
Con todas las funciones de alta disponibilidad (HA) y de recuperación de desastres (DR), el administrador de la base de datos tiene que tomar en cuenta que información se puede perder y el tiempo de inactividad aceptable debe medirse en los peores escenarios. La pérdida de datos afecta a su capacidad para cumplir con los objetivos de punto de recuperación (RPO) y el tiempo de inactividad afecta a los objetivos de tiempo de recuperación (RTO). Al utilizar grupos de disponibilidad (AGs), su RTO y RPO dependen de la replicación de registros del log de transacciones entre al menos dos réplicas para ser extremadamente rápido. Mientras peor sea el rendimiento, mayor será la pérdida de datos potenciales que se produzcan y más tiempo puede tardar en reconectarse un fallo en la base de datos.
Los grupos de disponibilidad tienen que conservar todos los registros del log de transacciones hasta que se hayan distribuido a todas las réplicas secundarias. La sincronización lenta incluso con una sola réplica evitará el truncamiento de registros. Si los registros del log no pueden ser truncados, el registro probablemente comenzará a crecer. Esto se vuelve un problema para el mantenimiento, ya sea porque el disco se sigue expandiendo o porque puede quedarse sin ningún espacio.
Modos de disponibilidad
Existen dos modos de disponibilidad, commit síncrono y commit asíncrono. El proceso de seleccionar un modo equivale a seleccionar si desea favorecer la protección de datos o el rendimiento de la transacción. Ambos modos de disponibilidad siguen el mismo flujo de trabajo, con una pequeña pero muy importante diferencia.
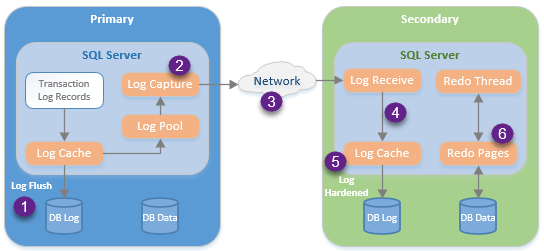
Con el modo de commit síncrona, la aplicación no recibe confirmación de que la transacción se haya realizado hasta que se hayan consolidado los registros en el log (paso 5) en todas las réplicas secundarias síncronas. Así es como AGs puede garantizar que no existan datos perdidos. Cualquier transacción que no se consolida antes de que se produzca el fallo primario se revertirá y el error correspondiente sera desplegado en la aplicación para recibir una alerta o para realizar su propio tratamiento de errores.
Cuando se utiliza el modo de confirmación asíncrono, la aplicación recibe una confirmación de que la transacción fue realizada después de que el último registro del log se vacía (paso 1) al archivo de registro en la réplica primaria. Esto hace que mejore el rendimiento porque la aplicación no tiene que esperar a que se transmitan los registros, sino que abre la AG al potencial de pérdida de datos. Si la réplica primaria falla antes que las réplicas secundarias se consoliden en los registros del log, la aplicación creerá que se ha realizado un commit de la transacción pero una conmutación por error daría lugar a la pérdida de los datos.
Medición de pérdida de datos potenciales
Thomas Grohser me dijo una vez: “no confundas la suerte con la alta disponibilidad”. Un servidor puede permanecer en línea sin fallar o apagarse por muchos años, pero si ese servidor no tiene características de redundancia, entonces no tiene realmente alta disponibilidad. El hecho de haber permanecido durante todo el año online no significa que cumples con 99,999% de tiempo online establecido en los acuerdos de servicio de (SLA).
La administración basada en directivas es un método para verificar que se pueden lograr sus RTOs y RPOs. Cubriré este método de vistas de administración dinámica (DMV) porque me parece que es más versátil y muy útil al crear alertas personalizadas en varias herramientas de monitoreo. Si desea leer más sobre el método de gestión basado en directivas, revise estas publicaciones de los libros en pantalla.
Cálculos
Existen dos métodos para calcular la pérdida de datos. Cada método tiene sus peculiaridades que son importantes para entender y ponerlos en contexto.
