offers flexibility in choosing the resources individually, and you can scale them as required.
If you have an existing DTU based Azure database, you can plan to migrate to vCore based on the approximate recommendation returned using the T-SQL. However, always perform workload tests on the lower environment (non-prod) before making changes in production.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023