
En los artículos previos de estas series (véase el artículo entero TOC al fondo), hemos discutido la estructura interna de las tablas e índices SQL Server, las líneas guía que puedes seguir para poder diseñar un índice apropiado, la lista de operaciones que pueden ser realizadas en los índices SQL Server, cómo diseñar índices Agrupados y No agrupados efectivos, los diferentes tipos de índices SQL Server (arriba y más allá de la clasificación de Índices Agrupados y No Agrupados), cómo ajustar el rendimiento de las consultas ineficientes usando diferentes tipos de Índices SQL Server y finalmente, cómo obtener información estadística sobre la estructura de índice y el uso del índice. En este artículo, el último artículo en estas series, vamos a discutir cómo beneficiarse de la información obtenida previamente en el mantenimiento de índices SQL Server.
Unas de las tareas más importantes de administración que todo administrador de base de datos debería importarle es el mantenimiento de la base de datos de índices. Como hemos mencionado previamente, no puedes crear un índice para mejorar el rendimiento de tus consultas y dejarlo por siempre sin monitoreo continuo de sus estadísticas de uso. El índice que es adecuado para ti, puede degradar el rendimiento de nuestra consulta en el futuro, debido a diferentes cambios realizados en la información de tu base de datos o esquema. Hemos discutido, en los artículos previos sobre obtener diferentes tipos de información y estadísticas sobre índices. Ahora vamos a usar esta información obtenida para realizar tareas de mantenimiento adecuado en ese índice.
Perder y duplicar índices
La primera cosa a ver, en el contexto de mantenimiento de índice, es identificar y crear índices perdidos. Estos son índices que han sido recomendados y sugeridos por el Motor SQL Server para mejorar el rendimiento de nuestras consultas.
Consulta el artículo Seguimiento y optimización de consultas utilizando índices SQL Server para explorar profundamente en el método de identificación de índices perdidos.
Otra área para concentrarse es la duplicación de índices. Es peor tomar tiempo revisando las columnas que están participando en cada índice en tu base de datos, que es retornada al consultar los sistemas de objetos sys.index_columns y sys.indexes descritos en el artículo previo, e identificar los índices duplicados que son creados en las mismas exactas columnas cuando se remueve las mismas. Recuerda el costo de los índices en la modificación de información y las operaciones de mantenimiento y que puede llegar a la degradación del rendimiento.
Tablas de montón
Las tablas de montón son tablas que contienen índices no Agrupados. Esto significa que las filas de información en la tabla de montón, no están almacenadas en ningún orden particular en cada página de información. Además no hay un orden particular para controlar la secuencia de páginas de información, que no está unida en una lista conectada. Como resultado, recuperar información de insertar o modificar en la tabla montón será muy lento y puede ser fragmentado más fácilmente.
Para más información sobre tablas de montón revisar Resumen de estructura de tablas SQL Server
Necesitas primero identificar las tablas montón en tu base de datos y concentrarte solo en las tablas grandes, ya que el Optimizador de Consultas de SQL Server no se beneficiará de los índices creados en tablas más pequeñas. Tablas de montón pueden ser detectadas al consultar objetos sys.indexes system, en conjunción con otros sistemas de vistas de catálogo, para recuperar información significante, como se muestra en el script T-SQL de abajo:
|
1 2 3 4 5 6 7 8 |
SELECT OBJECT_NAME(IDX.object_id) Table_Name , IDX.name Index_name , PAR.rows NumOfRows , IDX.type_desc TypeOfIndex FROM sys.partitions PAR INNER JOIN sys.indexes IDX ON PAR.object_id = IDX.object_id AND PAR.index_id = IDX.index_id AND IDX.type = 0 INNER JOIN sys.tables TBL ON TBL.object_id = IDX.object_id and TBL.type ='U' |
De los resultados de consulta anterior, identifica las tablas de montón grandes y crea un índice Agrupado en estas tablas para mejorar el rendimiento de la lectura de las consultas de estas tablas. El resultado en nuestro caso será como el mostrado abajo:

Índices no usados
En el artículo previo, mencionamos dos modos de obtener el uso de la información sobre índices de base de datos, el primero usando el sys.dm_db_index_usage_stats DMV y el segundo modo usando el reporte standard Index Usage Statistics. Índices no usados que no son usados en ninguna operación de búsqueda o escaneo, o que son relativamente pequeños, o que son actualizados muchas veces deberían ser removidos de tu tabla, ya que va a degradar la modificación de información y el rendimiento de operaciones de mantenimiento de índice, en vez de mejorar el rendimiento de tus consultas.
