
SQL Server databases consist of two physical files types; the data file in which the data and the database objects such as tables and indexes are stored, and the transaction log file in which SQL Server stores records for all transactions performed on that database.
SQL Server transaction log contains metadata about the recorded transaction, such as the transaction ID, the transaction start and end time, the changed pages and the data changes.
The SQL Server transaction log is an important database component that is used to make sure that the committed transaction’s data is preserved and the uncommitted transaction’s change will be rolled back. The transaction log is very useful when a hardware or application failures occur, by restoring the database to a previous point in time, as the log will be written to the log file before writing the data in the buffer cache to the data file.
During the database recovery process, any transaction that is committed, without reflecting the data changes to the data files due to failure will be redone again, as the record already written to the database transaction log file before writing it to the data file. On the other hand, any data changes associated with uncommitted transaction will be rolled back by reversing the operation written in the transaction log file. In this way SQL Server guarantees the database consistency.
Data is written to the database data files randomly, but the logs are written to the transaction log file sequentially one by one, making the log write process faster. No performance gain can be taken from having multiple transaction log files in the database, as the logs will be written one at a time. It will be useful if the transaction log file become full and you need to create another file in a different disk that has more space.
It is recommended also to keep the transaction log file in a separate drive from the database data files, as placing both data and log files on the same drive can result poor database performance.
The transaction log file internally consists of small units called Virtual Log Files (VLF).
And the process in which SQL Server marks these VLFs as inactive, making it available for reuse by the database is called Truncation. In order to mark these VLFs as inactive, it shouldn’t contain any active log related to an opened transaction, as these logs may be used for redone or redo process. Log truncation doesn’t mean that the transaction log size will be reduced, only it will be marked as inactive to be used in future.
Once the transaction log record inserted into the log file, it will be marked with a specific value called Logical Sequence Number (LSN). The log with the lowest LSN specifies the start of the active log that may be needed for any database activity, and the log with the highest LSN specifies the end of that active log. Any transaction log with LSN value less than the minimum LSN will be considered as inactive transaction log.
The transaction log records that are needed by SQL Server Replication, Mirroring, Change Data Capture or Log Backup processes will remain as active until released by these activities.
The SQL Server database recovery model property determines how the transactions are logged. The default recovery model for the newly created databases is the same recovery model as the model system database. If the database recovery model is SIMPLE, the data pages will be written to data files, and all VLFs with no active log will be truncated. If the recovery model of the database is FULL or BULK LOGGED, the VLFs will be truncated only if log is backed up, unless there are other activities that still need this logs as mentioned previously.
If the transaction log file grows and extended in small chunks, this will result huge number of VLFs, but if the allocation is performed in large chunks, this will result small number of VLFs. A huge number of VLFs will impact the database performance especially during the database backup, restore and recovery operations. So it is recommended to set the appropriate initial size, maximum size and autogrowth increment values for the transaction log, as every growth of that file is expensive.
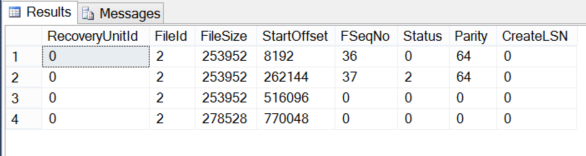
You can easily check the number of VLFs in your database by running the below simple DBCC query:
|
1 2 3 4 5 |
USE SQLShackDemo GO DBCC LOGINFO |
The query result below shows that we have only 4 VLFs in the SQLShackDemo database log file:
Before allocating space to the transaction log file, the space will be filled with zeroes by the operating system. This prevents any corruption on the database that is caused by processing the data written previously on that disk, having the same parity bit as the transaction logs. Using the Instance File Initialization feature, space can be allocated to the database data files only without zeroing the space.
It is better to monitor the transaction log file growth, as the transaction log could be expanded till it takes all the free space in the disk, generating error number 9002, telling us that the transaction log is full, and the database will become read-only.
The first step in managing the transaction log file is to verify the transaction log files information, which can be retrieved from the sys.database_files system catalog view as follows:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE SQLShackDemo GO SELECT name AS FileName, size FileSizeInKB, max_size FileSizeLimitInKB, growth SizeIncrementAmount, is_percent_growth FROM sys.database_files WHERE type_desc = 'LOG' |
From the query result you can check the transaction log file current size, the maximum limit for the file, the increment amount or percentage and if the growth is in percent or in megabytes:

Now we will go through the transaction log file space consumptions that prevent the log from being reused and lead to the transaction log full error.
