
Introducción
En charlas pasadas dimos un vistazo a la miríada de diferentes técnicas de inteligencia de negocios que uno puede utilizar para convertir los datos en información. En la “reunión” de hoy vamos a tratar de juntar todas estas técnicas, racionalizar nuestros planes de desarrollo y más vistazos generales a algunos buenos hábitos a adoptar o, para usar mejores palabras, utilizar los Procedimientos Recomendados de SQL Server Reporting Services.
Durante la discusión de hoy, estaremos tocando los siguientes temas:
- Discutir los pros y contras de utilizar bases de datos compartidas.
- Los ‘pluses’ y las trampas de utilizar reportes incrustados.
- Registro de utilización de reportes.
- Utilización de gráficos.
- Almacenar los datos en la caché.
¡Así que comencemos!
Utilización de datasets (compartido versus incrustado)
Para refrescar nuestras mentes acerca de qué es un dataset, prefiero utilizar una metáfora.
Al ‘adjuntar’ cualquier reporte a los datos desde la base de datos, uno requiere dos componentes críticos.
- Una fuente de datos
- Un conjunto de datos
Imagine que tenemos una casa (nuestra base de datos) que tiene un grifo de agua externo. Este grifo externo será usado para dar agua a cinco plantas de casa a 20m desde la casa. Lo que realmente necesitamos es una manguera de agua (fuente de datos) para obtener agua para las plantas. Las cinco plantas en macetas (datasets) son regadas con el agua de la manguera. Los datasets proveen datos para nuestros reportes, gráficos y matrices y estos datasets son poblados en tiempo de ejecución.
Hay dos maneras de que nuestras plantas sean regadas. Lleno cada maceta separadamente (cree cinco datasets locales o incrustados) o utilizo un gran cubo y lleno cada maceta desde el gran cubo (datasets compartidos). Los datasets compartidos son datasets globales y pueden ser utilizados para todos los reportes dentro del proyecto. Los datasets locales o incrustados están disponibles exclusivamente para el reporte actual.
Para decidir qué método de almacenaje de datos es el más óptimo (para nuestras necesidades actuales), tenemos que ver un escenario donde ambos son utilizados y luego preguntarnos algunas preguntas importantes.
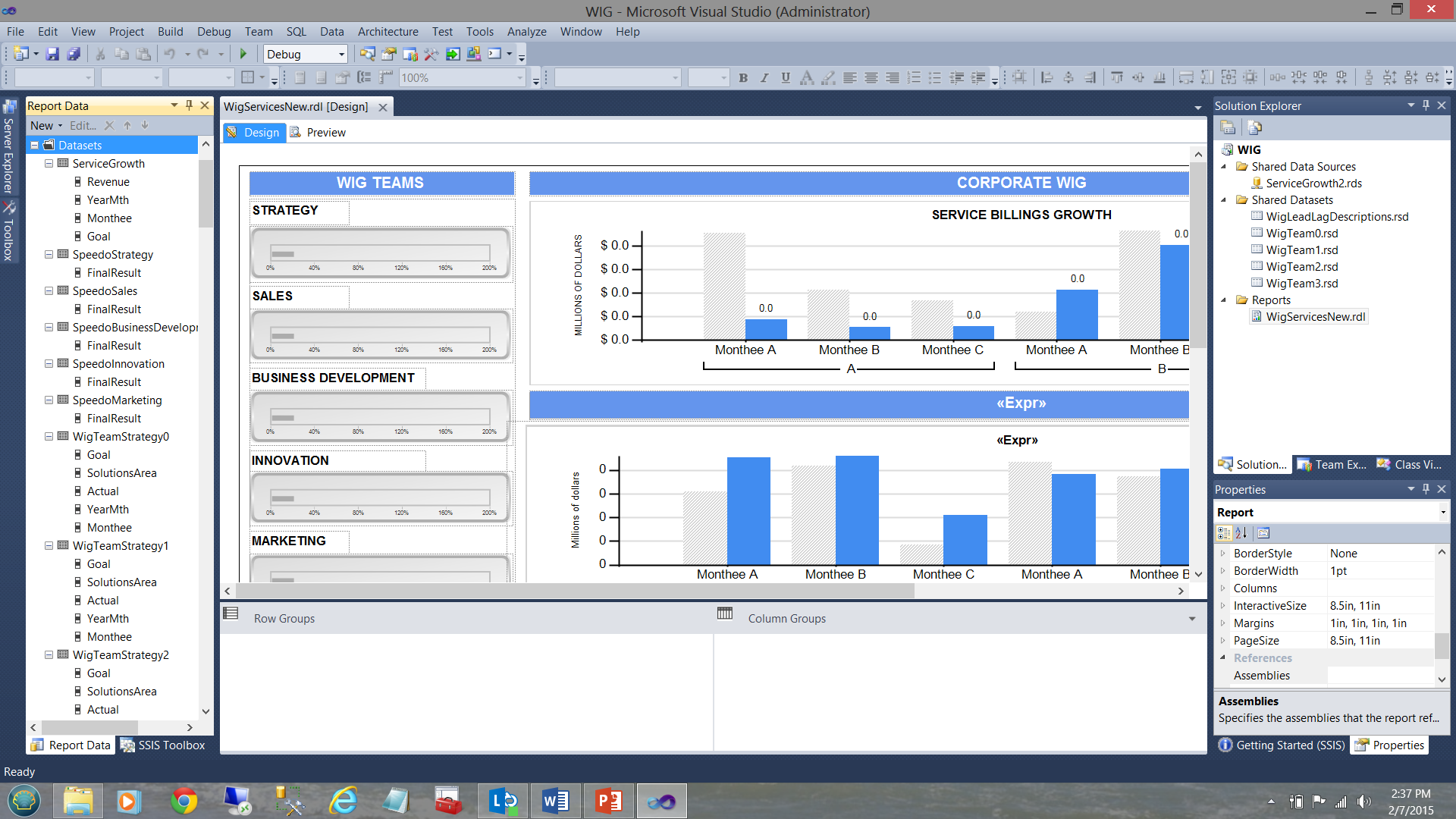
En la captura de pantalla abajo, vemos un reporte típico (creado para un usuario) que muestra las metas y resultados de desempeño variados para un periodo de tiempo.
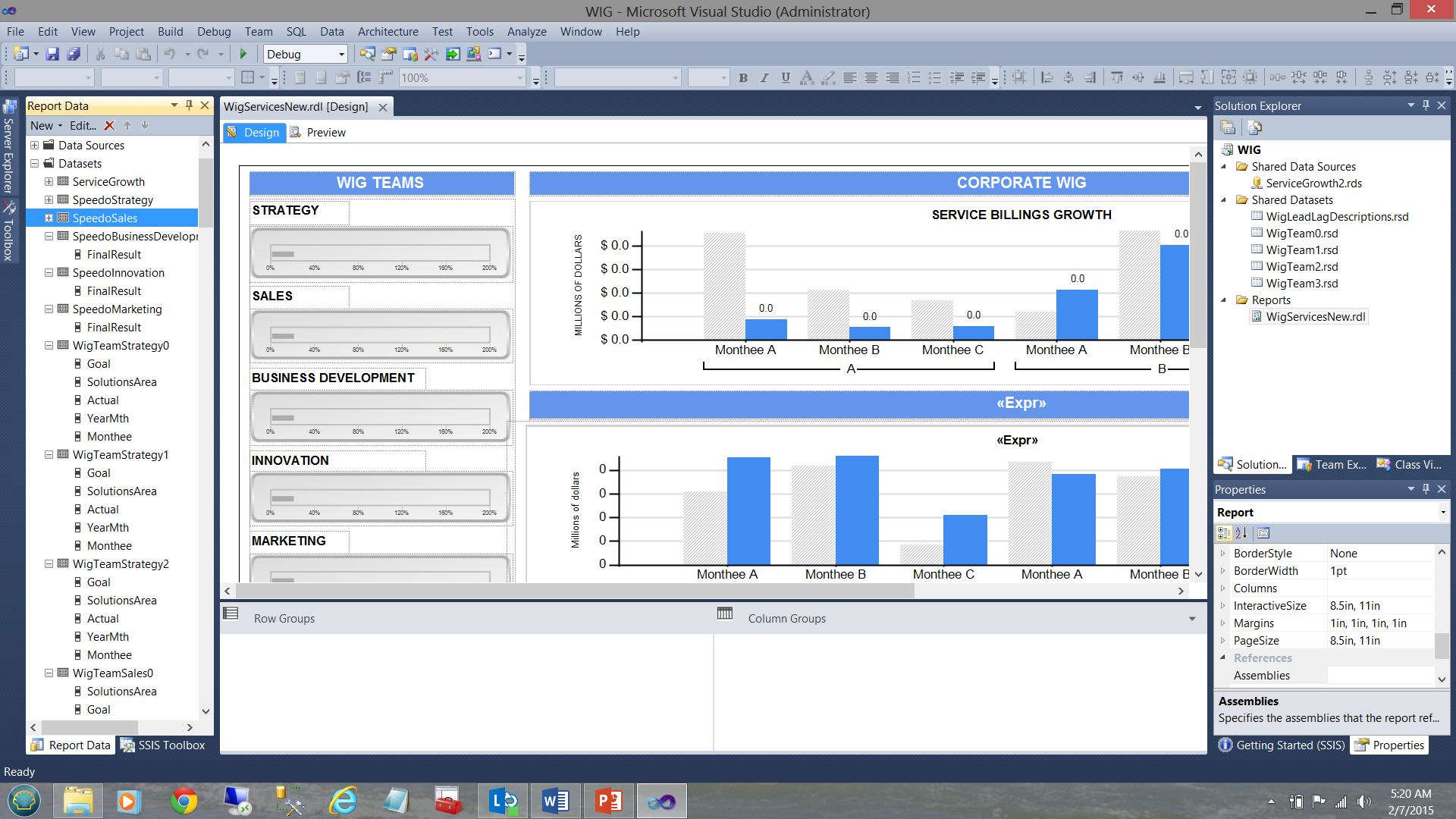
Un WIG (vea el término en la captura de pantalla anterior) es una “widly important goal (meta terriblemente importante)”.
Note que tenemos cinco datasets compartidos en la parte superior derecha de la captura de pantalla. Note también los datasets en la ventana “Report Data” en la parte izquierda de la captura de pantalla. El truco es entender cómo encajan las piezas. Armados con este conocimiento, podemos tomar algunas decisiones inteligentes, como qué tipo de dataset debería ser utilizado para cada uno de nuestros gráficos mostrados en la captura de pantalla anterior.
Abajo vemos una fuente de datos creada para aprovechar datos desde la base de datos WIG.
