
Descripción
La solución y la reparación de consultas erróneas, así como la resolución de problemas de rendimiento pueden implicar horas (o días) de investigación y pruebas de errores. A veces podemos reducir rápidamente ese tiempo identificando patrones de diseño comunes que son indicativos de un TSQL de bajo rendimiento.
El desarrollo del reconocimiento de estos patrones para estas zonas de ojos súper críticos, de detectar errores puede permitirnos enfocarnos inmediatamente en lo que es más probable que sea el problema. Mientras que contrariamente el ajuste del rendimiento a menudo puede estar compuesto por horas de recopilación de eventos extendidos, seguimientos, planes de ejecución y estadísticas, y la posibilidad de ser capaz de identificar posibles escollos rápidamente puede provocar un cortocircuito en todo ese trabajo.
Si bien debemos realizar nuestra debida diligencia y demostrar que cualquier cambio que hagamos sea óptimo, ¡saber por dónde empezar puede ahorrar mucho tiempo!
Consejos y trucos
OR en la cláusula Join Predicate/WHERE en varias columnasEl SQL Server nos muestra que puede filtrar eficientemente un conjunto de datos utilizando índices a través y por medio de la cláusula WHERE o cualquier combinación de filtros separados por un operador AND. Al ser exclusivas, todas estas operaciones que toman datos y los dividen en partes progresivamente más pequeñas, hasta que solo queda nuestro conjunto de resultados.
OR es una historia diferente. Debido a que es inclusivo, SQL Server no puede procesarlo en una sola operación. Entonces podemos indicar que, cada componente del OR debe evaluarse de forma independiente. Cuando se completa esta operación costosa, los resultados se pueden concatenar y devolver a la situación de forma muy ordenada normalmente.
El peor caso de escenario en el que OR funciona de manera ineficiente es cuando hay varias columnas o tablas involucradas. No solo necesitamos evaluar cada componente de la cláusula OR, sino que debemos seguir esa ruta a través de los otros filtros y tablas dentro de la consulta. Pese a que podría darse el caso de que incluso solo intervienen unas pocas tablas o columnas, se tiene que el rendimiento puede ser increíblemente malo.
Aquí hay un ejemplo muy simple de cómo un OR puede causar que el rendimiento empeore mucho más de lo que imaginas:
|
1 2 3 4 5 6 7 |
SELECT DISTINCT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.ProductID = DETAIL.ProductID OR PRODUCT.rowguid = DETAIL.rowguid; |
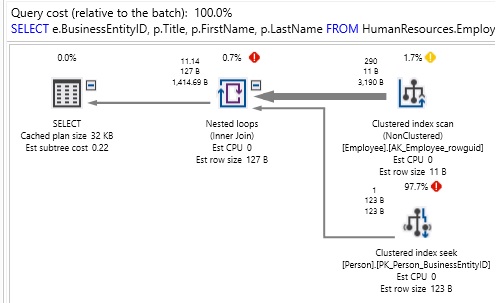
La consulta es bastante simple: 2 tablas y una combinación que verifica tanto ProductID como rowguid. Incluso pese a que, si ninguna de estas columnas estuviera indexada, nuestra expectativa sería un escaneo de tabla en Producto y un escaneo de tabla en SalesOrderDetail. Caro, pero por lo menos es algo que podemos comprender. Aquí está el rendimiento resultante de esta consulta:

Nosotros efectuamos el escaneo de ambas tablas, pero procesar el OR requirió una cantidad absurda de recursos del sistema. ¡1,2 millones de lecturas se hicieron en este esfuerzo! Teniendo en cuenta que el Producto contiene solo 504 filas y SalesOrderDetail contiene 121317 filas, leemos muchos más datos que el contenido completo de cada una de estas tablas. Adicionalmente se tiene que, Además, la consulta tardó aproximadamente 2 segundos en ejecutarse en un escritorio con SSD relativamente rápido.
La conclusión de esta demostración aterradora es que SQL Server no puede procesar fácilmente una condición OR en varias columnas. Por esta razón es que la mejor manera de lidiar con un OR es eliminarlo (si es posible) o dividirlo en consultas más pequeñas. Ya que por el contrario interrumpir una consulta corta y simple en una consulta más larga y prolongada puede no parecer elegante, pero al menos cuando se trata de problemas OR, a menudo es la mejor opción:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.ProductID = DETAIL.ProductID UNION SELECT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.rowguid = DETAIL.rowguid |
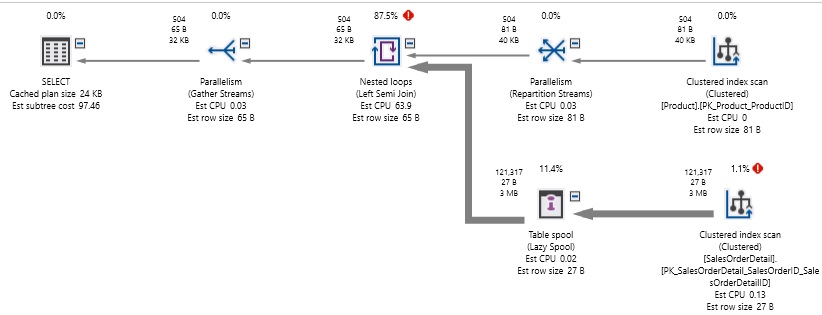
En esta reescritura de los procesos, nos tomamos cada componente del OR y lo convertimos en su propia instrucción SELECT. UNION la que por sí misma concatena el conjunto de resultados y elimina los duplicados. Aquí está el rendimiento resultante:

En este caso, el plan de ejecución se volvió significativamente más complejo, debido a que ahora estamos consultando cada tabla dos veces, en lugar de una, pero ya no necesitábamos jugar a ponerle la cola al burro de forma aleatoria con los conjuntos de resultados como lo hicimos antes. Las lecturas se redujeron significativamente de 1,2 millones a 750, y logrando que la consulta se ejecute en menos de un segundo, en lugar de en 2 segundos.
