
Se emplea un índice SQL para poder recuperar datos de una base de datos de una manera más rápida. El indexar una tabla o la vista es sin lugar a dudas, una de las mejores opciones de poder mejorar el rendimiento de las consultas y aplicaciones.
Un índice SQL es una tabla de búsqueda rápida para poder encontrar los registros que los usuarios necesitan buscar con mayor frecuencia. Ya que un índice es pequeño, rápido y optimizado para búsquedas rápidas. Además, que son muy útiles para conectar las tablas relacionales y la búsqueda de tablas grandes.
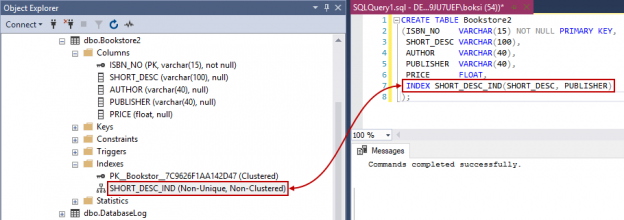
Los índices de SQL son la principal herramienta de rendimiento, por lo que generalmente se aplican si una base de datos se incrementa. SQL Server reconoce varios tipos de índices, pero uno de los más comunes es el índice agrupado. Esta clase de índice se crea automáticamente con una clave principal. Para poder aclarar mejor este punto, el ejemplo que viene a continuación crea una tabla que tiene una clave principal en la columna “EmployeeId”:
|
1 2 3 4 5 6 7 |
CREATE TABLE dbo.EmployeePhoto (EmployeeId INT NOT NULL PRIMARY KEY, Photo VARBINARY(MAX) NULL, MyRowGuidColumn UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL UNIQUE DEFAULT NEWID() ); |
Se dará cuenta que en la definición de la tabla creada para la siguiente tabla “EmployeePhoto”, la clave principal al final de la definición de la columna “EmployeeId”. Esto genera un índice SQL que está especialmente optimizado para un uso frecuente. En el momento en el que se ejecuta la consulta, SQL Server creará automáticamente un índice agrupado en la columna especificada y podremos comprobar esto desde el Explorador de objetos, si navegamos a la tabla que recién fue creada y luego a la carpeta de índices:
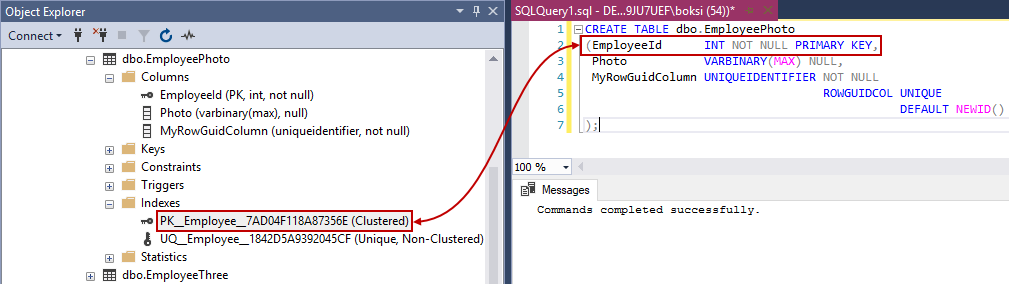
Tenemos que tener en cuenta que no solo podemos crear una clave principal que crea un índice SQL único. La restricción única hace lo mismo en las columnas especificadas. Entonces, obtenemos un índice único adicional para la columna “MyRowGuidColumn”. Podemos notar que no hay diferencias notables entre la restricción única y un índice único independiente de una restricción. La validación de datos se realiza de la misma manera y el optimizador de consultas no distingue entre un índice de SQL único creado por una restricción o creado manualmente. Por lo tanto, se debe crear una restricción de clave única o principal en la columna cuando la integridad de los datos es el objetivo, ya que, al hacerlo de esta forma, el objetivo del índice será claro.
