
Como profesionales de bases de datos, estamos frecuentemente en mucha proximidad con procesos, datos y aplicaciones importantes. Mientras adoptamos el mantra de “No dañar”, muchas tareas de mantenimiento o reportes que creamos llevan riesgos no vistos asociados con ellas.
¿Qué pasa cuando un disco se llena durante una toma de copia de seguridad diferencial diaria? ¿Qué si un trabajo de reconstrucción de índice corre durante un tiempo anormalmente largo e interfiere con el procesamiento de la mañana? ¿Qué si un proceso de carga de datos causa una contención extensiva de recursos, colapsando las operaciones normales? Todos estos son eventos planeados, y aun así pueden causar una disrupción considerable a los mismos procesos que estamos intentando salvaguardar.
Hay muchas maneras simples de proteger nuestros trabajos de mantenimiento importantes contra situaciones que podrían fácilmente tumbar nuestros sistemas de producción. Esta es una oportunidad para mejorar grandemente nuestras prácticas estándar y ¡evitar llamadas innecesarias a las 2am un domingo!
¿Qué puede ir mal?
En las tareas que realizamos regularmente, una gran variedad de cosas malas (prevenibles) pueden pasar. Aquí está una lista corta de ejemplos que pueden mantenernos despiertos hasta tarde en la noche:
- Un trabajo de recolección de datos realiza una cantidad inusualmente grande de actividad, llenando el disco duro para una base de datos de reportes y dejándolo en un estado donde los reportes no pueden correr.
- Un lanzamiento de software grande resulta en mucho más datos cambiados de lo esperado. Las copias de seguridad de registros de transacciones se vuelven muy grandes durante el lanzamiento, llenando el disco destino para copias de seguridad y causando que las copias de seguridad subsecuentes fallen.
- Siguiendo ese lanzamiento grande, un trabajo de reconstrucción de índice encuentra más índices de lo usual que requieren reconstrucción. Este proceso puede causar un crecimiento significativo del registro, llenando el disco de archivos de registro y evitando procesos transaccionales posteriores.
- Un proceso de archivar toma más que lo usual, corriendo en horas de producción normales e interfiriendo con importantes operaciones diarias.
- Múltiples trabajos de mantenimiento corren por mucho tiempo, sobreponiéndose y causando un consumo de CPU y disco (I/O) excesivos. Adicionalmente, cada trabajo es ralentizado por la contención de recursos causada por la presencia del otro.
Dependiendo de sus ambientes de bases de datos, algunos de estos problemas pueden ser más relevantes que otros, y puede que haya otros que no están listados aquí. Note la significancia de cómo los trabajos pueden impactarse entre sí y causar problemas cuando se combinan. El lanzamiento grande de software mencionado anteriormente causa crecimiento de los datos y el registro, lo cual podemos anticipar y mitigar. La fragmentación de índice causada por el lanzamiento, de todos modos, conduce a que el trabajo de mantenimiento de índice tenga que trabajar mucho más de lo que típicamente se espera. No sólo debemos proteger los trabajos contra problemas esperados, sino que necesitamos construir una protección contra situaciones inusuales o infrecuentes, especialmente aquellas causadas por la interacción de múltiples trabajos.
Solución
Podemos construir verificaciones simples en nuestros trabajos de mantenimiento que se ocupen de los recursos disponibles, así como qué necesitará una operación previamente a la ejecución. Esto nos permite asegurarnos de que nuestro ambiente puede manejar lo que estamos a punto de hacer, y abortar con un error significativo si los recursos son inadecuados.
Para ilustrar algunas de estas opciones, demostraremos un procedimiento almacenado de mantenimiento de índice simple. El mantenimiento de índice puede ser significativamente más complejo, pero las técnicas mostradas aquí serán útiles sin importar lo intrincado de sus procedimientos de mantenimiento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
CREATE PROCEDURE dbo.index_maintenance_daily @reorganization_percentage TINYINT = 10, @rebuild_percentage TINYINT = 35 AS BEGIN DECLARE @sql_command NVARCHAR(MAX) = ''; DECLARE @parameter_list NVARCHAR(MAX) = '@reorganization_percentage TINYINT, @rebuild_percentage TINYINT' DECLARE @database_list TABLE (database_name NVARCHAR(MAX) NOT NULL); INSERT INTO @database_list (database_name) SELECT name FROM sys.databases WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model'); CREATE TABLE #index_maintenance ( database_name NVARCHAR(MAX), schema_name NVARCHAR(MAX), object_name NVARCHAR(MAX), index_name NVARCHAR(MAX), index_type_desc NVARCHAR(MAX), avg_fragmentation_in_percent FLOAT, index_operation NVARCHAR(MAX)); SELECT @sql_command = @sql_command + ' USE [' + database_name + '] INSERT INTO #index_maintenance (database_name, schema_name, object_name, index_name, index_type_desc, avg_fragmentation_in_percent, index_operation) SELECT CAST(SD.name AS NVARCHAR(MAX)) AS database_name, CAST(SS.name AS NVARCHAR(MAX)) AS schema_name, CAST(SO.name AS NVARCHAR(MAX)) AS object_name, CAST(SI.name AS NVARCHAR(MAX)) AS index_name, IPS.index_type_desc, IPS.avg_fragmentation_in_percent, -- Be sure to filter as much as possible...this can return a lot of data if you dont filter by database and table. CAST(CASE WHEN IPS.avg_fragmentation_in_percent >= @rebuild_percentage THEN ''REBUILD'' WHEN IPS.avg_fragmentation_in_percent >= @reorganization_percentage THEN ''REORGANIZE'' END AS NVARCHAR(MAX)) AS index_operation FROM sys.dm_db_index_physical_stats(NULL, NULL, NULL, NULL , NULL) IPS INNER JOIN sys.databases SD ON SD.database_id = IPS.database_id INNER JOIN sys.indexes SI ON SI.index_id = IPS.index_id INNER JOIN sys.objects SO ON SO.object_id = SI.object_id AND IPS.object_id = SO.object_id INNER JOIN sys.schemas SS ON SS.schema_id = SO.schema_id WHERE alloc_unit_type_desc = ''IN_ROW_DATA'' AND index_level = 0 AND SD.name = ''' + database_name + ''' AND IPS.avg_fragmentation_in_percent >= @reorganization_percentage AND SI.name IS NOT NULL -- Only review index, not heap data. AND SO.is_ms_shipped = 0 -- Do not perform maintenance on system objects ORDER BY SD.name ASC;' FROM @database_list WHERE database_name IN (SELECT name FROM sys.databases); EXEC sp_executesql @sql_command, @parameter_list, @reorganization_percentage, @rebuild_percentage; SELECT @sql_command = ''; SELECT @sql_command = @sql_command + ' USE [' + database_name + '] ALTER INDEX [' + index_name + '] ON [' + schema_name + '].[' + object_name + '] ' + index_operation + '; ' FROM #index_maintenance; SELECT * FROM #index_maintenance ORDER BY avg_fragmentation_in_percent; EXEC sp_executesql @sql_command; DROP TABLE #index_maintenance; END |
Este procedimiento almacenado toma dos parámetros que indican a qué nivel de fragmentación un índice debería ser reorganizado y reconstruido. Usando esa información, cada índice en cada base de datos que no es del sistema será revisado y trabajado, si la fragmentación es suficientemente alta. Esto presumiblemente sería ejecutado en un programa diario o semanal en horas cuando el uso del sistema sea bajo.