El mejor modo de lidiar con índices no usados es quitarlos. Pero antes de hacer eso, asegúrate de que…
- El índice no es un índice nuevamente creado
- Que el sistema será usado en el futuro próximo
- Y que el SQL Server no haya sido reiniciado recientemente
La razón para esto es que los resultados de estos dos métodos serán actualizados cada vez que el SQL Server reinicie y puede proveer información incompleta para iniciar la eliminación del índice. En caso de un uso ineficiente de un índice Agrupado, asegúrate de remplazarlo con otro y mantener la tabla como montón.
Arreglar fragmentación de índice
En el SQL Server, la mayor parte de las tablas son tablas transaccionales, que no son estáticas pero son cambiantes en el tiempo. La fragmentación de índices ocurre cuando el orden lógico de las páginas del índice, basadas en el valor clave, no corresponde al orden físico dentro de la información del archivo. Hemos discutido previamente que, debido a la inserción frecuente de la información y modificación de operaciones, las páginas de índice serán divididas y fragmentadas, cuando la página este llena, o que no entre el valor nuevo o actualizado en el espacio libre actual, aumentando la cantidad de operaciones del disco I/O para leer la información requerida.
Por otro lado, configurando las opciones de creación de Fill Factor y pad_index con los valores apropiados ayudará a reducir la fragmentación de índice y problemas de división de página. Otras formas diferentes de obtener información de fragmentación sobre la base de datos de índices se puede realizar de diferentes formas, como consultar la función dinámica de administración sys.dm_db_index_physical_stats y el reporte standard Index Physical Statistics , que son mencionados en detalle en el artículo previo.
La desfragmentación de índice asegura que las páginas de índice sean contiguas, proveyendo formas más rápidas y eficientes para acceder a la información, en vez de leer de páginas esparcidas a través de páginas múltiples separadas.
El SQL Server nos provee de diferentes formas de arreglar el problema de fragmentación de índice. El primer método es usar el comando DBCC INDEXDEFRAG, que desfragmenta el nivel hoja de un índice, seriamente un índice a la vez usando un único hilo, de una forma que permite el orden físico a las páginas para corresponder al orden lógico izquierdo-a –derecha en los nodos hoja, mejorando el rendimiento de escaneo del índice. El comando DBCC INDEXDEFRAG es una operación online que guarda bucles de corto término en el objeto de la base de datos subyacente sin afectar ninguna consulta o actualización corriendo. El tiempo requerido para desfragmentar un índice depende principalmente del nivel de fragmentación donde un índice con pequeño porcentaje de fragmentación puede ser desfragmentado más rápido que un índice nuevo pueda ser construido. Por otro lado, un índice que es muy fragmentado, pueda tomar considerablemente más tiempo en desfragmentar que reconstruir. Si el comando INDEXDEFRAG es detenido en cualquier momento, todo el trabajo completado será retenido.