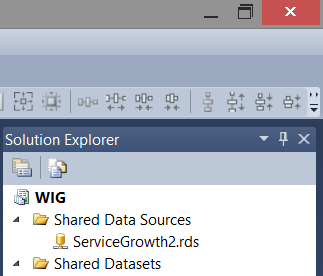
La información de conexión es almacenada dentro de la fuente de datos (ver abajo).
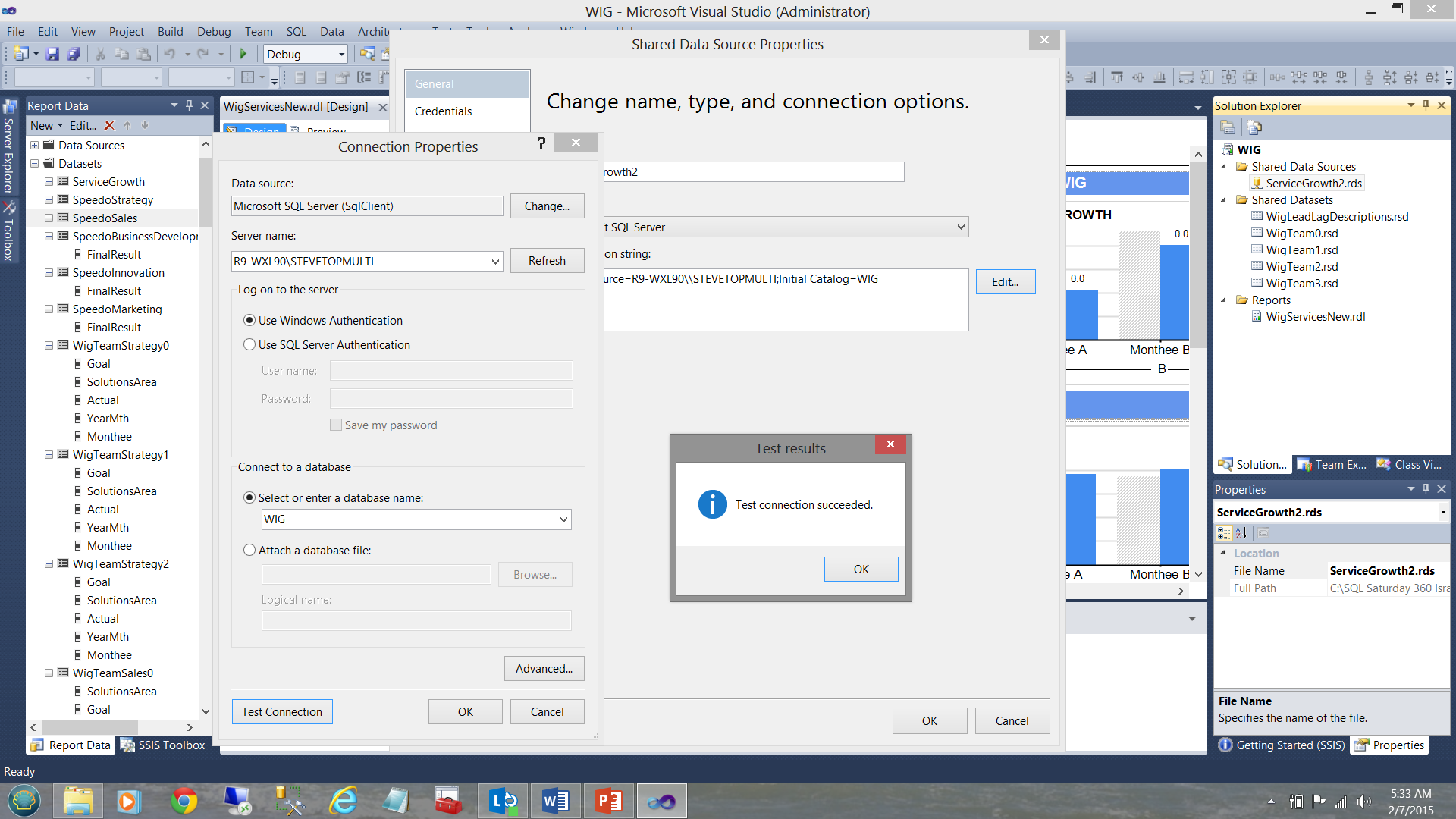
Nuestro dataset compartido “WigLeadLagDescriptions” (ver arriba y a la parte superior derecha debajo de la Carpeta “Shared Datasets”) está conectado (“lleno”) por nuestra fuente de datos “ServiceGrowth2” (ver abajo).
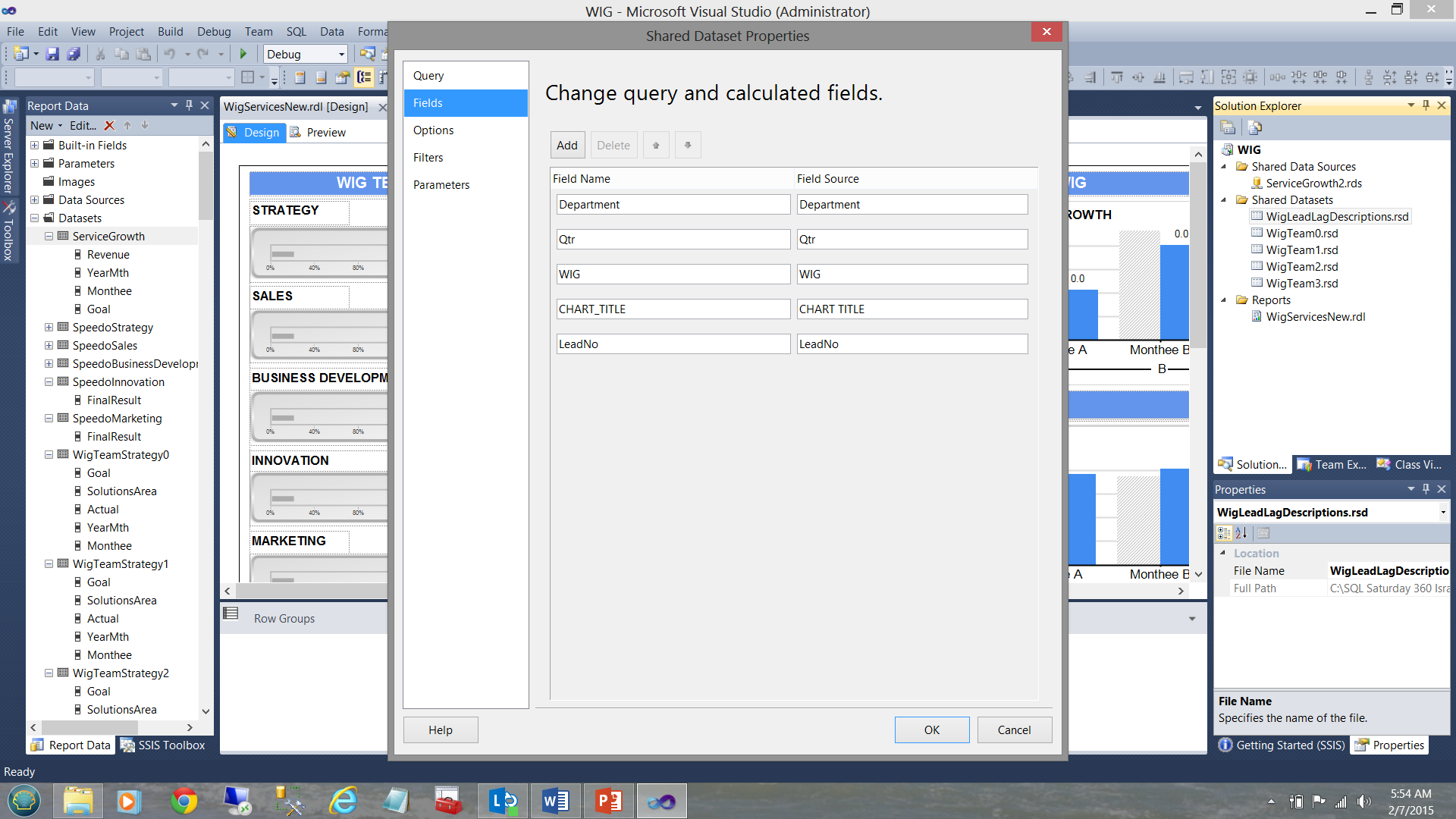
Finalmente, nuestro dataset local/incrustado “DescriptionStrategy” (ver abajo a la izquierda) deriva sus datos desde el dataset compartido “WigLeadLagDescription” (ver abajo a la parte superior derecha).
