
Cuando sea que una consulta es ejecutada en SQL Server, su plan de ejecución, así como algunos datos útiles de ejecución son ubicados en el caché del plan para usos futuros. Esta información es un tesoro de métricas que pueden permitir tener una visión muy útil del desempeño de su servidor y el consumo de recursos. Mucha de esta información sería difícil o imposible de adquirir de otra manera.
Entender cómo acceder y usar los metadatos acerca de la ejecución de la consulta nos proveerá con las herramientas que necesitamos para responder preguntas acerca de nuestro servidor y ganar datos de desempeño fascinantes. Me he sorprendido a mí mismo pasando más y más tiempo escribiendo, corrigiendo y usando consultas contra el caché del plan últimamente, ¡y espero compartir estas aventuras con ustedes!
El poder del caché del plan
Revisar a profundidad el caché del plan, lo que yo llamo frecuentemente “dumpster driving”, provee información acerca de una variedad de componentes de SQL Server, todos los cuales demostraremos aquí. Estos incluyen:
- Consumo de memoria del servidor
- Texto, plan de ejecución y frecuencia de ejecución de la consulta
- Consumo de recursos por consulta
- Recompilaciones de consulta
- Las consultas con peor desempeño en su servidor
Los datos en el caché del plan no son estáticos y cambiarán con el tiempo. Los planes de ejecución, junto con su consulta asociada y las métricas de recursos permanecerán en la memoria siempre que sean considerados relevantes. Los planes pueden ser removidos de la caché cuando hay presión de memoria, cuando envejecen (se vuelven fijos), o cuando un nuevo plan es creado, haciendo que el antiguo sea obsoleto. Tenga esto en cuenta mientras vemos alrededor: La información que encontremos en la caché del plan es transitoria e indicativa de una actividad reciente y actual del servidor y no refleja un historial de largo plazo. Como resultado, asegúrese de hacer una investigación a fondo en la caché del plan previo a tomar cualquier decisión significativa basado en esos datos.
Comencemos con una búsqueda basada en el texto de la consulta. Quizá usted está buscando consultas que han sido ejecutadas contra una tabla específica o han usado un cierto objeto. Aquí está un ejemplo donde buscamos todas las consultas ejecutadas contra la tabla SalesOrderHeader:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT TOP 10 databases.name, dm_exec_sql_text.text AS TSQL_Text, dm_exec_query_stats.creation_time, dm_exec_query_stats.execution_count, dm_exec_query_stats.total_worker_time AS total_cpu_time, dm_exec_query_stats.total_elapsed_time, dm_exec_query_stats.total_logical_reads, dm_exec_query_stats.total_physical_reads, dm_exec_query_plan.query_plan FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.plan_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) INNER JOIN sys.databases ON dm_exec_sql_text.dbid = databases.database_id WHERE dm_exec_sql_text.text LIKE '%SalesOrderHeader%'; |
Los resultados de esta consulta variarán dependiendo de su uso en esta tabla, pero en mi servidor se ve así:

La búsqueda tomó las 10 primeras consultas con este texto en mi servidor. Note que colectó consultas de cada base de datos, ¡no sólo AdventureWorks! Si lo quisiéramos, podemos filtrar en el nombre de la base de datos para limitar los resultados a la base de datos objetivo. Nuestras consultas de búsqueda también aparecen en la lista, dado que incluyen el nombre de la tabla también, y probablemente vale la pena excluirlas también. Aquí está un resumen de las vistas usadas anteriormente:
Sys.dm_exec_query_stats:Provee detalles acerca de ejecuciones de la consulta, como lecturas, escrituras, duración, etc…
Sys.dm_exec_sql_text: Esta función incluye el texto de la consulta ejecutada. El asidero del plan es un ID de identificación única para un plan de ejecución dado.
sys.dm_exec_query_plan: También una función de un asidero de un plan, esta función provee el plan de ejecución de consultas XML para una consulta dada.
sys.databases: Vista del sistema que provee bastante información acerca de cada base de datos en esta instancia.
Ahora podemos filtrar y encontrar qué consultas están corriendo basadas en su texto, cuán frecuentemente corren y algunos totales de uso básicos. También podemos hacer clic en el plan de ejecución XML y ver lo que el optimizador decidió hacer cuando la consulta fue ejecutada. Si usted hace clic en el enlace del plan de consultas dentro de los resultados, una nueva pestaña se abrirá con el plan en gráfico:

Como con un plan que usted ve normalmente en SQL Server Management Studio u otra herramienta, usted puede posar el cursor sobre cualquier paso para obtener más detalles, o abrir la ventana de propiedades para incluso más información. Como siempre, los signos de admiración, como el amarillo en la imagen anterior, son indicativos de un aviso de ejecución y siempre deberían ser investigados.