• Nota: Una explicación más detallada para cada tipo de estos índices de SQL se puede encontrar en el siguiente artículo: How to create and optimize SQL Server indexes for better performance
Entonces, si utilizamos muchas combinaciones en la tabla recién creada, SQL Server podrá buscar índices de una manera rápida y fácil, en lugar de que tenga que buscar secuencialmente en una tabla grande.
Los índices de SQL son relativamente rápidos en parte ya que no tienen que llevar todos los datos por cada fila de la tabla, solo los datos que estamos buscando. Esto ayuda a que el sistema operativo almacene en el caché muchos índices en la memoria para un acceso más rápido y que el sistema de archivos pueda leer una gran cantidad de registros simultáneamente en lugar de tener que leerlos desde el disco.
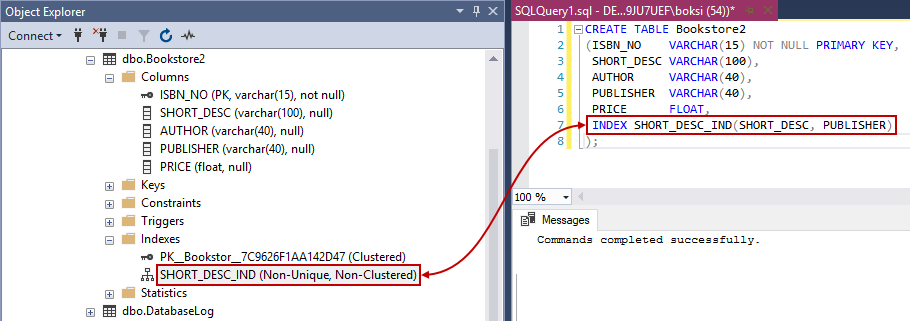
Se pueden generar índices adicionales utilizando la palabra clave Index en la definición de la tabla. Es muy útil cuando hay más de una columna en la tabla que se buscará con frecuencia. En el siguiente ejemplo se crearán índices dentro de la sentencia Create de una tabla:
|
1 2 3 4 5 6 7 8 |
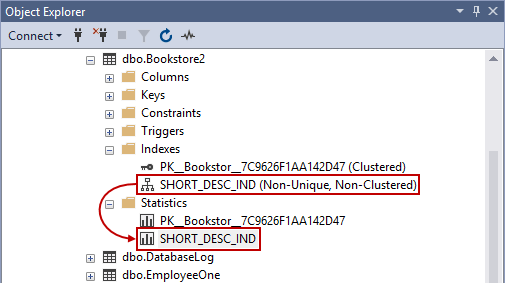
CREATE TABLE Bookstore2 (ISBN_NO VARCHAR(15) NOT NULL PRIMARY KEY, SHORT_DESC VARCHAR(100), AUTHOR VARCHAR(40), PUBLISHER VARCHAR(40), PRICE FLOAT, INDEX SHORT_DESC_IND(SHORT_DESC, PUBLISHER) ); |
En esta ocasión, si nos ponemos a navegar en el Explorador de objetos, encontraremos el índice en varias columnas:
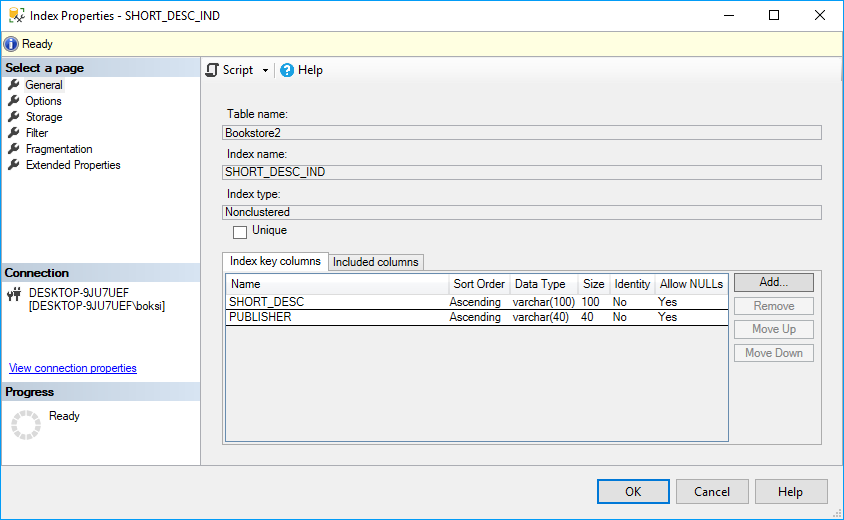
Podemos hacer clic con el botón derecho en el índice y al pulsar Propiedades nos mostrará qué abarca exactamente este índice, como el nombre de la tabla, el nombre del índice, el tipo de índice, las columnas únicas / no únicas y las claves de índice:
Tenemos que mencionar brevemente las estadísticas. Como su nombre nos lo indica, las estadísticas son hojas de los datos dentro de las columnas que están indexadas. Principalmente miden la distribución de datos dentro de las columnas y son utilizados por el optimizador de consultas, estimar filas y hacer planes de ejecución de alta calidad…
