
Resumen del manejo de errores
El manejo de los errores en el SQL Server nos da un control sobre el código Transact-SQL. Por ejemplo, cuando las cosas van mal, nosotros tenemos la oportunidad de hacer algo al respecto y probablemente poder hacerlo de nuevo. El manejo de errores de SQL Server puede ser tan fácil como simplemente registrar que algo sucedió o podríamos ser nosotros intentando poder corregir un error. Incluso se puede estar traduciendo el error al lenguaje SQL, ya que todos nosotros sabemos cómo los mensajes de error técnicos de SQL Server podrían no tener sentido y ser difíciles de entender. Pero afortunadamente, nosotros tenemos la oportunidad de poder traducir esos mensajes y convertirlos en algo más significativo para transmitir a los usuarios, desarrolladores, etc.
En este artículo, nosotros vamos a analizar más de cerca la instrucción TRY…CATCH la sintaxis, su aspecto, su funcionamiento y lo que se puede hacer cuando se produce un error. A parte de eso, el método se explicará en un caso de SQL Server utilizando un grupo de sentencias / bloques T-SQL, que es simplemente la forma en que SQL Server maneja los errores. Esta es una manera muy sencilla pero estructurada de hacerlo, y una vez que aprendas como hacerlo, puede ser bastante útil en muchos casos.
Adicionalmente de eso, hay la función RAISERROR que se puede utilizar para poder generar nuestros propios mensajes de error personalizados, que es una excelente forma de traducir los mensajes de error confusos en algo un poco más significativo que la gente pueda entender.
Manejando errores usando TRY… CATCH
Así es como se ve la sintaxis. Es muy simple aprender a usarla. Tenemos dos bloques de código:
|
1 2 3 4 5 6 7 |
BEGIN TRY --code to try END TRY BEGIN CATCH --code to run if error occurs --is generated in try END CATCH |
Cualquier cosa entre BEGIN TRY y END TRY es el código que queremos monitorear para detectar un error. Entonces, si se hubiera producido un error dentro de esta sentencia TRY, el control se habría transferido inmediatamente a la instrucción CATCH y luego habría empezado a ejecutar el código línea por línea.
Ya mismo, dentro de la declaración CATCH, nosotros podemos tratar de corregir el error, informar el error o incluso poder registrar el error para saber cuándo ocurrió, quién lo hizo al registrar el nombre de usuario, todo lo que es útil. Además tenemos acceso a algunos datos especiales que solo están disponibles dentro de la declaración CATCH:
- ERROR_NUMBER – Devuelve el número interno del error
- ERROR_STATE – Devuelve la información sobre la fuente
- ERROR_SEVERITY – Devuelve la información sobre cualquier cosa, desde errores informativos hasta errores que el usuario de DBA puede corregir, etc.
- ERROR_LINE – Devuelve el número de línea en el que ocurrió un error
- ERROR_PROCEDURE – Devuelve el nombre del procedimiento almacenado o la función
- ERROR_MESSAGE – Devuelve la información más esencial y ese es el mensaje de texto del error
Eso es todo lo que se requiere cuando se trata acerca del manejo de errores de SQL Server. Todo se puede realizar con una simple instrucción TRY y CATCH y la única parte cuando puede tornar difícil es cuando estamos lidiando con transacciones. ¿Por qué? Es que, si hay un COMIENZO DE TRANSACCIÓN, siempre debe terminar con una transacción COMPROMISO o ROLLBACK. El problema es si se genera un error después de que comencemos, pero antes de confirmar o revertir. En este caso peculiar, existe una función especial que se puede usar en la declaración CATCH que permite verificar si una transacción está en un estado comprometible o no, lo que nos permite tomar la decisión de revertir o cometerla.