Ningún límite está establecido en este procedimiento almacenado. Como resultado, podría consumir cualquier cantidad de espacio de registro, correr por 18 horas, o causar una contención no deseada. Dado que corre en horas de bajo consumo, es probable que estemos dormidos y no podamos responder rápidamente a un problema cuando ocurre. Con el miedo de estas situaciones inculcado, consideremos algunas maneras de prevenirlas antes de que puedan manifestarse por sí mismas.
Consumo excesivo de espacio de registro
La primera situación a atender es el uso del registro. Las operaciones de índice son registradas y pueden generar un crecimiento significativo del registro que podría potencialmente llenar el disco si se deja descuidado. Dado que iteramos a través de los índices uno por uno, tenemos el lujo de tomar un momento antes de cada uno para verificar el espacio en disco y ver que estemos listos para seguir adelante. Revisando el espacio de disco disponible así como el tamaño del índice a ser trabajado, podemos asegurarnos de que dejamos exactamente tanto espacio libro como queremos.
Introducida en SQL Server 2008R2 SP1, la vista de administración dinámica sys.dm_os_volue_stats, toma parámetros para un ID de base de datos y un ID de archivo, retornando el espacio en disco total y disponible en dispositivo respectivo para ese archivo. Podemos usar eso aquí para revisar cuándo espacio queda previamente a una operación de índice evaluando el siguiente TSQL:
|
1 2 3 4 5 6 |
SELECT CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) AS gb_free FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) WHERE f.database_id = DB_ID() AND f.type_desc = 'LOG'; |
Esto retorna el espacio libre en el dispositivo de registros, en gigabytes. Nuestro siguiente paso es añadir un tamaño de índice al procedimiento almacenado anterior y comparar los dos para determinar si existe suficiente espacio para soportar la operación. Para este ejemplo, asumiremos que debemos mantener 100GB libres en el disco de registros en todo momento, por lo tanto cualquier operación de índice que haría que el espacio libre baje hasta más allá de esa cantidad no debería ocurrir. El procedimiento almacenado resultante, mostrado a continuación, muestra cómo podemos protegernos contra el llenado del disco cuando estemos reconstruyendo índices:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'index_maintenance_daily') BEGIN DROP PROCEDURE dbo.index_maintenance_daily; END GO CREATE PROCEDURE dbo.index_maintenance_daily @reorganization_percentage TINYINT = 10, @rebuild_percentage TINYINT = 35, @log_space_free_required_gb INT = 100 AS BEGIN SET NOCOUNT ON; DECLARE @sql_command NVARCHAR(MAX) = ''; DECLARE @parameter_list NVARCHAR(MAX) = '@reorganization_percentage TINYINT, @rebuild_percentage TINYINT' DECLARE @database_list TABLE (database_name NVARCHAR(MAX) NOT NULL); INSERT INTO @database_list (database_name) SELECT name FROM sys.databases WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model'); CREATE TABLE #index_maintenance ( database_name NVARCHAR(MAX), schema_name NVARCHAR(MAX), object_name NVARCHAR(MAX), index_name NVARCHAR(MAX), index_type_desc NVARCHAR(MAX), avg_fragmentation_in_percent FLOAT, index_operation NVARCHAR(MAX), size_in_GB BIGINT); SELECT @sql_command = @sql_command + ' USE [' + database_name + '] INSERT INTO #index_maintenance (database_name, schema_name, object_name, index_name, index_type_desc, avg_fragmentation_in_percent, index_operation,size_in_GB) SELECT CAST(SD.name AS NVARCHAR(MAX)) AS database_name, CAST(SS.name AS NVARCHAR(MAX)) AS schema_name, CAST(SO.name AS NVARCHAR(MAX)) AS object_name, CAST(SI.name AS NVARCHAR(MAX)) AS index_name, IPS.index_type_desc, IPS.avg_fragmentation_in_percent, -- Be sure to filter as much as possible...this can return a lot of data if you dont filter by database and table. CAST(CASE WHEN IPS.avg_fragmentation_in_percent >= @rebuild_percentage THEN ''REBUILD'' WHEN IPS.avg_fragmentation_in_percent >= @reorganization_percentage THEN ''REORGANIZE'' END AS NVARCHAR(MAX)) AS index_operation, (page_count * 8 / 1024 / 1024) AS size_in_GB FROM sys.dm_db_index_physical_stats(NULL, NULL, NULL, NULL , NULL) IPS INNER JOIN sys.databases SD ON SD.database_id = IPS.database_id INNER JOIN sys.indexes SI ON SI.index_id = IPS.index_id INNER JOIN sys.objects SO ON SO.object_id = SI.object_id AND IPS.object_id = SO.object_id INNER JOIN sys.schemas SS ON SS.schema_id = SO.schema_id WHERE alloc_unit_type_desc = ''IN_ROW_DATA'' AND index_level = 0 AND SD.name = ''' + database_name + ''' AND IPS.avg_fragmentation_in_percent >= @reorganization_percentage AND SI.name IS NOT NULL -- Only review index, not heap data. AND SO.is_ms_shipped = 0 -- Do not perform maintenance on system objects ORDER BY SD.name ASC;' FROM @database_list WHERE database_name IN (SELECT name FROM sys.databases); EXEC sp_executesql @sql_command, @parameter_list, @reorganization_percentage, @rebuild_percentage; SELECT @sql_command = 'DECLARE @log_drive_space_free_gb INT; DECLARE @error_message VARCHAR(MAX);'; SELECT @sql_command = @sql_command + ' USE [' + database_name + ']; SELECT @log_drive_space_free_gb = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) WHERE f.database_id = DB_ID() AND f.type_desc = ''LOG''; SELECT @error_message = ''Not enough space available to process maintenance on ' + index_name + ' while executing the nightly index maintenance job. '' + CAST(@log_drive_space_free_gb AS VARCHAR(MAX)) + ''GB are currently free.'' IF @log_drive_space_free_gb - ' + CAST(size_in_GB AS VARCHAR(MAX)) + ' < @log_space_free_required_gb BEGIN RAISERROR(@error_message, 16, 1); RETURN; END ALTER INDEX [' + index_name + '] ON [' + schema_name + '].[' + object_name + '] ' + index_operation + ';' FROM #index_maintenance; SELECT @parameter_list = '@log_space_free_required_gb INT' SELECT * FROM #index_maintenance ORDER BY avg_fragmentation_in_percent; EXEC sp_executesql @sql_command, @parameter_list, @log_space_free_required_gb; DROP TABLE #index_maintenance; END |
La versión actualizada de este procedimiento almacenado verifica el tamaño del índice a reconstruir, la cantidad de espacio libre en el disco de registros y nuestro espacio libre requerido. Con esa información, determina si deberíamos proceder o salir inmediatamente del procedimiento almacenado sin tomar acciones en ningún otro índice posterior. Si esto pasa, recibimos un mensaje de error como este:
Msg 50000, Level 16, State 1, Line 126
Not enough space available to process maintenance on PK_ProductCostHistory_ProductID_StartDate while executing the nightly index maintenance job. 97GB are currently free.