Entonces, cada vez que se crea un índice SQL, las estadísticas se generan de forma automática para almacenar la distribución de los datos dentro de esa columna. Justo por debajo de la carpeta Índices, está también la carpeta de Estadísticas. Si expandimos podremos ver la hoja con el mismo nombre específico que hicimos anteriormente en nuestro índice (lo mismo ocurre con la clave principal):
Los usuarios no pueden hacer mucho en el SQL Server cuando se trata de las estadísticas, ya que mantener los valores predeterminados, es por lo general la mejor práctica que a la larga crea y actualiza automáticamente las estadísticas. SQL Server hará un excelente trabajo con la administración de estadísticas para el 99 % de las bases de datos, pero de todas maneras es bueno conocerlas porque son otra pieza fundamental del rompecabezas cuando se trata de resolver problemas en las consultas de ejecución lenta.
• Para poder obtener una información más detallada sobre las estadísticas, consulte el siguiente artículo: How to optimize SQL Server query performance – Statistics, Joins and Index Tuning
También vale la pena que mencionemos la selectividad y la densidad al crear índices SQL. Las cuales son solo medidas usadas para poder medir el peso y la calidad del índice:
- Selectividad – valores numéricos o claves distintas
- Densidad – número de valores de clave duplicados
Estos dos son proporcionales entre sí ya que se utilizan para poder medir tanto el peso como la calidad del índice. Especialmente, de cómo funciona esto en el mundo real ya que se puede explicar en un ejemplo artificial. Pongamos el ejemplo de que hay una tabla de Empleados con 1000 registros y una columna de fecha de nacimiento que tiene un índice. Si hay una consulta que llega a esa columna que a menudo proviene de nosotros o de la aplicación y no recupera más de 5 filas, eso significa que nuestra selectividad es 0,995 y la densidad es 0,005. Esto es a lo que tendríamos que aspirar cuando generamos un índice. En el mejor de los casos, deberíamos tener índices que sean altamente selectivos, lo que básicamente significa que las consultas que llegan a ellos deben devolver un número bajo de filas.