Vayamos a SQL Server Management Studio (SSMS) y empecemos con los conceptos básicos de cómo manejar los errores de SQL Server. La base de datos de ejemplo AdventureWorks 2014 se usara a través del artículo. El script a continuación es tan simple como es:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
USE AdventureWorks2014 GO -- Basic example of TRY...CATCH BEGIN TRY -- Generate a divide-by-zero error SELECT 1 / 0 AS Error; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_STATE() AS ErrorState, ERROR_SEVERITY() AS ErrorSeverity, ERROR_PROCEDURE() AS ErrorProcedure, ERROR_LINE() AS ErrorLine, ERROR_MESSAGE() AS ErrorMessage; END CATCH; GO |
Es un ejemplo de cómo se ve y cómo puede funcionar. Lo que estamos haciendo en BEGIN TRY es dividir 1 por 0, lo que, por supuesto, puede causar un error. Por lo tanto, tan pronto como ese bloque de código sea alcanzado, transferirá el control al bloque CATCH y luego seleccionará todas las propiedades utilizando las funciones integradas que vimos anteriormente. Si ejecutamos el script desde arriba, esto es lo que obtenemos:
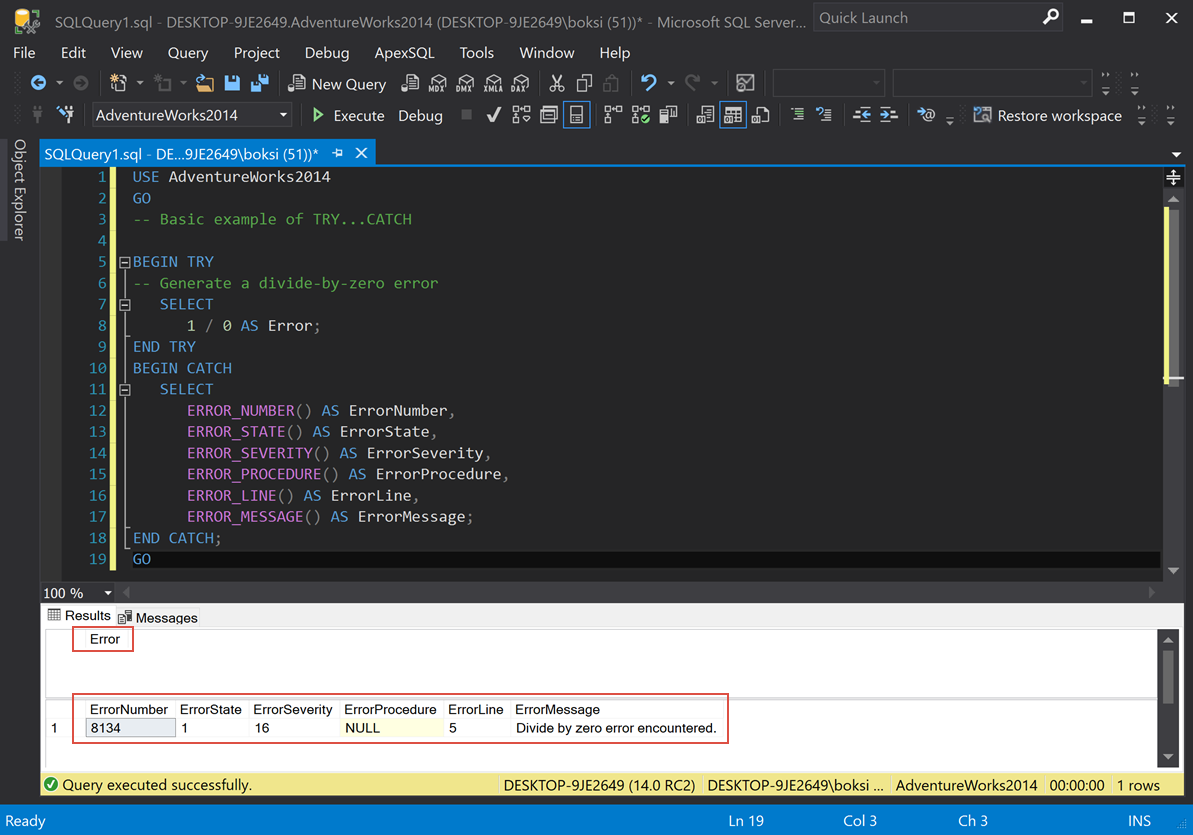
Generamos dos cuadrículas de resultados debido a dos instrucciones SELECT: la primera es 1 dividida por 0, lo que causa el error y la segunda es el control transferido que realmente nos dio algunos resultados. De izquierda a derecha, tenemos ErrorNumber, ErrorState, ErrorSeverity, no hay ningún procedimiento en este caso (NULL), ErrorLine y ErrorMessage.
Ahora, realicemos algo un poco más significativo. Es una buena idea poder hacer un seguimiento de estos errores. Las cosas que son propensas a errores deben ser capturadas de todos modos y al menos registradas. Además, puede poner desencadenadores en estas tablas registradas e incluso configurar una cuenta de correo electrónico y obtener un poco de creatividad para notificar a las personas cuando se produce un error.