Buscar en texto es útil, pero somos capaces de recolectar datos mucho más útiles ajustando nuestra consulta existente. Por ejemplo, ¿qué si queríamos saber cuáles consultas en nuestro servidor son las más pesadas? Esto hará el truco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
SELECT TOP 25 databases.name, dm_exec_sql_text.text AS TSQL_Text, CAST(CAST(dm_exec_query_stats.total_worker_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as cpu_per_execution, CAST(CAST(dm_exec_query_stats.total_logical_reads AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as logical_reads_per_execution, CAST(CAST(dm_exec_query_stats.total_elapsed_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as elapsed_time_per_execution, dm_exec_query_stats.creation_time, dm_exec_query_stats.execution_count, dm_exec_query_stats.total_worker_time AS total_cpu_time, dm_exec_query_stats.max_worker_time AS max_cpu_time, dm_exec_query_stats.total_elapsed_time, dm_exec_query_stats.max_elapsed_time, dm_exec_query_stats.total_logical_reads, dm_exec_query_stats.max_logical_reads, dm_exec_query_stats.total_physical_reads, dm_exec_query_stats.max_physical_reads, dm_exec_query_plan.query_plan, dm_exec_cached_plans.cacheobjtype, dm_exec_cached_plans.objtype, dm_exec_cached_plans.size_in_bytes FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.plan_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) INNER JOIN sys.databases ON dm_exec_sql_text.dbid = databases.database_id INNER JOIN sys.dm_exec_cached_plans ON dm_exec_cached_plans.plan_handle = dm_exec_query_stats.plan_handle WHERE databases.name = 'AdventureWorks2014' ORDER BY dm_exec_query_stats.max_logical_reads DESC; |
Una nueva vista ha sido añadida a esta consulta: sys.dm_exec_cached_plans, la cual provee información adicional en un plan en caché, como el tipo de consulta que fue ejecutado y el tamaño del plan almacenado. Los resultados no caben fácilmente en una sola línea, así que hemos cortado un puñado de ellos para mantenerlos legibles:
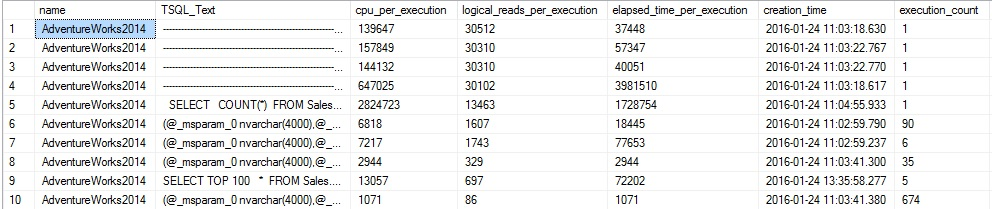
La clave en los resultados es que están ordenados por las lecturas máximas para una ejecución dada, lo cual nos permite cernir las consultas con más lecturas y determinar si es necesaria una optimización. También podríamos ordenar por el total de lecturas lógicas, o también por tiempo transcurrido (duración de consulta), tiempo de trabajo (CPU) o número de ejecuciones. Esto nos permite sacar consultas comunes y ver cuáles son las consultas problemáticas basados en una variedad de métricas. Calcular métricas por ejecución nos permite entender más fácilmente cuán pesada fue una consulta dada, y nos permite contrastar la frecuencia de ejecución versus el costo de la ejecución.
