
Los índices son usados para acelerar el proceso de consultas en SQL Server, resultando en alto desempeño. Son similares a índices de libros de texto. En los libros de texto, si usted necesita ir a un capítulo en particular, usted va al índice, encuentra el número de página del capítulo y va directamente a esa página. Sin índices, el proceso de encontrar su capítulo deseado habría sido muy lento.
Lo mismo aplica a los índices en bases de datos. Sin índices, un Sistema de Gestión de Bases de Datos (DBMS, por sus siglas en inglés) tiene que recorrer todos los registros en la tabla para recuperar los resultados deseados. Este proceso es llamado escaneo de tablas, y es extremadamente lento. Por otra parte, si usted crea índices, la base de datos va a ese índice primero y luego recupera los correspondientes registros de tabla directamente.
Hay dos tipos de Índices en SQL Server:
- Índices Agrupados
- Índices No Agrupados
Índices Agrupados
Un índice agrupado define el orden en el cual los datos son físicamente almacenados en una tabla. Los datos de las tablas pueden ser ordenados sólo en una forma, por lo tanto, sólo puede haber un índice agrupado por tabla. En SQL Server, la restricción de llave primaria crea automáticamente un índice agrupado en esa columna en particular.
Demos un vistazo. Primero, cree una tabla “student” dentro de “schooldb” ejecutando el siguiente script:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE DATABASE schooldb CREATE TABLE student ( id INT PRIMARY KEY, name VARCHAR(50) NOT NULL, gender VARCHAR(50) NOT NULL, DOB datetime NOT NULL, total_score INT NOT NULL, city VARCHAR(50) NOT NULL ) |
Note aquí que, en la tabla “student”, hemos establecido la restricción de llave primaria en la columna “id”. Esto crea automáticamente un índice agrupado en la columna “id”. Esto crea automáticamente un índice agrupado en la columna “id”. Para ver todos los índices en una tabla particular, ejecute el procedimiento agregado “sp_helpindex”. Este procedimiento almacenado acepta el nombre de la tabla como parámetro y recupera todos los índices de la tabla. La siguiente consulta recupera los índices creados en la tabla “student”.
|
1 2 3 |
USE schooldb EXECUTE sp_helpindex student |
La consulta de arriba retornará este resultado:
| index_name | index_description | index_keys |
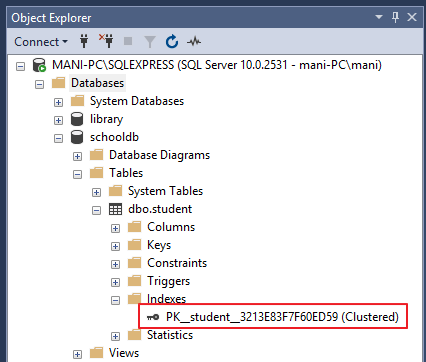
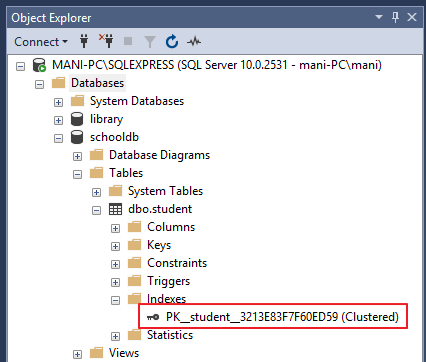
| PK__student__3213E83F7F60ED59 | clustered, unique, primary key located on PRIMARY | id |
En la salida usted puede ver el único índice. Este es el índice que fue automáticamente creado debido a la restricción de llave primaria en la columna “id”.
Otra manera de ver índices de tablas es yendo a “Object Explorer->Databases->Database_Name->Tables->Table_Name -> Indexes”. Vea la siguiente captura de pantalla para referencia.
Este índice agrupado almacena el registro en la tabla “student” en orden ascendente de “id”. Por lo tanto, si el registro insertado tiene el id de 5, el registro será insertado en la 5ª fila de la tabla en lugar de la primera fila. De forma similar, si el cuarto registro tiene un id de 3, será insertado en la tercera fila en lugar de la cuarta fila. Esto se debe a que el índice agrupado tiene que mantener el orden físico de los registros almacenados de acuerdo a la columna indexada, por ejemplo, id. Para ver esta acción de orden, ejecute el siguiente script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
USE schooldb INSERT INTO student VALUES (6, 'Kate', 'Female', '03-JAN-1985', 500, 'Liverpool'), (2, 'Jon', 'Male', '02-FEB-1974', 545, 'Manchester'), (9, 'Wise', 'Male', '11-NOV-1987', 499, 'Manchester'), (3, 'Sara', 'Female', '07-MAR-1988', 600, 'Leeds'), (1, 'Jolly', 'Female', '12-JUN-1989', 500, 'London'), (4, 'Laura', 'Female', '22-DEC-1981', 400, 'Liverpool'), (7, 'Joseph', 'Male', '09-APR-1982', 643, 'London'), (5, 'Alan', 'Male', '29-JUL-1993', 500, 'London'), (8, 'Mice', 'Male', '16-AUG-1974', 543, 'Liverpool'), (10, 'Elis', 'Female', '28-OCT-1990', 400, 'Leeds'); |
El script de arriba inserta diez registros en la tabla student. Note aquí que los registros son insertados en el orden al azar de los valores en la columna “id”. Pero, debido al índice agrupado por defecto en la columna id, los registros son almacenados físicamente en orden ascendiente de los valores en la columna “id”. Ejecute la siguiente sentencia SELECT para recuperar los registros desde la tabla student.
|
1 2 3 |
USE schooldb SELECT * FROM student |
Los registros serán recuperados en el siguiente orden:
| id | name | gender | DOB | total_score | city |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
Creando índices Agrupados Personalizados
Usted puede crear su propio índice personalizado, así como el índice agrupado por defecto. Para crear un nuevo índice agrupado en una tabla, usted debe primero eliminar el índice previo
Para eliminar un índice vaya a “Object Explorer->Databases->Database_Name->Tables->Table_Name -> Indexes”. Haga clic derecho en el índice que desea eliminar y seleccione DELETE. Vea la siguiente captura de pantalla.