Si no estás familiarizado con la base de datos del correo electrónico, consulte este artículo para obtener más información sobre el sistema de correo electrónico: Cómo configurar la base de datos del correo electrónico en SQL Server
La siguiente secuencia de comandos crea una tabla llamada DB_Errors que se puede usar para poder almacenar datos de seguimiento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- Table to record errors CREATE TABLE DB_Errors (ErrorID INT IDENTITY(1, 1), UserName VARCHAR(100), ErrorNumber INT, ErrorState INT, ErrorSeverity INT, ErrorLine INT, ErrorProcedure VARCHAR(MAX), ErrorMessage VARCHAR(MAX), ErrorDateTime DATETIME) GO |
Tenemos una columna de identidad simple, seguida de un nombre de usuario para saber quién generó el error y el resto es simplemente la información exacta de las funciones integradas que enumeramos anteriormente.
Entonces, empecemos a modificar un procedimiento almacenado personalizado de la base de datos y pongamos un manejador de errores allí:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
ALTER PROCEDURE dbo.AddSale @employeeid INT, @productid INT, @quantity SMALLINT, @saleid UNIQUEIDENTIFIER OUTPUT AS SET @saleid = NEWID() BEGIN TRY INSERT INTO Sales.Sales SELECT @saleid, @productid, @employeeid, @quantity END TRY BEGIN CATCH INSERT INTO dbo.DB_Errors VALUES (SUSER_SNAME(), ERROR_NUMBER(), ERROR_STATE(), ERROR_SEVERITY(), ERROR_LINE(), ERROR_PROCEDURE(), ERROR_MESSAGE(), GETDATE()); END CATCH GO |
La modificación de este procedimiento almacenado simplemente envuelve el manejo de errores en este caso alrededor de la única declaración dentro del procedimiento almacenado. Si llamamos a este procedimiento almacenado y pasamos algunos datos válidos, esto es lo que sucede:
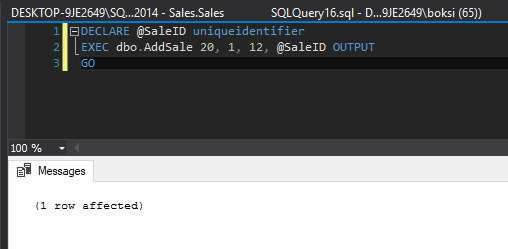
Una declaración de selección rápida indica que el registro se ha insertado de forma correcta:
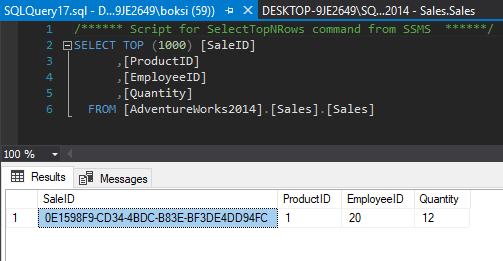
Entonces, si llamamos al procedimiento almacenado anterior una vez más, pasando los mismos parámetros, la cuadrícula de resultados se llenará de manera diferente:
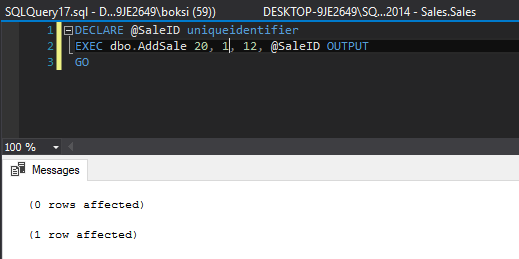
Esta vez, tenemos dos indicadores en la cuadrícula de resultados:
0 filas afectadas – esta línea indica que en realidad no entró nada en la tabla de ventas
1 fila afectada – esta línea indica que algo entró en nuestra tabla de registro recién creada
Ahora, lo que podemos hacer aquí es mirar la tabla de errores y ver qué sucedió. Una simple sentencia Select realizara el trabajo:
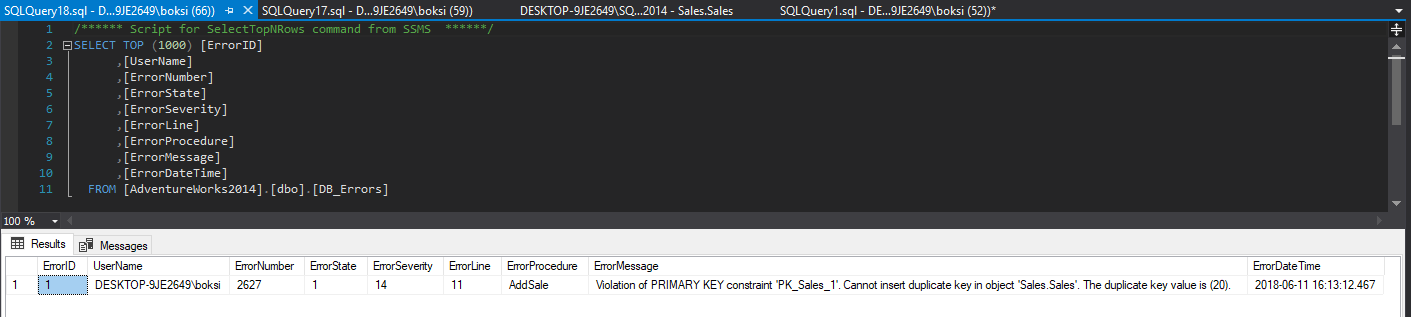
Tenemos toda la información que establecimos previamente para que se registre, solo que esta vez también completamos el campo del procedimiento y, Claro, el mensaje técnico “amigable” de SQL Server de que tenemos una infracción:
Violación de la restricción PRIMARY KEY ‘PK_Sales_1’. No se puede insertar una clave duplicada en el objeto ‘Ventas. Ventas’. El valor de la clave duplicada es (20).
Este fue un ejemplo muy artificial, pero el punto es que, en el mundo real, poner una fecha inválida es muy común. Por ejemplo, pasar una ID de empleado que no existe en un caso cuando tenemos una clave externa configurada entre la tabla de Ventas y la tabla de Empleados, lo que quiere decir es que el Empleado debe existir para crear un nuevo registro en la tabla de Ventas. Este caso de uso causará una violación de la restricción de clave externa.
La idea general detrás de esto es no hacer desaparecer el error. Al menos queremos informar a una persona que algo salió mal y luego también registrarlo. En el mundo real, si hubiera una aplicación que se basara en un procedimiento almacenado, los desarrolladores probablemente tendrían el manejo del error de SQL Server codificado en algún lugar, también porque podría saber cuándo ocurrió un error. Aquí también es donde sería una buena idea devolver un error al usuario/aplicación. Esto se puede hacer agregando la función RAISERROR para que podamos enviar nuestra propia versión del error.
Por ejemplo, si nosotros sabemos que es más probable que ocurra una identificación de empleado que no existe, entonces podemos hacer una búsqueda. Esta búsqueda puede verificar si el ID de empleado existe y si no, esta arroja el error exacto de que ocurrió. O en el peor de los casos, si tuviéramos un error inesperado de no tener idea de lo que era, entonces podemos devolver lo que era antes.
Generando errores personalizados
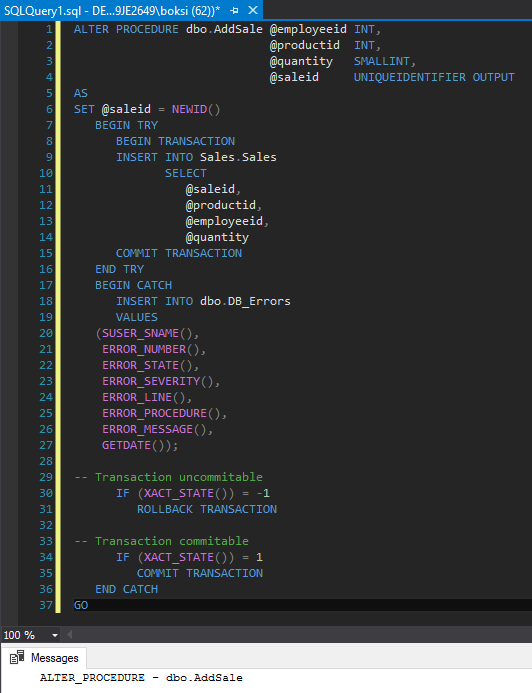
Nosotros solo mencionamos de forma breve la parte delicada de las transacciones, así que aquí hay un ejemplo simple de cómo tratarlas. Podemos utilizar el mismo procedimiento que antes, solo que esta vez envolvemos una transacción alrededor de la declaración Insertar:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
ALTER PROCEDURE dbo.AddSale @employeeid INT, @productid INT, @quantity SMALLINT, @saleid UNIQUEIDENTIFIER OUTPUT AS SET @saleid = NEWID() BEGIN TRY BEGIN TRANSACTION INSERT INTO Sales.Sales SELECT @saleid, @productid, @employeeid, @quantity COMMIT TRANSACTION END TRY BEGIN CATCH INSERT INTO dbo.DB_Errors VALUES (SUSER_SNAME(), ERROR_NUMBER(), ERROR_STATE(), ERROR_SEVERITY(), ERROR_LINE(), ERROR_PROCEDURE(), ERROR_MESSAGE(), GETDATE()); -- Transaction uncommittable IF (XACT_STATE()) = -1 ROLLBACK TRANSACTION -- Transaction committable IF (XACT_STATE()) = 1 COMMIT TRANSACTION END CATCH GO |
Entonces, si todo esto se ejecuta correctamente dentro de la transacción Begin, podrá insertar un registro en Ventas y luego lo confirmará. Pero si algo sale mal antes de que se lleve a cabo el Compromiso y transfiere el control a nuestras Capturas, la pregunta es: ¿cómo sabemos si lo realizamos o revertimos todo?
