
Microsoft SQL Server es un sistema de administración relacional de base de datos (RDBMS) que, en su nivel fundamental, almacena la información en tablas. Las tablas son los objetos de base de datos que se comportan como contenedores de información, en los cuales la información será lógicamente organizada en formato de filas y columnas. Cada fila es considerada como una entidad que es descrita por las columnas que contienen los atributos de la entidad. Por ejemplo la tabla de usuarios contiene una fila para cada usuario, y cada usuario es descrito por las columnas de la tabla que contiene la información del usuario, como el CustomerName y CustomerAddress. Las filas de la tabla no tienen orden predefinido, de modo que para mostrar la información en un orden especifico, podrías necesitar de especificar el orden en el que las filas van a ser devueltas. Las tablas pueden también ser usadas como límite/mecanismos de seguridad, donde los usuarios de la base de datos pueden obtener permisos del nivel de la tabla.
Lo Básico de la tabla
Las tablas de Microsoft SQL Server están contenidas dentro de los objetos contenedores de base de datos que son llamados esquemas. El esquema también funciona como límite de seguridad, donde puedes limitar permisos de base de datos de usuarios para estar en un nivel especifico de esquema solamente. Puedes imaginar el esquema como un folder que contiene una lista de archivos. Puedes crear hasta 2.147.483.647 tablas en una base de datos con más de 1024 columnas en cada tabla. Cuando diseñas una tabla de base de datos, las propiedades que son asignadas a la tabla y a las columnas dentro de la misma, van a controlar los tipos de información permitidas y los rangos de información que la tabla acepta. Un diseño de tabla adecuado hará más fácil y más rápido el almacenamiento de información y recuperar información de la tabla.
Tipos de tablas especiales
Además de la tabla definida de usuario básico, SQL Server nos provee la habilidad de trabajar con otros tipos de tablas especiales. El primer tipo es la Tabla Temporal que es almacenada en el sistema de base de datos tempdb. Hay dos tipos de tablas temporales: Una tabla temporal local que tiene el único signo prefijo de número (#) y se puede acceder solo por la conexión vigente, y la tabla Global temporal que tiene dos signos prefijos de número (##) y se puede acceder por cualquier conexión una vez creada.
Una Tabla Ancha es una tabla que utiliza la Columna dispersa para optimizar el almacenamiento para los valores NULL, reduciendo el espacio consumido por la tabla e incrementando el número de columnas permitidas en la tabla a 30 mil columnas
Las Tablas del Sistema son un tipo especial de tabla en el cual el motor de SQL Server almacena información sobre las instancias de configuración de SQL Server e informaciones de objetos, que pueden ser consultadas usando las vistas del sistema.
Las Tablas con Particiones son tablas en las cuales la información será dividida horizontalmente en unidades separadas en el mismo grupo de archivos o diferentes grupos de archivos basados en una clave específica, para realzar el rendimiento de recuperación de información.
Implementación Física
Físicamente, las tablas de SQL Server son almacenadas en la base de datos como un conjunto de 8 KB de páginas. Las páginas de tablas están almacenadas por defecto en una sola partición que reside en el grupo de archivo default PRIMARY. Una tabla puede ser almacenada en particiones múltiples, en los cuales cada grupo de filas será almacenado en particiones específicas, en uno o más grupo de archivos basado en una columna especifica. Cada partición de tabla contiene filas de información. En una estructura de índice agrupado, que es administrada in unidades de localización, dependiendo de los tipos de información de cada columna en cada fila de información. La imagen basada en Microsoft, el artículo SQL Server libros en pantalla Organización de Tablas e Índices resume la estructura de la tabla:
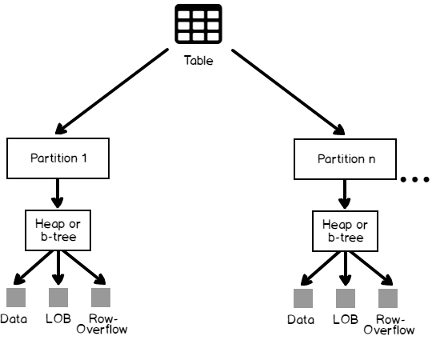
Como puedes ver de la anterior imagen, las páginas de información para la tabla de SQL Server pueden ser organizadas dentro de cada partición en dos formas: En Montón o en tablas Árbol B Agrupadas. En la tabla de Montón, las filas de información no son almacenadas en ningún orden particular dentro de cada página de información. Además, no hay un orden particular de controlar las secuencias de páginas de información que no estén conectadas a una lista de conexión. Esto es debido al hecho a que la tabla de montón contiene índices no agrupados. Como no hay un orden impuesto para las filas de la tabla de montón, las filas de información serán adicionadas a la primera localización disponible dentro de las páginas de tablas, después de verificar que tiene suficiente espacio. Si no hay espacio disponible, serán añadidas páginas adicionales a la tabla y las filas serán insertadas en estas nuevas páginas. Esta es la razón por la cual el orden de la información no puede ser predicha. Solo el orden de las filas devueltas puede ser impuesto usando la cláusula ORDER BY en la declaración SELECT.