Algunos de los resultados TSQL_Text muestran un puñado de guiones. Esto es porque el texto de consulta almacenado en dm_exec_sql_text incluye todo el texto de la consulta, incluyendo comentarios. Podemos copiar el TSQL desde la columna TSQL_Text y pegarla en una ventana separada para obtener una mejor vista. Hay un beneficio añadido de los comentarios de inclusión: Podemos etiquetar consultas de modo que sea fácil identificarlas posteriormente. Por ejemplo, digamos que estamos introduciendo una nueva consulta en producción que correrá 50 mil veces por hora. Estamos preocupados acerca del desempeño y queremos poder monitorear el consumo de recursos tan pronto como sea publicada. Una manera eficiente y fácil de hacer una consulta fácil de encontrar en la caché sería añadiendo una etiqueta única, como en el siguiente ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- 01232016 Open Order Query by EHP SELECT TOP 100 SalesOrderHeader.SalesOrderID, SalesOrderDetail.SalesOrderDetailID, SalesOrderHeader.OrderDate, SalesOrderHeader.DueDate, SalesOrderHeader.PurchaseOrderNumber, SalesOrderDetail.ProductID, SalesOrderDetail.LineTotal FROM Sales.SalesOrderHeader INNER JOIN Sales.SalesOrderDetail ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID WHERE Status <> 5; |
El comentario al principio de la consulta será incluido en la caché del plan. Al costo de cerca de 30 bytes de texto SQL, ahora podemos buscar en la caché del plan esta consulta específica y obtener exactamente lo que queremos sin ningún ruido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
SELECT databases.name, dm_exec_sql_text.text AS TSQL_Text, CAST(CAST(dm_exec_query_stats.total_worker_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as cpu_per_execution, CAST(CAST(dm_exec_query_stats.total_logical_reads AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as logical_reads_per_execution, CAST(CAST(dm_exec_query_stats.total_elapsed_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as elapsed_time_per_execution, dm_exec_query_stats.creation_time, dm_exec_query_stats.execution_count, dm_exec_query_stats.total_worker_time AS total_cpu_time, dm_exec_query_stats.max_worker_time AS max_cpu_time, dm_exec_query_stats.total_elapsed_time, dm_exec_query_stats.max_elapsed_time, dm_exec_query_stats.total_logical_reads, dm_exec_query_stats.max_logical_reads, dm_exec_query_stats.total_physical_reads, dm_exec_query_stats.max_physical_reads, dm_exec_query_plan.query_plan, dm_exec_cached_plans.cacheobjtype, dm_exec_cached_plans.objtype, dm_exec_cached_plans.size_in_bytes FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.plan_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) INNER JOIN sys.databases ON dm_exec_sql_text.dbid = databases.database_id INNER JOIN sys.dm_exec_cached_plans ON dm_exec_cached_plans.plan_handle = dm_exec_query_stats.plan_handle WHERE dm_exec_sql_text.text LIKE '-- 01232016 Open Order Query by EHP%'; |
Los resultados sólo incluyen consultas que comienzan con la etiqueta de comentario que creamos, y por tanto todos los otros resultados similares, incluyendo la anterior consulta de búsqueda, son eliminados de lo que se retorna:

Note que el tiempo de creación está incluido, lo cual nos dice cuándo fue creado el plan. Esto provee una visión acerca de por cuánto tiempo el plan ha estado en la caché. Con eso, podemos calcular el número de ejecuciones por hora para una consulta dada añadiendo el siguiente TSQL a cualquiera de nuestras búsquedas:
|
1 |
CAST(CAST(dm_exec_query_stats.execution_count AS DECIMAL) / CAST((CASE WHEN DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) = 0 THEN 1 ELSE DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) END) AS DECIMAL) AS INT) AS executions_per_hour |
Esto se ve un poco confuso, ya que necesitamos hacer algunas conversiones para evitar truncados o redondeados no deseados, pero el cálculo básico es simplemente el conteo de ejecuciones dividido entre las horas. La sentencia CASE administra el escenario donde el plan menos antiguo que una hora, en cuyo caso cero no sería un resultado útil, así que usamos uno para el valor de horas. Con ese TSQL añadido a nuestra consulta previa, podemos ver el resultado deseado:

Ahora que tenemos lo básico hecho, ¡comencemos a desglosar los planes de ejecución en sí mismo y busquemos basados en su contenido!
Buscando planes de ejecución de consultas específicos
Hay muchas razones por las que quisiéramos buscar el plan de ejecución para partes específicas que nos interesan. Considere algunos de estos ejemplos:
- El uso de un índice específico.
- Avisos, como conversiones implícitas, derrames TempDB, o joins sin predicado.
- Uso de Paralelismo.
- Escaneos de índices agrupados, escaneo de tablas u operadores que puedan ser indicativos de un problema más grande.
- Uso de una tabla, función, procedimiento almacenado y otro objeto que puede no estar explícitamente en el texto de la consulta.
- Los planes de ejecución que involucran índices forzados, pistas de consultas de tablas u otros objetos.