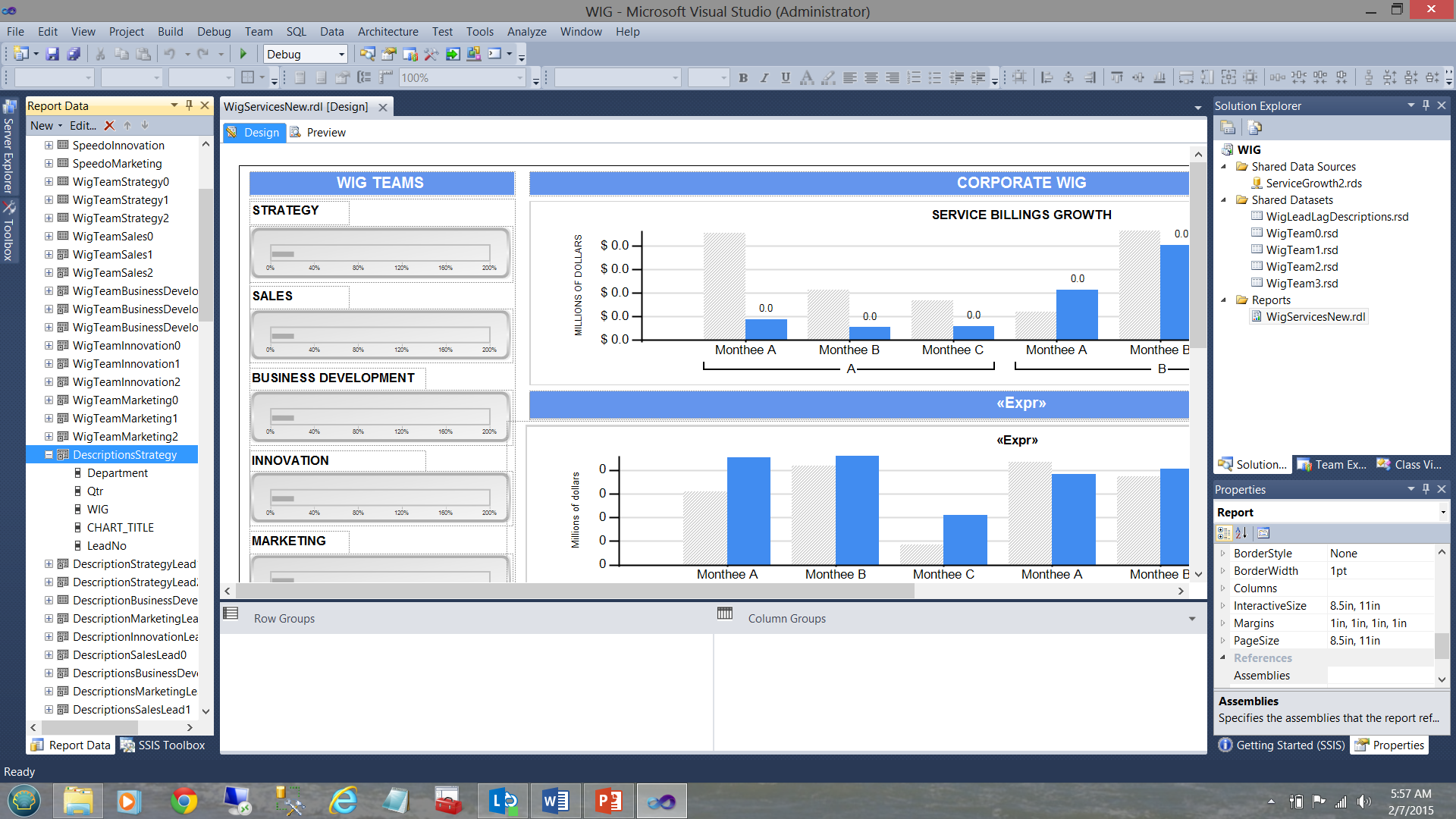
Ahora, como este dataset local es exclusivamente utilizados por los gráficos del equipo Strategy y como los datos en el dataset compartido contienen las descripciones para todos los departamentos, necesitamos aplicar el filtro al dataset local para asegurarnos de que los únicos datos dentro de ese dataset están relacionados solamente a Strategy. Esto fue logrado como sigue:
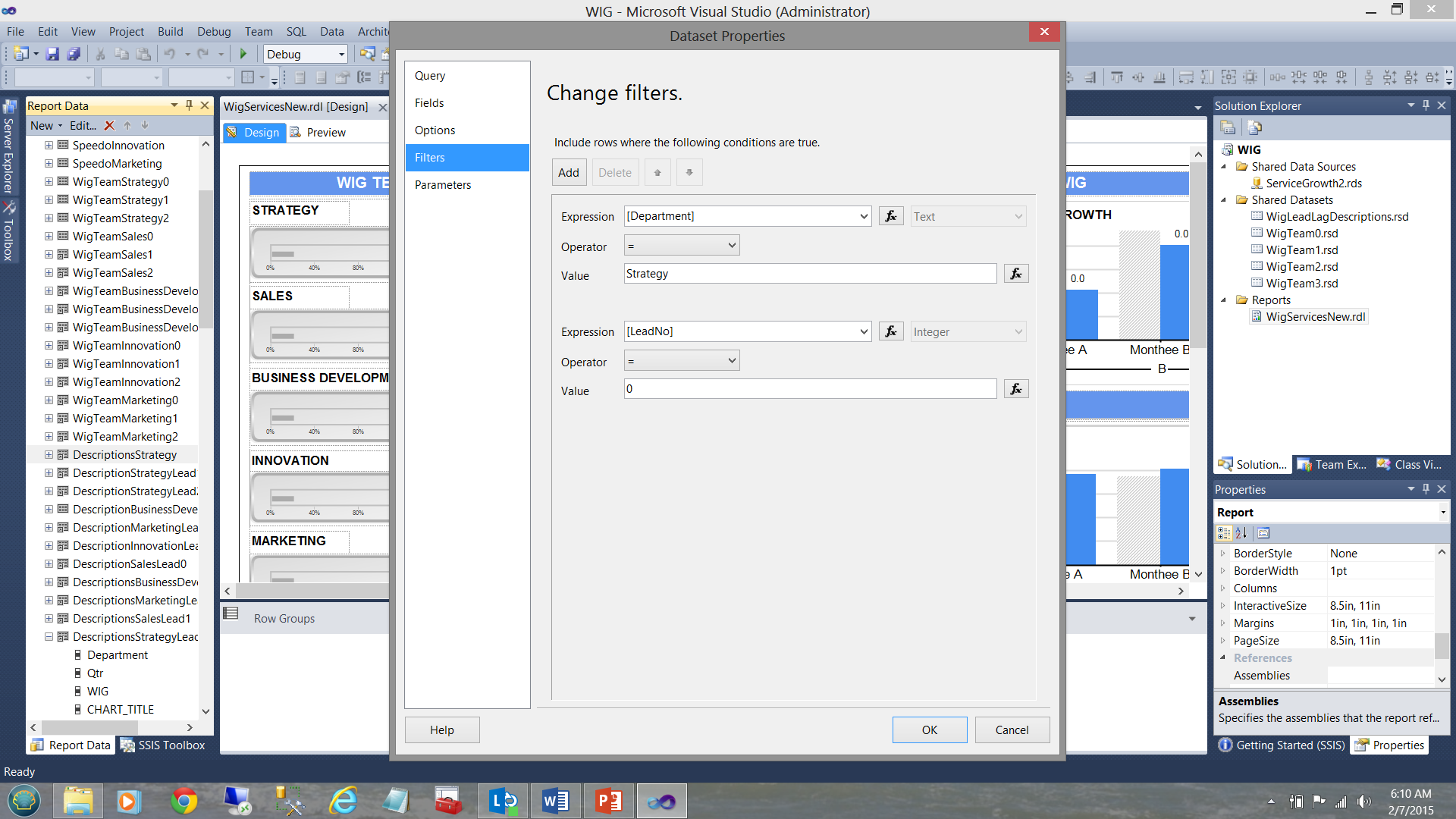
Alejándonos un poco de toda esta confusión, así es como la distribución de datos fue organizada viéndolo desde arriba.
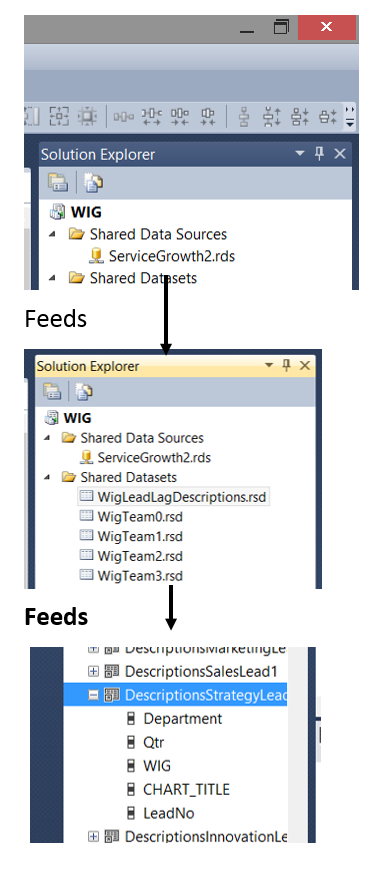
En resumen, cada dataset local o “incrustado” contendrá un subconjunto del dataset compartido. Este subconjunto es obtenido FILTRANDO los datos obtenidos desde el conjunto de datos compartido. Esto es logrado colocando una restricción de filtro en la definición del dataset local (ver abajo).
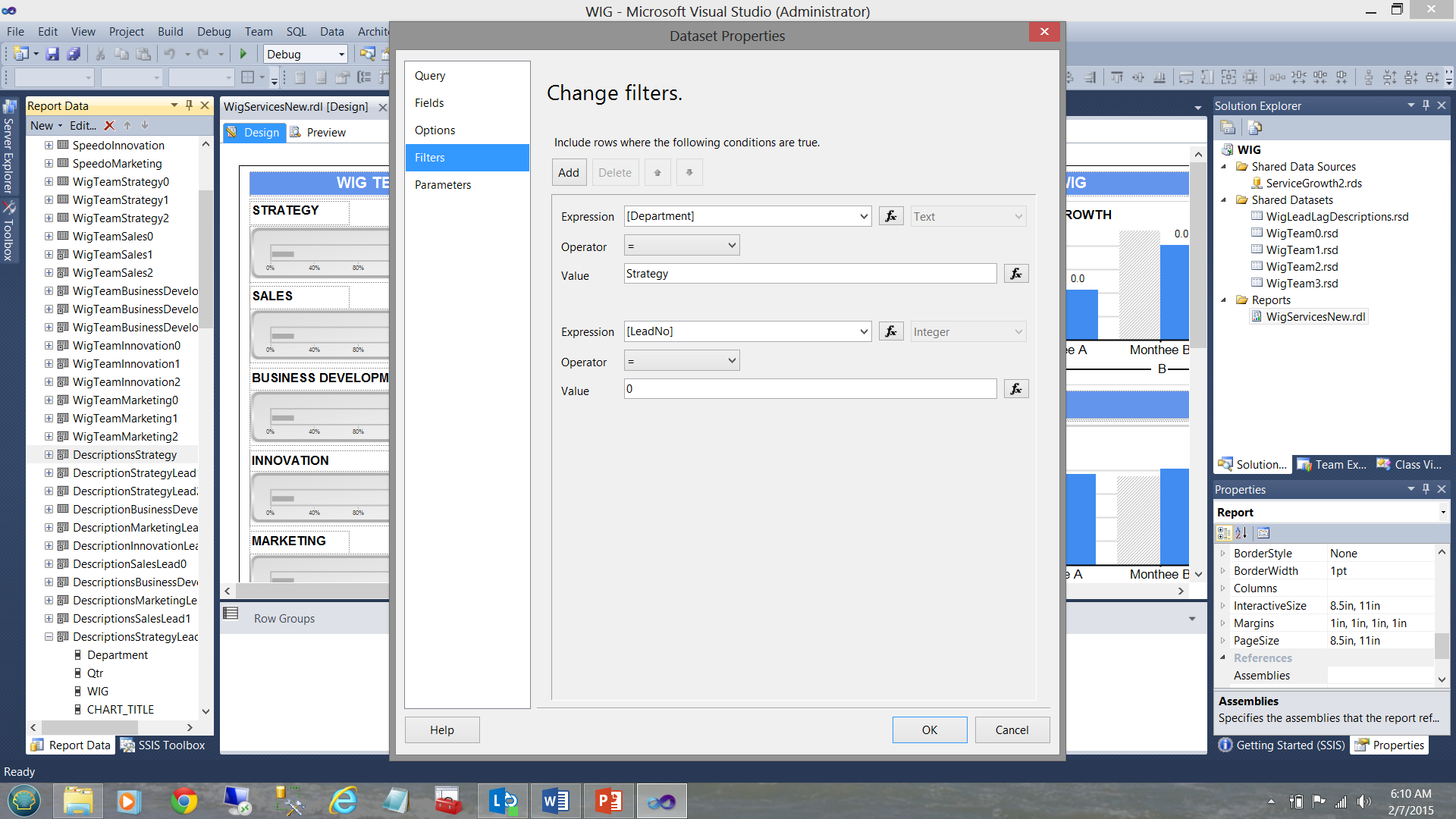
Así que, ¿cómo decidimos qué tipo de dataset es apropiado? Mucho dependen de cuántos datos serán obtenidos y de si USTED LO REQUIERE todo para cada gráfico y/o matriz dentro del reporte.