Tabla Montón
Cuando almacenas información en tablas de montón, las filas en la tabla son identificadas por una referencia para el identificador de esa fila (RID) que contiene el número de archivo, el número de página de información y el espacio de cada página de información. La tabla de montón tiene una fila en el objeto sistema objeto sys.partitions para cada partición con un valor de id índice igual a 0. Puedes consultar el sistema objeto sys.indexes también para mostrar los detalles del índice de la tabla montón, que te mostrará que, el id de ese índice es 0 y que el tipo es el de HEAP, como se muestra abajo:

Cada partición en el la tabla montón tendrá un una estructura montón con las unidades de asignación de información para almacenar y manejar la información en esa partición dependiendo de los tipos de información en el montón. Por ejemplo, todos los montones contienen unidades de asignación IN_ROW_DATA y puede contener unidades de asignación LOB_DATA si contiene objetos grandes de información o unidades de asignación ROW_OVERFLOW_DATA si contiene columnas de extensión variable que excede el límite del tamaño de fila de 8K bytes.
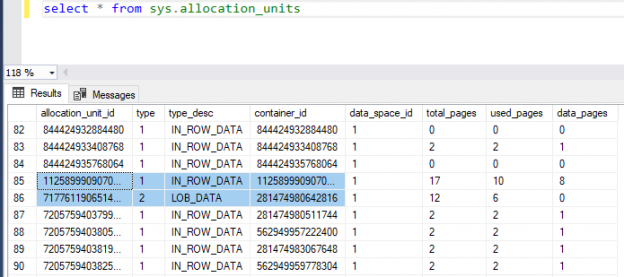
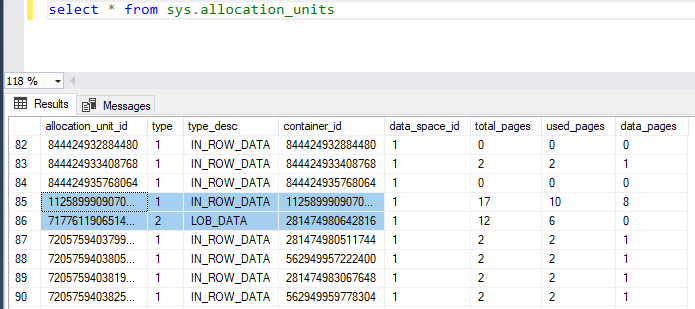
A pesar que cada montón no tiene una estructura de índice que maneje las páginas y la asignación de información, el motor de SQL Server usa un Mapa de Asignación de Índice (IAM) para mantener una entrada para cada página para localizar la asignación de estas páginas disponibles. El IAM es considerado como la única conexión lógica entre las páginas de información, que el Motor de SQL Server usará para moverse en el montón. El sistema objeto sys.allocation_units puede ser usado para listar todas las unidades de asignación en bases de datos específicos como es mostrado abajo:
Información adicional sobre la primera página IAM, la primera página, y la página raíz pueden ser vistas al consultar el sistema objeto como es mostrado abajo:
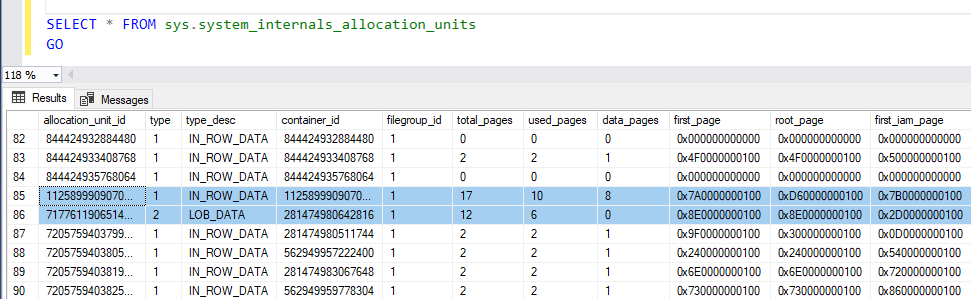
Para realizar un escáner de tabla en la tabla montón, el Motor SQL Server escaneará las páginas IAM en serie para localizar los límites que están sosteniendo la información solicitada. Recordar que la extensión consiste en 8 páginas. El SQL Server usa el primer valor de página IAM, que apunta a la primera página IAM en la cadena de páginas IAM, mostrada en la primera captura para localizar la página IAM que contiene la dirección de asignación de la tabla montón, donde SQL Server usará esa dirección en el IAM para encontrar las páginas de información de montón solicitadas.