Tenga en cuenta que todavía hay una gran cantidad de escaneos de índice en el plan de ejecución, pero a pesar de la necesidad de escanear tablas cuatro veces para satisfacer nuestra consulta, el rendimiento es mucho mejor que antes.
Es importante tener cuidado al escribir consultas con una cláusula OR. Por ello, es crítico que pruebe y verifique que el rendimiento sea adecuado y que no esté introduciendo accidentalmente una bomba de tiempo de rendimiento similar a lo que observamos anteriormente. Si está revisando una aplicación de bajo rendimiento, la misma que se ejecuta en un OR en diferentes columnas o tablas, usted deberá concentrarse en eso como una posible causa de los problemas. Este es un patrón de consulta fácil de identificar que a menudo conduce a un bajo rendimiento.
Búsquedas de cadenas comodín
La búsqueda de las cadenas de manera eficiente puede ser un gran desafío, y además de que hay muchas más formas de procesar cadenas de manera ineficiente que eficiente. Para las columnas de cadenas buscadas con frecuencia, debemos asegurarnos de que:
- Los índices están presentes en las columnas buscadas
- Se pueden usar esos índices
- Si no, ¿podemos usar índices de texto completo?
- Si no, ¿podemos usar hashes, n-grams o alguna otra solución?
Debe ser muy importante el considerar que, sin el uso de características adicionales o consideraciones de diseño, el SQL Server no es bueno y eficiente en la búsqueda de cadenas difusas. Es decir, si quiero detectar la presencia de una cadena en cualquier posición dentro de una columna, obtener esos datos será ineficiente:
|
1 2 3 4 5 6 7 |
SELECT Person.BusinessEntityID, Person.FirstName, Person.LastName, Person.MiddleName FROM Person.Person WHERE Person.LastName LIKE '%For%'; |
En esta búsqueda de las cadenas específicas, estamos verificando Apellido para cualquier ocurrencia de “For” en cualquier posición dentro de la cadena. Recuerde que lo importante es que cuando se coloca un “%” al comienzo de una cadena, estamos haciendo imposible el uso de cualquier índice ascendente. De manera similar, cuando un “%” está al final de una cadena, también es imposible usar un índice descendente. La consulta anterior dará como resultado el siguiente rendimiento:
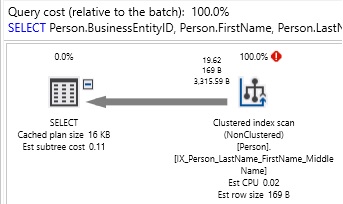

Como se esperaba, la consulta da como resultado efectuar un escaneo en Person.Person. La única forma de saber si existe una subcadena dentro de una columna de texto es desplazarse a través de cada carácter en cada fila, buscando ocurrencias de esa cadena. En una tabla pequeña, esto puede ser aceptable, pero de contraparte el efectuar una comparación con cualquier conjunto de datos de gran tamaño, será lento laborioso y doloroso esperar.
Hay una variedad de formas de atacar esta situación, que incluyen:
- Reevaluar la aplicación. ¿Realmente necesitamos hacer una búsqueda con comodines de esta manera? ¿Los usuarios realmente quieren buscar en todas las partes de esta columna una cadena determinada? Si no, ¡elimine esta capacidad y el problema desaparece! Si no hay problema de que preocuparse.
- ¿Podemos aplicar otros filtros a la consulta para reducir el tamaño de los datos antes de analizar la comparación de cadenas? Si podemos filtrar por fecha, hora, estado o algún otro tipo de criterio comúnmente utilizado, tal vez podríamos reducir los datos que necesitamos escanear a una cantidad lo suficientemente pequeña como para que nuestra consulta tenga un rendimiento aceptable.
- ¿Podemos hacer una búsqueda de cadena principal, en lugar de una búsqueda con comodines? ¿Se puede cambiar “% For%” a “For%”?
- ¿La indexación de texto completo es una opción disponible? ¿Podemos implementarlo y usarlo?
- ¿Podemos implementar una solución hash o n-gram de consulta?
Las primeras 3 opciones anteriores son percibidas como tantas consideraciones de diseño/arquitectura como soluciones de optimización. Por ello la pregunta es: ¿Qué más podemos suponer, cambiar o comprender acerca de esta consulta para ajustarla para que funcione bien? Todos estos cuestionamientos requieren cierto nivel de conocimiento de la aplicación o la capacidad de cambiar los datos devueltos por una consulta. Puede que estas no sean opciones disponibles para nosotros, en razón de esto es crítico y es importante involucrar a todas las partes que estén inmersos en el mismo tema y enfoque con respecto a la búsqueda de cadenas. Por ejemplo, en el caso de que una tabla tiene mil millones de filas y los usuarios desean buscar con frecuencia en una columna NVARCHAR (MAX) y la aparición de cadenas en cualquier posición, se tiene entonces que es necesario que se lleve a cabo una discusión seria sobre por qué alguien querría hacer esto y qué alternativas están disponibles. Si esa funcionalidad es realmente importante, entonces la empresa necesitará comprometer recursos adicionales para soportar la costosa búsqueda de cadenas, o aceptar una gran cantidad de retraso, lentitud, latencia y consumo de recursos en el proceso.
Es muy importante mencionar que la indexación de texto completo es una característica en SQL Server que puede generar índices que permitirán la búsqueda de cadenas flexibles en columnas de texto. Es necesario recordar que esto incluye búsquedas con comodines, pero también búsquedas lingüísticas de contexto que utilizan las reglas de un idioma determinado para tomar decisiones inteligentes sobre si una palabra o frase son lo suficientemente similares y adecuadas al contenido de una columna como para considerarse una adecuada coincidencia. Si bien es flexible, es importante mencionar que el texto completo es una característica adicional que debe instalarse, configurarse y mantenerse. Para algunas aplicaciones que están muy centradas en cadenas, esta de manera muy crítica ¡puede ser la solución perfecta! Se proporciona un enlace al final de este artículo con más detalles sobre esta característica, lo que puede hacer con ella, cómo instalarlo y configurarlo.