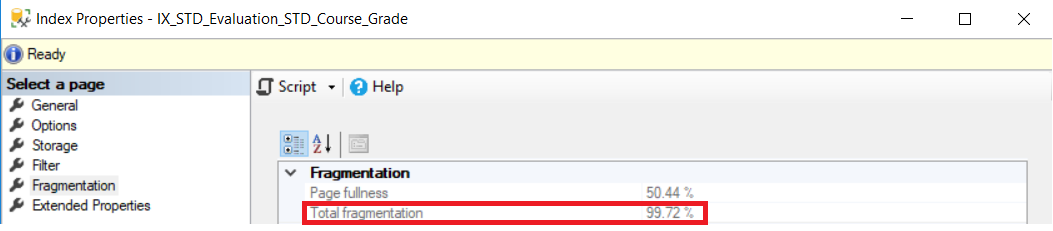
Asume que tenemos el índice de abajo con un porcentaje de fragmentación igual a 99.72 %, como se muestra en la captura de pantalla de abajo, tomando de las propiedades del índice:
El comando DBCC INDEXDEFRAG puede ser usado para desfragmentar todos los índices en una base de datos específica, todos los índices en una tabla específica o índice específico solo dependen de los parámetros provistos. El script de abajo es usado para desfragmentar el índice previo que tiene un porcentaje alto de fragmentación:
|
1 2 |
DBCC INDEXDEFRAG (IndexDemoDB, 'STD_Evaluation', IX_STD_Evaluation_STD_Course_Grade); GO |
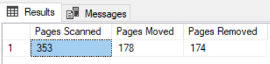
El resultado retornado del comando, muestra el número de páginas que son escaneadas, movidas y removidas durante el proceso de desfragmentación, como se muestra abajo:
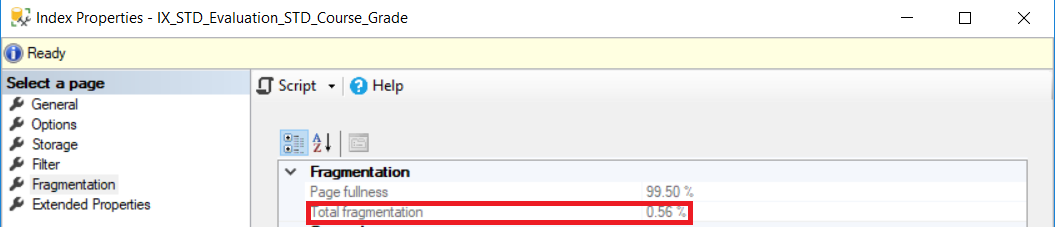
Verificando el porcentaje de desfragmentación después de correr el comando DBCC INDEXDEFRAG, el porcentaje de fragmentación se vuelve menos que el 1% mostrado abajo:
La fragmentación de índice puede ser también resuelto al reconstruir y reorganizar los índices SQL Server regularmente. Las operaciones de Reconstrucción de índice remueve fragmentación al abandonar el índice y creándolo de nuevo, desfragmentando todos los niveles de índice, compactando las páginas de índice usando los valores de Fill Factor especificados en el comando reconstruir, o usando el valor existente si no es especificado y actualizando las estadísticas usando FULLSCAN de toda la información. Recuerda que reconstruir un índice desactivado lo vuelve de nuevo a vida. La operación de reconstrucción de índice puede ser realizada online, sin cerrar otras consultas cuando se usa el SQL Server Enterprise edition, u offline al guardar bucles en los objetos de base de datos durante la operación de reconstrucción. Además, la operación de índice reconstruido puede usar paralelismos cuando se usa Enterprise edition. Por el otro lado, si la operación de reconstrucción falló, una operación fuerte de reducción será realizada. El índice puede ser reconstruido usando el comando T-SQL ALTER INDEX REBUILD.
La operación de Index Reorganize reordena físicamente las páginas de nivel hoja del índice para corresponder con el orden lógico de los nodos hoja. La operación de reorganización de índice será siempre realizado online. Microsoft recomienda arreglar problemas de fragmentación de índice al reconstruir el índice si el porcentaje de fragmentación excede el 30 %, donde recomienda arreglar el problema de fragmentación de índice al reorganizar el índice si el porcentaje de fragmentación de índice excede 5 % y menos de 30 %. La operación de reorganización de índice usará un solo hilo, independientemente del SQL Server Edition usado. Por otro lado, si la operación de reorganización falla, va y para donde se quedó, sin retroceder la operación de reorganización. El índice puede ser reorganizado usando el comando ALTER INDEX REORGANIZE.