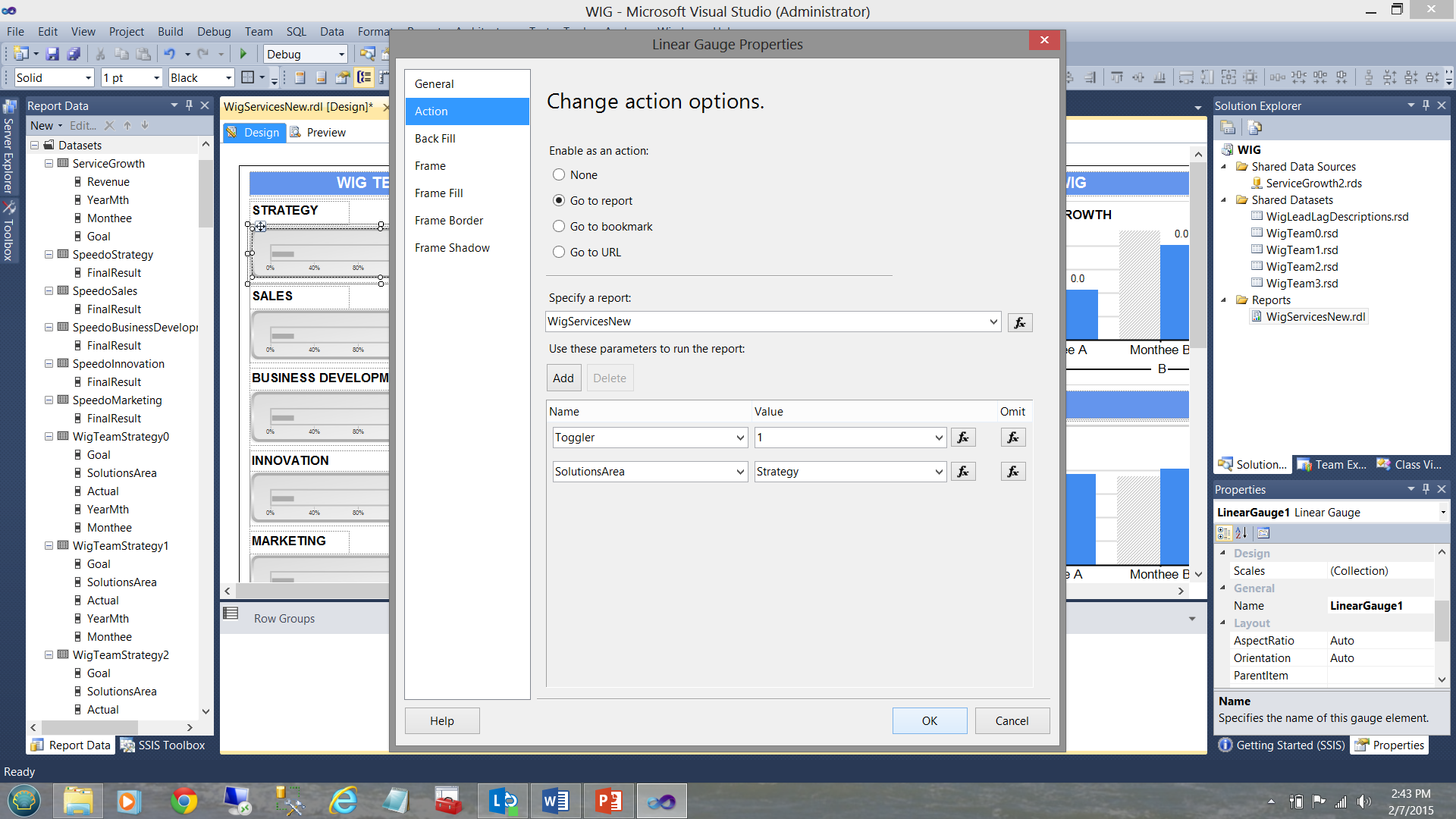
Lo que no he revelado hasta ahora es que las estimaciones horizontales del equipo WIG (ver abajo) tienen una ‘acción’ adjunta a ellas.
Hacer clic en una de estas estimaciones horizontales resulta en una llamada recursiva al mismo reporte y pasa un valor entero al reporte. Si hacemos clic en la estimación Strategy (ver abajo), el mismo reporte es llamado y un valor de 1 es dado a la variable llamada “Toggler” y el nombre del área de soluciones es también pasado vía la variable SolutionsArea (ver abajo).
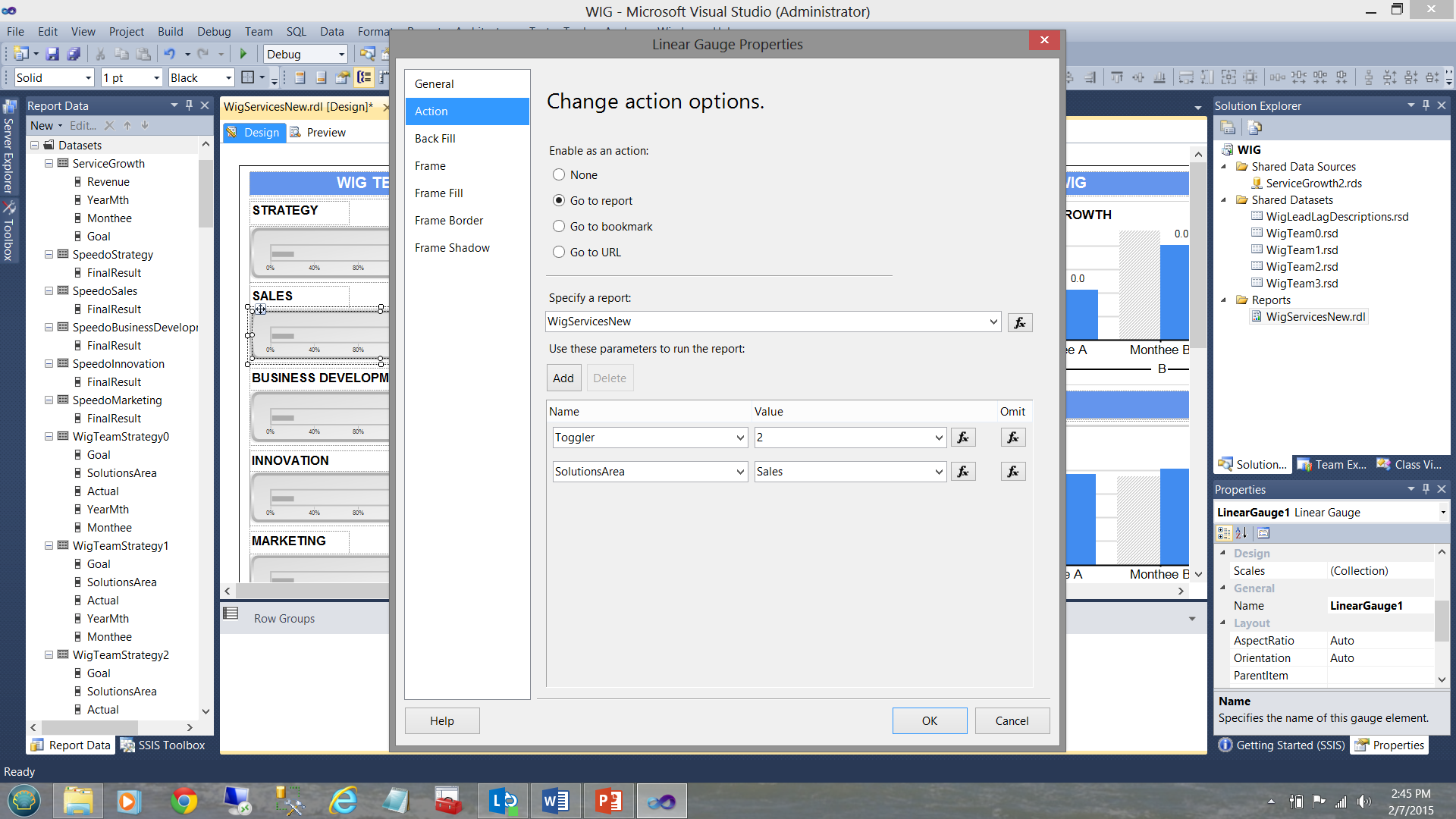
Si hacemos clic en la estimación horizontal “Sales”, una vez más una llamada recursiva es ejecutada. De todos modos, esta vez “Toggler” es configurado a “2” y “SolutionsArea” es configurado a “Sales” (ver abajo).
Hay 4 “Equipos WIG” más en adición a los dos que hemos discutido, haciendo 6 en total.