The first transaction log space consumer is the Index Maintenance operations; the Index Rebuild and Index Reorganize. Rebuilding the indexes in a database with FULL recovery model is heavily logged, but in the SIMPLE and BULK LOGGED recovery models, the index rebuild operation is minimally logged, where only the allocations are logged. On the other hand,
Index reorganize operation is fully logged regardless of the database recovery model.
If your database is included in one of the SQL Server availability or disaster recovery solutions, and you are not able to change the database recovery model to SIMPLE before rebuilding the index and change it back to FULL after you finish, then you need to increase the log backup frequency during the index rebuilding operation in order to truncate inactive logs as possible.
If the transaction log consumer is not clear on the surface, the first step you can perform is to check what is preventing the transaction log from being reused by querying the sys.databases system table as below:
|
1 2 3 4 5 |
SELECT name AS Database_Name ,log_reuse_wait_desc FROM sys.databases |
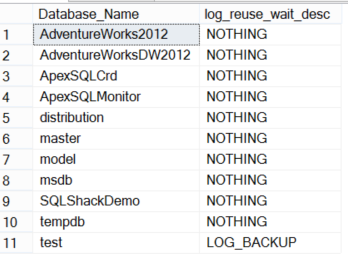
We are interested here in the log_reuse_wait_desc column value, which shows us what is preventing the transaction log from being reused.
The healthy value for the log_reuse_wait_desc column is NOTHING, which indicates that the transaction log is reusable.
If the log_reuse_wait_desc column value is Log Backup, this means that your database recovery model is FULL and transaction log is pending log backup operation to be truncated.
The database full backup will not truncate the transaction log. The transaction log truncation can be achieved only by taking log backup. Without the log backup, the transaction log file will keep growing without allowing the space to be reused.
The first thing you need to think about here, is that , do you really need the database recovery model to be FULL, depending on the disaster recovery solution you may use and the company business requirements. If it is not required, then it is better to switch the database recovery model to simple, where no log backup is required here as the inactive transaction logs will be automatically marked as reusable at the checkpoint.
If you find that the database should operate in FULL recovery model, then you need to schedule a transaction log backup job with frequency depends on the data changes frequency and the data loss acceptance if a crash occur.
When the returned value for the log_reuse_wait_desc column is ACTIVE_TRANSACTION, then there is an uncommitted transaction that is running for a long time and consuming the database log file space.
This transaction will delay the truncation of any transaction log that is generated when it starts, even the transaction logs of the committed changes.
In SQL Server, any single data modification statement will act as an implicit transaction, in order to ensure the data consistency.
A common example of transactions that take long time and fill the transaction log file are purging and archiving operations. The more records you are trying to delete from your table, the more logs will be written to the transaction log, the longer time this transaction will take.
The complexity of the delete transaction will be increased if the table from where you are deleting data has FOREIGN KEY constraints with CASCADE ON DELETE. Here the transaction log records will be written for the data deleted by the cascade delete operation. The same thing will happen if there is an ON DELETE trigger in the table you are deleting data from, where transaction log records will be written for the operation performed by that trigger.
Rather than purging the data using a single DELETE statement, you can minimize the logging for such operation by deleting the data in batches, using the TOP operator with the DELETE statement. In this way the large transaction will be divided into multiple smaller transactions.
Any created transaction will remain active in the database till it is committed, rolled back or the session lost the connection with the SQL Server. If the transaction has not terminated properly, it will not close its connection to the database, as the transaction still active from the database side, preventing the transaction log truncation. As a result, the transaction log will keep growing, and filling up the disk. This type of transactions that left uncommitted from the database side and disconnected from the application side is called Orphaned Transactions.