Más información puede ser añadida al mensaje de error para asistir en la solución de problemas, o atender necesidades específicas en su ambiente. El resultado clave fue que el procedimiento almacenado inmediatamente lanzó un error y salió, parando cualquier crecimiento posterior del registro y previniendo una molesta llamada en la noche.
Tiempos largos de corrida de trabajos
La sincronización de los trabajos de mantenimiento es importante. Queremos que esos trabajos corran durante las horas cuando el uso de cargas de trabajo de producción y otros procedimientos de mantenimiento son mínimos. También queremos que esos trabajos finalicen antes de que nuestras horas más ocupadas comiencen. Para este ejemplo, asumamos que queremos que un trabajo particular inicie a la 1am y finalice no más tarde que 7am. Hay dos maneras de enfocar este desafío:
- Proactivamente: Añadir un TSQL al procedimiento de mantenimiento, similar al anterior, que finalizará si un cierto tiempo es excedido.
- Reactivamente:Añadir un trabajo paralelo que monitorea activamente trabajos de mantenimiento, finalizándolos si corren por mucho tiempo (o si cualquier otra condición inaceptable emerge).
Podemos fácilmente justificar ambas opciones. La solución proactiva finaliza grácilmente el trabajo cuando pasa de las 7am, pero no es infalible. Si un índice específico toma un tiempo inusualmente largo, entonces el trabajo continuaría hasta que el índice se haya completado. Sólo entonces el trabajo terminaría, evitando que los índices restantes sean reconstruidos.
La solución de monitoreo activo puede parar un trabajo en cualquier momento, sin importar su progreso. Este trabajo sería algo a mantener a través del tiempo y asegurarse de que funciona correctamente—–si fuera a finalizar accidentalmente un trabajo importante en el momento incorrecto, el costo de ese error podría ser alto. También, los trabajos parados por este proceso necesitarían ser tolerantes para parar en cualquier punto. Un proceso de archivar o ETL que es interrumpido a la mitad podría inadvertidamente dejar datos inconsistentes atrás, a menos que estuviera diseñado para ser robusto y prevenir que esa situación emerja.
La solución proactiva es similar a nuestro TSQL de crecimiento de registros en el ejemplo anterior. Previo a cada operación de índice, queremos revisar ya sea el tiempo de corrida del trabajo o el tiempo actual y tomar acción basados en eso. Para este ejemplo, haremos ambos, verificando que el tiempo no está entre 7am y 1am, y que el procedimiento almacenado en sí mismo no ha corrido por más de 6 horas.
La siguiente sentencia TSQL verifica el tiempo actual y retornará desde el procedimiento almacenado actual si el tiempo ya no está dentro del periodo de mantenimiento asignado:
|
1 2 3 4 5 6 |
DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME); IF @current_time > '07:00:00' OR @current_time < '01:00:00' BEGIN PRINT 'This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: ' + CAST(@current_time AS VARCHAR(MAX)) RETURN END |
Las variables pueden ser añadidas para tomar el lugar de los tiempos de modo que puedan ser pasadas como parámetros desde un trabajo. Actualmente es casi las 7pm hora local, así que correr este TSQL proveerá la salida esperada:
This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: 18:59:08.3230000
Alternativamente, de ser las 3am, correr el anterior TSQL hubiera resultado en ninguna salida ya que estaríamos dentro de los márgenes establecidos por nuestras reglas de mantenimiento/negocio.
Revisar el tiempo de corrida del trabajo es también relativamente simple, y puede ser hecho con un sello de tiempo artificial. Revisaremos y verificaremos que el tiempo actual no es más de seis horas más grande que el tiempo de inicio del trabajo como sigue:
|
1 2 3 4 5 6 7 8 |
DECLARE @job_start_time DATETIME = CURRENT_TIMESTAMP; --...Insert maintenance TSQL here DECLARE @current_time DATETIME = CURRENT_TIMESTAMP; IF DATEDIFF(HOUR, @job_start_time, @current_time) >= 6 BEGIN PRINT 'This job has exceeded the maximum runtime allowed (6 hours). Start time: ' + CAST(@job_start_time AS VARCHAR(MAX)) + ' Current Time: ' + CAST(@current_time AS VARCHAR(MAX)); RETURN END |
El tiempo de inicio es registrado tan pronto el procedimiento almacenado comienza. Cuando sea que deseemos revisar el tiempo actual de corrida, podemos hacerlo con la consulta anterior. En el evento que más de seis horas hayan pasado, la verificación DATEDIFF retornará verdadero y un mensaje será impreso y el procedimiento almacenado finalizará.
RAISERROR puede ser usado si usted quisiera que su trabajo lance un mensaje de error a los registros de errores (y fallar notoriamente). Alternativamente, si usted tiene un registro de errores personalizado para información de trabajos detallada, los mensajes y detalles anteriores pueden ser enviados también. Las alternativas a RAISERROR para el escenario de revisión de la hora anteriormente mostrado se ven así:
|
1 2 3 4 5 6 7 8 |
DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME); DECLARE @message VARCHAR(MAX); IF @current_time > '07:00:00' OR @current_time < '01:00:00' BEGIN SELECT @message = 'This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: ' + CAST(@current_time AS VARCHAR(MAX)); RAISERROR(@message, 16, 1); RETURN; END |
De manera similar, la revisión de la duración puede ser escrita para lanzar un error también:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @job_start_time DATETIME = CURRENT_TIMESTAMP; DECLARE @message VARCHAR(MAX); --...Insert maintenance TSQL here DECLARE @current_time DATETIME = CURRENT_TIMESTAMP; IF DATEDIFF(HOUR, @job_start_time, @current_time) >= 6 BEGIN SELECT @message = 'This job has exceeded the maximum runtime allowed (6 hours). Start time: ' + CAST(@job_start_time AS VARCHAR(MAX)) + ' Current Time: ' + CAST(@current_time AS VARCHAR(MAX)); RAISERROR(@message, 16, 1); RETURN END |
El error resultante se vería así:
Msg 50000, Level 16, State 1, Line 250
This job has exceeded the maximum runtime allowed (6 hours). Start time: Jan 13 2016 7:14PM Current Time: Jan 13 2016 7:14PM
Una manera alternativa (aunque más compleja) para adquirir una información similar sería consultar msdb por datos de trabajos, asumiendo que su TSQL está corriendo dentro de un trabajo. Esta información es almacenada en un par de tablas de sistema que pueden ser combinadas:
|
1 2 3 4 5 6 |
SELECT sysjobs.name, sysjobactivity.* FROM msdb.dbo.sysjobactivity INNER JOIN msdb.dbo.sysjobs ON sysjobactivity.job_id = sysjobs.job_id |
Esto retorna el historial de corridas de todos los trabajos, una muestra de lo cual se ve así:

Desde estos datos nosotros podemos revisar el trabajo actual por nombre, la instancia más actual de la cual tiene un start_execution_date poblado, pero no stop_execution_date. Manipular estos datos es un poco más complejo que revisar el tiempo o la duración como demostramos previamente, pero podría ser deseable cuando los tiempos de corrida son esporádicos, o las reglas de negocios varían con cada corrida separada.