Al momento de crear índices SQL, generalmente me gusta configurar el SQL Server para que muestre información de la actividad del disco generada por las consultas. Por lo tanto, lo primero que podemos hacer es habilitar las estadísticas de IO. Ya que es una excelente manera de ver cuánto trabajo tiene que hacer el SQL Server para recuperar los datos. De igual manera debemos incluir el plan de ejecución real y para eso, me gustaría usar una herramienta de análisis y visualización de un plan de ejecución de SQL gratuita llamada “ApexSQL Plan”. Esta herramienta nos mostrará el plan de ejecución que se usó para recuperar los datos, de este modo podremos ver qué índices de SQL se utilizan y si corresponden. Al empezar a usar ApexSQL Plan, realmente no estamos obligados a habilitar las estadísticas IO ya que la aplicación tiene estadísticas avanzadas de lecturas de I/O, como la cantidad de lecturas lógicas, incluyendo LOB, lecturas físicas (incluidas la lectura anticipada y LOB), y cuántas veces la tabla de la base de datos fue escaneada. Por lo tanto, el habilitar las estadísticas en SQL Server puede ayudar cuando se trabaja en SQL Server Management Studio. A continuación, se muestra la siguiente consulta que se utilizará como ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CHECKPOINT; GO DBCC DROPCLEANBUFFERS; DBCC FREESYSTEMCACHE('ALL'); GO SET STATISTICS IO ON; GO SELECT sod.SalesOrderID, sod.ProductID, sod.ModifiedDate FROM Sales.SalesOrderDetail sod JOIN Sales.SpecialOfferProduct sop ON sod.SpecialOfferID = sop.SpecialOfferID AND sod.ProductID = sop.ProductID WHERE sop.ModifiedDate >= '2013-04-30 00:00:00.000'; GO |