La forma más simple de buscar el texto de un plan de ejecución para el uso de índices sería tomar el XML como una pila de texto y escanearlo buscando todas las ocurrencias del nombre del índice:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT dm_exec_query_plan.query_plan, usecounts AS execution_count, dm_exec_sql_text.text FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) INNER JOIN sys.dm_exec_query_stats ON dm_exec_query_stats.plan_handle = dm_exec_cached_plans.plan_handle CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.plan_handle) WHERE CAST(dm_exec_query_plan.query_plan AS NVARCHAR(MAX)) LIKE '%PK_SalesOrderHeader_SalesOrderID%' |
Esto retorna los resultados que estamos buscando, pero también bastante ruido. Dado que no estamos buscando específicamente el uso de índices, frecuentemente va a haber planes de ejecución adicionales retornados que involucran el índice en cuestión, pero no los usaron explícitamente. Las búsquedas de metadatos de usuario o el mantenimiento del sistema puede causar algo de este ruido:
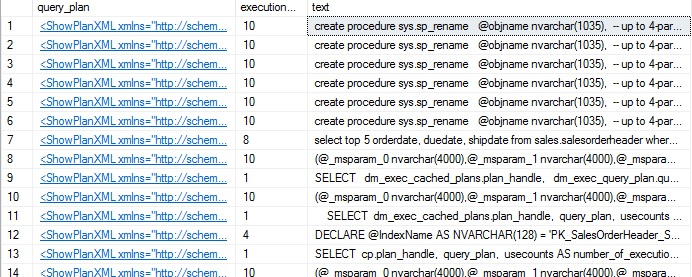
Los renombramientos del índice, así como las varias búsquedas que hemos estado ejecutando, todo se mostrará en la lista. En un servidor más ocupado, la cantidad de ruido puede hacer que consuma más tiempo encontrar las consultas que realmente estamos buscando. Adicionalmente, esta búsqueda es muy lenta. Ya que los planes de ejecución son XML; nos beneficiaremos de buscar a través de ellos usando XML. La siguiente consulta retornará sólo instancias donde el índice es realmente usado, y no incluirá referencias no relacionadas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DECLARE @index_name AS NVARCHAR(128) = '[PK_SalesOrderHeader_SalesOrderID]'; ;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT stmt.value('(@StatementText)[1]', 'varchar(max)') AS sql_text, obj.value('(@Database)[1]', 'varchar(128)') AS database_name, obj.value('(@Schema)[1]', 'varchar(128)') AS schema_name, obj.value('(@Table)[1]', 'varchar(128)') AS table_name, obj.value('(@Index)[1]', 'varchar(128)') AS index_name, obj.value('(@IndexKind)[1]', 'varchar(128)') AS index_type, dm_exec_query_plan.query_plan, dm_exec_cached_plans.usecounts AS execution_count FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS nodes(stmt) CROSS APPLY stmt.nodes('.//IndexScan/Object[@Index=sql:variable("@index_name")]') AS index_object(obj) |
Esto es un poco más complicado, ya que necesitamos buscar en el XML explícitamente usos del índice por nombre, pero los resultados serán precisos:

Las 4 filas retornadas corresponden a consultas específicas en las cuales la clave primaria en SalesOrderHeader era usada en el plan de ejecución. Esto puede ser una excelente herramienta cuando se está buscando, no sólo si un índice es usado, sino cómo es usado y en qué consultas. Si estamos intentado eliminar índices innecesarios y descubrir uno que es leído mil veces al día, podemos usar esta investigación más profunda para ver exactamente qué consultas causan esas lecturas. Con esa información a la mano, podemos tomar decisiones inteligentes acerca de si el índice puede ser removido, cómo la consulta podría ser rescrita para ya no necesitarla, o alguna otra solución.
De manera similar a la búsqueda de consultas que usan índices específicos, podemos analizar gramaticalmente el XML y buscar cualquier operación de plan de ejecución que pueda ser de interés. Por ejemplo, las conversiones implícitas con frecuencia dañarán el desempeño, dado que el optimizador necesita convertir entre tipos de datos sobre la marcha. Esto puede causar escaneos en lugar de búsquedas, lecturas excesivas y, lo peor de todo, latencia no deseada. Podemos combinar dos consultas previas para proveer una lista de todas las consultas en la cache para AdventureWorks2014 que han tenido conversiones implícitas, así como incluir las métricas útiles de nuestras búsquedas iniciales en la caché del plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