Estas opciones pueden ser fácilmente insertadas en procedimiento almacenado de mantenimiento de índice mostrado anteriormente. El resultado tendrá protección integrada contra el crecimiento del registro y tiempos de corrida inaceptables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'index_maintenance_daily') BEGIN DROP PROCEDURE dbo.index_maintenance_daily; END GO CREATE PROCEDURE dbo.index_maintenance_daily @reorganization_percentage TINYINT = 10, @rebuild_percentage TINYINT = 35, @log_space_free_required_gb INT = 100 AS BEGIN SET NOCOUNT ON; DECLARE @job_start_time DATETIME = CURRENT_TIMESTAMP; DECLARE @sql_command NVARCHAR(MAX) = ''; DECLARE @parameter_list NVARCHAR(MAX) = '@reorganization_percentage TINYINT, @rebuild_percentage TINYINT' DECLARE @database_list TABLE (database_name NVARCHAR(MAX) NOT NULL); INSERT INTO @database_list (database_name) SELECT name FROM sys.databases WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model'); CREATE TABLE #index_maintenance ( database_name NVARCHAR(MAX), schema_name NVARCHAR(MAX), object_name NVARCHAR(MAX), index_name NVARCHAR(MAX), index_type_desc NVARCHAR(MAX), avg_fragmentation_in_percent FLOAT, index_operation NVARCHAR(MAX), size_in_GB BIGINT); SELECT @sql_command = @sql_command + ' USE [' + database_name + '] INSERT INTO #index_maintenance (database_name, schema_name, object_name, index_name, index_type_desc, avg_fragmentation_in_percent, index_operation,size_in_GB) SELECT CAST(SD.name AS NVARCHAR(MAX)) AS database_name, CAST(SS.name AS NVARCHAR(MAX)) AS schema_name, CAST(SO.name AS NVARCHAR(MAX)) AS object_name, CAST(SI.name AS NVARCHAR(MAX)) AS index_name, IPS.index_type_desc, IPS.avg_fragmentation_in_percent, -- Be sure to filter as much as possible...this can return a lot of data if you dont filter by database and table. CAST(CASE WHEN IPS.avg_fragmentation_in_percent >= @rebuild_percentage THEN ''REBUILD'' WHEN IPS.avg_fragmentation_in_percent >= @reorganization_percentage THEN ''REORGANIZE'' END AS NVARCHAR(MAX)) AS index_operation, (page_count * 8 / 1024 / 1024) AS size_in_GB FROM sys.dm_db_index_physical_stats(NULL, NULL, NULL, NULL , NULL) IPS INNER JOIN sys.databases SD ON SD.database_id = IPS.database_id INNER JOIN sys.indexes SI ON SI.index_id = IPS.index_id INNER JOIN sys.objects SO ON SO.object_id = SI.object_id AND IPS.object_id = SO.object_id INNER JOIN sys.schemas SS ON SS.schema_id = SO.schema_id WHERE alloc_unit_type_desc = ''IN_ROW_DATA'' AND index_level = 0 AND SD.name = ''' + database_name + ''' AND IPS.avg_fragmentation_in_percent >= @reorganization_percentage AND SI.name IS NOT NULL -- Only review index, not heap data. AND SO.is_ms_shipped = 0 -- Do not perform maintenance on system objects ORDER BY SD.name ASC;' FROM @database_list WHERE database_name IN (SELECT name FROM sys.databases); EXEC sp_executesql @sql_command, @parameter_list, @reorganization_percentage, @rebuild_percentage; SELECT @sql_command = 'DECLARE @log_drive_space_free_gb INT; DECLARE @error_message VARCHAR(MAX); DECLARE @current_time TIME;'; SELECT @sql_command = @sql_command + ' USE [' + database_name + ']; SELECT @log_drive_space_free_gb = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) WHERE f.database_id = DB_ID() AND f.type_desc = ''LOG''; SELECT @error_message = ''Not enough space available to process maintenance on ' + index_name + ' while executing the nightly index maintenance job. '' + CAST(@log_drive_space_free_gb AS VARCHAR(MAX)) + ''GB are currently free.'' IF @log_drive_space_free_gb - ' + CAST(size_in_GB AS VARCHAR(MAX)) + ' < @log_space_free_required_gb BEGIN RAISERROR(@error_message, 16, 1); RETURN; END IF DATEDIFF(HOUR, ''' + CAST(@job_start_time AS VARCHAR(MAX)) + ''', @current_time) >= 6 BEGIN SELECT @error_message = ''This job has exceeded the maximum runtime allowed (6 hours). Start time: ''''' + CAST(@job_start_time AS VARCHAR(MAX)) + ''''' Current Time: '' + CAST(@current_time AS VARCHAR(MAX)); RAISERROR(@error_message, 16, 1); RETURN END SELECT @current_time = CAST(CURRENT_TIMESTAMP AS TIME); IF @current_time > ''07:00:00'' OR @current_time < ''01:00:00'' BEGIN SELECT @error_message = ''This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: '' + CAST(@current_time AS VARCHAR(MAX)); RAISERROR(@error_message, 16, 1); RETURN END ALTER INDEX [' + index_name + '] ON [' + schema_name + '].[' + object_name + '] ' + index_operation + ';' FROM #index_maintenance; SELECT @parameter_list = '@log_space_free_required_gb INT' SELECT * FROM #index_maintenance ORDER BY avg_fragmentation_in_percent; EXEC sp_executesql @sql_command, @parameter_list, @log_space_free_required_gb; DROP TABLE #index_maintenance; END |
Previo a cada operación de reconstrucción/reorganización de índice, después de que el espacio de registros es verificado, la duración del procedimiento almacenado es revisada y luego el momento del día en que está corriendo. Estos procesos de verificación toman una cantidad trivial de tiempo en correr y proveen un gran aseguramiento contra operaciones intensivas en el consumo de recursos corriendo en horas de operación de producción críticas.