Cola de envío de registro
Tpérdida_datos = log_enviados_cola / tasa_generación_log
Su primer idea podría ser mirar la tasa de envío en lugar de la tasa de generación, pero es importante recordar que no estamos buscando cuánto tiempo se tardará en sincronizar, sino, estamos buscando qué margen de tiempo vamos a perder a los datos. Además, se está midiendo la pérdida de datos por tiempo en lugar de la cantidad.
Este cálculo puede ser algo engañoso si su carga de escritura es inconsistente. Una vez administré un sistema que utilizaba filestream. La base de datos tendría una carga de escritura muy baja hasta que un archivo de 4 MB fue eliminado en él. El instante después de que la transacción se hizo un commit, la cola de envío de registro se volvió muy grande, mientras que la tasa de generación de registro todavía era muy baja. Esto hizo que mis alertas se activarán, aunque los 4 MB de datos estuvieran sincronizados extremadamente rápido y la siguiente consulta mostraba que estábamos dentro de nuestros SLA de RPO.
Si eliges este cálculo, deberás activar alertas después de que se hayan violado los SLA de RPO durante un período de tiempo, como también después de 5 sondeos a intervalos de 1 minuto. Esto ayudará a reducir los falsos positivos.
Hora del último commit
Tpérdia_datos = última_vez_commitprimari – última_vez_commitsecundario
Este último método de tiempo de commit es más fácil de entender. El último tiempo de commit en su réplica secundaria siempre será igual o menor que la réplica primaria. El encontrar la diferencia entre estos valores le indicará cuánto se retrasa con respecto a su réplica.
De manera similar al método de cola de envío de registro, el último commit puede ser engañoso en sistemas con una carga de trabajo inconsistente. Si se produce una transacción a las 02:00 A.M. y, a posteriormente, la carga de escritura en la base de datos se queda inactiva durante una hora, este cálculo podrá resultar engañoso hasta que se sincronice la transacción siguiente. La métrica declararía un retraso de una hora, aunque no hubieran datos que se perdieran durante esa hora.
Aunque es engañoso, el retraso de una hora es técnicamente preciso. RPO mide el período de tiempo en el que los datos pueden perderse. No mide la cantidad de datos que se perderían durante ese período de tiempo. El hecho de que no existan datos que se pierdan no cambia el hecho de que perdería las últimas horas de datos. Sin embargo, ser preciso aún distorsiona el panorama general, porque si existieran flujos de datos no habría tenido el retraso de una hora indicado.
Consultas métricas RPO
Método de registro de cola de envío
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
;WITH UpTime AS ( SELECT DATEDIFF(SECOND,create_date,GETDATE()) [upTime_secs] FROM sys.databases WHERE name = 'tempdb' ), AG_Stats AS ( SELECT AR.replica_server_name, HARS.role_desc, Db_name(DRS.database_id) [DBName], CAST(DRS.log_send_queue_size AS DECIMAL(19,2)) log_send_queue_size_KB, (CAST(perf.cntr_value AS DECIMAL(19,2)) / CAST(UpTime.upTime_secs AS DECIMAL(19,2))) / CAST(1024 AS DECIMAL(19,2)) [log_KB_flushed_per_sec] FROM sys.dm_hadr_database_replica_states DRS INNER JOIN sys.availability_replicas AR ON DRS.replica_id = AR.replica_id INNER JOIN sys.dm_hadr_availability_replica_states HARS ON AR.group_id = HARS.group_id AND AR.replica_id = HARS.replica_id --I am calculating this as an average over the entire time that the instance has been online. --To capture a smaller, more recent window, you will need to: --1. Store the counter value. --2. Wait N seconds. --3. Recheck counter value. --4. Divide the difference between the two checks by N. INNER JOIN sys.dm_os_performance_counters perf ON perf.instance_name = Db_name(DRS.database_id) AND perf.counter_name like 'Log Bytes Flushed/sec%' CROSS APPLY UpTime ), Pri_CommitTime AS ( SELECT replica_server_name , DBName , [log_KB_flushed_per_sec] FROM AG_Stats WHERE role_desc = 'PRIMARY' ), Sec_CommitTime AS ( SELECT replica_server_name , DBName --Send queue will be NULL if secondary is not online and synchronizing , log_send_queue_size_KB FROM AG_Stats WHERE role_desc = 'SECONDARY' ) SELECT p.replica_server_name [primary_replica] , p.