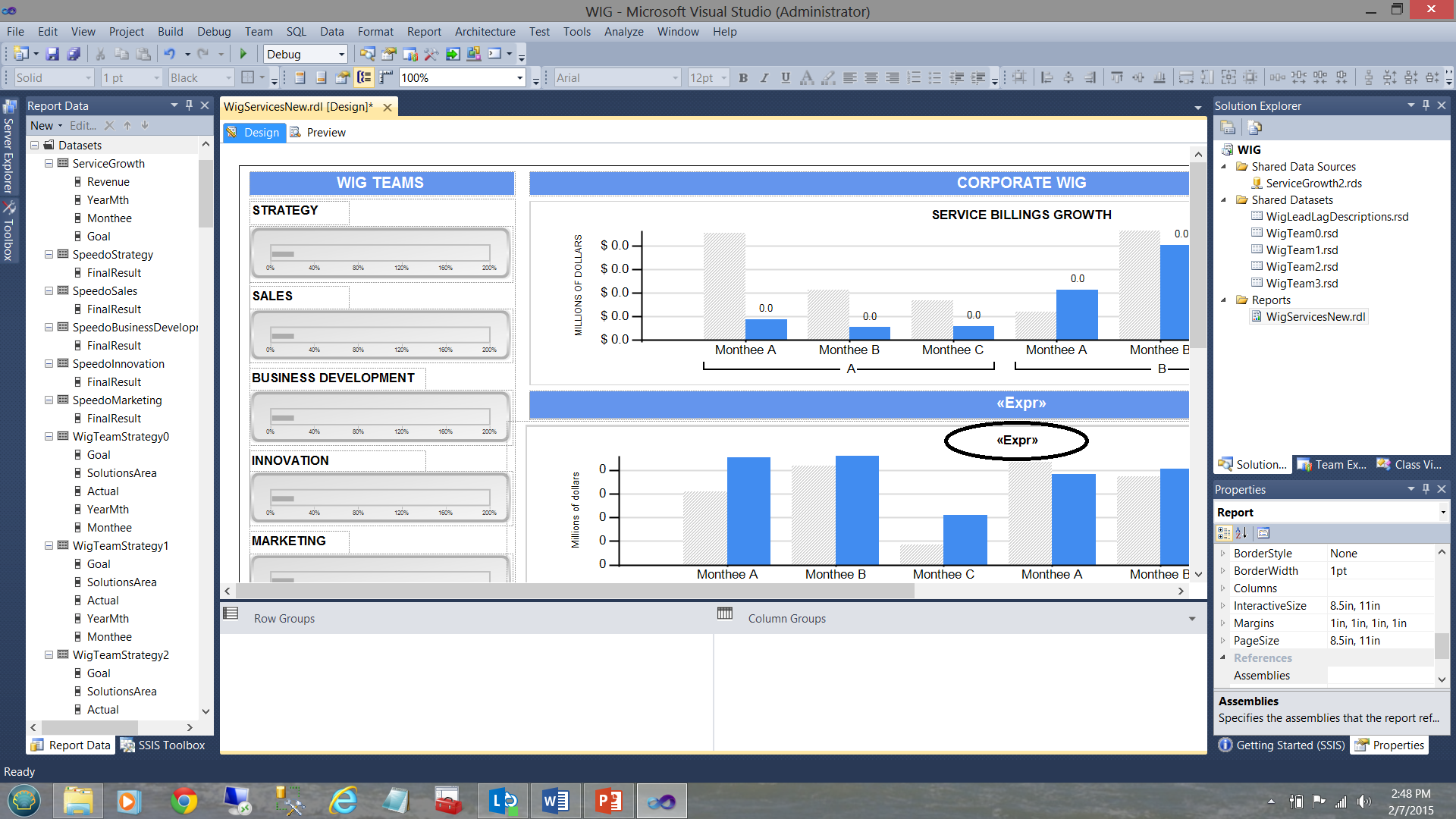
El lector astuto notará que en la captura de pantalla de arriba que el gráfico de barra inferior tiene un título “<Expr>” (ver el círculo en la captura de pantalla de arriba). Lo que no es inmediatamente aparente es que hay de hecho 6 gráficos de barra superpuestos uno encima de otro (Como se muestra diagramáticamente abajo):

Dicho esto, cuando el usuario hace clic en la estimación Strategi, la variable “SolutionsArea” es configurada a ‘Strategy’ y la variable “Toggler” a 1. El truco es que cada vez sólo un gráfico podrá ser visible, y utilizando la propiedad de visibilidad de los gráficos nosotros podemos mostrar o esconder el gráfico dependiendo de qué valor de “Toggler” es pasado por la selección de área de solución del usuario.
Para saber más acerca de cómo es manejada esta técnica, por favor dé un vistazo al artículo que recientemente publiqué en SQLShack titulado “Now you see it, now you don’t”
Para este reporte, elegimos utilizar datasets locales o incrustados (local para este reporte), ya que cada dataset es solamente utilizado y adjuntado a un y sólo un gráfico de barra vertical. El punto importante siendo que recibimos un golpe en tiempo de ejecución UNA VEZ teniendo los datasets individuales poblándose desde datasets compartidos, y estos datasets locales o incrustados están siendo persistidos en la caché. Como vimos arriba, cada uno es filtrado para un área de soluciones particular. Una vez más, el lector astuto notará que sería muy difícil implementar un mecanismo de filtrado equivalente y eficiente en el dataset compartido (especialmente si este dataset contiene cientos o miles de registros).
Muchas personas dicen que una imagen vale más que mil palabras, y respecto de la larga discusión que hemos tenido, podemos resumirlo todo en la presentación a continuación:
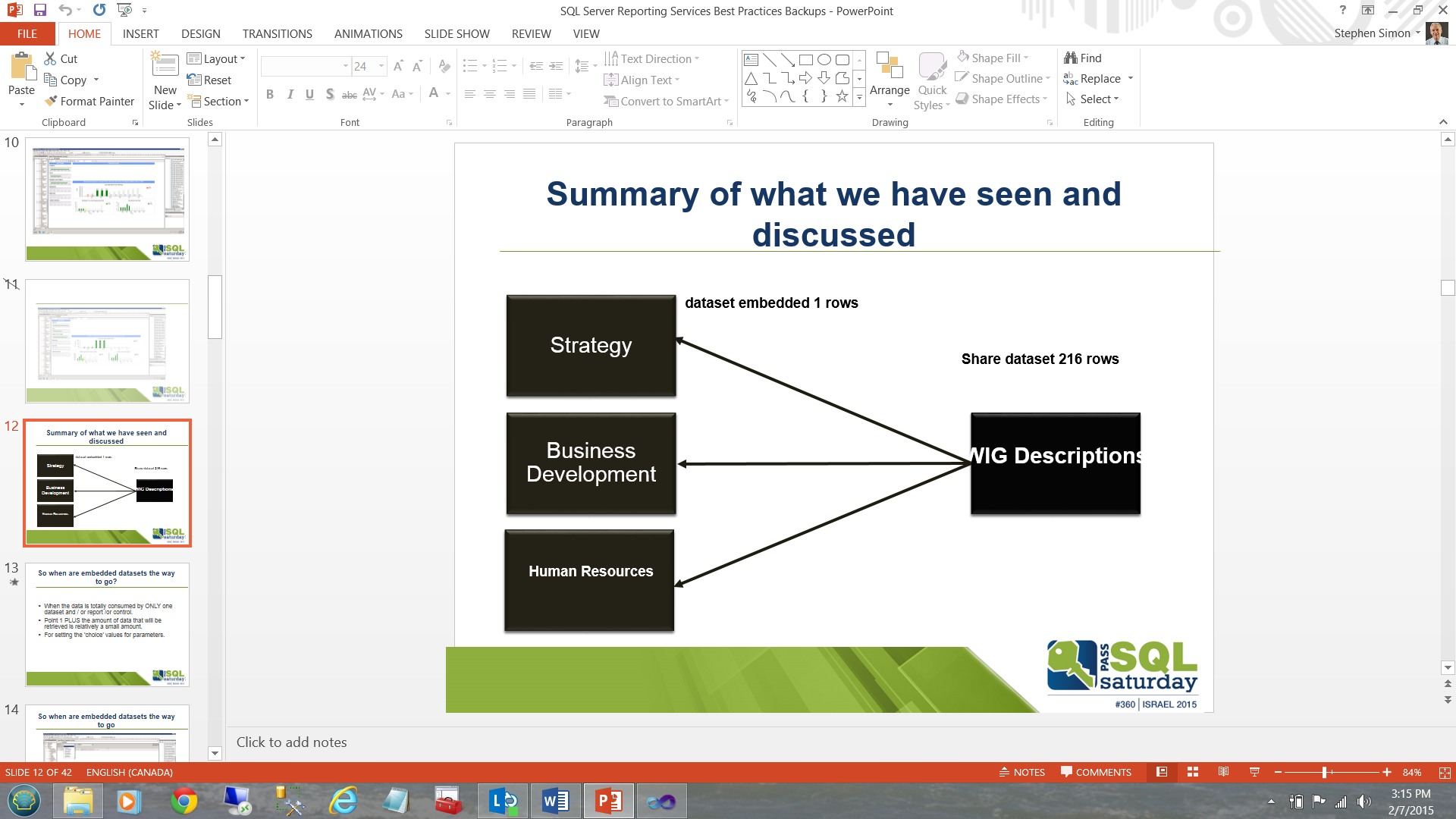
En lugar de ejecutar una consulta mayor basada en tablas o procedimientos almacenados seis veces para poblar cada una de las cajas (datasets locales) en la parte izquierda y potencialmente tener que hacer un escaneo de tablas o en el mejor de los casos un escaneo indexado en TODOS los registros de tablas (buscar estas seis áreas de soluciones desde la miríada de áreas presentes en la tabla), obtenemos una vez la caja/dataset “WIG Descriptions” a la derecha y luego poblamos la izquierda usando 6 consultas desde el dataset de subconjunto “WIG Descriptions”.
Casos en los que los datasets compartidos son la respuesta
En nuestro siguiente ejemplo estaremos viendo un panel de control que creé para una gran institución financiera (como un prototipo) hace algunos años. El panel de control se puede ver abajo:
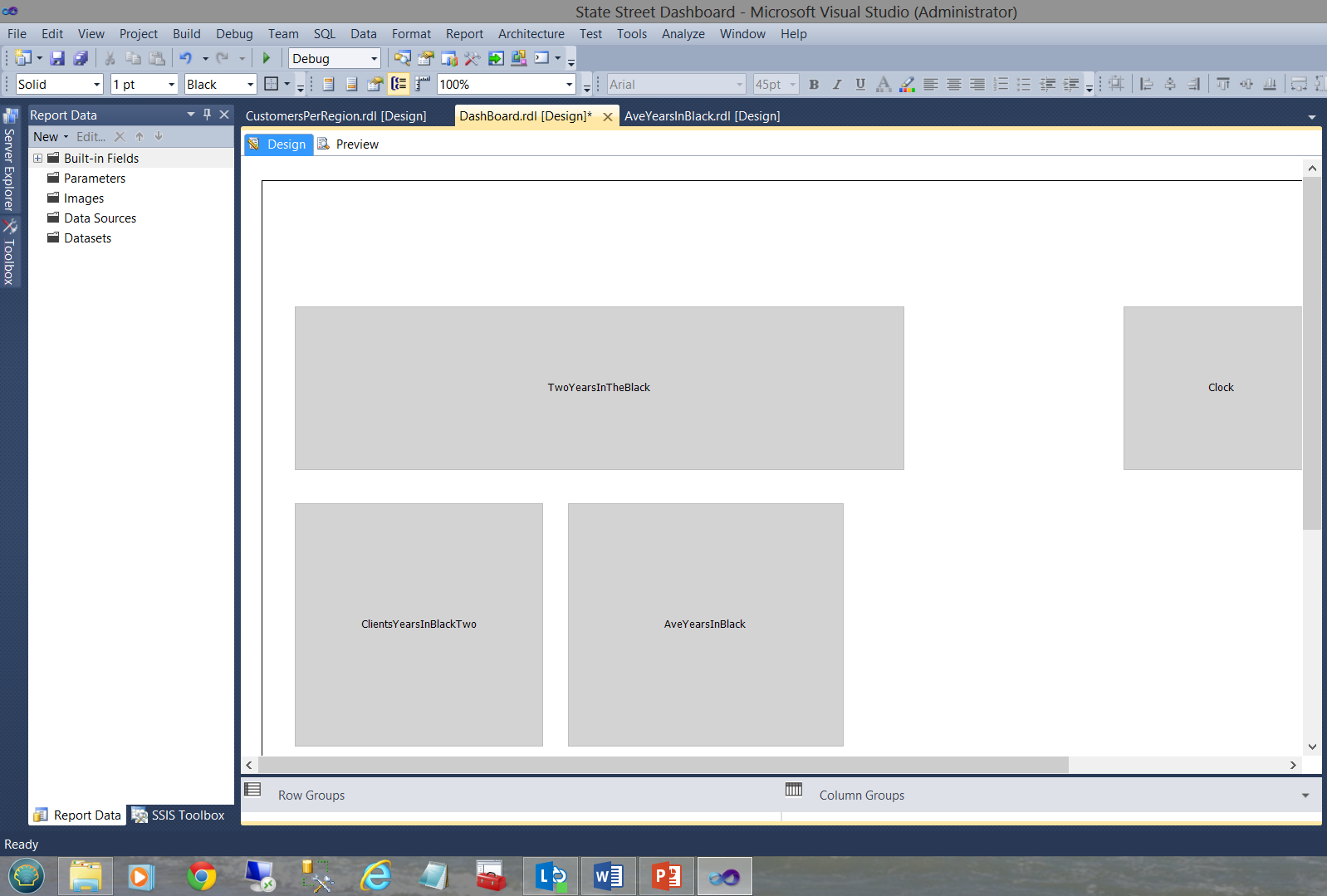
El panel de control funciona con numerosos sub reportes como se puede ver arriba. Cada sub reporte tiene sus propios datasets compartidos y NO datasets locales o incrustados, como se puede ver en la captura de pantalla abajo.