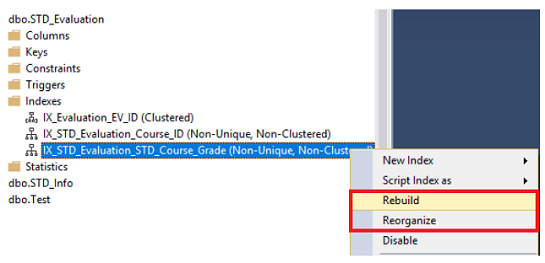
El índice puede ser reconstruido o reorganizado usando el SQL Server Management Studio al abrir los nodos de Índices bajo tu tabla, escoge el índice que pretendes desfragmentar, haz clic derecho en ese índice y escoge la opción Rebuild o Reorganize, basado en el porcentaje de fragmentación de ese índice, como se muestra abajo:
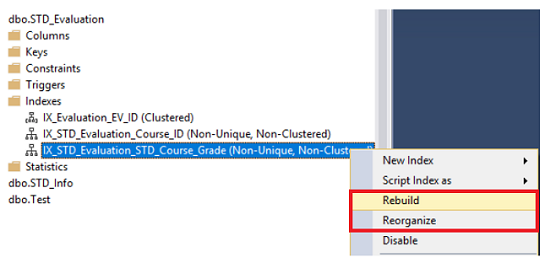
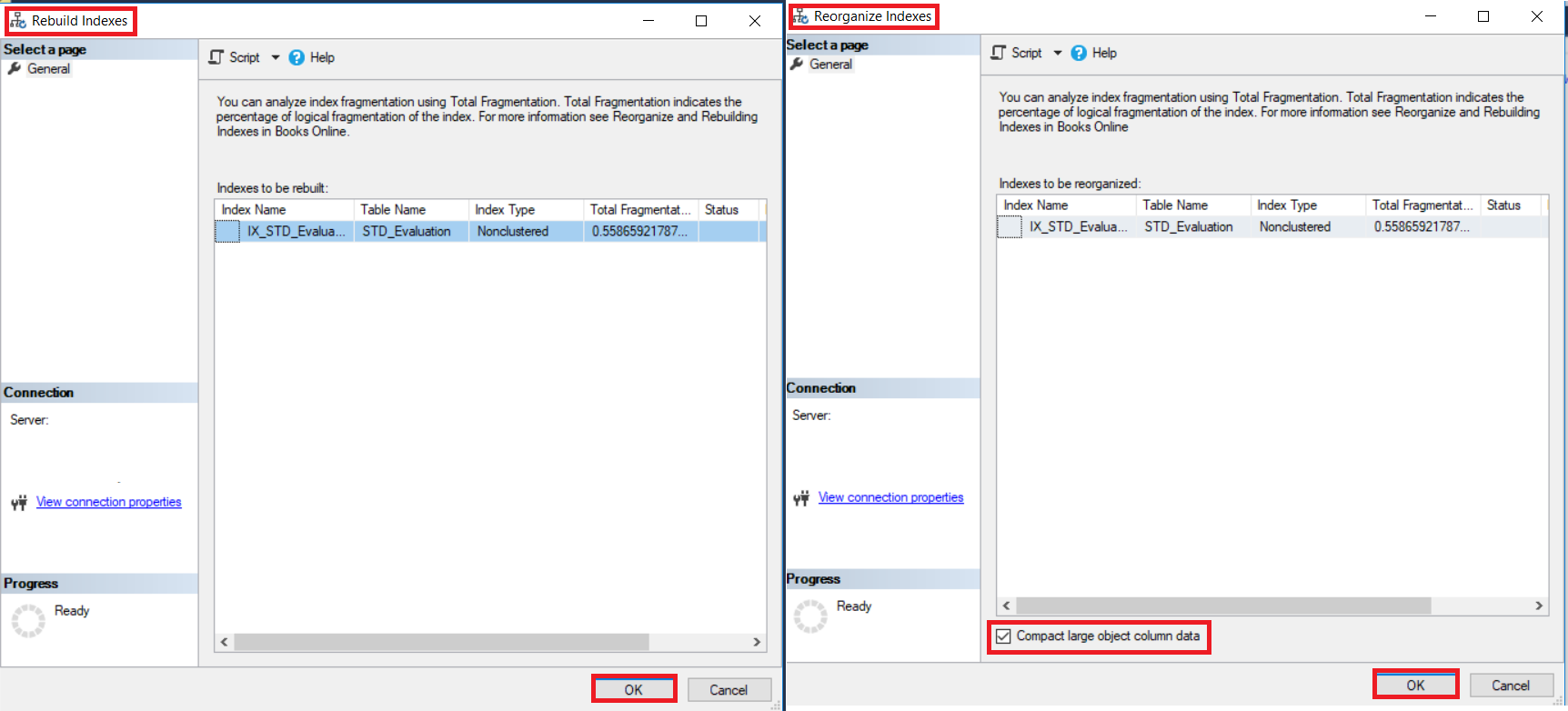
El SQL Server te permite reconstruir o reorganizar todas las tablas de índices, al hacer clic derecho en el nodo de índices bajo tu tabla y escoger la opción Rebuild All o Reorganize All, como se muestra abajo:
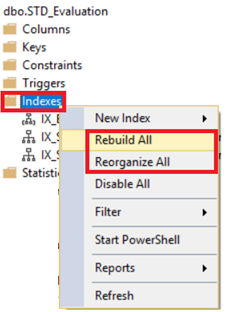
La ventana mostrada de reconstruir o reorganizar va a listar todas las tablas de índices que van a ser desfragmentados usando esa operación, con el nivel de fragmentación de cada índice, como se muestra en la captura de pantalla de abajo:
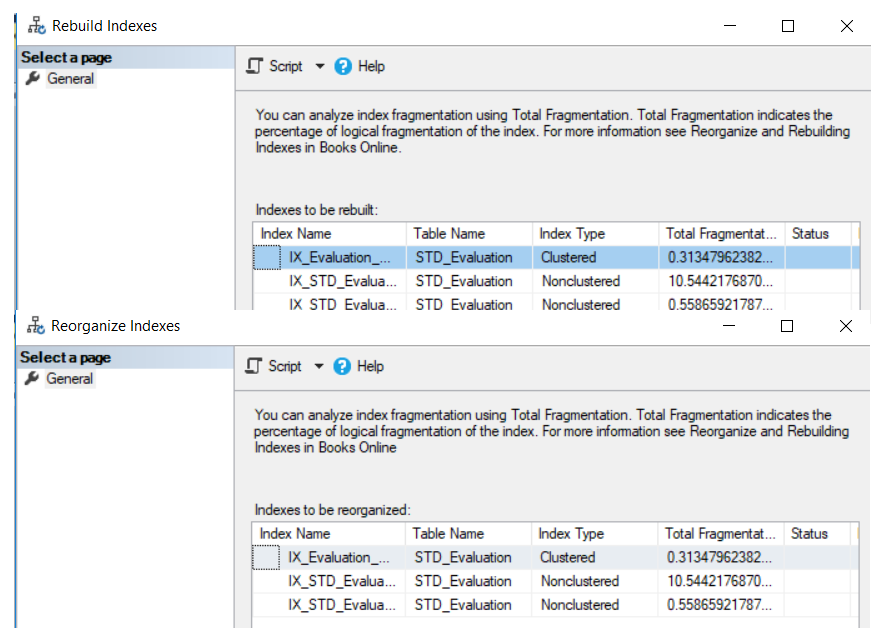
La misma operación puede también ser realizada usando comandos T-SQL. Puedes reconstruir el índice previo, usando el comando ALTER INDEX REBUILD T-SQL, con la habilidad de configurar las diferentes opciones de creación de índice, como el FILL FACTOR, ONLINE o PAD_INDEX, como se muestra abajo:
|
1 2 3 4 |
USE [IndexDemoDB] GO ALTER INDEX [IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation] REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
También, el índice puede ser reorganizado, usando el comando ALTER INDEX REORGANIZE T- de abajo:
|
1 2 3 4 |
USE [IndexDemoDB] GO ALTER INDEX [IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation] REORGANIZE WITH ( LOB_COMPACTION = ON ) GO |
Puedes también organizar todas las tablas de índices, al proveer la declaración ALTER INDEX REORGANIZE T-SQL con la opción ALL, en vez de el nombre de índice, como la declaración T-SQL de abajo:
|
1 2 3 |
ALTER INDEX ALL ON [dbo].[STD_Evaluation] REORGANIZE ; GO |
Y reconstruir todos los índices de la tabla, al proveer la declaración ALTER INDEX REBUILD T-SQL con la opción ALL, en vez del nombre del índice, como la declaración T-SQL de abajo:
|
1 2 3 |
ALTER INDEX ALL ON [dbo].[STD_Evaluation] REBUILD WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
En SQL Server 2014, la nueva funcionalidad fue introducida que nos permite controlar cómo es manejado el mecanismo de bloqueo, que es requerido por la operación de reconstrucción de índice online. Este mecanismo es llamado Managed Lock Priority, que se beneficia de la nueva y definida fila de Baja Prioridad que contiene los procesos con prioridades más bajas que aquellas esperando en la fila de espera, dando al administrador de base datos la habilidad de manejar las prioridades de espera.
Para más información, ver Cómo controlar el bloqueo de Indices Reconsstruidos online usando SQL Server 2014 Prioridad de Bloqueo administrado..
Mantenimiento las estadísticas de índice
Las estadísticas de Índice son usadas por el Optimizador de consultas de SQL Server para determinar si el índice será usado en la ejecución de la consulta. Estadísticas obsoletas llevara al Optimizador de Consultas a seleccionar el índice equivocado mientras se ejecuta la consulta. Desde el aspecto operativo de sistema SQL Server, cuando se selecciona un índice, el Optimizador de Consultas de SQL Server va a ignorar el índice si tiene un alto porcentaje de fragmentación (como buscar en el costará más que el escaneo de tabla), los valores de índice no son únicos, las estadísticas de índice están obsoletas o el orden de las columnas en la consulta no corresponde al orden de las columnas de índice clave.