Deberemos considerar que una última opción disponible para nosotros puede ser una gran solución para columnas de cadenas más cortas. Los N-Grams son segmentos de cadena que se pueden almacenar por separado de los datos que estamos buscando y pueden proporcionar la capacidad de buscar subcadenas sin la necesidad de escanear una tabla grande. Antes de discutir este tema, es importante comprender completamente las reglas de búsqueda que utiliza una aplicación. Por ejemplo:
- ¿Se permite un número mínimo o máximo de caracteres en una búsqueda?
- ¿Se permiten búsquedas vacías (un escaneo de tabla)?
- ¿Se permiten múltiples palabras/frases?
- ¿Necesitamos almacenar subcadenas al comienzo de una cadena? Estos se pueden recopilar con una búsqueda de índice si es necesario
Hay que considerar que una vez que se evalúan estas consideraciones, podemos tomar una columna de cadena y dividirla en segmentos de cadena. Por ejemplo, en el caso de que debemos considerar un sistema de búsqueda donde hay una longitud mínima de búsqueda de 3 caracteres y la palabra almacenada “Dinosaurio”. Es aquí donde están las subcadenas de Dinosaurio que tienen 3 caracteres de longitud o más (ignorando el inicio de la cadena, que se puede reunir por separado y rápidamente con una búsqueda de índice en esta columna):
ino, inos, inosa, inosau, inosaur, nos, nosa, nosau, nosaur, osa, osau, osaur, sau, saur, aur.
Si tuviéramos que crear una tabla separada que almacenara cada una de estas subcadenas (también conocidas como n-gramos), podemos vincular esos n-gramos a la fila de nuestra gran tabla que tiene la palabra dinosaurio. Por esta razón, en lugar de escanear una tabla grande para obtener resultados, podemos hacer una búsqueda de igualdad contra la tabla de n-grams. Por ejemplo, si tuve que elaborar una búsqueda comodín para “dino”, mi búsqueda se puede redirigir a una búsqueda que se vería así:
|
1 2 3 4 |
SELECT n_gram_table.my_big_table_id_column FROM dbo.n_gram_table WHERE n_gram_table.n_gram_data = 'Dino'; |
Suponiendo que n_gram_data está indexado, deberemos devolver rápidamente todos los IDs de nuestra tabla grande que tenga la palabra Dino en cualquier lugar. La tabla de n-grams solo requiere 2 columnas, y podemos vincular el tamaño de la cadena de n-grams utilizando nuestras reglas de aplicación definidas anteriormente. Incluso si se tiene el caso de que, si esta tabla se hace grande, es probable que proporcione capacidades de búsqueda muy rápidas.
Hay que recordar que el costo es importante de este enfoque es el mantenimiento. Por esta razón, necesitamos actualizar la tabla de n-grams cada vez que se inserta, se elimina o se actualizan los datos de la cadena. Además, el número de n-grams por fila aumentará rápidamente a medida que aumenta el tamaño de la columna. Esta situación nos dará como resultado, un enfoque excelente para cadenas más cortas, como nombres, códigos postales o números de teléfono. Pese a que es una solución muy costosa para cadenas más largas, como texto de correo electrónico, descripciones y otras columnas de formato libre o longitud máxima.
Para recapitular rápidamente: hay que tomar en consideración que la búsqueda de cadenas comodín es inherentemente costosa. Nuestras mejores armas contra ella se basan en las eficientes reglas de diseño y arquitectura que nos permiten eliminar el “%” principal o limitar la forma en que buscamos de manera que permitan la implementación de otros filtros o soluciones. Por esta consideración, al final de este artículo se proporcionó un enlace con más información y algunas demostraciones de cómo generar y usar datos de n-grams. Si bien es una implementación más complicada, es otra arma muy importante en nuestro arsenal cuando otras opciones nos han fallado.
Operaciones de escritura grandes
Es importante mencionar que Después de una discusión de por qué la iteración puede causar un rendimiento deficiente, es ahora que vamos a explorar un escenario en el que contrariamente se tiene la situación en el que la iteración MEJORA el rendimiento. Un componente de optimización aún no discutido aquí es la contención. Debemos recordar de que cuando realizamos cualquier operación contra los datos, se puede observar que se tienen bloqueos contra cierta cantidad de datos para garantizar que los resultados sean consistentes y no interfieran con otras consultas que otros además de nosotros están ejecutando en contraposición de los mismos datos.
El cierre y el bloqueo de datos en algunas circunstancias puede ser el resultado de tener cosas buenas, ya que protegen los datos de la corrupción y nos protegen de los malos resultados. Sin embargo, cuando la contienda continúa por un largo tiempo, las consultas importantes pueden verse obligadas a esperar, lo que resulta en usuarios descontentos y las quejas de retaso y lentitud que genera latencia resultante.
Las operaciones de escritura grandes son el elemento secundario de la disputa, ya que a menudo bloquean una tabla completa durante el tiempo que lleva actualizar los datos, verificar restricciones, actualizar índices y desencadenar procesos (si los hay). Se deberá responder a las siguientes inquietudes ¿Qué tan grande es grande? No hay una regla estricta aquí. En una tabla sin desencadenadores o claves externas, grande podría ser 50,000, 100,000 o 1,000,000 de filas. En una tabla con muchas restricciones y desencadenadores, grande podría ser 2,000. La única forma de confirmar que se trata de un problema es tomar en la realidad el probarlo, observarlo y responder en consecuencia.
Además de la contención, las grandes operaciones de escritura generarán un gran crecimiento del archivo de registro. Recuerde que siempre que escriba volúmenes de datos inusualmente grandes, usted deberá vigilar el registro de transacciones y verificar que no corre el riesgo de llenarlo, o peor aún, de llenar su ubicación de almacenamiento físico.