Si el error no es grave y está en un estado comprometible, todavía nosotros podemos realizar la transacción. Pero si algo salió mal y está en un estado no comprometible, entonces podemos revertir la transacción. Esto se puede hacer simplemente ejecutando y analizando la función XACT_STATE que informa del estado de la transacción.
Esta función devuelve uno de los siguientes tres valores:
1 – la transacción es comprometible
-1 – la transacción no se puede comprometer y se debe revertir
0 – no hay transacciones pendientes
Lo que importa aquí es recordar hacer esto en realidad dentro de la sentencia de la captura porque no desea iniciar transacciones y luego no confirmarlas o deshacerlas:
Por lo tanto, si ejecutamos el mismo procedimiento de almacenado proporcionando, como por ejemplo. EmployeeID no válido, llegaremos a obtener los mismos errores que antes generados de adentro hacia afuera de la tabla:
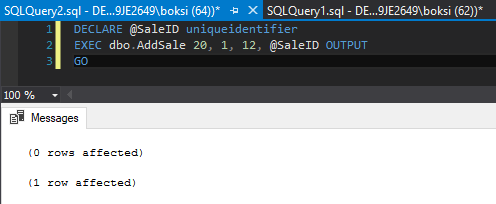
La forma en que podemos decir que esto no se insertó es mediante la ejecución de una consulta Select simple, seleccionando todo desde la tabla de ventas donde EmployeeID es 20:
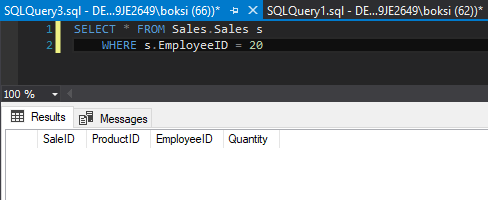
Para finalizar, veamos cómo podríamos crear nuestros propios mensajes personalizados de error. Esto es muy bueno cuando sabemos que existe una posible situación que podría ocurrir. Como mencionamos anteriormente, es factible que alguien pase una identificación de empleado no válida. En este caso particular, podemos hacer una verificación antes de esa fecha y, por supuesto, cuando esto suceda, podemos generar nuestro propio mensaje personalizado, ya que la identificación del empleado que no existe. Esto se puede hacer fácilmente modificando nuestro procedimiento almacenado una vez más y añadiendo la búsqueda en nuestro bloque de Prueba:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
ALTER PROCEDURE dbo.AddSale @employeeid INT, @productid INT, @quantity SMALLINT, @saleid UNIQUEIDENTIFIER OUTPUT AS SET @saleid = NEWID() BEGIN TRY IF (SELECT COUNT(*) FROM HumanResources.Employee e WHERE employeeid = @employeeid) = 0 RAISEERROR ('EmployeeID does not exist.', 11, 1) INSERT INTO Sales.Sales SELECT @saleid, @productid, @employeeid, @quantity END TRY BEGIN CATCH INSERT INTO dbo.DB_Errors VALUES (SUSER_SNAME(), ERROR_NUMBER(), ERROR_STATE(), ERROR_SEVERITY(), ERROR_LINE(), ERROR_PROCEDURE(), ERROR_MESSAGE(), GETDATE()); DECLARE @Message varchar(MAX) = ERROR_MESSAGE(), @Severity int = ERROR_SEVERITY(), @State smallint = ERROR_STATE() RAISEERROR (@Message, @Severity, @State) END CATCH GO |
Si este recuento vuelve a cero, eso quiere decir que el empleado con esa identificación no existe. Luego podemos usar el RAISERROR donde realizamos un mensaje definido por el usuario y además nuestra severidad y nuestro estado de costumbre. Si este recuento vuelve a cero, eso significa que el empleado con esa identificación no existe. Luego podemos llamar a RAISERROR donde definimos un mensaje definido por el usuario y, además, nuestra gravedad y estado personalizados. Entonces, sería mucho más fácil para alguien que usa este procedimiento almacenado entender cuál es el problema, en lugar de ver el mensaje de error muy técnico que arroja SQL, en este caso, sobre la validación de la clave externa.