Las estadísticas de índice puedes ser actualizadas automáticamente por el Motor SQL Server o manualmente usando el procedimiento sp_updatestats stored, que corre UPDATE STATISTICS contra todas las tablas user-defined y tablas internas en la actual base de datos, o usando el comando UPDATE STATISTICS T-SQL, que puede ser usado para actualizar las estadísticas de todas las tablas de índices o actualizar las estadísticas de un índice específico en la tabla. La declaración T-SQL de abajo es usada para actualizar las estadísticas de todos los índices bajo la tabla STD_Evaluation:
|
1 2 |
UPDATE STATISTICS STD_Evaluation; GO |
Donde la declaración T-SQL de abajo va a actualizar las estadísticas de solo un índice, bajo esa tabla:
|
1 2 |
UPDATE STATISTICS STD_Evaluation IX_STD_Evaluation_STD_Course_Grade; GO |
Puedes también actualizar las estadísticas de toda la tabla de índices, al especificar el porcentaje de las filas ejemplares, como se muestra en la declaración T-SQL de abajo:
|
1 2 |
UPDATE STATISTICS STD_Evaluation WITH SAMPLE 50 PERCENT; |
O forzarlo a escanear todas las filas de la tabla durante la actualización de estadísticas de la tabla, usando la opción FULLSCAN, mostrado abajo:
|
1 2 3 |
UPDATE STATISTICS STD_Evaluation WITH FULLSCAN, NORECOMPUTE; GO |
Automatizar mantenimiento de índice SQL server
Hasta este punto, nos hemos familiarizado en cómo tomar la decisión si vamos a reconstruir o reorganizar un índice SQL Server, basados en el porcentaje de la fragmentación, y cómo desfragmentar un índice específico o todas las tablas de índice usando los métodos rebuild o reorganize. También revisamos la importancia de rendimiento de diferentes tipos de tareas de mantenimiento de índices regularmente, para poder permitir que el Optimizador de Consultas de SQL Server considere estos índices para mejorar el rendimiento de las diferentes consultas y minimizar los costos de estos índices en el sistema general de base de datos.
Por otro lado, realizar las tareas de mantenimiento de índices manualmente no es una buena práctica, ya que estos operadores puedan tomar un largo tiempo que el DBA no tendrá paciencia para esperar, además que el DBA no está siempre disponible para recordar correr estas tareas, lo cual puede llevar a acumular altos porcentajes de fragmentación.
Hay dos opciones para automatizar el mantenimiento de índices. La primera opción es planificar un script personalizado de mantenimiento de índice, para reconstruir, reorganizar, desfragmentar y actualizar las estadísticas basado en el porcentaje de fragmentación usando el trabajo SQL Server Agent, que puede ser tu propio script basado en el comportamiento de tu sistema y requerimientos, o personalizar mi script flexible favorito Ola Hallengren’s index maintenance que te provee de un gran número de opciones que pueden entrar en un gran rango de sistemas de comportamientos.