DECLARE @database_name NVARCHAR(128) = 'AdventureWorks2014'; ;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT dm_exec_sql_text.text AS sql_text, CAST(CAST(dm_exec_query_stats.execution_count AS DECIMAL) / CAST((CASE WHEN DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) = 0 THEN 1 ELSE DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) END) AS DECIMAL) AS INT) AS executions_per_hour, dm_exec_query_stats.creation_time, dm_exec_query_stats.execution_count, CAST(CAST(dm_exec_query_stats.total_worker_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as cpu_per_execution, CAST(CAST(dm_exec_query_stats.total_logical_reads AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as logical_reads_per_execution, CAST(CAST(dm_exec_query_stats.total_elapsed_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as elapsed_time_per_execution, dm_exec_query_stats.total_worker_time AS total_cpu_time, dm_exec_query_stats.max_worker_time AS max_cpu_time, dm_exec_query_stats.total_elapsed_time, dm_exec_query_stats.max_elapsed_time, dm_exec_query_stats.total_logical_reads, dm_exec_query_stats.max_logical_reads, dm_exec_query_stats.total_physical_reads, dm_exec_query_stats.max_physical_reads, dm_exec_query_plan.query_plan FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.sql_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) WHERE query_plan.exist('//PlanAffectingConvert') = 1 AND query_plan.exist('//ColumnReference[@Database = "[AdventureWorks2014]"]') = 1 ORDER BY dm_exec_query_stats.total_worker_time DESC; |
La primera revisión del XML verificará si PlanAffectingConvert es encontrado en el plan de ejecución, lo que verifica las conversiones implícitas por nosotros. La segunda revisión del XML limita los resultados a AdventureWorks2014. Usted puede cambiar esto a otra base de datos o removerlo del todo si usted no espera mucho ruido de otras bases de datos. Los resultados se verán así:

Si nos desplazamos a la derecha, la última columna provee los planes de ejecución para nuestros resultados. Abriremos el plan de ejecución para la consulta contra HumanResources.Employee en la línea 8 del conjunto de resultados:
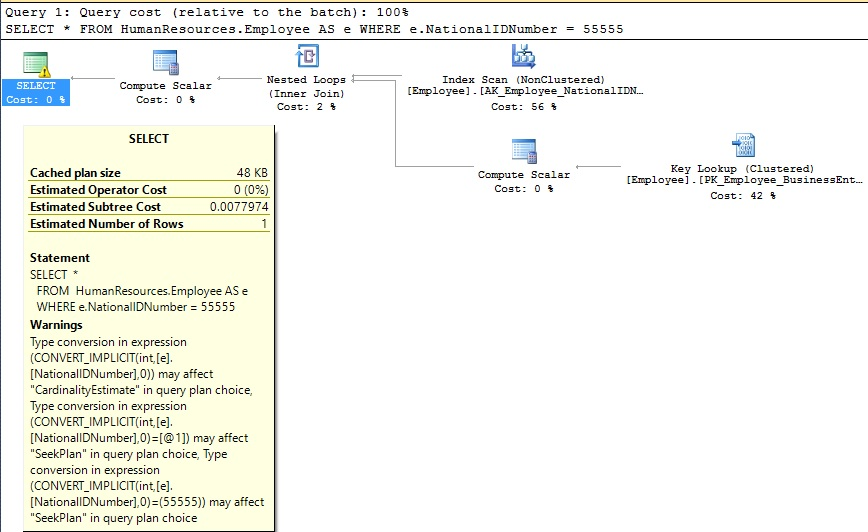
Podemos verificar en las propiedades de la sentencia SELECT que una conversión implícita tuvo lugar en NationalIDNumber. Si encontramos este tipo de consulta en un ambiente de producción, podemos rastrearlo y ajustar la fuente para referenciar esta columna como una cadena en lugar de un valor numérico, lo cual resolvería la conversión implícita, mejoraría el plan de ejecución y mejoraría el desempeño.
Tan fácilmente como buscamos conversiones implícitas, también podríamos ver derrames TempDB, lo cual podría indicar ordenamientos demasiado grandes, combinaciones hash o TSQL pobremente escritos llevando a una situación similar. Podríamos entonces escribir otra consulta para revisar las combinaciones sin un predicado join, o columnas sin estadísticas o cualquier otra alera que podamos imaginar. En lugar de escribir docenas de consultas, usemos una sola para verificar todas las alertas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
DECLARE @database_name NVARCHAR(128) = 'AdventureWorks2014'; ;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT dm_exec_sql_text.text AS sql_text, CAST(CAST(dm_exec_query_stats.execution_count AS DECIMAL) / CAST((CASE WHEN DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) = 0 THEN 1 ELSE DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) END) AS DECIMAL) AS INT) AS executions_per_hour, dm_exec_query_stats.creation_time, dm_exec_query_stats.execution_count, CAST(CAST(dm_exec_query_stats.total_worker_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as cpu_per_execution, CAST(CAST(dm_exec_query_stats.total_logical_reads AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as logical_reads_per_execution, CAST(CAST(dm_exec_query_stats.total_elapsed_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as elapsed_time_per_execution, dm_exec_query_stats.total_worker_time AS total_cpu_time, dm_exec_query_stats.max_worker_time AS max_cpu_time, dm_exec_query_stats.total_elapsed_time, dm_exec_query_stats.max_elapsed_time, dm_exec_query_stats.total_logical_reads, dm_exec_query_stats.max_logical_reads, dm_exec_query_stats.total_physical_reads, dm_exec_query_stats.max_physical_reads, dm_exec_query_plan.query_plan FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.sql_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) WHERE query_plan.exist('//Warnings') = 1 AND query_plan.exist('//ColumnReference[@Database = "[AdventureWorks2014]"]') = 1 ORDER BY dm_exec_query_stats.total_worker_time DESC; |
Esto es virtualmente idéntico a nuestra última búsqueda en el plan de consultas, excepto que hemos agrandado nuestra búsqueda para verificar la existencia de cualquier alerta, más allá de sólo conversiones implícitas.