Ahora, para crear un nuevo índice agrupado, ejecute el siguiente script:
|
1 2 3 4 |
use schooldb CREATE CLUSTERED INDEX IX_tblStudent_Gender_Score ON student(gender ASC, total_score DESC) |
El proceso de crear un índice agrupado es similar a un índice normal con una excepción. Con un índice agrupado, usted tiene que usar la palabra reservada “CLUSTERED” antes de “INDEX”.
El script de arriba crea un índice llamado “IX_tblStudent_Gender_Score” en la tabla student. Este índice es creado en las columnas “gender” y “total_score”. Un índice que es creado en más que una columna es llamado “índice compuesto”.
El índice de arriba primero ordena todos los registros en orden ascendente de gender. Si gender es lo mismo para dos o más registros, los registros son ordenados en orden descendiente de los valores en su columna “total_score”. Usted puede crear un índice agrupado en una sola columna también. Ahora, si usted selecciona todos los registros desde la tabla student, ellos serán recuperados en el siguiente orden:
| id | name | gender | DOB | total_score | city |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
Índices no Agrupados
Un índice no agrupado no ordena los datos físicos dentro de la tabla. De hecho, un índice no agrupado es agrupado en un solo lugar y los datos de la tabla son almacenados en otro lugar. Esto es similar a un libro de texto donde el contenido del libro está localizado en un lugar y el índice está localizado en otro. Esto permite tener más de un índice no agrupado por tabla.
Es importante mencionar que dentro de la tabla los datos serán ordenados por un índice agrupado. De todos modos, por dentro los datos del índice no agrupado son almacenados en un orden específico. El índice contiene valores de columna en los cuales el índice es creado y la dirección del registro a la que el valor de la columna pertenece.
Cuando una consulta es lanzada contra una columna en la cual el índice es creado, la base de datos primero irá al índice y buscará la dirección de la fila correspondiente en la tabla. Luego, irá a esa dirección de fila y obtendrá otros valores de columna. Es debido a este paso adicional que los índices no agrupados son más lentos que los índices agrupados.
Creando un Índice No Agrupado
La sintaxis para crear un Índice no agrupado es similar a la del índice agrupado. De todos modos, en el caso de los índices no agrupados, la palabra reservada “NONCLUSTERED” es usada en lugar de “CLUSTERED”. Revise el siguiente script.
|
1 2 3 4 |
use schooldb CREATE NONCLUSTERED INDEX IX_tblStudent_Name ON student(name ASC) |
El siguiente script crea un índice no agrupado en la columna “name” de la tabla student. El índice ordena por name en orden ascendente. Como dijimos anteriormente, los datos de la tabla e índice serán almacenados en lugares diferentes. Los registros de la tabla serán ordenados por un índice agrupado si hay uno. El índice será ordenado de acuerdo a su definición y será almacenado separadamente desde la tabla.
Datos de la Tabla Student:
| id | name | gender | DOB | total_score | City |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
Datos del ÍndiceIX_tblStudent_Name
| name | Row Address |
| Alan | Row Address |
| Elis | Row Address |
| Jolly | Row Address |
| Jon | Row Address |
| Joseph | Row Address |
| Kate | Row Address |
| Laura | Row Address |
| Mice | Row Address |
| Sara | Row Address |
| Wise | Row Address |
Note, aquí en el índice cada fila tiene una columna que almacena la dirección de la fila a la cual el nombre pertenece. Así que, si una consulta es lanzada para recuperar gender y DOB de un estudiante llamado “Jon”, la base de datos primero buscará el nombre “Jon” dentro del índice. Luego leerá la dirección de la fila de “Jon” e irá directamente a esa fila en la tabla “student” para recuperar gender y DOB de Jon.
Conclusión
De la discusión encontramos las siguientes diferencias entre índices agrupados y no agrupados.
- Puede haber sólo un índice agrupado por tabla. De todos modos, usted puede crear múltiples índices no agrupados en una sola tabla.
- Los índices agrupados sólo ordenan tablas. Por lo tanto, no consumen almacenaje extra. Los índices no agrupados son almacenados en un lugar separado de la tabla real. Reclamando más espacio de almacenamiento.
- Los índices agrupados son más rápidos que los índices no agrupados, ya que no involucran ningún paso extra de búsqueda.
Ver más
Para arreglar la fragmentación de índices SQL, considere ApexSQL Defrag – una herramienta de desfragmentación, mantenimiento, análisis y monitoreo de índices de SQL Server.
Enlaces Útiles
- Diferencias entre índices agrupados y no agrupados en SQL – Video de YouTube
- Índices agrupados y no agrupados
- Índices no agrupados en SQL


Ver todas las entradas de Ben Richardson
- Cómo usar las funciones de Windows en SQL Server - December 16, 2019
- Como comprender el tipo de datos GUID en SQL Server - September 30, 2019
- Cómo utilizar las funciones integradas de SQL Server y crear funciones escalares definidas por el usuario - September 30, 2019