Debemos considerar que se tiene que tener en cuenta que muchas operaciones de escritura grandes serán el resultado de nuestro propio trabajo: las versiones de software, los procesos de carga del almacén de datos, los procesos ETL y otras operaciones similares pueden necesitar escribir una gran cantidad de datos, incluso si se realiza con poca frecuencia. Debemos recordar que la prioridad de escribir documentos largos depende de nosotros el identificar el nivel de contención permitido para realizar nuestras tablas antes de ejecutar estos procesos. Si estamos cargando una tabla grande durante una ventana de mantenimiento cuando nadie más la está usando, entonces somos libres de implementarla usando cualquier estrategia que deseemos. Por otra parte, si se da la situación en la que estamos escribiendo grandes cantidades de datos en un sitio de producción ocupado, entonces deberemos reducir las filas modificadas por operación lo que sería una buena protección contra la contención.
Las operaciones comunes que pueden dar lugar a grandes escrituras son:
- Agregar una nueva columna a una tabla y rellenarla en toda la tabla
- Actualización de una columna en una tabla completa
- Cambiar el tipo de datos de una columna. Vea el enlace al final del artículo para obtener más información al respecto
- Importar un gran volumen de datos nuevos
- Archivar o eliminar un gran volumen de datos antiguos
Esto puede no ser a menudo un problema de rendimiento, pero es importante comprender los efectos de operaciones de escritura muy grandes ya que es factible el poder evitar eventos de mantenimiento importantes o lanzamientos que se descarrilan inesperadamente.
Índices faltantes
Debemos considerar que SQL Server, a través de la GUI de Management Studio, el XML del plan de ejecución o los DMV de índice que faltan, permitirá que recibamos la información cuando faltan índices que podrían ayudar a que una consulta funcione mejor:

Esta advertencia es útil porque nos permite saber que a diferencia de otras circunstancias que existe una solución potencialmente más fácil para mejorar el rendimiento de las consultas. Por otra parte también tiene un lado obscuro ya que también es engañoso porque un índice adicional puede no ser la mejor manera de resolver un problema de atraso y de latencia. El texto verde nos proporciona todos los detalles de un nuevo índice, pero tenemos que hacer un poco de trabajo antes de considerar tomar el consejo de SQL Server:
- ¿Existen índices existentes que sean similares a este que puedan modificarse para cubrir este caso de estudio?
- ¿Necesitamos todas las columnas de inclusión? ¿Sería suficiente un índice en las columnas de clasificación?
- ¿Qué tan alto es el impacto del índice? ¿Mejorará una consulta en un 98 %, o solo en un 5 %?
- ¿Este índice ya existe, pero por alguna razón el optimizador de consultas no lo elige?
A menudo, los índices sugeridos son excesivos. Por ejemplo, aquí está la instrucción de creación de índice para el plan parcial que se muestra arriba:
|
1 2 3 |
CREATE NONCLUSTERED INDEX <Name of Missing Index, sysname,> ON Sales.SalesOrderHeader (Status,SalesPersonID) INCLUDE (SalesOrderID,SubTotal) |
En este caso, ya hay un índice en SalesPersonID. El estado es una columna en la que la tabla contiene principalmente un valor, por lo que significa que, como columna de clasificación, no nos proporcionaría mucho valor. El impacto del 19% no es terriblemente impresionante. En última instancia, deberíamos preguntarnos si la consulta es lo suficientemente importante como para garantizar esta mejora. Por otra parte, si se ejecuta un millón de veces al día, entonces quizás todo este trabajo para una mejora del 20% valga la pena.
Considere otra recomendación de índice alternativa:
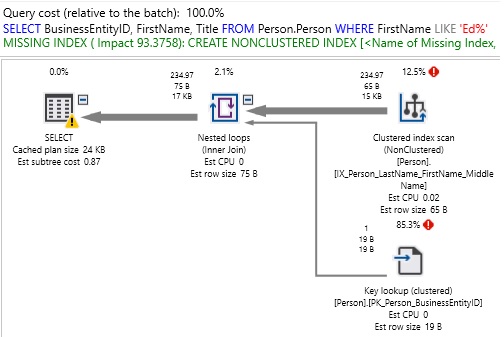
Aquí, el índice que falta es:
|
1 2 3 |
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Person].[Person] ([FirstName]) INCLUDE ([BusinessEntityID],[Title]) |
Es importante observar que, por esta vez, el índice sugerido proporcionaría una mejora del 93% y manejaría una columna no indexada (Nombre). Si la situación existente es que esta es una consulta que se ejecuta con frecuencia, entonces agregar este índice probablemente sería un movimiento inteligente. ¿Agregamos BusinessEntityID y Title como columnas INCLUDE? Esta es una pregunta mucho más subjetiva y debemos decidir si la consulta es lo suficientemente importante como para querer asegurarnos de que nunca haya una búsqueda clave para extraer esas columnas adicionales del índice agrupado. Recuerde que la presente interrogante de esta pregunta es un eco de “¿Cómo sabemos cuándo el rendimiento de una consulta es óptimo?”. Deberemos verificar que, si el índice de no cobertura es lo suficientemente bueno, detenerse allí sería la decisión correcta, ya que ahorraría los recursos informáticos necesarios para almacenar las columnas adicionales. Pero de contraparte si el rendimiento aún no es lo suficientemente bueno, entonces el siguiente paso lógico sería agregar las columnas INCLUDE.
Siempre que recordemos que los índices requieren mantenimiento y ralentizan las operaciones de escritura, podemos abordar la indexación desde una perspectiva pragmática y asegurarnos de no cometer ninguno de estos errores:
Indexación excesiva de una tabla
Resulta bastante lógico que cuando una tabla tiene demasiados índices, las operaciones de escritura se vuelven más lentas ya que cada ACTUALIZACIÓN, BORRADO e INSERCIÓN que toca una columna indexada debe actualizar todos los índices en ella. Además, esos índices ocupan espacio en el almacenamiento, así como en las copias de seguridad de la base de datos. El término de “Demasiados” es vago, pero enfatiza que, en última instancia, el rendimiento de la aplicación es la clave para determinar si las cosas son óptimas o no.