Tenemos que tomar en cuenta que también tenemos un CHECKPOINT y DBCC DROPCLEANBUFFERS que se pueden utilizar para probar consultas con un caché limpio del búfer. Básicamente, se está creando un estado de un sistema limpio sin apagar y reiniciar el servidor SQL.
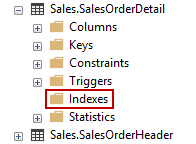
Entonces, tenemos una tabla dentro de la base de datos AdventureWorks2014 de muestra que se llama “SalesOrderDetail”. De una forma predeterminada, esta tabla ya tiene tres índices, pero los he eliminado con fines de prueba. Si se expande, la carpeta estará vacía:
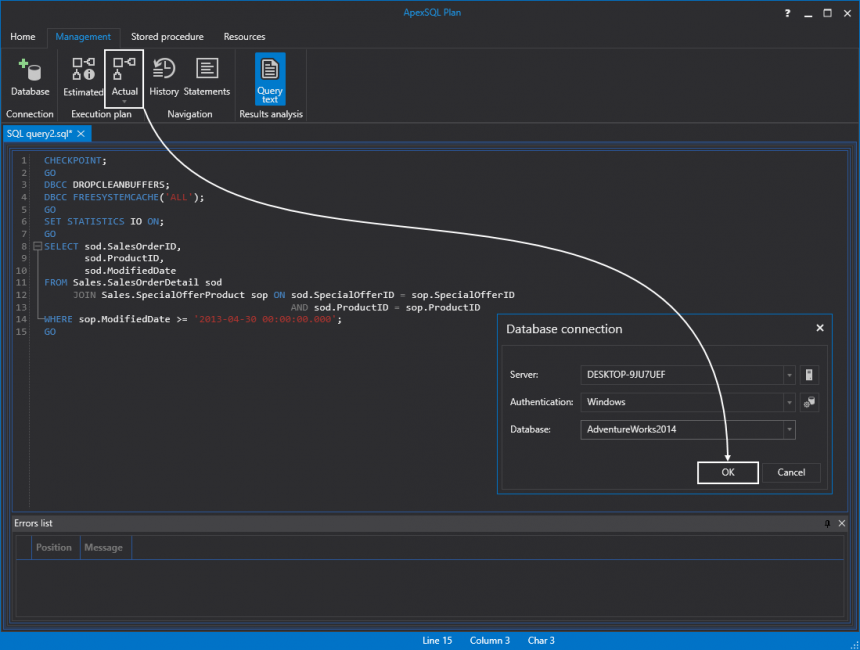
A continuación, consigamos el plan de ejecución real simplemente pegando el código en el Plan ApexSQL y haciendo clic en el botón Actual. Esta acción le indicara al diálogo de la conexión de la base de datos, la primera vez en la que tenemos que elegir el servidor SQL, el método de autenticación y la base de datos adecuada para conectarse:
Como resultado nos llevará al plan de ejecución de consultas, en el cual podemos ver que SQL Server está realizando una exploración de la tabla y está tomando la mayoría de los recursos (56,2 %) en relación con el lote. Esto es malo ya que está escaneando todo en esa tabla para extraer solo una pequeña parte de los datos. Para ser más específicos, la consulta devuelve solo 1.021 filas de un total de 121.317:
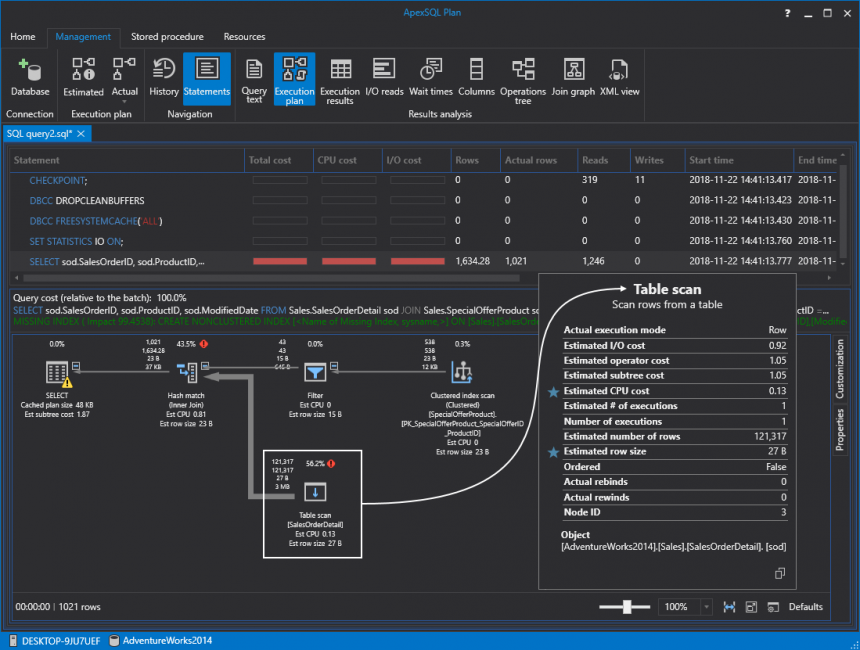
Si dirigimos el mouse sobre el signo de exclamación en rojo, una información sobre la herramienta adicional mostrará el costo de IO. En este caso, es el 99,5 por ciento:
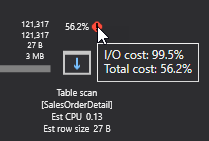