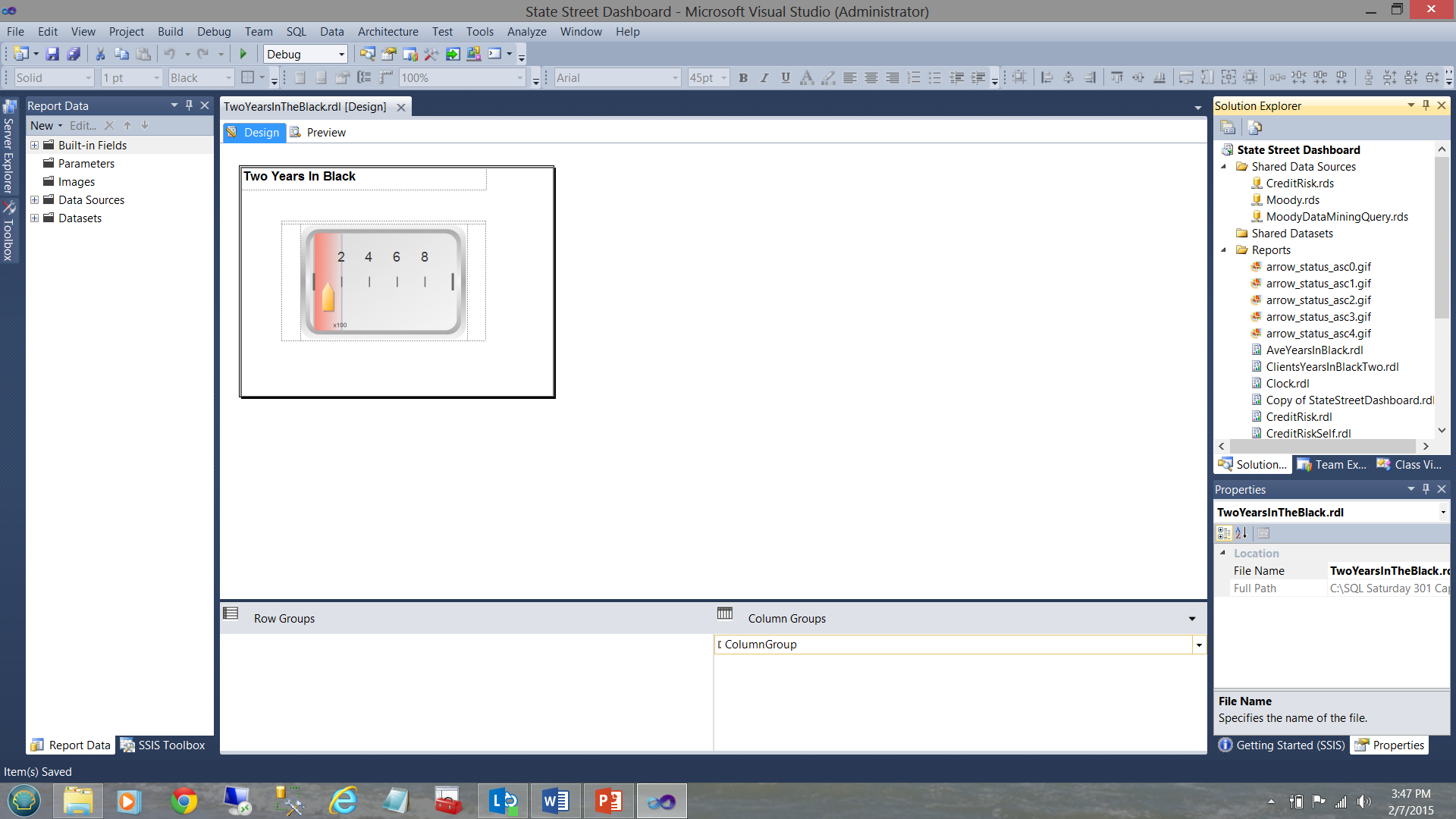
Abriendo la pestaña de dataset a la izquierda, el lector puede ver que el dataset proveyendo los datos se origina desde el dataset compartido “SQLShackYeaarsInBlackIsTwo” (ver abajo).
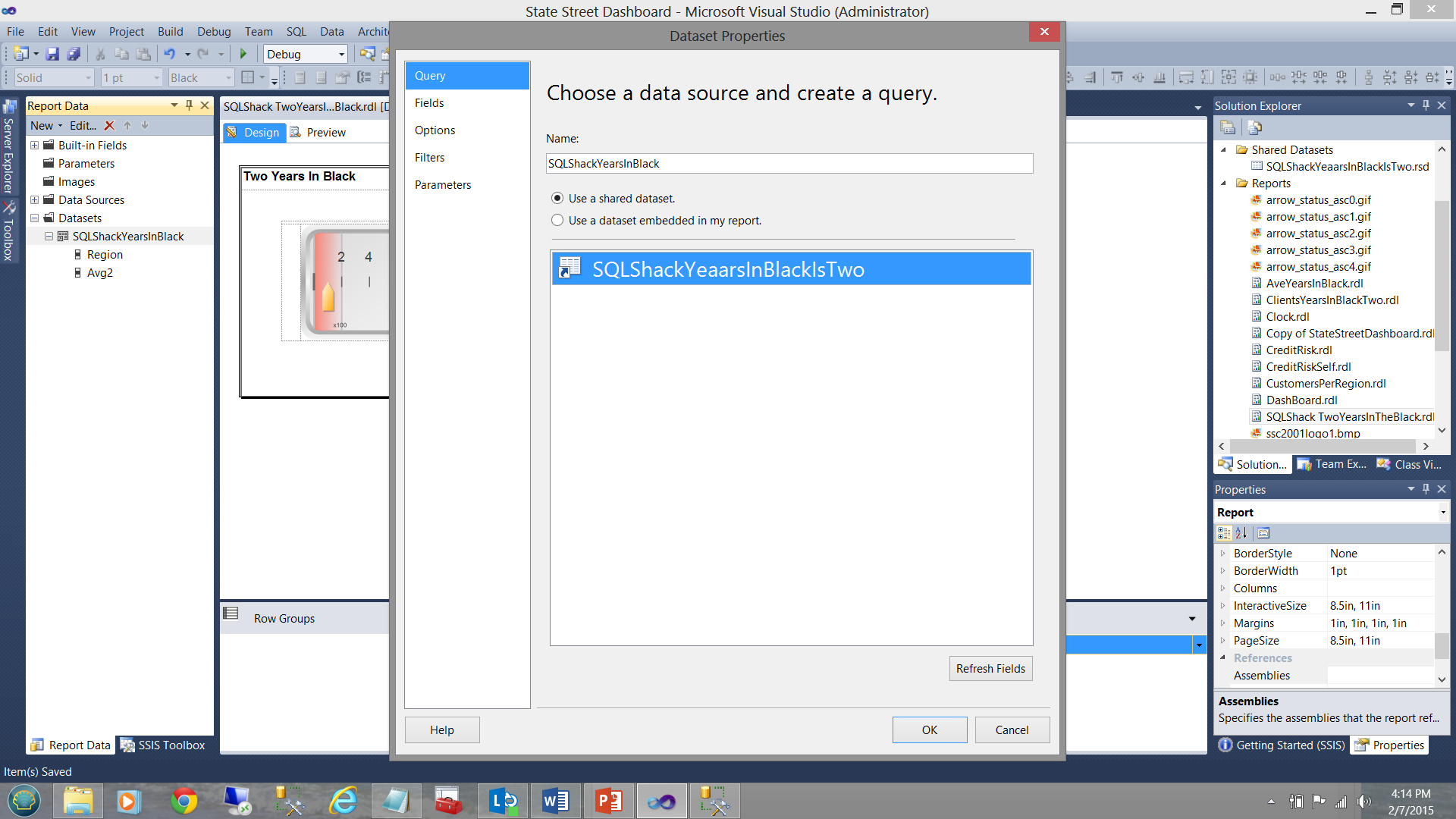
El punto importante a entender es que mientras que un dataset local “SQLShackYearsInBlack” genera un stub, ninguna consulta posterior es definida para jalar los datos desde las tablas de la base de datos y hay meramente una conexión hecha entre el “dataset local” (el cual será utilizado por la estimación vista arriba) y el dataset compartido.
Las diferencias son finas y sutiles. Además, la decisión correcta es vital para asegurar la máxima eficiencia en generar los resultados del reporte.
Limpiando la caché del reporte
Una de las trampas cuando se trata de desarrollar nuestros reportes en el ambiente de Visual Studio, es el envío a la caché de los datos dentro del archivo generado por el sistema “.rdl.data”. Los matices de esto son finos en que podemos hacer cambios cosméticos al reporte respecto del filtrado, etc., y cuando usamos la vista previa del reporte después de haber hecho estos cambios, lo que es generado es definitivamente NO lo que esperamos ver. Esto puede incluir cambios que podríamos haber hecho a los procedimientos almacenados que alimentan los datasets. Mientras que se los corra dentro del ambiente de SQL Server Management Studio, los resultados correctos son obtenidos; el instante que su reporte es corrido y generado, uno nota que los resultados son “los mismo de siempre”. Esto puede ser desconcertante a veces.