La segunda opción para automatizar las tareas de mantenimiento de índice es usando los Rebuild Index, Reorganize Index and Update Statistics Maintenance Plans, de los nodos de Management como se muestra abajo:
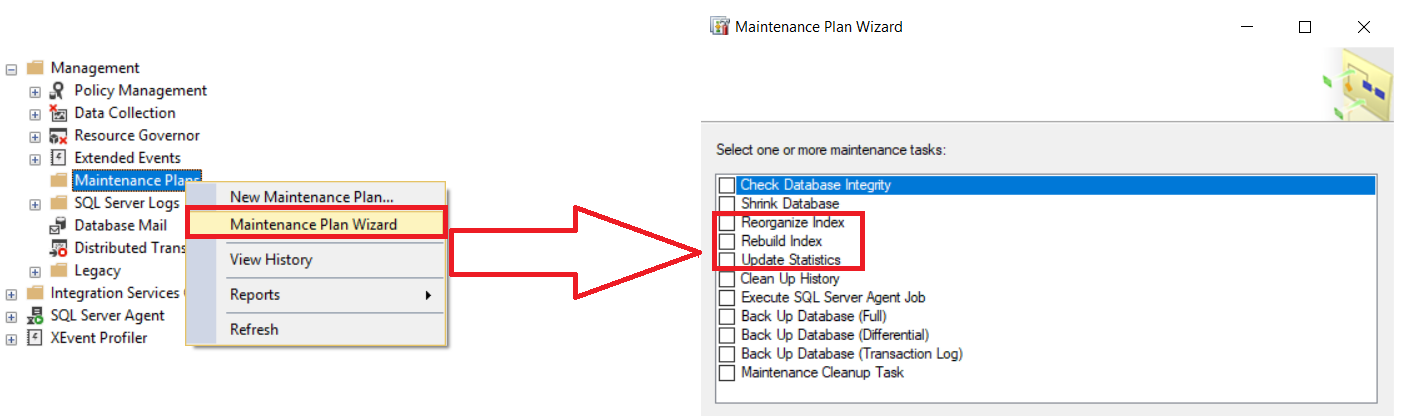
Necesitas especificar el nombre de la base de datos o bases de datos que pretendes realizar una tarea de mantenimiento de índices, con la habilidad de reducir para realizar sobre una tabla específica y programar ese mantenimiento para ser realizado durante las horas no pico, basados en la carga de trabajo que especifica las ventanas de mantenimiento disponibles en tu compañía, tu estructura de base de datos, cuán rápido la información es fragmentada y la edición de SQL Server. Recuerda que el tiempo requerido para realiza las tareas de mantenimiento puede ser disminuida al usar el Enterprise Edition, que te permite realizar la operación de reconstrucción de índice online y usar planes paralelos.
Usando los SQL Server Maintenance Plans para automatizar las áreas de mantenimiento de índices no es una opción preferida cuando se usa versiones SQL Server anterior a 2016, debido a la falta de control en estas pesadas operaciones. Esto es debido a que estas tareas de mantenimiento serán realizadas en todas las tablas o índices de base de datos independientemente del porcentaje de fragmentación de estos índices. Esas operaciones van a requerir una ventana de largo manteamiento y va a consumir intensivamente los recursos del servidor cuando se mantiene grandes bases de datos.
Empezando del SQL Server 2016, nuevas opciones fueron añadidas a las tareas de mantenimiento de índices que nos permiten realizar las tareas de Reconstruir Índices y Reorganizar Índices, basados en el porcentaje de fragmentación del índice, y otras opciones útiles para controlar el proceso de mantenimiento del índice.
Para más información sobre este mejoramiento, consulta el SQL Server 2016 Maintenance Plan Enhancements.
Las siguientes capturas de pantalla resumen como podemos especificar los parámetros de porcentaje de fragmentación para ambos planes de mantenimiento de reconstrucción del índice y reorganización, y otras opciones de control como se muestra abajo:
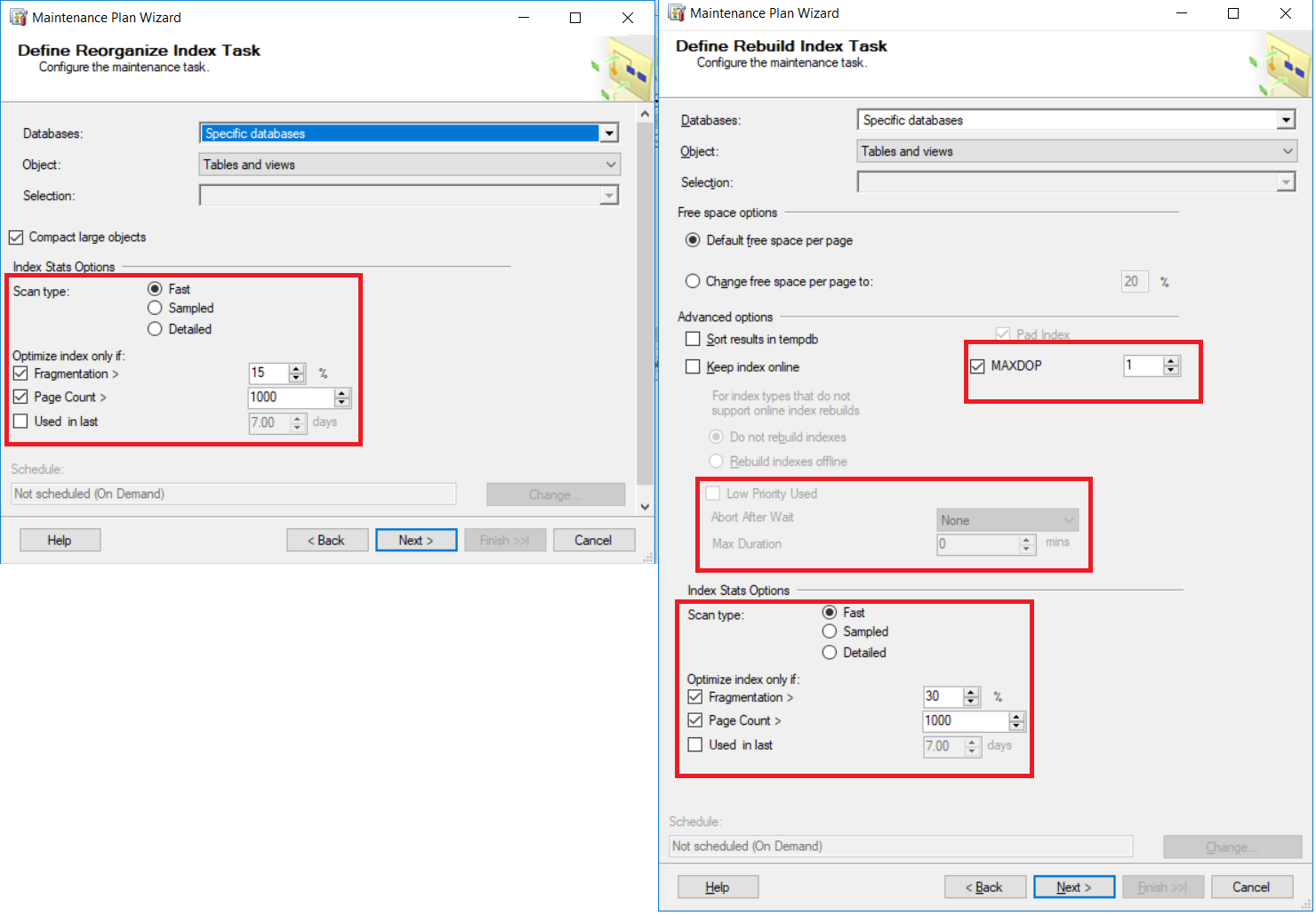
Requerimientos de mantenimiento de Índices