La fila remarcada es nueva, y revisar el plan de ejecución revela el problema:
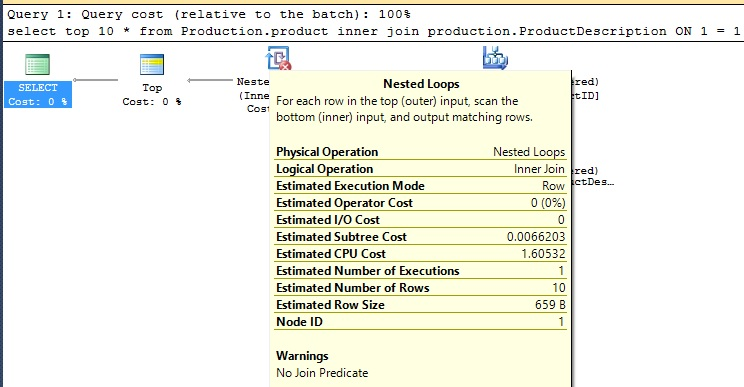
Yo escribí algunos TSQL muy pobres ahí, combinando dos tablas Production en 1 = 1, lo cual lleva a una alerta muy brillante: “No Join Predicate”. Típicamente, este es el tipo de alerta que usted no decubrirá hasta que haya quejas de usuarios de que la aplicación es lenta. Con la habilidad de buscar periódicamente en la caché, podemos proactivamente encontrar estas alertas o, en el peor caso, identificarlas rápidamente después de que alguien se ha quejado con usted.
¿Qué tal una sumergida final en la caché de planes? Esta vez, identificaremos cualquier consulta que resultó en un escaneo de tabla o un escaneo de índices agrupados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DECLARE @database_name NVARCHAR(128) = 'AdventureWorks2014'; ;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT dm_exec_sql_text.text AS sql_text, CAST(CAST(dm_exec_query_stats.execution_count AS DECIMAL) / CAST((CASE WHEN DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) = 0 THEN 1 ELSE DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP) END) AS DECIMAL) AS INT) AS executions_per_hour, dm_exec_query_stats.creation_time, dm_exec_query_stats.execution_count, CAST(CAST(dm_exec_query_stats.total_worker_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as cpu_per_execution, CAST(CAST(dm_exec_query_stats.total_logical_reads AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as logical_reads_per_execution, CAST(CAST(dm_exec_query_stats.total_elapsed_time AS DECIMAL)/CAST(dm_exec_query_stats.execution_count AS DECIMAL) AS INT) as elapsed_time_per_execution, dm_exec_query_stats.total_worker_time AS total_cpu_time, dm_exec_query_stats.max_worker_time AS max_cpu_time, dm_exec_query_stats.total_elapsed_time, dm_exec_query_stats.max_elapsed_time, dm_exec_query_stats.total_logical_reads, dm_exec_query_stats.max_logical_reads, dm_exec_query_stats.total_physical_reads, dm_exec_query_stats.max_physical_reads, dm_exec_query_plan.query_plan FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.sql_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) WHERE (query_plan.exist('//RelOp[@PhysicalOp = "Index Scan"]') = 1 OR query_plan.exist('//RelOp[@PhysicalOp = "Clustered Index Scan"]') = 1) AND query_plan.exist('//ColumnReference[@Database = "[AdventureWorks2014]"]') = 1 ORDER BY dm_exec_query_stats.total_worker_time DESC; |
Una vez más, nuestra consulta es muy similar a la anterior, siendo la única diferencia que estamos revisando la caché de planes por la existencia de cualquier escaneo. Podríamos fácilmente reducir los resultados por tabla, índice u otras métricas, si muchas filas fueron retornadas. Abajo están algunos resultados de ejemplo de mi SQL Server local:

La fila 42 se ve como un error obvio. Podemos ver el plan de ejecución y verificar que un escaneo de índice agrupado en realidad ocurrió:

Esto, como los muchos otros planes de ejecución retornaron, tendrá algún tipo de escaneo que valga la pena investigar.
En adición a buscar a través de la caché por consultas u operadores específicos, podemos también agregar estos datos y determinar algunas otras métricas útiles, como:
- ¿Cuándo de la caché de planes es usada por cada base de datos?
- ¿Cuán grande es la caché de planes actualmente?
- ¿Cuáles son los planes más grandes en la caché?
- ¿Qué porcentaje de la caché de planes es el resultado de consultas contra una tabla o índice particulares?
Esta información puede proveer una visión del uso de memoria de nuestro SQL Server e identificar grupos de consultas que son gastadores de memoria. Los planes de ejecución muy grandes pueden ser indicativos de consultas de desempeño pobre también, aunque una investigación más profunda es requerida para confirmar esto. De cualquier manera, podemos tener algo de dirección cuando tratamos de mejorar el uso de memoria o encontrar planes de ejecución específicos.