Entonces, 1.021 filas de 121.317 regresaron casi instantáneamente en el equipo actual, pero SQL Server todavía le queda por hacer mucho trabajo y, a medida que los datos se llenan en la tabla, la consulta podría ir cada vez más y más lenta con el tiempo. Entonces, en primer lugar, lo que debemos hacer es crear un índice agrupado en la tabla “SalesOrderDetail”. Tenemos que tener en cuenta que siempre debemos elegir de una manera sabia el índice agrupado. En este caso, lo estamos creando en “SalesOrderID” y “SalesOrderDetailID” porque estamos estimando tener mucha información sobre ellos. Sigamos avanzando y creemos este índice SQL ejecutando la siguiente consulta:
|
1 2 3 4 5 |
ALTER TABLE [Sales].[SalesOrderDetail] ADD CONSTRAINT [PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID] PRIMARY KEY CLUSTERED ( [SalesOrderID] ASC, [SalesOrderDetailID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] |
Antes de hacer eso. Modifiquemos rápidamente a la pestaña de lecturas de IO y tomemos una captura desde allí, solo para tener esta información antes de hacer algo:
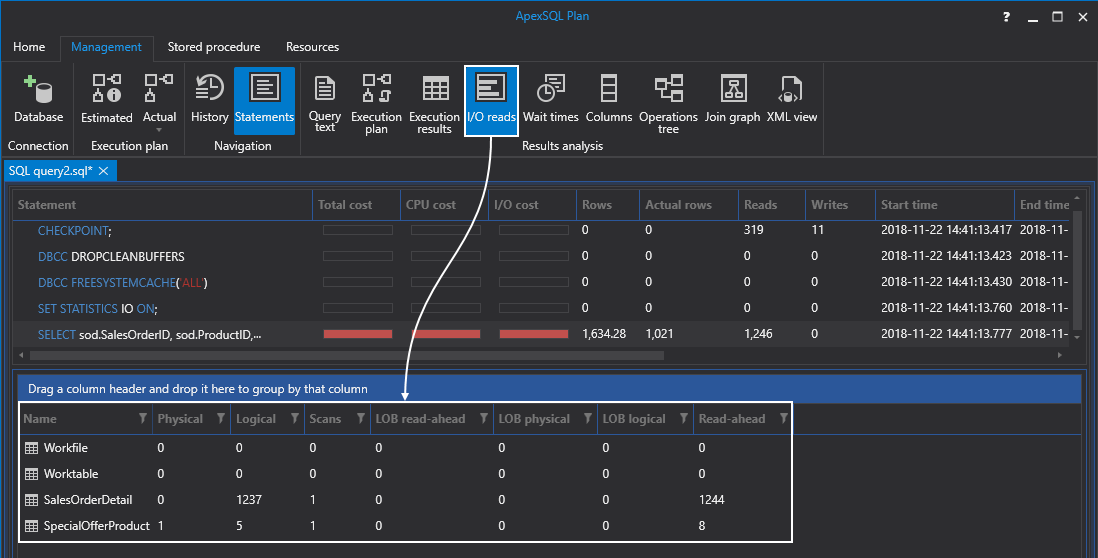
Una vez ejecutada la consulta anterior, conseguiremos un índice agrupado creado por una restricción de clave principal. Si actualizamos la carpeta de Índices en el Explorador de objetos, podremos ver el reciente índice creado, clave principal única y agrupada:

Ahora, con esto no va a mejorar mucho el rendimiento. Ya que, si volvemos a ejecutar la misma consulta, nada más cambiará de la exploración de la tabla a una exploración de índice agrupado:
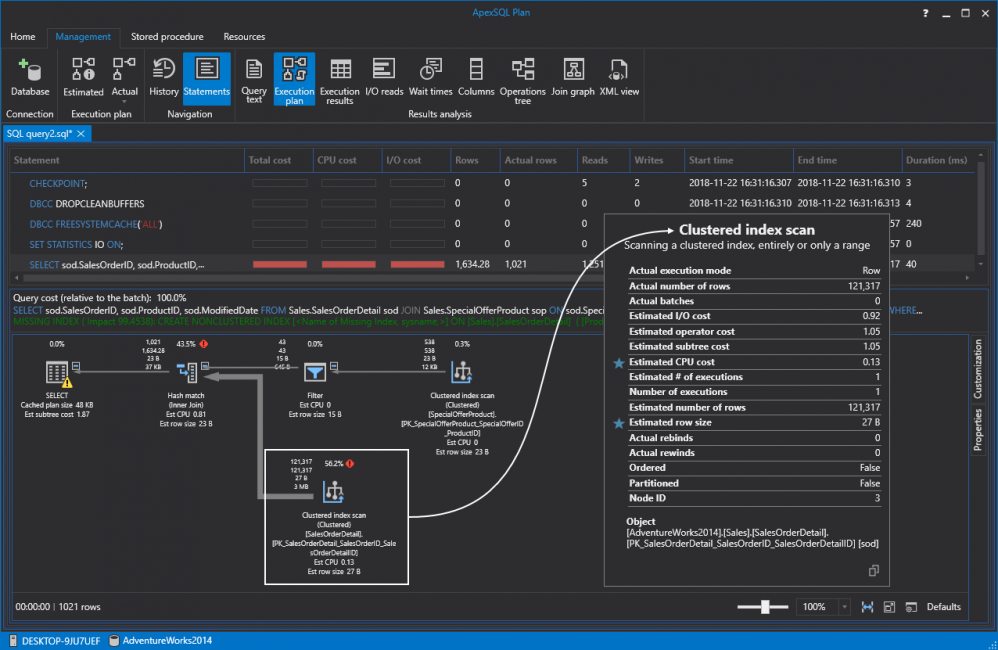