The below T-SQL script can be used to list all active transactions in your database. You can use this script to monitor the active transactions, and find the long-running ones with the oldest database_Transaction_Begin_Time value:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT transaction_id , database_ID , database_Transaction_Begin_Time, database_transaction_log_record_count, database_transaction_begin_lsn , database_transaction_last_lsn, CASE database_transaction_state WHEN 1 THEN 'The transaction has not been initialized.' WHEN 3 THEN 'The transaction has been initialized but has not generated any log recorst.' WHEN 4 THEN 'The transaction has generated log records.' WHEN 5 THEN 'The transaction has been prepared.' WHEN 10 THEN 'The transaction has been committed.' WHEN 11 THEN 'The transaction has been rolled back.' WHEN 12 THEN 'The transaction is being committed. In this state the log record is being generated, but it has not been materialized or persisted' END database_transaction_state FROM sys.dm_tran_database_transactions |
The result will be like:

Another useful indicator from the previous query is the database_transaction_log_record_count column that can show you which transaction is filling the database transaction log file.
In order to get the session running the transaction that is consuming your transaction log file, you can query the sys.dm_tran_session_transactions for the TransactionID derived from the previous query as follows:
|
1 2 3 4 5 6 7 |
DECLARE @TransID as bigint SET @TransID= ---The Transaction ID resulted from the old query SELECT session_id FROM sys.dm_tran_session_transactions WHERE transaction_id = @TransID |
To stop the orphaned transaction that is consuming space in your transaction log, you need to KILL the session derived from the previous script. The transaction will be rolled back and the space will be available during the next transaction log backup.
If the returned value for the log_reuse_wait_desc column is REPLICATION, then the transaction logs are pending replication for long time and can’t be truncated due to slow log reader agent activities. This is a problem you may face if you configure SQL Server Replication or Change Data Capture (CDC) features in your database.
To troubleshoot this type of issues you need first to make sure that the SQL Server Agent service is running, then check that the Log Reader Agent jobs are running. If the jobs are running and the issue still active, you need to check the replication monitor and the Log Reader Agent jobs history to check what the cause of that delay is. You may need to re-initialize the subscribers and create a new snapshot if the subscriber was inactive for the configurable max_distretention period.
If the cause of this issue is CDC, then you need to check that the CDC capture job is running and tracking changes. If the CDC capture job is running and the issue still then you need to check what is exactly delaying the log reading which could be a change on a huge amount of data on a table with CDC enabled on it. Disable the CDC and enable it again before doing such huge changes.
Once the replication or the CDC issue resolved, the transaction log will be truncated and available for reuse in the next log backup.
When the returned value for the log_reuse_wait_desc column is DATABASE_MIRRORING, then the database Mirroring is the main cause for the transaction log truncation and reuse issue.
There are two modes of SQL Server Mirroring; Synchronous Mirroring on which the transaction will be committed on the principal server only once that transaction log records have been copied to the mirrored server. And Asynchronous Mirroring on which the transaction will be committed directly without waiting for transaction log records to be copied to the mirrored server.
To troubleshoot the mirroring wait, you need to check the mirroring state on the principal server first, the mirroring could be suspended due to a sudden disconnection and you need to resume it back. If the state of the mirroring is disconnected, you need to check the connection between the principal and the mirrored servers that could be broken. When using synchronous mirroring, slow connections between the principal and mirrored servers could grow the transaction log file and consume disk space, as the logs will remain active till copying it to the mirrored server.
Resolving the mirroring delay or disconnection problem, the transaction log will be truncated and available for reuse in the next log backup. As these records already copied to the mirrored server and not part of the active log now.
The last log_reuse_wait_desc returned value we will check in this article is the ACTIVE_BACKUP_OR_RESTORE. This type indicates that a Full or Differential backup operation, running for a long time, is the cause of the transaction log reuse issue.
During Full and Differential backup operations, the SQL Server will delay the transaction log truncation process in order to include the active part of the transaction logs in the backup in order to ensure the database consistent during the restoration process. You need to go deeply to investigate what makes the backup slow such as checking the disk IO system, so that, the backup will not take long time and consume the transaction log in future.
Conclusion
The SQL Server transaction log file is as an important component of the SQL Server database as the data file itself. SQL Server stores records for all database modifications and transactions to be used in the case of disaster or corruption and ensure the data consistency and integrity.
As a DBA, you should maintain the transaction log and keep t healthy by monitoring it and managing its growth. You can use any monitoring tool such as Microsoft SCOM to create an alert to notify you when the transaction log file free space reaches a specific threshold. Once you detect a transaction log issue you have to take it seriously and do an immediate action to resolve it, in order to prevent the growth side effects in the future.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021