Empecemos con una lista rápida de nuestros planes más grandes en la caché de planes. Estos típicamente serán consultas a un gran número de objetos, aquellos con una gran cantidad de texto o algunas operaciones XML pesadas.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT dm_exec_sql_text.text, dm_exec_cached_plans.objtype, dm_exec_cached_plans.size_in_bytes, dm_exec_query_plan.query_plan FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(dm_exec_cached_plans.plan_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_cached_plans.plan_handle) WHERE dm_exec_cached_plans.cacheobjtype = N'Compiled Plan' AND dm_exec_cached_plans.objtype IN(N'Adhoc', N'Prepared') AND dm_exec_cached_plans.usecounts = 1 ORDER BY dm_exec_cached_plans.size_in_bytes DESC; |
Ejecutar esta consulta en mi servidor local revela un plan de ejecución que pesa cerca de 1.75MB, y muy pocos que están entre 200KB y 800KB:

Hacer clic en el plan en la parte superior revela que no fue una sola consulta que hace al plan, sino que 14 consultas todas en el mismo lote. Todas son consultas de prueba que fueron ejecutadas mientras se buscaba en la caché de planes. Si usted está ejecutando consultas contra ambientes de producción para aprender acerca de la utilización de la caché, puede que quiera filtrar su conjunto de resultados. Añadir un comentario con un texto único es una buena manera de etiquetar la consulta y filtrarla después usando una cláusula WHERE en dm_exec_sql_text.text. Los porcentajes podrían también ser añadidos a esta consulta para mostrar el porcentaje de la caché total tomada por cualquier consulta dada.
Obtener el tamaño total de la caché es relativamente fácil, y puede ser hecho con una sola suma contra dm_exec_cached_plans:
|
1 2 3 4 5 6 |
SELECT SUM(CAST(dm_exec_cached_plans.size_in_bytes AS BIGINT)) / 1024 AS size_in_KB FROM sys.dm_exec_cached_plans WHERE dm_exec_cached_plans.cacheobjtype = N'Compiled Plan' AND dm_exec_cached_plans.objtype IN(N'Adhoc', N'Prepared') AND dm_exec_cached_plans.usecounts = 1; |
Note el CAST en un BIGINT. Dado que la columna size_in_bytes es un INT, si una suma de eso fuera a exceder el máximo valor que puede tener un (2^31 – 1), entonces un error sería lanzando dado que SQL Server no podría convertirlo automáticamente como un BIGINT. El resultado es retornado rápidamente y es suficientemente fácil de leer:
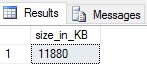
En el caso de mi servidor local, la caché de planes está actualmente usando 11,880KB (11.6MB). En un servidor de producción más grande, este valor sería significativamente más alto. Tenga en mente que la caché no puede “llenarse”. Cuando ocurre presión de la memoria, los planes más antiguos o menos usados son limpiados de la caché de planes automáticamente. Podemos fácilmente revisar cuál es la edad promedio de un plan de ejecución basados en esta consulta:
|
1 2 3 4 5 6 7 8 |
SELECT AVG(DATEDIFF(HOUR, dm_exec_query_stats.creation_time, CURRENT_TIMESTAMP)) AS average_create_time FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.plan_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) INNER JOIN sys.databases ON dm_exec_sql_text.dbid = databases.database_id WHERE databases.name = 'AdventureWorks2014' |
En este caso, la respuesta es 19 horas:
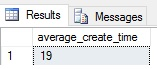
OPor supuesto, esta métrica no tiene sentido por sí misma y sólo se volvería útil cuando se ve la tendencia durante un largo periodo de tiempo. Los reinicios del servidor, las reconstrucciones de índices y otras actividades de mantenimiento podrían reducir este número también, así que la correcta tendencia de esta métrica es necesaria para cualquier uso de ella que valga la pena.