Un enfoque alternativo integrado es el trabajo paralelo, el cual corre periódicamente y revisa que nuestros trabajos de mantenimiento estén operando dentro de los parámetros. Si cualquier situación inaceptable es detectada, el trabajo responsable puede ser forzado a terminar. Esto es muy útil si el trabajo problemático está trabado en una operación grande y no puede alcanzar uno de los puntos de verificación que creamos en nuestros ejemplos anteriores. Para ilustrar esto, he creado un trabajo que corre el procedimiento almacenado de mantenimiento de índice mencionado anteriormente:
Desde aquí, construiremos el TSQL para un trabajo de verificación que correrá cada 30 segundos y finalizará el trabajo de mantenimiento de índice si está corriendo y cualquier condición inaceptable existe (como poco espacio para registros o un tiempo de corrida largo). El siguiente procedimiento almacenado encapsulará toda la lógica presentada anteriormente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'job_verification') BEGIN DROP PROCEDURE dbo.job_verification; END GO CREATE PROCEDURE dbo.job_verification @log_space_free_required_gb INT = 100, @job_to_check VARCHAR(MAX) = 'Index Maintenance!' AS BEGIN SET NOCOUNT ON; DECLARE @log_drive_space_free_gb INT; DECLARE @job_start_time DATETIME; DECLARE @error_message VARCHAR(MAX); DECLARE @current_time TIME; DECLARE @sql_command VARCHAR(MAX); DECLARE @stop_job BIT = 0; -- This will be switched to 1 if any job-ending criteria is met SELECT -- Get free log space @log_drive_space_free_gb = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) WHERE f.database_id = DB_ID() AND f.type_desc = 'LOG'; -- If current free log space is below our allowed threshold, proceed to check if maintenance job is running IF @log_drive_space_free_gb < @log_space_free_required_gb BEGIN SELECT @error_message = 'Not enough space available to process maintenance while executing the nightly index maintenance job. ' + CAST(@log_drive_space_free_gb AS VARCHAR(MAX)) + 'GB are currently free.'; SELECT @stop_job = 1; END -- Get the start time for the index maintenance job, if it is running. SELECT @job_start_time = sysjobactivity.start_execution_date FROM msdb.dbo.sysjobs_view INNER JOIN msdb.dbo.sysjobactivity ON sysjobs_view.job_id = sysjobactivity.job_id WHERE sysjobs_view.name = @job_to_check AND sysjobactivity.run_Requested_date IS NOT NULL AND sysjobactivity.stop_execution_date IS NULL AND sysjobactivity.session_id = (SELECT MAX(session_id) FROM msdb.dbo.sysjobs_view INNER JOIN msdb.dbo.sysjobactivity ON sysjobs_view.job_id = sysjobactivity.job_id WHERE sysjobs_view.name = @job_to_check) -- If the job has been running for more than six hours, then set the error message and flag it to be ended. IF (DATEDIFF(HOUR, @job_start_time, @current_time) >= 6) AND @job_start_time IS NOT NULL BEGIN SELECT @error_message = 'This job has exceeded the maximum runtime allowed (6 hours). Start time: ' + CAST(@job_start_time AS VARCHAR(MAX)) + ' Current Time: ' + CAST(CURRENT_TIMESTAMP AS VARCHAR(MAX)); SELECT @stop_job = 1; END SELECT @current_time = CAST(CURRENT_TIMESTAMP AS TIME); IF @current_time > '07:00:00' OR @current_time < '01:00:00' BEGIN SELECT @error_message = 'This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: ' + CAST(@current_time AS VARCHAR(MAX)); SELECT @stop_job = 1; END -- Verify that the maintenance job is running first, before attempting to stop it (If a condition above was met first). IF @stop_job = 1 AND EXISTS ( SELECT * FROM msdb.dbo.sysjobs_view INNER JOIN