Subindexar una tablaUna tabla subindexada no sirve para efectuar las consultas de lectura de manera efectiva. Por tanto, de manera ideal, las consultas más comunes ejecutadas en una tabla deberían beneficiarse de los índices. Las consultas menos frecuentes se evalúan caso por caso y se indexan cuando son beneficiosas. Recordemos que cuando se soluciona un problema de rendimiento en tablas que tienen pocos o ningún índice no agrupado, entonces es probable que el problema sea de baja indexación. Es importante mencionar que, en estos casos, ¡puede sentirse facultado para agregar índices para mejorar el rendimiento según sea necesario!
Sin índice agrupado/clave primariaTodas las tablas deben tener un índice agrupado y una clave primaria. Los índices agrupados casi siempre funcionarán mejor que los montones que se hallan dispersos y proporcionarán la infraestructura necesaria para agregar índices no agrupados de manera eficiente cuando sea necesario. El disponer de una clave principal proporciona información valiosa al optimizador de consultas que permitirá realizar y tomar decisiones inteligentes al crear planes de ejecución. Si se encuentra con una tabla sin índice agrupado o sin clave principal, considere estas prioridades principales para investigar y resolver antes de continuar con la investigación adicional.
Resulta muy relevante que usted consulte el enlace al final de este artículo para obtener detalles sobre la captura, tendencias e informes sobre datos de índice faltantes utilizando las vistas de administración dinámica incorporadas de SQL Server. Esto te permite aprender sobre las sugerencias de índice faltantes cuando no esté mirando su computadora. También le permitirá observar y ver cuándo se hacen múltiples sugerencias en una sola consulta. La GUI solo mostrará la sugerencia principal, pero el XML sin procesar para el plan de ejecución incluirá tantos como se sugiera.
Alto conteo de tablas
Resulta en esta circunstancia que el optimizador de consultas en SQL Server se enfrenta al mismo desafío que cualquier optimizador de consultas relacionales: por cuanto se requiere encontrar un buen plan de ejecución frente a muchas opciones en un lapso de tiempo muy corto. Esto da como resultado en un juego de ajedrez y que requiere evaluar de manera muy anticipada cada uno de los movimientos tras movimientos. Con cada evaluación, se descarta una gran cantidad de planes similares al plan subóptimo, o deja uno a un lado como un plan candidato. Más tablas en una consulta equivaldrían a un tablero de ajedrez más grande. Con significativamente más cantidad y variables de opciones disponibles, SQL Server tiene más trabajo por hacer, pero no puede tomar mucho más tiempo para determinar el plan a utilizar.
Cada tabla agregada a una consulta aumenta su complejidad en una creciente cantidad factorial. Si bien el optimizador generalmente tomará buenas decisiones, incluso frente a muchas tablas, es importante verificar que aumentamos el riesgo de planes ineficientes con cada tabla agregada a una consulta. Esto no quiere decir que las consultas con muchas tablas sean malas, sino que debemos tener cuidado al aumentar el tamaño de una consulta. Recuerde que para cada conjunto de tablas es importante que se deba determinar el orden de unión, el tipo de unión y cómo/cuándo aplicar filtros y agregación.
Según cómo se unen las tablas, una consulta se dividirá en una de dos formas básicas:
- Árbol profundo a la izquierda: A join B, B join C, C join D, D join E, etc… Esta es una consulta en la que la mayoría de las tablas se unen secuencialmente una tras otra
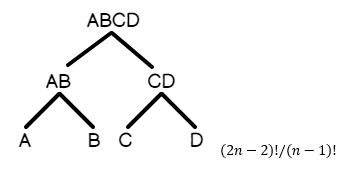
- Árbol tupido: A join B, A join C, B join D, C join E, etc… Esta es una consulta en la que las tablas se ramifican en múltiples unidades lógicas dentro de cada rama del árbol
Aquí en este apartado temático se puede ver que hay una representación gráfica de un árbol tupido, en el que las uniones se ramifican hacia arriba en el conjunto de resultados:
Del mismo modo, aquí hay una representación de cómo se vería un árbol profundo a la izquierda.
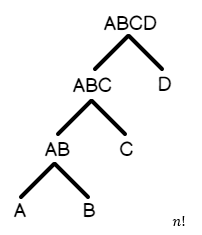
Dado que el árbol profundo a la izquierda se ordena de forma más natural en función de cómo se unen las tablas, se observa que el número de planes de ejecución candidatos para la consulta es menor que para un árbol espeso. Por esta razón, se incluye arriba la matemática detrás del análisis combinatorio: es decir, cuántos planes se generarán en promedio para un tipo de consulta dado.
Para enfatizar la enormidad de los recuentos matemáticos detrás de la tabla, considere una consulta que accede a 12 tablas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
SELECT TOP 25 Product.ProductID, Product.Name AS ProductName, Product.ProductNumber, CostMeasure.UnitMeasureCode, CostMeasure.Name AS CostMeasureName, ProductVendor.AverageLeadTime, ProductVendor.StandardPrice, ProductReview.ReviewerName, ProductReview.Rating, ProductCategory.Name AS CategoryName, ProductSubCategory.Name AS SubCategoryName FROM Production.Product INNER JOIN Production.ProductSubCategory ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID INNER JOIN Production.ProductCategory ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID INNER JOIN Production.UnitMeasure SizeUnitMeasureCode ON Product.SizeUnitMeasureCode = SizeUnitMeasureCode.UnitMeasureCode INNER JOIN Production.UnitMeasure WeightUnitMeasureCode ON Product.WeightUnitMeasureCode = WeightUnitMeasureCode.UnitMeasureCode INNER JOIN Production.ProductModel ON ProductModel.ProductModelID = Product.ProductModelID LEFT JOIN Production.ProductModelIllustration ON ProductModel.ProductModelID = ProductModelIllustration.ProductModelID LEFT JOIN Production.ProductModelProductDescriptionCulture ON ProductModelProductDescriptionCulture.ProductModelID = ProductModel.ProductModelID LEFT JOIN Production.ProductDescription ON ProductDescription.ProductDescriptionID = ProductModelProductDescriptionCulture.ProductDescriptionID LEFT JOIN Production.ProductReview ON ProductReview.ProductID = Product.ProductID LEFT JOIN Purchasing.ProductVendor ON ProductVendor.ProductID = Product.ProductID LEFT JOIN Production.UnitMeasure CostMeasure ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode ORDER BY Product.ProductID DESC; |
Con 12 tablas en una consulta de estilo relativamente ocupado, las matemáticas funcionarían para:
(2n-2)! / (n-1)! = (2*12-1)! / (12-1)! = 28,158,588,057,600 posibles planes de ejecución.