[DBName] AS [DatabaseName] , s.replica_server_name [secondary_replica] , CAST(s.log_send_queue_size_KB / p.[log_KB_flushed_per_sec] AS BIGINT) [Sync_Lag_Secs] FROM Pri_CommitTime p LEFT JOIN Sec_CommitTime s ON [s].[DBName] = [p].[DBName] |

Método del último commit
NOTA: Esta consulta es un poco más simple y no requiere calcular contadores de monitor de rendimiento acumulativo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
;WITH AG_Stats AS ( SELECT AR.replica_server_name, HARS.role_desc, Db_name(DRS.database_id) [DBName], DRS.last_commit_time FROM sys.dm_hadr_database_replica_states DRS INNER JOIN sys.availability_replicas AR ON DRS.replica_id = AR.replica_id INNER JOIN sys.dm_hadr_availability_replica_states HARS ON AR.group_id = HARS.group_id AND AR.replica_id = HARS.replica_id ), Pri_CommitTime AS ( SELECT replica_server_name , DBName , last_commit_time FROM AG_Stats WHERE role_desc = 'PRIMARY' ), Sec_CommitTime AS ( SELECT replica_server_name , DBName , last_commit_time FROM AG_Stats WHERE role_desc = 'SECONDARY' ) SELECT p.replica_server_name [primary_replica] , p.[DBName] AS [DatabaseName] , s.replica_server_name [secondary_replica] , DATEDIFF(ss,s.last_commit_time,p.last_commit_time) AS [Sync_Lag_Secs] FROM Pri_CommitTime p LEFT JOIN Sec_CommitTime s ON [s].[DBName] = [p].[DBName] |

Objetivo del tiempo de recuperación
El objetivo de tiempo de recuperación implica algo más que el rendimiento de la sincronización AG.
Cálculo
Tconmutación = Tdetección + Tsobrecarga + Trehacer
Detección
El tiempo de detección ocurre desde el instante en que se produce un error interno o existe un tiempo de espera hasta el momento en que el AG comienza a conmutar por error. El clúster comprobará la integridad del AG invocando al procedimiento almacenado sp_server_diagnostics. Si existe un error interno, el clúster iniciará una conmutación por error después de recibir los resultados. Este procedimiento almacenado se lo llama a un intervalo que es 1/3 del umbral de tiempo de espera de comprobación total. De manera predeterminada, realiza sondeos cada 10 segundos con un tiempo de espera de 30 segundos.
Si no se detecta ningún error, se puede producir una conmutación por error si se alcanza el tiempo de espera de comprobación de estado o si la concesión entre la instancia DLL de recursos y SQL Server ha caducado (20 segundos por defecto). Para más detalles sobre estas condiciones, revise esta publicación de libros en línea.
Sobrecarga
La sobrecarga resulta ser el tiempo que tarda un clúster en realizar conmutación por error además de restablecer las bases de datos online. El tiempo de conmutación por error suele ser constante y puede verificarse fácilmente. Traer las bases de datos online depende de la recuperación del accidente. Esta recuperación suele ser muy rápida, pero una conmutación por error en medio de una transacción muy grande puede producir retrasos a medida que la recuperación de fallos se restablece. Es recomendable probar la conmutación por error en un entorno que no sea el de producción durante operaciones como voluminosas reconstrucciones de índices.
Rehacer
El momento en que las páginas de datos se consolidan en la réplica secundaria, SQL Server vuelve a realizar las transacciones para avanzar hacia adelante. Esta es un área en la que necesitamos supervisar, sobre todo si la réplica secundaria no es suficiente en comparación con la réplica primaria. Dividir la cola_rehacer por el tasa_rehacer indicará su retraso.