La razón para esto es que nuestro reporte tiene como fuente de sus datos un archivo de disco en la caché (ver abajo).
Este archivo generado por Reporting Services debe ser removido y regenerado por Reporting Services para que los cambios sean generados. ¡Una generación o regeneración del proyecto NO logra esto!
Jason Faulkner tiene una rutina súper pequeña que escribió, la cual nos ayuda a encontrar una manera rápida y sucia de purgar este archivo de datos.
- Vaya a Tools > External Tools
- Añada una nueva herramienta y establezca los parámetros como sigue:
- Title: Clear Report Data Cache
- Command: "%WinDir%\System32\cmd.exe“
- Arguments: /C DEL /S /Q "$(SolutionDir)\*.rdl.data
- Opciones seleccionadas: Use Output window y Close on exit
jasonfaulkner.com/ClearDataCacheBIS
La característica “Clear Report Data Cache” (una vez construida) puede ser vista en la captura de pantalla abajo:
Registro de la Utilización del Reporte
¿Cuán seguido le han pedido crear un reporte que es tan importante que el reporte es requerido “ayer o más pronto” sólo para encontrarse con que el reporte fue usado una vez y nunca más? De hecho, su proyecto de Visual Studio Reporting Services puede verse similar al mostrado a continuación:
Este proyecto tiene una plétora de reportes sin usar/redundantes/obsoletos. En resumen, el proyecto debería ser limpiado y el reporte refrescado. La pregunta dura es sólo cómo nos cercioramos cuáles reportes están siendo utilizados y cuáles no.
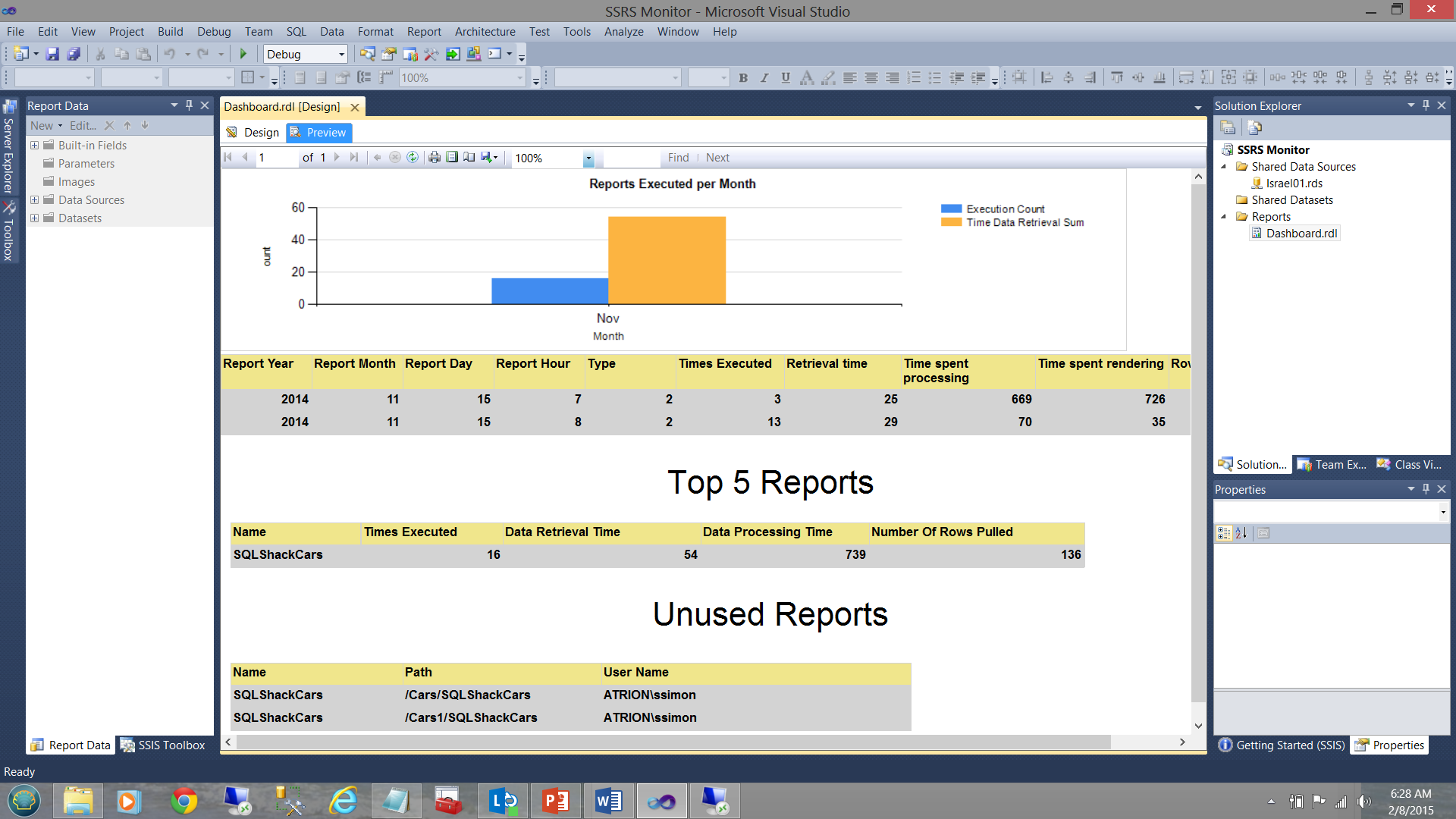
Una manera de obtener estas estadísticas es construir una aplicación de monitoreo rápida y sucia de SQL Server Reporting Services (ver abajo).
De hecho, este es el tópico para mi siguiente artículo, e iremos tras los pasos para crear esta aplicación/reporte.
En el ínterin, por favor note que
- El gráfico de barra vertical (arriba) muestra el número de reportes ejecutados para el mes actual.
- La matriz (inmediatamente debajo del gráfico de barra vertical) muestra los tiempos de ejecución, etc., para todos los reportes que fueron corridos este mes.
- La matriz “Top 5 Reports” muestra los cinco reportes más ejecutados durante el mes actual.
- La característica “Unused Reports” es lo que nos interesa en nuestro presente ejercicio, y esto nos dirá qué reportes no han sido usados por algún tiempo y son por lo tanto candidato para remoción y limpieza.
El uso de gráficos dentro de reportes
Hagámonos la pregunta “¿Por qué deberíamos considerar el uso de gráficos como un procedimiento recomendado?” Si somos honestos con nosotros mismos, los siguientes puntos deberían venir a la mente.
- Los gráficos permiten al tomador de decisiones extraer información en una cantidad mínima de tiempo.
- Las anomalías se vuelven inmediatamente aparentes.
- Ningún tomador de decisiones tiene el tiempo para cernir a través de montones de datos.
- Una imagen vale más que 1000 palabras. En resumen: Información, los datos NO son requeridos.
En la captura de pantalla mostrada abajo, los resultados financieros para los pasados pocos años de SQLShackFinancial son mostrados. En la primera captura de pantalla, el color de relleno del gráfico de barra vertical es generado por el sistema. En nuestro caso, el color azul. Mientras que el gráfico de barra vertical no muestre el incremento del ingreso con tiempo, no nos dice nada acerca de cómo lo “real” se compara con lo “planeado”.
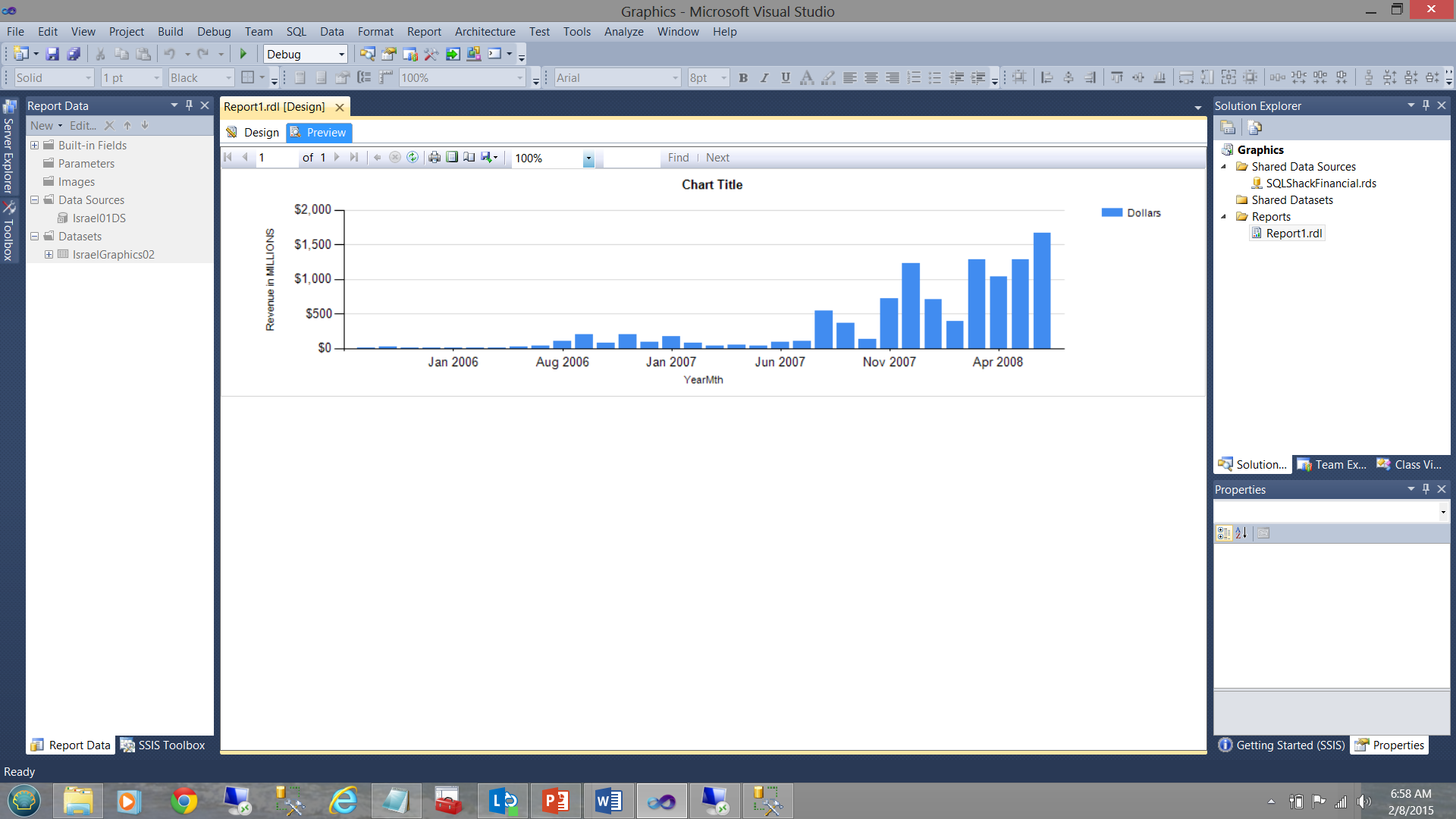
En nuestra siguiente captura de pantalla, la cual es generada desde la misma consulta y desde el mismo proyecto de SQL Server Reporting Services, los datos se vuelven más informativos. Note el uso de “nuestros colores seleccionados” para decirnos la historia completa (ver abajo).
