
Introducción
Una de las funciones primarias en Inteligencias de Negocios es permitir a los usuarios de negocios entender la naturaleza de los datos generados por sus sistemas de negocios. Por ejemplo, en la industria de seguros, un caso de negocios en un departamento de reclamos de políticas típicamente involucraría entender el número de documentos enviados versus documentos pendientes requeridos para procesar exitosamente un reclamo. Una representación relacional no normalizada de tal caso de negocios se vería como se muestra en la Tabla 1:
Tabla 1
RecKey | PolID | PolNumber | PolType | Effective Date | DocID | DocName | Submitted | Outstanding |
1 | 2 | Pol002 | Hospital Cover | 01-Oct-07 | 1 | Doc A | 0 | |
2 | 2 | Pol002 | Hospital Cover | 01-Oct-07 | 4 | Doc B | 0 | |
3 | 2 | Pol002 | Hospital Cover | 01-Oct-07 | 5 | Doc C | 1 | |
4 | 2 | Pol002 | Hospital Cover | 01-Oct-07 | 7 | Doc D | 1 | |
5 | 2 | Pol002 | Hospital Cover | 01-Oct-07 | 10 | Doc E | 1 |
Note que, aunque hay 5 entradas en la Tabla 1, todo esto es información acerca de la misma política – Pol002.Del lado de reportes operacionales, esto puede transmitir un mensaje incorrecto de que hay 5 políticas cuyos documentos están pendientes. La forma correcta sería transponer esta información que resultaría en una vista que contiene una sola instancia de esta política y todos sus documentos pendientes/enviados como se muestra en la Tabla 2:
Tabla 2
PolNumber | PolType | Effective Date | Doc A | Doc B | Doc C | Doc D | Doc E |
Pol002 | Hospital Cover | 01-Oct-07 | 0 | 0 | 1 | 1 | 1 |
El objetivo de este artículo es demostrar diferentes opciones que podrían ser utilizadas para lograr una vista que es presentada en la Tabla 2. También vamos a usar Planes de Ejecución Real de SQL Server, Tiempo y Estadísticas IO que indican el costo de usar una opción sobre otra.
Opción #1: PIVOT
Si usted ya está familiarizado con Transact-SQL (T-SQL), entonces puede que encuentre que la manera más simple de transponer filas en columnas es usar un operador PIVOT. La Figura 1 muestra cómo un script que usa un operador PIVOT es usado para transponer filas en columnas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT * FROM ( SELECT [PolNumber], [PolType], [Effective Date], [DocName], [Submitted] FROM [dbo].[InsuranceClaims] ) AS SourceTable PIVOT(AVG([Submitted]) FOR [DocName] IN([Doc A], [Doc B], [Doc C], [Doc D], [Doc E])) AS PivotTable; |

Expansión Vertical
A medida que añadimos números de políticas en nuestro conjunto de datos, el script puede recuperar números de políticas recientemente añadidocs sin requerir ningún cambio – como se muestra en la Figura 2.

Expansión Horizontal
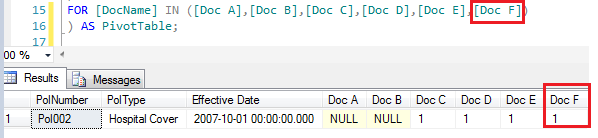
La mayor limitación de usar un operador PIVOT es que usted necesita tener una lista predefinida de todos los posibles valores que podrían ser almacenados en la cláusula FOR. Por ejemplo, mi cláusula FOR ve los valores dentro de la columna [DocName]l, los cuales son Doc A – Doc E. Lo que pasará si el negocio introduce otro requerimiento (por ejemplo, Doc F) ), ¿eso debería ser enviado para propósitos de procesar una reclamación Hospital Cover? Bueno, si usted re ejecuta el script en la Figura 1, usted no verá valores para Doc F en lugar de eso usted sólo puede ver valores editando la parte de la cláusula FOR de su script para incluir la columna Doc F como se muestra en la Figura 3.
De todas maneras, imagine, ¿si el negocio más tarde decide añadir 100 documentos más que son requeridos para procesar un reclamo? Se vuelve imposible mantener tal cambio, y si el script está ya en producción, puede que tenga que elevar una solicitud de cambio para implementar tal cambio. Por tanto, aunque transponer las filas usando el operador PIVOR puede parecer simple, puede que más tarde sea difícil de mantener.
Análisis del Desempeño
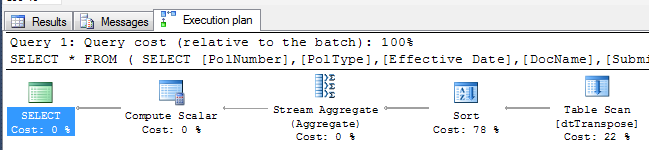
El plan real estimado representado en la Figura 4, indica que sólo una consulta fue ejecutada con la mayoría del costo usado por el operador Sort.
La tabla dtTranspose fue sólo escaneada una vez con los datos recuperados desde el disco (lecturas físicas) y luego cargada y leída desde la caché (lectura lógica) como se muestra en la Figura 5.