msdb.dbo.sysjobactivity ON sysjobs_view.job_id = sysjobactivity.job_id WHERE sysjobs_view.name = @job_to_check AND sysjobactivity.run_Requested_date IS NOT NULL AND sysjobactivity.stop_execution_date IS NULL AND sysjobactivity.session_id = (SELECT MAX(session_id) FROM msdb.dbo.sysjobs_view INNER JOIN msdb.dbo.sysjobactivity ON sysjobs_view.job_id = sysjobactivity.job_id WHERE sysjobs_view.name = @job_to_check)) BEGIN -- If job is running, then end it immediately and raise an error with details. EXEC msdb.dbo.sp_stop_job @job_name = @job_to_check; RAISERROR(@error_message, 16, 1); RETURN; END END |
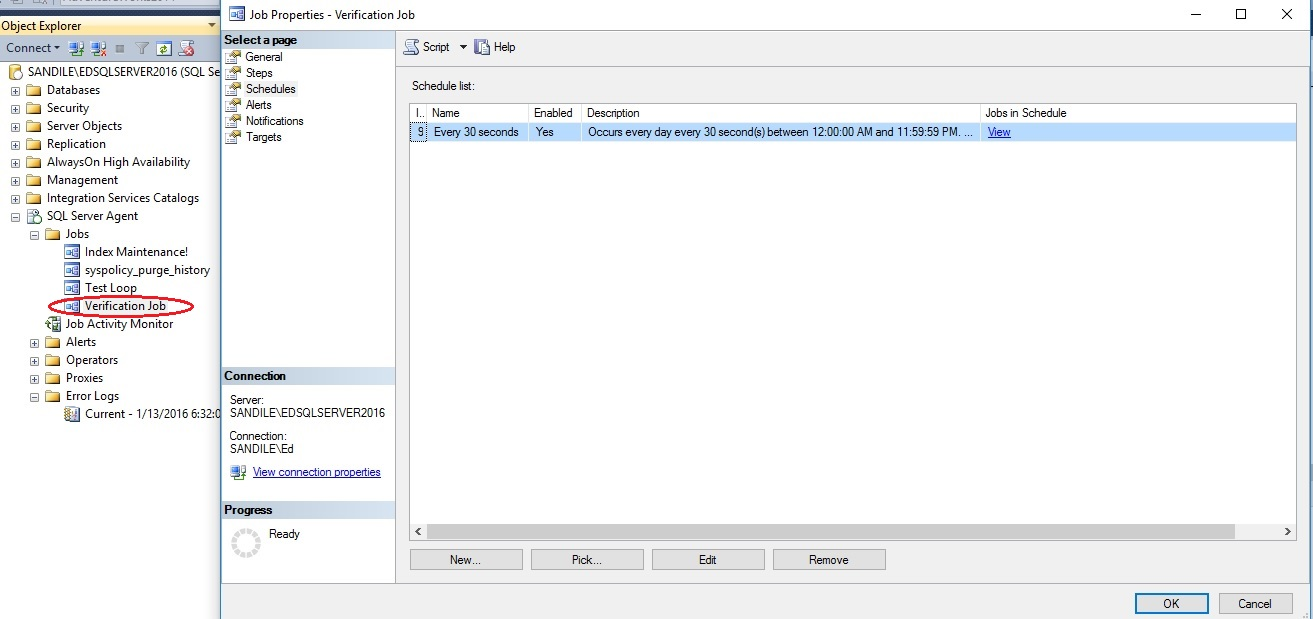
Luego crearemos un trabajo que corre cada 30 segundos y llama al anterior procedimiento almacenado:
Una mirada al historial de trabajos mostrará el primer puñado de trabajos exitosamente ejecutados:
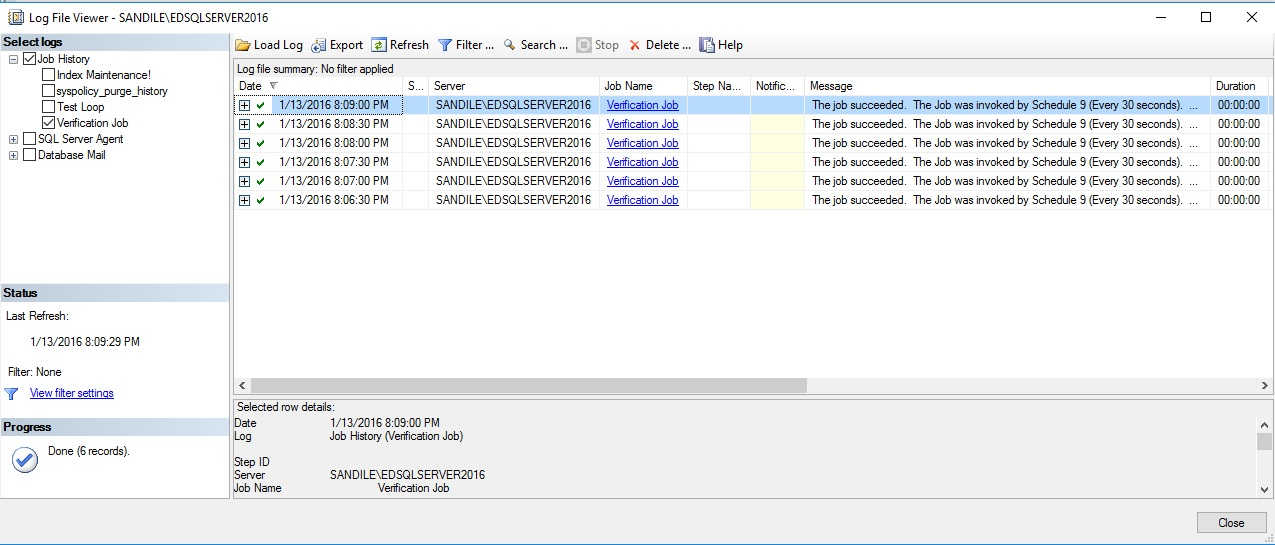
Como se esperaba, este proceso de verificación no necesita ni siquiera un segundo para completarse, dado que sólo está verificando el disco y los metadatos de los trabajos y puede hacerlo de manera rápida y eficiente. Digamos que yo estaba a punto de iniciar mi trabajo de mantenimiento de índice y revisarlo de nuevo en 30 segundos:
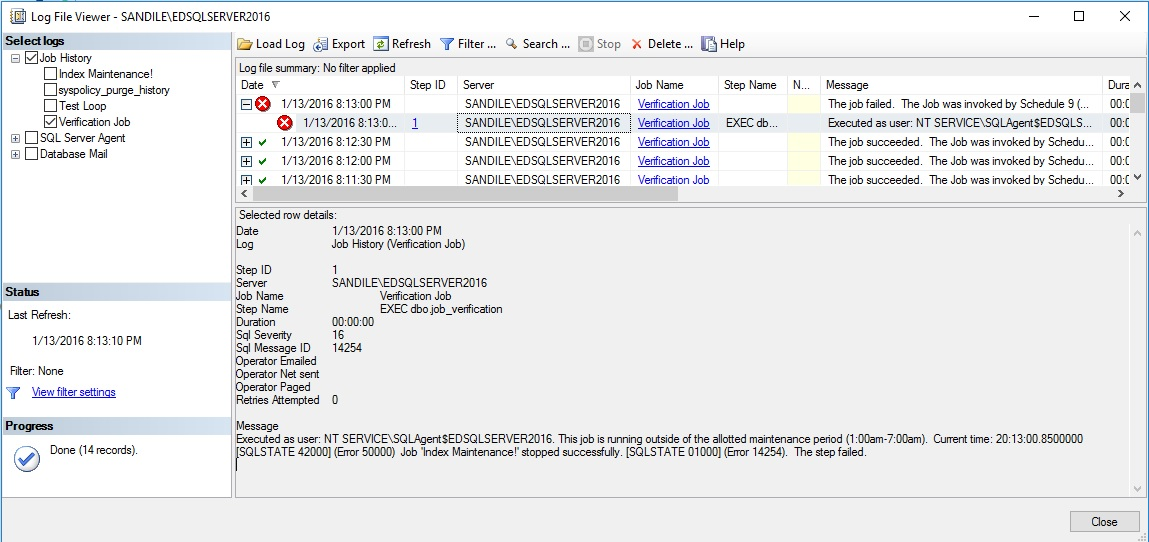
trabajo de verificación ve que el trabajo de mantenimiento de índice no debería estar corriendo y usa msdb.dbo.sp_stop_job para terminarlo inmediatamente. En adición a esto, el mensaje de error lanzado dentro del trabajo de verificación es visible desde dentro del historial de trabajos, recordándonos que el trabajo está corriendo fuera del periodo de mantenimiento asignado.
Esta técnica puede ser expandida tanto como pueda imaginar. Un trabajo sustituto como este puede ser usado para monitorear cualquier condición en SQL Server y tomar la acción apropiada inmediatamente. Adicionalmente a simplemente terminar trabajos o escribir errores al registro de errores de SQL Server, podríamos también tomar acciones como:
- Enviar un correo electrónico a un DBA, desarrollador o a un operador en llamada (si es un problema serio).
- El destino del correo electrónico podría variar dependiendo del error. Por ejemplo, un error de espacio de disco podría también enviar un correo electrónico al administrador SAN, mientras que un error TSQL sólo enviaría un correo al DBA responsable.
- Deshabilitar un trabajo que corre frecuentemente, alertando al DBA de que el asunto requerirá atención tan pronto como sea posible.
- Realizar una copian de seguridad del registro y/o reducción del archivo, si las condiciones existen donde estas operaciones puedan ser necesarias.
- Escribir datos adicionales a Windows Application Event Log.
- Ejecutar otro procedimiento almacenado o trabajo que asista en remediar la situación encontrada.
La flexibilidad introducida aquí es inmensa y puede evitar que los problemas de producción críticos se presenten alguna vez. Si usted decide intentarlo, asegúrese de ser creativo y hacer que el proceso de verificación maneje todas las tareas manuales en las que usted está típicamente estancado cuando estas situaciones emergen. Use esto no sólo para prevenir desastres, sino también para simplificar su trabajo y mitigar procesos manuales proclives a error.
¡Un correo electrónico a las 9am que le hace saber de problemas de mantenimiento de índice inesperados durante la noche anterior es 100% preferible a una llamada a las 2:00am cuando un disco se queda sin espacio y SQL Server no puede escribir en sus archivos de registros de transacciones!