Cuando la operación de modificación de información es realizada en las páginas de tablas de información de montón, los Punteros de Envío serán insertados en el montón para apuntar la nueva localización de la información movida. Estos punteros de envío van a causar problemas de rendimiento en el tiempo debido a que visitan la antigua/original localización vs la nueva localización especificada por los punteros de envío para obtener un valor específico. Empezando por la versión 2008 de SQL Server, un nuevo método ha sido introducido para mejorar los problemas de rendimiento de los punteros de envío, usando el comando ALTER TABLE REBUILD, que reconstruirá la tabla de montón como se muestra abajo:
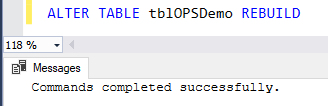
Es mejor no mantener la tabla con mecanismos de clasificación, cuando tienes largas tablas que puedes usar para recuperar información de una clasificación especifica con orden de agrupación de manera que resulte en un muy malo rendimiento. Para evitar esos problemas de rendimiento, la tabla puede ser diseñada con un orden lógico interno. Esto puede ser conseguido convirtiendo la tabla de tabla montón a tabla agrupada.
Tabla Agrupada
Una tabla agrupada es una tabla que tiene índices agrupados predefinidos en la columna o múltiples columnas de la tabla que define el orden de almacenamiento de las filas dentro de las páginas de las páginas de información y el orden de las páginas dentro de la tabla, basados en la clave de índice de agrupamiento. Como las filas de la tabla pueden ser almacenadas solo en un orden, puedes decidir solo un uso de índice agrupado por cada tabla.
Es un error común el asumir que las páginas de índice agrupados están físicamente clasificados basados en la clave de índice agrupado. SQL Server siempre trata de alinear entre el orden físico y lógico mientras se crea el índice, pero una vez que la información es eliminada o modificada, este orden será quebrado, llevando al común problema de fragmentación. Cuando una operación INSERT es realizada en la tabla agrupada, el SQL Server va a localizarla en la posición lógica correcta, si hay un espacio adecuado para ella, de otro modo, la página será dividida en dos páginas para encajar la nueva información insertada.
Un índice agrupado es construido usando las estructuras Árbol B, con un Árbol B por cada partición de las tablas agrupadas, en la cual la información de las páginas de cada nivel de los índices agrupados, desde el nivel raíz hasta el nivel de hoja, están unidos en una lista doblemente unida. Esto provee una navegación rápida de información debido al proceso de recuperación, basado en los valores de índices agrupados. Similar a la estructura de montón, cada Árbol B contendrá unidades de asignación IN_ROW_DATA y puede contener unidades de designación LOB_DATA si contiene objetos de información grandes o unidades de designación ROW_OVERFLOW_DATA si contiene longitudes de columna variables que excedan el tamaño de fila límite de 8K bytes.
Permítenos crear una restricción clave primaria en la primera tabla de montón, que va a añadir un índice agrupado automáticamente a esa tabla como se muestra abajo:

Consultando el sistema objeto sys.indexes para la tabla otra vez, verás que el ID del índice agrupado es 1 como se muestra en los detalles del índice abajo:

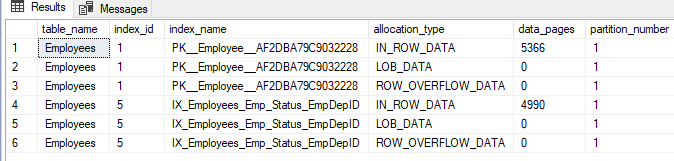
Podemos también obtener información detallada sobre todas las unidades de localización disponibles en una de nuestras largas tablas, la tabla de Empleado por ejemplo, al consultar el sistema objeto de sys.allocation_units y unirlo con las vistas sys.partitions, sys.objects y el sys.indexes system, usando la declaración T-SQL de abajo:
|
1 2 3 4 5 6 |
SELECT Obj.name AS table_name,Par.index_id, IDX.name AS index_name , AllUn.type_desc AS allocation_type, AllUn.data_pages, partition_number FROM sys.allocation_units AS AllUn JOIN sys.partitions AS Par ON AllUn.container_id = Par.partition_id JOIN sys.objects AS Obj ON Par.object_id = Obj.object_id JOIN sys.indexes AS IDX ON Par.index_id = IDX.index_id AND IDX.object_id = Par.object_id WHERE Obj.name = N'Employees' |
El resultado mostrará una lista de todas las particiones que forman la tabla Empleado, con toda la información de tipos de asignación disponible en cada partición, y el número de páginas de información en cada unidad de asignación, como se muestra abajo:
Conclusión
En este artículo hemos descrito en detalle, la estructura principal de la unidad de almacenaje de información de SQL Server, la tabla. Mencionamos también los diferentes tipos de tablas definidas por usuario que pueden ser usadas para almacenar tu información. Después de eso, andamos por las diferencias entre tablas de montón y tablas agrupadas desde diferentes aspectos, cómo convertir las tablas entre estos dos tipos, como también cómo obtener información estadística sobre las tablas de montón y agrupadas. En el siguiente artículo, iremos por los conceptos principales de los Índices de SQL Server. Sigue sintonizado.
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.


He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019