Opción #2: CURSOR
Aunque el consenso general en la comunidad profesional es alejarse de Cursores de SQL Server, hay aún instancias por las cuales el uso de cursores es recomendado. Supongo que, si fueran completamente inútiles, Microsoft hubiera deprecado su uso hace mucho tiempo, ¿verdad? De todas maneras, los Cursores nos presentan otra opción para transponer filas en columnas que resultará en una salida como se representa en la Tabla 2. La Figura 6 muestra un código T-SQL que puede ser usado para transponer filas en columnas. El resultado de la ejecución del script es una impresión de la variable @message_T que almacena los datos transpuesto – obviamente usted puede tomar el contenido de la variable y colocarlo en un objeto permanente de SQL Server, por ejemplo, una tabla.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DECLARE @PolNumber NVARCHAR(255), @PolNumber5 NVARCHAR(255), @PolType VARCHAR(255), @DocName NVARCHAR(255), @Submitted INT, @Eff DATE, @message_T NVARCHAR(MAX); SET @message_T = ''; SET @PolNumber5 = ''; DECLARE policyDocs_csr CURSOR FOR SELECT [PolNumber], [PolType], [Effective Date], [DocName], [Submitted] FROM [dbo].[InsuranceClaims] ORDER BY [PolNumber]; OPEN policyDocs_csr; FETCH NEXT FROM policyDocs_csr INTO @PolNumber, @PolType, @Eff, @DocName, @Submitted; WHILE @@FETCH_STATUS = 0 BEGIN IF @PolNumber5 <> @PolNumber SET @message_T = @message_T+CHAR(13)+@PolNumber+' | '+@PolType+' | '+CONVERT(VARCHAR, @eff)+' | '+@DocName+' ( '+CONVERT(VARCHAR, isnull(@submitted, ''))+' ) | '; ELSE IF @PolNumber5 = @PolNumber SET @message_T = @message_T+@DocName+' ( '+CONVERT(VARCHAR, isnull(@submitted, ''))+' ) | '; SET @PolNumber5 = @PolNumber; FETCH NEXT FROM policyDocs_csr INTO @PolNumber, @PolType, @Eff, @DocName, @Submitted; END; IF @@FETCH_STATUS <> 0 PRINT @message_T; CLOSE policyDocs_csr; DEALLOCATE policyDocs_csr; |
Ya viendo el script de curso usted puede estar de acuerdo con que tiene más líneas de código que la opción PIVOT – por tanto, más líneas de código son necesarias por un Cursor para producir un resultado similar a la Tabla 2 (ese resultado es mostrado en la Figura 7).

Expansión Vertical
Similar a PIVOT, el cursor tiene la capacidad dinámica de adjuntar más filas a medida que nuestro conjunto de datos se expande para incluir más números de políticas, como se muestra en la Figura 7:

Expansión Horizontal
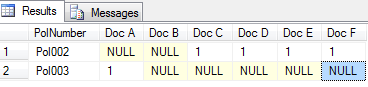
A diferencia de PIVOT, el cursor sobresale en esta área ya que puede expandirse para incluir nuevos documentos añadidos, Doc F, sin alterar el script en la Figura 6.
Análisis del Desempeño
La mayor limitación de transponer filas a columnas usando CURSOR es una desventaja que está enlazada a usar cursores en general – ellos representan un costo significativo. Esto es porque el Cursor genera una consulta separada para cada operación FETCH NEXT – el script en la Figura 6 generó esas 5 consultas como parte del plan de ejecución. En adición a las consultas FETCH NEXT, el CURSOR añadió otra ejecución de consulta para los propósitos de recuperar datos desde el conjunto de datos principal.
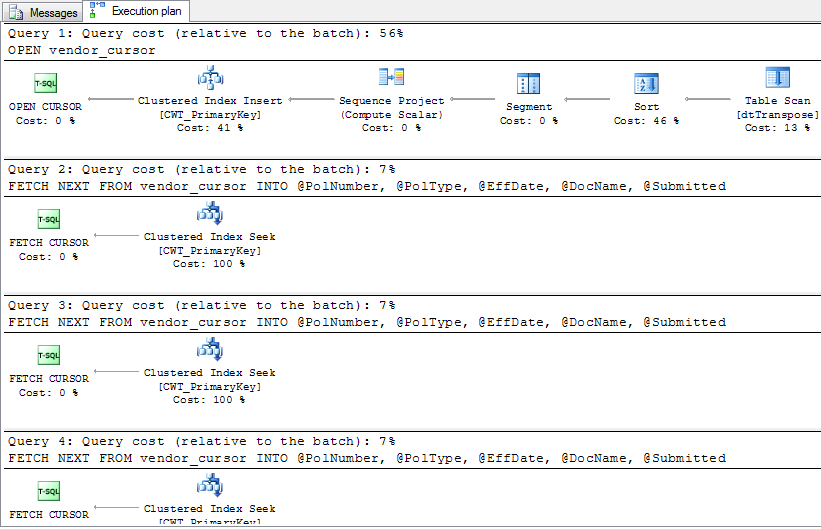
Debido a múltiples consultas generadas por operación FETCH NEXT, no es sorpresa observar (en la Figura 10) que las estadísticas IO del uso de CURSOR fueron ampliamente gastadas en almacenar la salida de las operaciones FETCH NEXT en una tabla interna – Worktable. Recuerde que, con todos sus altos requerimientos de mantenimiento, la versión PIVOT del script nunca almacenó temporalmente datos en Worktables.

Opción #3: XML
La opción XML para transponer filas a columnas es básicamente una versión óptima de PIVOT en que se ocupa de la limitación dinámica de columnas. La versión XML del script se ocupa de esta limitación usando una combinación de XML Path, T-SQL dinámico y algunas funciones integradas (por ejemplo, STUFF, QUOTENAME) como se muestra en la Figura 11.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @cols NVARCHAR(MAX), @query NVARCHAR(MAX); SET @cols = STUFF( ( SELECT DISTINCT ','+QUOTENAME(c.[DocName]) FROM [dbo].[InsuranceClaims] c FOR XML PATH(''), TYPE ).value('.', 'nvarchar(max)'), 1, 1, ''); SET @query = 'SELECT [PolNumber], '+@cols+'from (SELECT [PolNumber], [PolType], [submitted] AS [amount], [DocName] AS [category] FROM [dbo].[InsuranceClaims] )x pivot (max(amount) for category in ('+@cols+')) p'; EXECUTE (@query); |
Expansión Vertical
Similar a PIVOT y CURSOR, las políticas nuevas añadidas pueden ser recuperadas en la versión XML del script sin alterar el script original.
Expansión Horizontal
A diferencia de PIVOT, los documentos nuevos añadidos pueden ser mostrados sin alterar el script.
Análisis del Desempeño
El plan de ejecución en la Figura 13 muestra que tomó 2 consultas transponer nuestros datos – lo cual es una gran mejora comparado con la opción CURSOR.
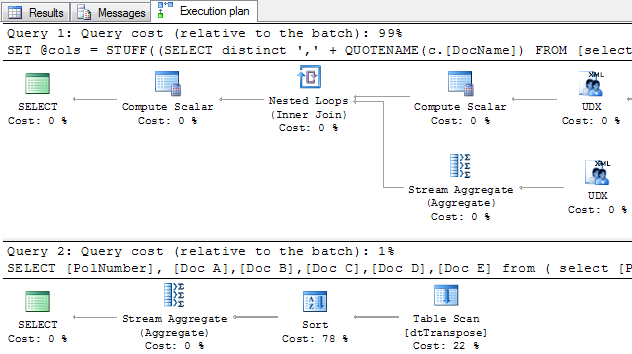
En términos de IO, las estadísticas de la versión XML del script son casi similares a las de PIVOT – la única diferencia es que la versión XML tiene un segundo escaneo de la tabla dtTranspose, pero esta vez desde una lectura lógica – la caché de datos.