Con estos últimos cambios en nuestro procedimiento de tienda, también hay otro RAISERROR en el bloque de captura. Si se generó otro error, en lugar de que se pierda, podemos volver a usar al RAISERROR y devolver exactamente lo que sucedió. Es por eso que hemos declarado todas las variables y los resultados de todas las funciones. De esta manera, no solo se registrará sino que también se informará a la aplicación o al usuario.
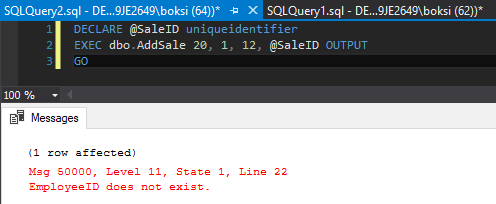
Y ahora, si ejecutamos el mismo código desde antes, ambos se registrarán y también indicarán que la identificación del empleado no existe:
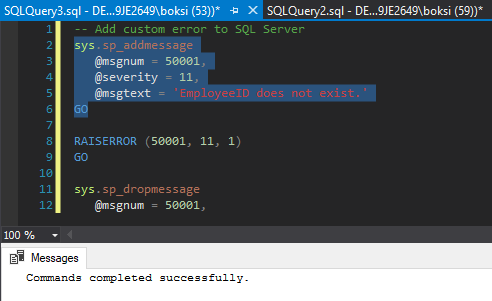
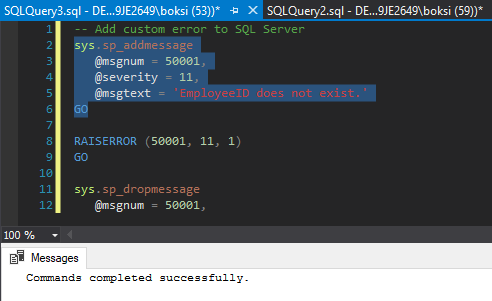
Adicionalmente, otra cosa que vale la pena mencionar es que podemos predefinir este código de mensaje de error, la gravedad y el estado. Existe un procedimiento almacenado llamado sp_addmessage que se utiliza para añadir nuestros propios mensajes de error. Esto es bastante útil cuando necesitamos realizar el mensaje en múltiples lugares, solo podemos utilizar RAISERROR y pasar el número del mensaje en lugar de que tengamos que volver a escribir las cosas de nuevo. Al ejecutar el código seleccionado desde abajo, luego agregamos este error a SQL Server:
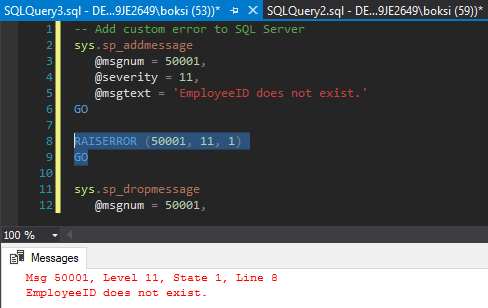
Esto quiere decir que ahora, en lugar de hacerlo como lo hicimos anteriormente, podemos usar al RAISERROR y pasar el número de error y así es como se ve:
El mensaje sp_dropmessage se usa, por lo general, para quitar un mensaje de error definido por el usuario específico. También podemos ver que todos los mensajes en SQL Server están ejecutando la consulta desde abajo:
|
1 |
SELECT * FROM master.dbo.sysmessages |
Hay muchos de ellos y puedes ver los personalizados en la parte superior.
Deseo que este artículo te haya sido informativo y les agradezco que lo haya leído.
Referencias

He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
View all posts by Bojan Petrovic