Espacio de disco para copias de seguridad
Las copias de seguridad por naturaleza van a resultar en que el espacio del disco sea comido cuando estén en ejecución. La mayoría de las rutas de copias de seguridad que construimos involucran copias de seguridad completas (una o quizá dos veces a la semana), copias de seguridad diferenciales (diariamente en días en que no se toman copias completas) y/o copias de seguridad de los registros de transacciones, los cuales corren frecuentemente y respaldan cambios desde la última copia de seguridad del registro. A pesar de las especificidades en su ambiente, hay algunas generalizaciones que podemos hacer:
- Los datos crecerán a lo largo del tiempo, y por lo tanto las copias de seguridad incrementarán su tamaño.
- Cualquier cosa que cause cambios significativos en los datos también causará que el tamaño de las copias de seguridad de registros de transacciones aumenten.
- Si un objetivo de copia de seguridad es compartido con otras aplicaciones, entonces ella podrían potencialmente interferir o usar el espacio.
- Mientras más tiempo haya pasado desde la última copia de seguridad diferencial/de registro de transacciones, estas serán más grandes y tomarán más tiempo.
- Si una limpieza del dispositivo de copias de seguridad objetivo no ocurre regularmente, eventualmente se llenará, causando fallas.
Cada una de estas situaciones se presta a posibles soluciones, como no compartir el dispositivo de copias de seguridad con otros programas, o probar el crecimiento del registro en scripts de lanzamiento previos al lanzamiento final en producción. Mientras que podemos mitigar el riesgo, siempre existe la posibilidad de que los dispositivos se llenen. Si lo hacen, todas las copias de seguridad posteriores fallarán, dejando agujeros en el registro de copias de seguridad que podrían resultar en detrimento en el evento de un desastre o una solicitud de datos de respaldo.
Como con el espacio para registros, podemos monitorear el tamaño de las copias de seguridad y el uso para tomar decisiones inteligentes acerca de cómo debería proceder un trabajo. Esto puede ser administrado desde dentro de un procedimiento almacenado de respaldo usando xp_cmdshell, si el uso de ese procedimiento almacenado de sistema es tolerado. Alternativamente, Powershell también puede ser usado para monitorear el espacio en el dispositivo. Una solución alternativa que particularmente me gusta es crear una base de datos mínimamente usada en el servidor que está respaldando y poner los datos y archivos de registros en el dispositivo de respaldo. Esto le permite usar dm_os_volume_stats para monitorear el uso del disco directamente dentro del proceso de copia de seguridad sin ningún compromiso de seguridad.
Para un ejemplo de esta solución, usaremos mi disco local C como el dispositivo de respaldo y el disco F como el objetivo para todos los otros archivos de datos de la base de datos. Dado que nuestros archivos de datos están en el disco F, podemos fácilmente ver el espacio disponible así:
|
1 2 3 4 5 6 |
SELECT CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) AS gb_free FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) WHERE f.database_id = DB_ID() AND f.type_desc = 'ROWS'; |
Esto retorna el espacio libre en el dispositivo correspondiente a la base de datos de la que estoy haciendo consultas, en este caso AdventureWorks2014. El resultado es exactamente lo que yo estoy buscando:

Con 14.5TB libres, vamos a estar en buena forma por un buen tiempo. ¿Qué hay del dispositivo de respaldo? Si queremos usar xp_cmdshell, podemos recolectar esa información bastante fácil:
|
1 2 3 4 5 6 7 8 |
DECLARE @results TABLE (output_data NVARCHAR(MAX)); INSERT INTO @results (output_data) EXEC xp_cmdshell 'DIR C:'; SELECT * FROM @results WHERE output_data LIKE '%bytes free%'; |
El resultado de esta consulta es una sola fila con el número de directorios y bytes libres:

Desafortunadamente, xp_cmdshell es un agujero de seguridad, permitiendo acceso directo al Sistema Operativo desde SQL Server. Mientras que algunos ambientes puede tolerar su uso, muchos no. Como resultado, presentemos una alternativa que puede sentirse un poco como trampa al principio, pero provee una mejor visión del espacio del disco sin la necesidad de habilitar características adicionales:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE DATABASE DBTest ON ( NAME = DBTest_Data, FILENAME = 'C:\SQLData\DBTest.mdf', SIZE = 10MB, MAXSIZE = 10MB, FILEGROWTH = 10MB) LOG ON ( NAME = DBTest_Log, FILENAME = 'C:\SQLData\DBTest.ldf', SIZE = 5MB, MAXSIZE = 5MB, FILEGROWTH = 5MB); |
Esto crea una base de datos llamada DBTest en mi disco C con datos y archivos de registro de tamaño relativamente pequeño. Si planea crear una base de datos más legítima a ser usada por cualquier proceso actual, ajuste el tamaño de los archivos y los ajustes de auto crecimiento como necesite. Con una base de datos en este disco, podemos correr la consulta DMV que vimos más atrás y obtener el espacio libre en este disco:
|
1 2 3 4 5 6 7 |
USE DBTest; SELECT CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) AS gb_free FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) WHERE f.database_id = DB_ID() AND f.type_desc = 'ROWS'; |
El resultado es exactamente lo que estábamos buscando más antes, sin necesidad de ningún comando al nivel del Sistema Operativo vía xp_cmdshell o Powershell:
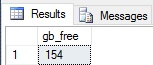
Actualmente tengo 154GB libres, y el único costo de estos datos fue la creación de una pequeña base de datos en el disco de respaldo. Con esta herramienta a mano, podemos mirar a un simple procedimiento almacenado de respaldo y añadirle lógica para manejar el espacio mientras está corriendo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
USE AdventureWorks2014; GO IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'full_backup_plan') BEGIN DROP PROCEDURE dbo.full_backup_plan; END GO CREATE PROCEDURE dbo.full_backup_plan @backup_location NVARCHAR(MAX) = 'C:\SQLBackups\' -- Default backup folder AS BEGIN SET NOCOUNT ON; DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME); DECLARE @current_day TINYINT = DATEPART(DW, CURRENT_TIMESTAMP); DECLARE @datetime_string NVARCHAR(MAX) = FORMAT(CURRENT_TIMESTAMP , 'MMddyyyyHHmmss'); DECLARE @sql_command NVARCHAR(MAX) = ''; DECLARE @database_list TABLE (database_name NVARCHAR(MAX) NOT NULL, recovery_model_desc NVARCHAR(MAX)); INSERT INTO @database_list (database_name, recovery_model_desc) SELECT name, recovery_model_desc FROM sys.databases WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model'); SELECT @sql_command = @sql_command + ' BACKUP DATABASE [' + database_name + '] TO DISK = ''' + @backup_location + database_name + '_' + @datetime_string + '.bak''; ' FROM @database_list; PRINT @sql_command; EXEC sp_executesql @sql_command; END |