Opción #4: SQL Dinámico
Otra alternatica a la opción óptima de XML es transponer las filas a columnas usando puramente SQL dinámico – sin funciones XML. Esta opción utiliza las mismas funciones integradas que son usadas en la versión XML del script como se muestra en la Figura 15.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); SET @columns = N''; SELECT @columns+=N', p.'+QUOTENAME([Name]) FROM ( SELECT [DocName] AS [Name] FROM [dbo].[InsuranceClaims] AS p GROUP BY [DocName] ) AS x; SET @sql = N' SELECT [PolNumber], '+STUFF(@columns, 1, 2, '')+' FROM ( SELECT [PolNumber], [Submitted] AS [Quantity], [DocName] as [Name] FROM [dbo].[InsuranceClaims]) AS j PIVOT (SUM(Quantity) FOR [Name] in ('+STUFF(REPLACE(@columns, ', p.[', ',['), 1, 1, '')+')) AS p;'; EXEC sp_executesql |
Expansión Vertical
Similar a las opciones PIVOT, Cursor y XML, las políticas nuevas añadidas pueden ser recuperadas en la versión XML del script sin alterar el script original.
Expansión Horizontal
Similar a la opción XML, los documentos nuevos añadidos pueden ser mostrados sin alterar el script.
Análisis de Desempeño
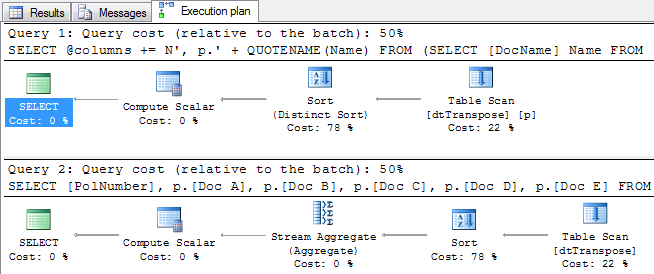
Similar a la opción XML, el plan de ejecución en el script de SQL Dinámico usa dos consultas para retornar la salida. De todas maneras, a diferencia de la versión XML del script, la distribución de la carga de trabajo en la opción de SQL Dinámico es compartida equitativamente entre las dos consultas.
Conclusión
En este artículo echamos un vistazo a las opciones disponibles para transponer filas a columnas en T-SQL. La opción PIVOT se mostró como la más simple, con un plan de consultas menos caro, pero sus capacidades estaban limitadas cuando se trataba de ocuparse de la expansión dinámica de columnas. Luego vimos a CURSOR como una opción posible para transponer filas a columnas y nos dimos cuenta de que se ocupa de todas las limitaciones encontradas en PIVOT, aunque su habilidad para generar diferentes planes de consultas para cada operación FETCH NEXT era su propia desventaja de desempeño. Finalmente, las opciones XML y SQL Dinámico provaron ser las mejores opciones óptimas en términos de transponer filas a columnas con resultados de desempeño favorables y un manejo efectivo de expansiones verticales y horizontales.
Referencias:
Worktables
Statistics
Using PIVOT and UNPIVOT

Él es un miembro del Grupo de Usuarios de SQL de Johannesburgo y tiene un grado de maestría en MCom IT Management de la Universidad de Johannesburgo.
Actualmente, él trabaja para Sambe Consulting como Consultor principal.
Ver todas las publicaciones de Sifiso W. Ndlovu
- Entendiendo el Impacto de las sugerencias NOLOCK y WITH NOLOCK en SQL Server - May 28, 2018
- Cómo reemplazar caracteres especiales ASCII en SQL Server - May 25, 2018
- Convertir resultados de SQL Server a JSON - June 2, 2017