Si la consulta hubiera sido de naturaleza más lineal, entonces tendríamos:
n! = 12! = 479,001,600 posibles planes de ejecución.
De manera impresionante se puede observar que ¡Esto es solo para 12 tablas! ¡Imagine una consulta en 20, 30 o 50 tablas! Pese a que el optimizador a menudo puede reducir esos números muy rápidamente eliminando franjas enteras de opciones subóptimas, se tiene que enfatizar que sin embargo las probabilidades de que pueda hacerlo y generar un buen plan disminuyen a medida que aumenta el recuento de tablas.
¿Cuáles son algunas formas útiles de optimizar una consulta que está sufriendo debido a demasiadas tablas?
- Mover metadatos o tablas de búsqueda en una consulta separada que coloca estos datos en una tabla temporal
- Las uniones que se usan para devolver una sola constante se pueden mover a un parámetro o variable
- Divida una consulta grande en consultas más pequeñas cuyos conjuntos de datos se puedan unir más tarde cuando esté listo
- Para consultas muy utilizadas, considere una vista indizada para agilizar el acceso constante a datos importantes
- Eliminar tablas, subconsultas y uniones innecesarias
El considerar el descomponer una consulta grande en consultas más pequeñas requiere que no haya cambios sustanciales de datos entre esas consultas que de alguna manera invalidarían el conjunto de resultados. Si por ejemplo una consulta debe ser un conjunto atómico, es posible que deba usar una combinación de niveles de aislamiento, transacciones y bloqueo para garantizar la integridad de los datos.
Es muy relevante el considerar que, en la mayoría de los casos, cuando unimos un gran número de tablas, podemos dividir la consulta en unidades lógicas más pequeñas que se pueden ejecutar por separado. Recordamos que, para la consulta del ejemplo anterior en las 12 tablas, podríamos eliminar fácilmente algunas tablas no utilizadas y dividir la recuperación de datos en dos consultas separadas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
SELECT TOP 25 Product.ProductID, Product.Name AS ProductName, Product.ProductNumber, ProductCategory.Name AS ProductCategory, ProductSubCategory.Name AS ProductSubCategory, Product.ProductModelID INTO #Product FROM Production.Product INNER JOIN Production.ProductSubCategory ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID INNER JOIN Production.ProductCategory ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID ORDER BY Product.ModifiedDate DESC; SELECT Product.ProductID, Product.ProductName, Product.ProductNumber, CostMeasure.UnitMeasureCode, CostMeasure.Name AS CostMeasureName, ProductVendor.AverageLeadTime, ProductVendor.StandardPrice, ProductReview.ReviewerName, ProductReview.Rating, Product.ProductCategory, Product.ProductSubCategory FROM #Product INNER JOIN Production.ProductModel ON ProductModel.ProductModelID = Product.ProductModelID LEFT JOIN Production.ProductReview ON ProductReview.ProductID = Product.ProductID LEFT JOIN Purchasing.ProductVendor ON ProductVendor.ProductID = Product.ProductID LEFT JOIN Production.UnitMeasure CostMeasure ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode; DROP TABLE #Product; |
Como se podrá observar en esta situación, esta es solo una de las muchas soluciones posibles, pero es una forma de reducir una consulta más grande y compleja en dos más simples. Resulta entonces que como beneficio adicional, podemos revisar las tablas involucradas y eliminar las tablas, columnas, variables o cualquier otra cosa innecesaria que no sea relevante e importante para devolver los datos que estamos buscando.
El recuento de tablas representa un costo verdaderamente considerable para los planes de ejecución deficientes, por cuanto la situación hace que se obliga al optimizador de consultas a examinar un conjunto de resultados más grande y efectuar de forma importante el descartar resultados potencialmente más válidos en la búsqueda de un gran plan en menos de un segundo. Por el contrario, si usted está evaluando una consulta de bajo rendimiento que tiene un recuento de tabla muy grande, intente dividirla en consultas más pequeñas. Es posible que esta táctica no siempre proporcione una mejora significativa, pero a menudo resulta en una acción mucho más eficaz cuando se han explorado otras vías y hay muchas tablas que se están leyendo mucho en una sola consulta.
Sugerencias de consulta (hints)
Una sugerencia de consulta es una dirección explícita de nosotros hacia el optimizador de consultas. Pese a ello, estamos omitiendo algunas de las reglas utilizadas por el optimizador para obligarlo a comportarse de una manera que normalmente no lo haría. En este sentido, es más una directiva que una pista.