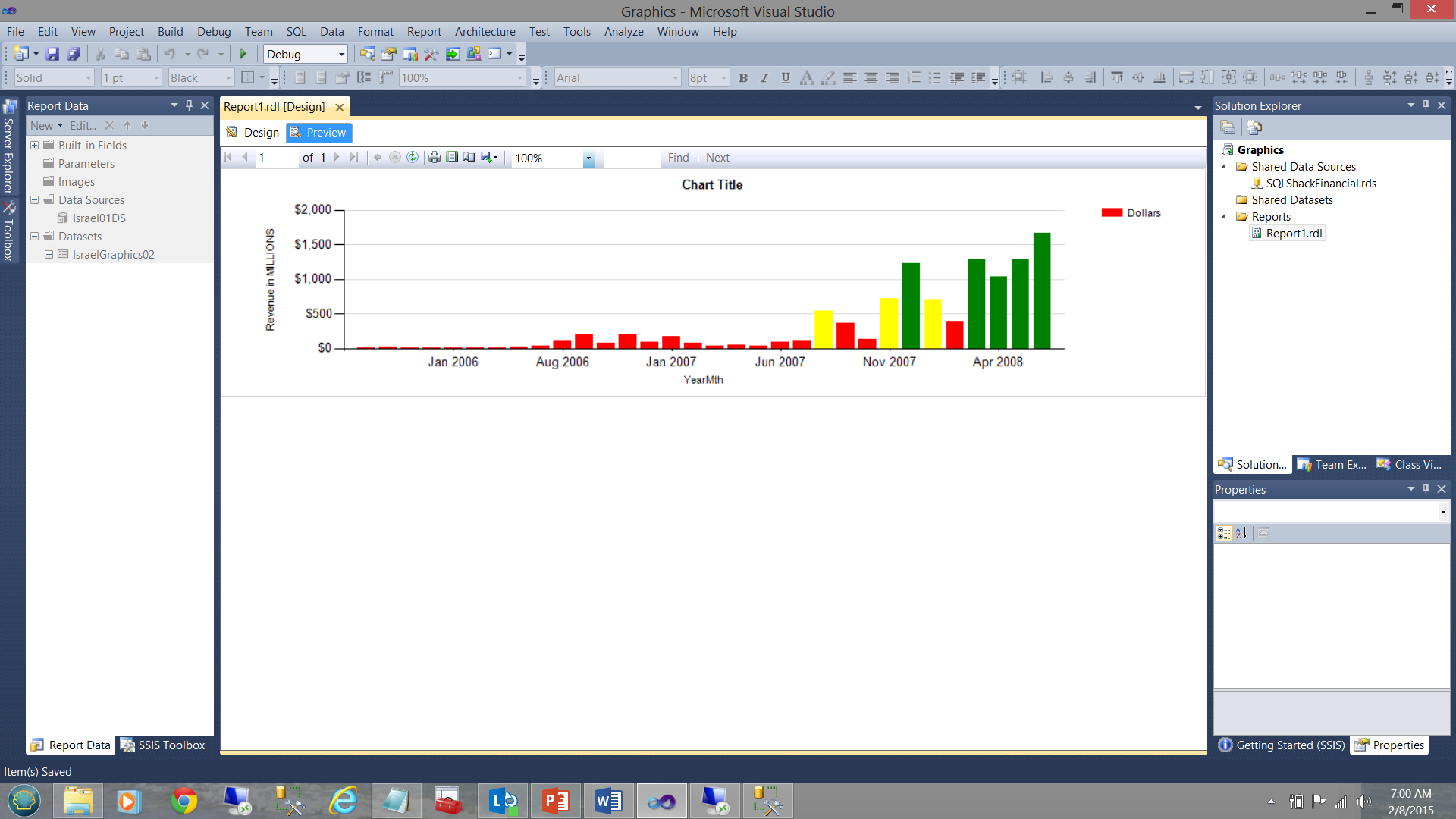
Hasta julio de 2007 nos estaba yendo extremadamente mal, PERO los negocios comenzaron a ‘dar vuelta’ hacia adelante.
Las reglas de negocios para el color de relleno para las barras verticales fueron definidas como sigue.
Para cada cantidad
| Cantidad | <$500000000 | >= $500000000 and < $1000000000 | >= $1000000000 |
| Color de relleno | Rojo | Amarillo | Amarillo |
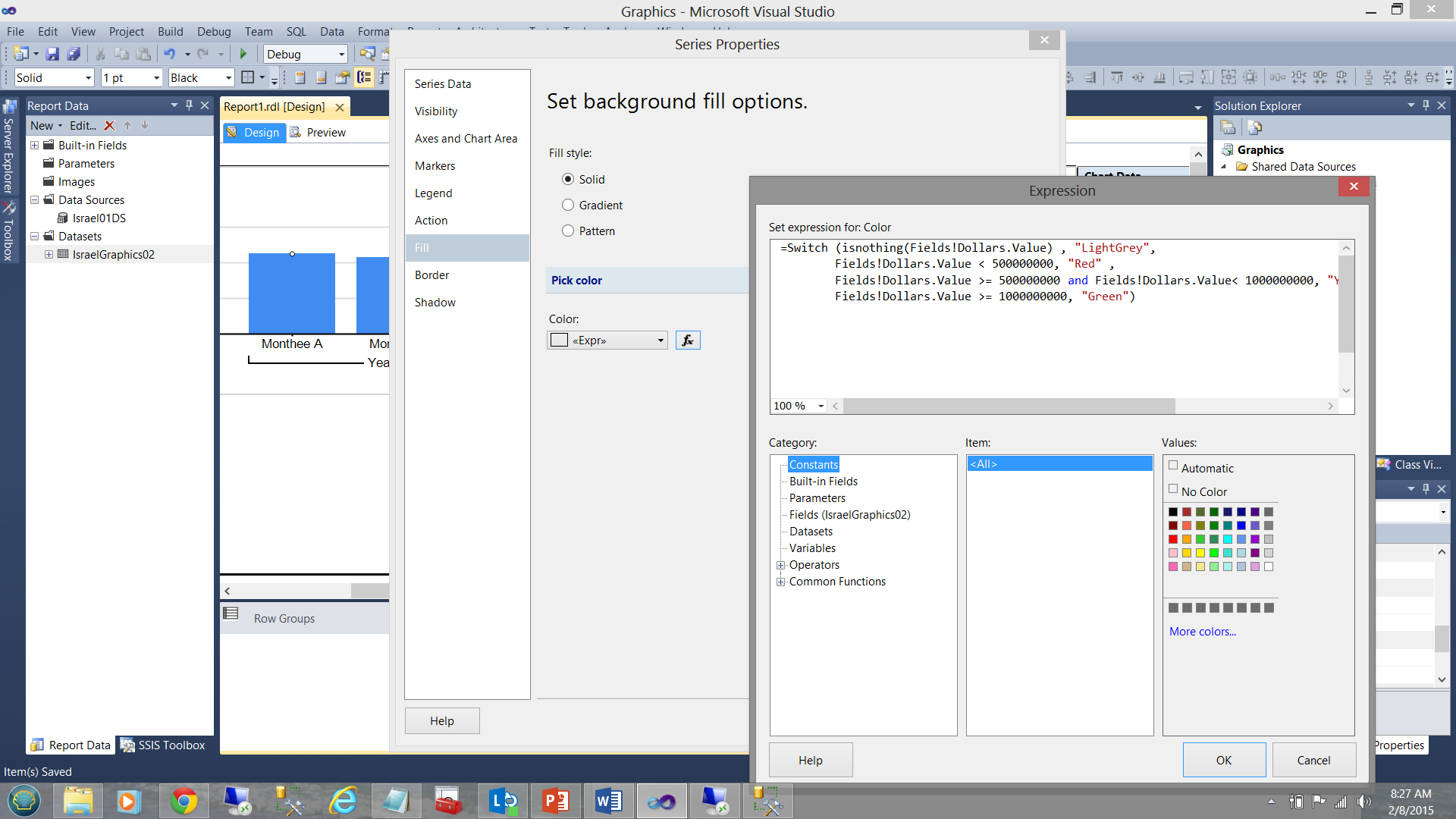
En términos de código:
|
1 2 3 4 |
=Switch (isnothing(Fields!Dollars.Value) , "LightGrey", Fields!Dollars.Value < 500000000, "Red" , Fields!Dollars.Value >= 500000000 and Fields!Dollars.Value< 1000000000, "Yellow", Fields!Dollars.Value >= 1000000000, "Green") |
Conclusiones
SQL Server Reporting Services tiene sus mañas y muy a menudo parece una herramienta difícil de utilizar para obtener información eficiente y efectiva desde nuestros datos. Saber cómo trabajar mejor con el producto es importante, así como las maneras de dar soluciones alternativas a las variadas “trampas”.
Los datasets son la clave para generar eficientemente los reportes. Los datasets locales nos ayudan cuando estamos tomando una “vista reducida” de los datos. “Muéstrame ese registro de 100,000,000 que debe ser mostrado para el título de mi gráfico de barra vertical”.
Los datasets son la clave para generar eficientemente los reportes. Los datasets locales nos ayudan cuando estamos tomando una “vista reducida” de los datos. “Muéstrame ese registro de 100,000,000 que debe ser mostrado para el título de mi gráfico de barra vertical”.
Como todo o demás en la vida, las generalizaciones nunca son 100% ciertas.
¡Feliz programación!
Steve ha hecho presentaciones en 8 PASS Summits y una en PASS Europe 2009 y 2010. Él ha presentado recientemente una presentación de Master Data Services en PASS Amsterdam Rally.
Steve ha hecho 5 presentaciones en Information Builders’ Summits. Él es un mentor regional de PASS.
Ver todas las entradas de Steve Simon
- Procedimientos Recomendados para SQL Server Reporting Services - December 24, 2016
- Excel cargando múltiples libros a SQL Server - December 24, 2016
- Creando archivos CSV dinámicamente generados que contienen datos de SQL Server - October 29, 2016