Este simple procedimiento almacenado realizará una copia de seguridad completa de todas las bases de datos en el servidor, con la excepción de msdb, tempdb, model y master. Lo que queremos hacer es verificar el espacio libre antes de correr las copias de seguridad, similar a lo anterior. Si el espacio es inaceptablemente bajo, finalice el trabajo y notifique a las personas correctas inmediatamente. Manteniendo suficiente espacio en el disco prevenimos que se agote completamente y cause que las copias de seguridad del registro de transacciones fallen. La prueba para el espacio en el disco de respaldo incorpora nuestra consulta dm_os_volume_stats de más antes y asume que debemos mantener 25GB libres en todo tiempo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'full_backup_plan') BEGIN DROP PROCEDURE dbo.full_backup_plan; END GO CREATE PROCEDURE dbo.full_backup_plan @backup_location NVARCHAR(MAX) = 'C:\SQLBackups\', -- Default backup folder @backup_free_space_required_gb INT = 25 -- Default GB allowed on the backup drive AS BEGIN SET NOCOUNT ON; DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME); DECLARE @current_day TINYINT = DATEPART(DW, CURRENT_TIMESTAMP); DECLARE @datetime_string NVARCHAR(MAX) = FORMAT(CURRENT_TIMESTAMP , 'MMddyyyyHHmmss'); DECLARE @sql_command NVARCHAR(MAX) = ''; DECLARE @database_list TABLE (database_name NVARCHAR(MAX) NOT NULL, recovery_model_desc NVARCHAR(MAX)); INSERT INTO @database_list (database_name, recovery_model_desc) SELECT name, recovery_model_desc FROM sys.databases WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model'); SELECT @sql_command = @sql_command + ' DECLARE @backup_drive_space_free BIGINT; DECLARE @current_db_size BIGINT; DECLARE @error_message NVARCHAR(MAX);' SELECT @sql_command = @sql_command + ' USE [DBTest]; SELECT @backup_drive_space_free = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) WHERE f.database_id = DB_ID() AND f.type_desc = ''ROWS''; USE [' + database_name + ']; SELECT @current_db_size = SUM(size) * 8 / 1024 / 1024 FROM sysfiles; IF @backup_drive_space_free - @current_db_size < ' + CAST(@backup_free_space_required_gb AS NVARCHAR(MAX)) + ' BEGIN SELECT @error_message = ''Not enough space available to process backup on ' + database_name + ' while executing the full backup maintenance job. '' + CAST(@backup_drive_space_free AS VARCHAR(MAX)) + ''GB are currently free.''; RAISERROR(@error_message, 16, 1); RETURN; END BACKUP DATABASE [' + database_name + '] TO DISK = ''' + @backup_location + database_name + '_' + @datetime_string + '.bak''; ' FROM @database_list; PRINT @sql_command; EXEC sp_executesql @sql_command; END |
Dentro del SQL dinámico, y previamente a cada copia de seguridad, revisamos el espacio libre actual en el disco de respaldo, el tamaño de la base de datos que estamos por respaldar y comparamos esos valores (en GB) con el espacio libre establecido en los parámetros del procedimiento almacenado. En el evento de que la copia de seguridad que vamos a tomar sea muy grande, un error será lanzado. Podemos, adicionalmente, tomar cualquier número de acciones para alertar a las partes responsables, como correos electrónicos, servicios de buscapersonas y/o registros adicionales.
En el evento de que trate de respaldar una base de datos particularmente grande, el error esperado será lanzado:
Msg 50000, Level 16, State 1, Line 656 Not enough space available to process backup on AdventureWorks2014 while executing the full backup maintenance job. 141GB are currently free.
Dado que las fallas de copias de seguridad son mucho más serias que la reconstrucción de un índice no esté corriendo, desearíamos movernos con cautela y asegurarnos de que las personas indicadas fueron notificadas lo más rápido posible. La solución del trabajo paralelo de más antes podría también ser usada para monitorear trabajos de copias de seguridad y, en el evento de que el espacio libre sea muy bajo, enviar alertas como sea necesario y/o finalizar el trabajo.
Conclusión
Nuestra habilidad de monitorear proactivamente y administrar situaciones potencialmente problemáticas tiene unos pocos límites. Con algo de creatividad, podemos monitorear bloqueos, volumen de IO, espacio de datos usado y más. Cuando sea que un trabajo falla o somos despertados a las 2am por una situación urgente, nuestros primeros pensamientos deberían ser determinar cómo prevenir que esa situación se dé nuevamente. Una combinación de alertas inteligentes y administración proactiva de los trabajos asegurará que nuestro servidor de bases de datos nunca entre a una situación irrecuperable.
Usted probablemente tiene otras herramientas de monitoreo que vigilan una variedad de métricas del Sistema Operativo, el disco y SQL Server. Esto es algo bueno, y tener un monitoreo redundante asegura que una falla en uno no vuelve a todos los datos de alerta irrelevantes. Las soluciones presentadas anteriormente son la punta del iceberg en términos de monitoreo personalizado y respuestas automatizadas y deberían completar esos otros sistemas, no reemplazarlos.
Siempre considere cómo diferentes trabajos interactúan y prográmelos de modos que no se sobreponen en tareas sensibles o intensivas en recursos. Las copias de seguridad, las reconstrucciones de índices, los procesos ETL, actualizar estadísticas, archivar, los lanzamientos de software y los procesos de recolección de datos deberían estar programados de tal manera que no se impactan entre sí y tampoco afectan el proceso normal del negocio. Cuando hay un riesgo de una programación de tiempo pobre, construya mecanismo de atajos que eviten que emerjan situaciones intolerables.
En un universo ideal, siempre detectaríamos problemas de espacio de disco mucho antes de que se vuelvan una amenaza a nuestro proceso del día a día, pero sabemos que el mundo real no funciona así. Las excepciones pasarán, ¡así que esté preparado! Haga que los procesos comunes sean lo suficientemente robustos para resistir aquellas circunstancias inevitables y su trabajo se volverá significativamente más fácil. Como un extra, ¡usted impresionará a sus compañeros de trabajo y jefes con medidas para ahorrar tiempo y dinero!
Referencias y lecturas complementarias
Aquí están unos enlaces a una variedad de material fuente que puede clarificar algunas vistas del sistema, procedimientos almacenados, así como clarificar algunos detalles respecto de las operaciones de respaldo e índices:
Notes on log growth from online index rebuild operations
Use of backup compression to improve backup size and times
sys.dm_os_volume_stats
sp_stop_job
dbo.sysjobhistory

En su tiempo libre, Ed juega video juegos, películas de ciencia ficción y fantásticas, viajar y ser un gran geek al nivel que sus amigos puedan tolerar.
Vea todas las entradas de Ed Pollack
- Técnicas de optimización de consultas en SQL Server: consejos y trucos de aplicación - September 30, 2019
- Todo lo que querías saber sobre SQL Saturday (pero tenías miedo de preguntar) - April 13, 2018
- Cambios del Optimizador de Consultas en SQL Server 2016 explicados - April 21, 2017