Cuando reconstruyes un índice, un espacio adicional temporal del disco es requerido durante la operación para almacenar una copia del índice viejo, deshaciendo los cambios realizados en caso de fallo, y para aislar la operación de reconstrucción del índice online de los efectos de modificaciones hechas por otras transacciones usando filas versionando y clasificando los valores de índice clave. Si la opción SORT_IN_TEMPDB es habilitada, espacio tempdb, donde entra el tamaño de índice, debería estar disponible para clasificar los valores de índice. Esta opción hace más rápido el proceso de reconstrucción al separar las transacciones del índice de las transacciones concurrentes del usuario, si la base de datos tempdb está en una unidad de disco separada. Por otro lado, es requerido espacio adicional permanente de disco para almacenar la nueva estructura del índice.
Para realizar operaciones de larga escala, como operaciones index Rebuild y Reorganize, que pueden llenar el registro de transacción rápidamente, el archivo de base de datos de registro de transacciones debería tener suficiente espacio libre para almacenar las operaciones de transacciones de índices, que no serán truncadas hasta que la operación es completamente exitosa, y cualquier transacción de usuario concurrente realizado durante la operación de índice.
La gran cantidad de registros de transacciones escritas en los archivos de registros de base de datos de transacción durante las operaciones de desfragmentación del índice requiere un tiempo más largo para copiar el archivo de registro de transacción. Este efecto puede ser minimizado al realizar registros copia de transacción más frecuentemente durante las operaciones de mantenimiento o cambiando el modelo de recuperación de base de datos a SIMPLE o BULK o LOGGED para minimizar el registro durante esa operación, si es aplicable. Además, el costo de red extra será causado al mandar una gran cantidad de registros de transacción a los servidores de Grupos de Disponibilidad secundarios. Si un problema de red notable es causado durante las operaciones de mantenimiento, puedes superar ese problema al pausar el proceso de sincronización de información durante las operaciones de mantenimiento de índice, si es aplicable.
Conclusión
En estas series de artículos, hemos tratado de cubrir todos los conceptos que están relacionados el Índice de SQL Server, empezando por las estructuras básicas de las tablas e índices de SQL Server, explorando por diseño de índices y optimización de consultas usando estos índices, y finalizando con obtención de información estadística sobre los índices y usar esta información para mantener los índices. Espero que hayan disfrutado estas series y hayan mejorado su conocimiento.
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.


He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019