Sin embargo, ya hemos alistamos el camino para los futuros índices de SQL no agrupados. Ya, sin más preámbulos, de una vez creemos un índice no agrupado. Tomemos en cuenta que ApexSQL Plan determina los índices faltantes y crea consultas para (re) crearlos desde la información disponible. Siéntase libre de poder revisar y editar el código predeterminado o simplemente presione el comando de Ejecutar para crear el índice:
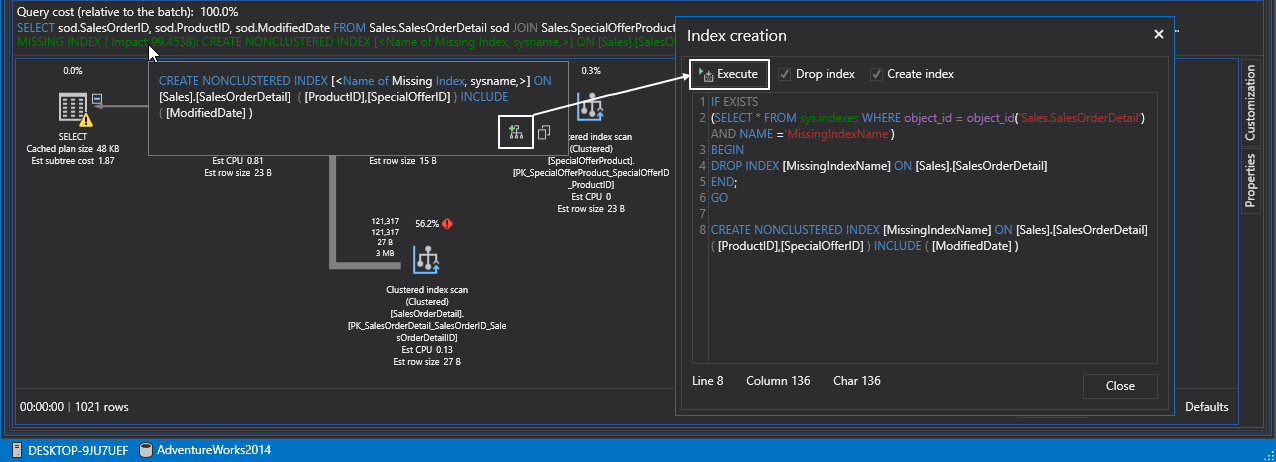
Si una vez más volvemos a ejecutar la consulta, SQL Server está realizando una búsqueda de índice no agrupado en lugar de la exploración anterior. Tenemos que recordar que las búsquedas son siempre son mejores que las exploraciones al azar:
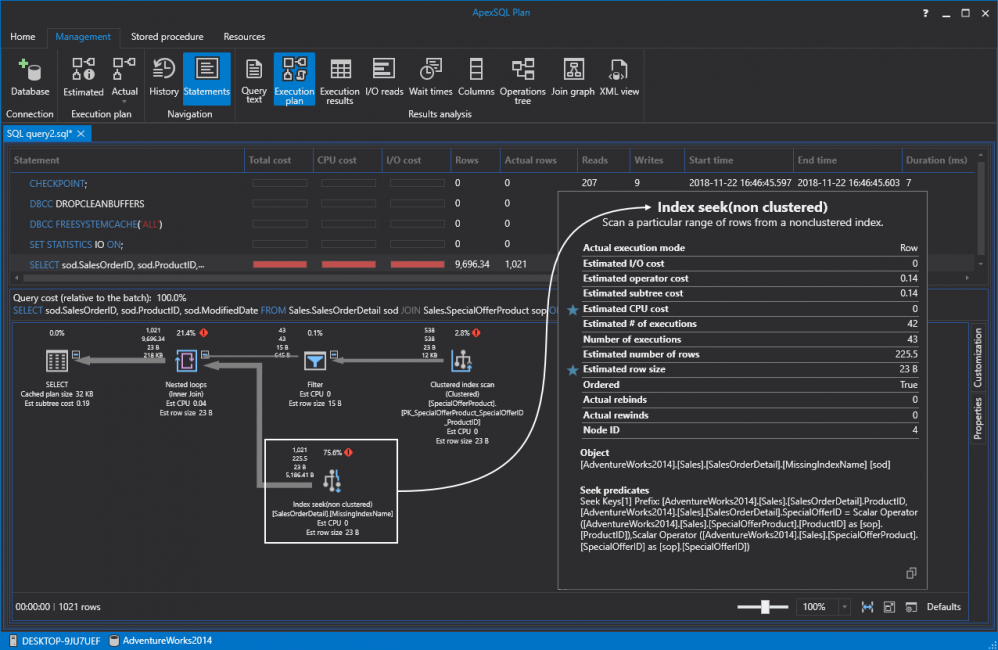
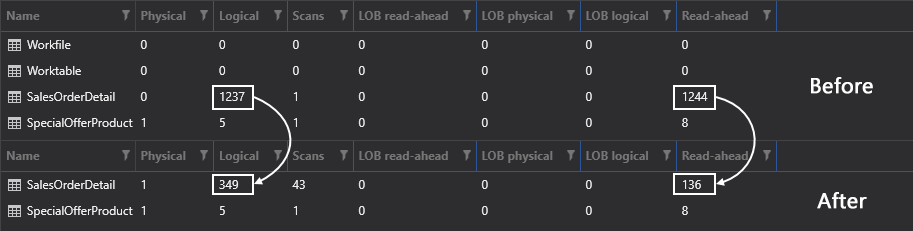
No dejemos que estos números nos engañen. Aunque algunos de estos números son más altos en relación con el lote comparado con las ejecuciones anteriores, esto no quiere decir que necesariamente sea algo malo. Si cambiamos a las lecturas de IO nuevamente y las comparamos con los resultados anteriores, podremos ver que esas lecturas bajan drásticamente de 1.237 a 349, y de 1.244 a 136. La razón por la que esto acaba de pasar de una forma tan eficiente es que SQL Server usó solo los índices de SQL para recuperar los datos:
Guías para el diseño del Índice
Los índices de SQL mal diseñados y la ausencia de ellos son las fuentes principales de los problemas de rendimiento de las aplicaciones y las bases de datos. A continuación, tenemos algunos consejos que debemos considerar al indexar tablas:
- Evite la indexación de tablas / columnas muy utilizadas: mientras más índices haya en una tabla, mayor será la afectación en el rendimiento de las declaraciones Insertar, Actualizar, Eliminar y Combinar, porque todos los índices deben modificarse adecuadamente. Lo cual significa que SQL Server tendrá que hacer la división de páginas, mover datos, y tendrá que hacerlo para todos los índices afectados por esas declaraciones DML
- Utilizar las claves de índice estrechas todas las veces que sea posible: mantengamos los índices estrechos, lo que quiere decir, que con el menor número de columnas posible. Las claves numéricas exactas son las claves de índice SQL más eficientes (por ejemplo, enteros). Estas claves necesitan menos espacio en disco y menos gastos adicionales de mantenimiento.
- Utilizar índices agrupados en columnas únicas: tenemos que considerar que las columnas que son únicas o que contienen muchos valores distintos y evitarlas para las columnas que experimentan cambios más frecuentes.
- Los índices no agrupados en las columnas en las que se buscan y / o se unen con frecuencia: asegúrese de que estos índices no agrupados se coloquen en claves y columnas externas que se usan con frecuencia en condiciones de búsqueda, como la cláusula Where que devuelve coincidencias exactas
- Cubrir los índices de SQL para obtener mayores ganancias en el rendimiento: las mejoras se logran cuando el índice contiene todas las columnas de la consulta.
Espero que este artículo sobre los índices SQL haya sido informativo y le doy gracias por la lectura del mismo.

He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
View all posts by Bojan Petrovic