¿Qué tal desglosar el uso de la caché de planes por base de datos? La siguiente consulta agrega datos y retorna el espacio usado y las cuentas para todas las bases de datos en mi servidor:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT databases.name, SUM(CAST(dm_exec_cached_plans.size_in_bytes AS BIGINT)) AS plan_cache_size_in_bytes, COUNT(*) AS number_of_plans FROM sys.dm_exec_query_stats query_stats CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS query_plan INNER JOIN sys.databases ON databases.database_id = query_plan.dbid INNER JOIN sys.dm_exec_cached_plans ON dm_exec_cached_plans.plan_handle = query_stats.plan_handle GROUP BY databases.name |
El resultado muestra que AdventureWorks2014 es la más pesada tanto en uso y cantidad de espacio:
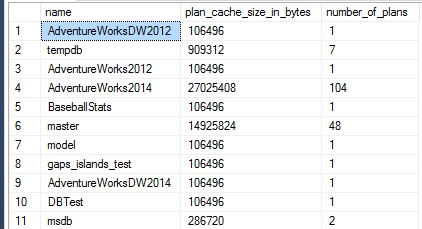
Finalmente, pero no menos importante, podemos recolectar el número de planes (y el espacio total usado) para cualquier índice dado como sigue:
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @index_name AS NVARCHAR(128) = '[PK_SalesOrderHeader_SalesOrderID]'; ;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT SUM(CAST(dm_exec_cached_plans.size_in_bytes AS BIGINT)) AS plan_cache_size_in_bytes, COUNT(*) AS number_of_plans FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS nodes(stmt) CROSS APPLY stmt.nodes('.//IndexScan/Object[@Index=sql:variable("@index_name")]') AS index_object(obj) |
Los resultados son como siguen:

En la caché de planes hay un total de seis planes de ejecución que usan la clave primaria en Sales.SalesOrderHeader, lo cual añade hasta 2MB.
Pero espere, ¿hay más?
Hay muchas otras métricas que pueden ser obtenidas de la caché de planes, un gran número de las cuales serán creadas basadas en las necesidades de su propio ambiente de bases de datos. Dependiendo de cómo TSQL es creado y usado, la caché de planes se verá diferente. Si un negocio depende mucho de ORMs para generar TSQL, entonces habrá más planes en la caché, y probablemente una edad de planes más baja. Las consultas Ad-hoc se desempeñarán de manera similar, aunque al menos tenga algún control de los desarrolladores para asegurar que no hay muchas columnas seleccionadas en muchas tablas combinadas. Un ambiente que depende mucho de procedimientos almacenados u otras consultas parametrizadas tenderá a ver menos consultas distintas en la caché y planes que duran más.
Estos son sólo unos pocos ejemplos de cómo las herramientas de desarrollo y las técnicas de consulta pueden afectar la caché del plan. La mejor manera de familiarizarse con la suya es sumergirse, investigar y determinar cómo es usada donde usted está. Tome lo que se presenta aquí vaya adelante con ello. Escriba sus propias consultas y asegúrese de compartirlas conmigo cuando esté preparado 🙂
SQL Server 2016 Query Store
Algo nuevo en SQL Server 2016 es Query Store: Una característica que añade una enorme cantidad de datos acerca de cómo las consultas son ejecutadas, cómo se desempeñan, y permite una investigación fácil a cerca de las mejores maneras de mejorarlas. Query Store provee una manera alternativa de sumergirse en la caché de planes y ver planes de ejecución, el texto de las consultas, y hacerlo sin las preocupaciones de planes dejando la caché antes de que usted los obtenga.
Dicho eso, Query Store es aún una versión de prueba de SQL Server 2016 (CTP 3.3 en la última revisión). Muchos artículos han sido escritos acerca de este tópico, y yo recomiendo revisarlos:
Intro to the Query Store w/ Configuration Info: Query Store – the next generation tool for every DBA
Example Queries and Usage of the Query Store: The SQL Server Query Store in action
Conclusión
La cache de planes de consulta no es expuesto a nosotros fácilmente en SQL Server, pero las muchas vistas disponibles a nosotros permiten una revisión a profundidad de las consultas que han corrido recientemente y cómo se han desempeñado. Estos datos pueden proveer información valiosa acerca de más métricas de las que podría listar en este artículo
Use las consultas provistas aquí como un punto de partida y personalícelas/extiéndalas para cumplir con sus necesidades. Cualquier cosa encontrada en el texto de las consultas, planes de ejecución o estadísticas de consultas puede ser analizada, y cualquiera de estas puede ser agregada basada en cualquier objeto relevante de la base de datos. Con estas capacidades, podemos no sólo buscar planes, sino también analizar la tendencia de uso, localizar problemas en el tiempo y arreglarlos cuando sea necesario.
Referencias y lecturas complementarias
MSDN provee una documentación completa acerca de todas las vistas referenciadas en estos artículos:
Adicionalmente, Microsoft provee muchos artículos acerca del uso de planes, como este:

En su tiempo libre, Ed juega video juegos, películas de ciencia ficción y fantásticas, viajar y ser un gran geek al nivel que sus amigos puedan tolerar.
Vea todas las entradas de Ed Pollack
- Técnicas de optimización de consultas en SQL Server: consejos y trucos de aplicación - September 30, 2019
- Todo lo que querías saber sobre SQL Saturday (pero tenías miedo de preguntar) - April 13, 2018
- Cambios del Optimizador de Consultas en SQL Server 2016 explicados - April 21, 2017