Debemos recordar que las sugerencias de consulta a menudo se usan cuando tenemos un problema de rendimiento y afortunadamente al agregar una sugerencia de manera rápida y mágica se soluciona. Hay bastantes sugerencias disponibles en SQL Server que afectan los niveles de aislamiento, los tipos de unión, el bloqueo de tablas y más. Recuerde que según la regla de las compensaciones del trade-off, si bien las sugerencias pueden tener usos legítimos, presentan un peligro para el rendimiento por muchas razones:
- Los cambios futuros en los datos o el esquema pueden dar como resultado que una sugerencia ya no sea aplicable y se convierta en un obstáculo hasta que se elimine
- Las sugerencias pueden ocultar problemas más grandes, como la falta de índices, solicitudes de datos excesivamente grandes o lógica de negocios rota. Resolver la raíz de un problema es preferible a resolver un síntoma
- Las sugerencias pueden provocar un comportamiento inesperado, como datos incorrectos de lecturas sucias mediante el uso de NOLOCK
- Aplicar una sugerencia para abordar un caso límite puede causar una degradación del rendimiento en todos los demás escenarios
Debemos considerar de manera muy seria que la regla general es aplicar sugerencias de consulta con la menor frecuencia posible, por cuanto de acuerdo con la experiencia solo después de que se haya realizado suficiente investigación, y solo cuando estemos seguros de que no habrá efectos secundarios negativos del cambio. Deben usarse como si fuera un bisturí cuando fallan todas las demás opciones. Algunas notas sobre sugerencias de uso común:
- NOLOCK: en caso de que los datos estén bloqueados, esto le indica a SQL Server que lea los datos del último valor conocido disponible, también conocido como lectura sucia. Por ello cuando y como es posible usar algunos valores antiguos y algunos valores nuevos, los conjuntos de datos pueden contener inconsistencias. No utilice esto en ningún lugar donde la calidad de los datos sea importante
- RECOMPILE: al agregar esto al final de una consulta, se generará un nuevo plan de ejecución cada vez que se ejecute esta consulta. Esto no debe usarse en una consulta que se ejecuta con frecuencia, ya que el costo para optimizar una consulta no es trivial y puede resultar en consecuencias realmente funestas. Sin embargo, para informes o procesos poco frecuentes, esta puede ser una forma efectiva de evitar la reutilización no deseada del plan. Esto a menudo se usa como vendaje cuando las estadísticas están desactualizadas o cuando se está olfateando parámetros
- MERGE/HASH/LOOP: Esto le dice al optimizador de consultas que use un tipo específico de combinación como parte de una operación de combinación. La ejecución de este proceso dará lugar a una situación de mucho riesgo ya que la unión óptima cambiará a medida que los datos, el esquema y los parámetros evolucionen con el tiempo. Si bien esto puede solucionar un problema en este momento, introducirá un elemento de deuda técnica que permanecerá durante todo el tiempo que lo haga
- OPTIMIZE FOR: puede especificar un valor de parámetro para optimizar la consulta. Esto se usa a menudo cuando queremos que se controle el rendimiento para un caso de uso muy común para que los valores atípicos no contaminen el caché del plan. Esta situación es muy similar a las sugerencias de combinación, esto es frágil y cuando la lógica empresarial cambia, este uso de sugerencias puede volverse obsoleto
Considere nuestra consulta de búsqueda de nombre de antes:
|
1 2 3 4 5 6 7 8 9 |
SELECT e.BusinessEntityID, p.Title, p.FirstName, p.LastName FROM HumanResources.Employee e INNER JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID WHERE FirstName LIKE 'E%' |
Podemos forzar una UNIÓN MERGE en el predicado join:
|
1 2 3 4 5 6 7 8 9 |
SELECT e.BusinessEntityID, p.Title, p.FirstName, p.LastName FROM HumanResources.Employee e INNER MERGE JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID WHERE FirstName LIKE 'E%' |
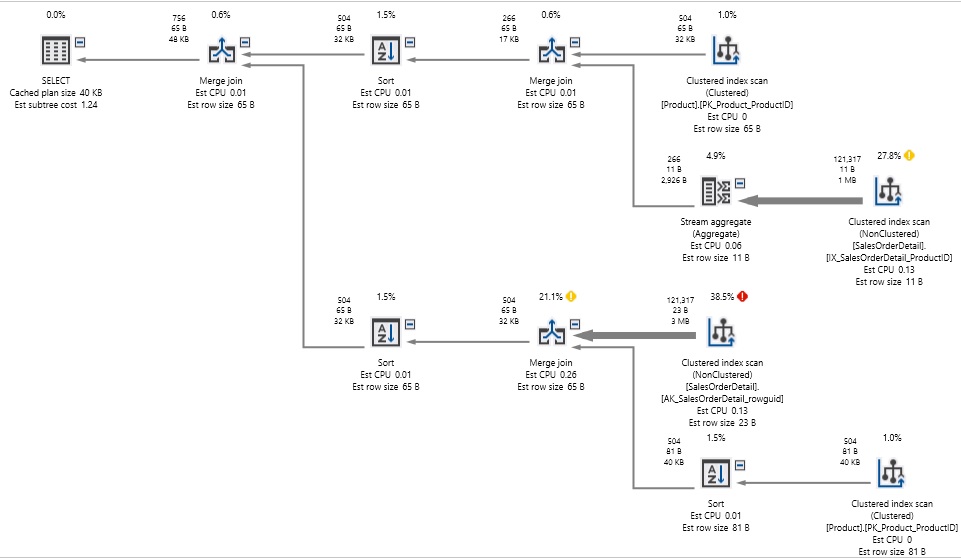
Cuando lo hacemos, podríamos observar un mejor desempeño en ciertas circunstancias, lo cual resulta en algo que no es frecuente pero también podríamos observar un desempeño muy pobre en otros:
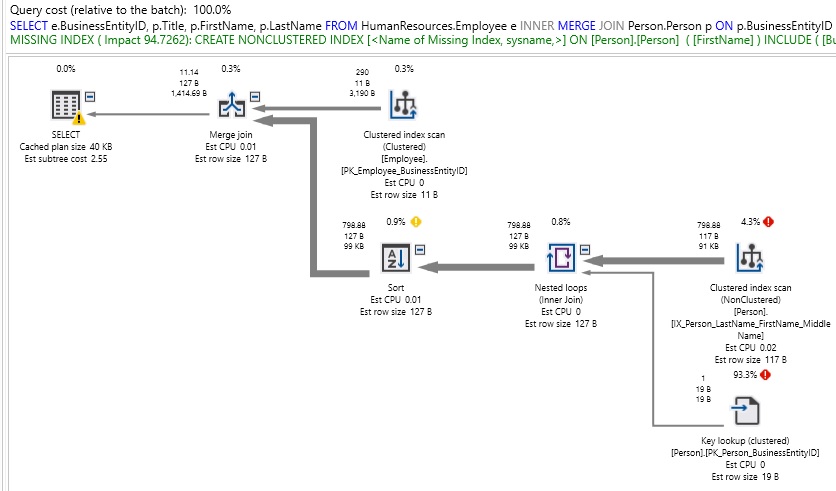

Definitivamente hay que considerar que, para una consulta relativamente simple, ¡esto es bastante feo! También tenga en cuenta que nuestro tipo de combinación tiene un uso de índice limitado, y esto dará como resultado que estamos obteniendo una recomendación de índice donde probablemente no deberíamos necesitarla/quererla. Como se verá, de hecho, forzar una MERGE JOIN agregó una variedad de operadores adicionales a nuestro plan de ejecución para ordenar adecuadamente los resultados para su uso en la resolución de nuestro conjunto de resultados. Podemos forzar un HASH JOIN de manera similar:
|
1 2 3 4 5 6 7 8 9 |
SELECT e.BusinessEntityID, p.Title, p.FirstName, p.LastName FROM HumanResources.Employee e INNER HASH JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID WHERE FirstName LIKE 'E%' |
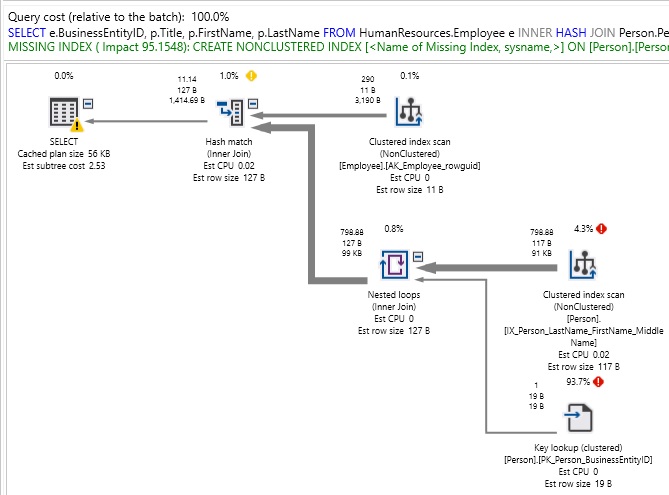

Véase que, en esta circunstancia de nuevo, ¡el plan no es bonito! Tenga en cuenta la advertencia en la pestaña de salida que nos informa que el orden de unión ha sido aplicado por nuestra elección de unión. La advertencia nos manifiesta que esto es importante ya que dice que el tipo de combinación que elegimos también limitó las posibles formas de ordenar las tablas durante la optimización. Recuerde que esencialmente, hemos eliminado muchas herramientas útiles disponibles para el optimizador de consultas y lo hemos forzado a trabajar con mucho menos de lo que necesita para tener éxito.
Por esta razón, si eliminamos las sugerencias, el optimizador elegirá una unión NESTED LOOP y obtendrá el siguiente rendimiento:
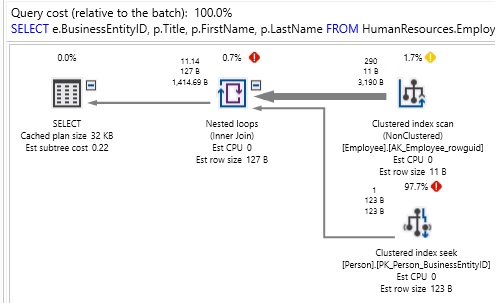

Por ello es importante considerar que estas son las sugerencias que a menudo se usan como soluciones rápidas a problemas complejos o desordenados. Si bien existen razones legítimas para usar una sugerencia, generalmente se consideran como si fueran los últimos recursos. Las sugerencias son elementos de consulta adicionales que requieren un permanente proceso de mantenimiento y revisión a lo largo del tiempo a medida que cambian el código, los datos o el esquema de la aplicación. Si es necesario, asegúrese de documentar a fondo su uso. Es poco probable que un DBA o desarrollador sepa por qué usó una pista en 3 años a menos que documente muy bien su necesidad.
Conclusión
En este artículo se analizó y se discutió una variedad de errores de consulta comunes que pueden derivar y conducir a un bajo rendimiento. Dado que son relativamente fáciles de identificar sin una investigación exhaustiva, nosotros podríamos utilizar este conocimiento para mejorar nuestro tiempo de respuesta ante emergencias de latencia o rendimiento. Como se podrá observar esta situación que se muestra es solo la punta del iceberg, pero proporciona un excelente punto de partida para encontrar los puntos débiles en un script.
En consecuencia, ya sea limpiando uniones y cláusulas WHERE o dividiendo una consulta grande en fragmentos más pequeños, el enfocar nuestra evaluación, prueba y proceso de control de calidad mejorará la calidad de nuestros resultados, además de permitirnos completar estos proyectos de manera mucho más acelerada.
Todos tienen su propio conjunto de herramientas de consejos y trucos que les permiten trabajar de manera más rápida e inteligente.¿Tiene algún consejo de consulta rápido, divertido o interesante? ¡Házmelo saber! ¡Siempre estoy buscando nuevas formas de acelerar TSQL y evitar días de búsqueda frustrante!
Tabla de contenido
| Técnicas de optimización de consultas en SQL Server: lo básico |
| Técnicas de optimización de consultas en SQL Server: consejos y trucos |
| Técnicas de optimización de consultas en SQL Server: diseño y arquitectura de bases de datos |
| Técnicas de optimización de consultas en SQL Server: detección de parámetros |

En su tiempo libre, Ed juega video juegos, películas de ciencia ficción y fantásticas, viajar y ser un gran geek al nivel que sus amigos puedan tolerar.
Vea todas las entradas de Ed Pollack
- Técnicas de optimización de consultas en SQL Server: consejos y trucos de aplicación - September 30, 2019
- Todo lo que querías saber sobre SQL Saturday (pero tenías miedo de preguntar) - April 13, 2018
- Cambios del Optimizador de Consultas en SQL Server 2016 explicados - April 21, 2017