Trehacer = cola_rehacer / tasa_rehacer
Consulta métrica RTO
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
;WITH AG_Stats AS ( SELECT AR.replica_server_name, HARS.role_desc, Db_name(DRS.database_id) [DBName], DRS.redo_queue_size redo_queue_size_KB, DRS.redo_rate redo_rate_KB_Sec FROM sys.dm_hadr_database_replica_states DRS INNER JOIN sys.availability_replicas AR ON DRS.replica_id = AR.replica_id INNER JOIN sys.dm_hadr_availability_replica_states HARS ON AR.group_id = HARS.group_id AND AR.replica_id = HARS.replica_id ), Pri_CommitTime AS ( SELECT replica_server_name , DBName , redo_queue_size_KB , redo_rate_KB_Sec FROM AG_Stats WHERE role_desc = 'PRIMARY' ), Sec_CommitTime AS ( SELECT replica_server_name , DBName --Send queue and rate will be NULL if secondary is not online and synchronizing , redo_queue_size_KB , redo_rate_KB_Sec FROM AG_Stats WHERE role_desc = 'SECONDARY' ) SELECT p.replica_server_name [primary_replica] , p.[DBName] AS [DatabaseName] , s.replica_server_name [secondary_replica] , CAST(s.redo_queue_size_KB / s.redo_rate_KB_Sec AS BIGINT) [Redo_Lag_Secs] FROM Pri_CommitTime p LEFT JOIN Sec_CommitTime s ON [s].[DBName] = [p].[DBName] |

Rendimiento síncrono
Todo lo que sea discutido hasta el momento ha girado en torno a una recuperación en el modo de confirmación asíncrono. El aspecto final del retraso en la sincronización que se cubrirá es el impacto de rendimiento del uso del modo de confirmación síncrono. Tal como se mencionó anteriormente, este modo de sincronización de commit garantiza que no exista una pérdida de datos, pero el precio de no perder datos es el rendimiento.
El impacto que tengan sus transacciones a causa de la sincronización se puede medir con los contadores del monitor de rendimiento o los tipos de espera.
Cálculos
Contadores del monitor de rendimiento
Tcosto = Ttransacciones_escritura_espejo / Tretraso transacción
La simple división de las transacciones de escritura reflejadas por segundo y de los contadores de retardo de transacciones proporcionan el costo de habilitar la confirmación síncrona en unidades de tiempo. Es el método de mi preferencia si hablamos de métodos de los tipos de espera que demostraré a continuación, ya que es posible medir en el nivel de base de datos y calcular las transacciones implícitas. En otras palabras, si ejecuto una sola instrucción INSERT con un millón de filas, se calculará el retardo inducido en cada fila. El método de los tipos de espera vería la inserción única como una acción y le proporcionaría el retraso causado a todas las millones de filas. Esta diferencia es discutible para la mayoría de los sistemas OLTP, debido a que suelen tener mayores cantidades de transacciones más chicas.
Tipo de espera – HADR_SYNC_COMMIT
Tcosto = Ttiempo_espera / Tespera_contador_tarea
El contador de tipo de espera es acumulativo, lo cual implica que tendrá que extraer instantáneas en momento de encontrar sus diferencias o realizar el cálculo basado en toda la actividad desde que la instancia de SQL Server se reinició por última vez.
Consultas métricas de sincronización
Método de contadores de monitor de rendimiento
NOTA: El siguiente script es mucho más extenso que los anteriores. Esto es porque decidí demostrar cómo probaría los contadores de rendimiento y calcularía un período de tiempo reciente. Esta métrica podría lograrse con el cálculo del tiempo de recuperación demostrado también arriba.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
--Compruebe las métricas primero IF OBJECT_ID('tempdb..#perf') IS NOT NULL DROP TABLE #perf SELECT IDENTITY (int, 1,1) id ,instance_name ,CAST(cntr_value * 1000 AS DECIMAL(19,2)) [mirrorWriteTrnsMS] ,CAST(NULL AS DECIMAL(19,2)) [trnDelayMS] INTO #perf FROM sys.dm_os_performance_counters perf WHERE perf.counter_name LIKE 'Mirrored Write Transactions/sec%' AND object_name LIKE 'SQLServer:Database Replica%' UPDATE p SET p.[trnDelayMS] = perf.cntr_value FROM #perf p INNER JOIN sys.dm_os_performance_counters perf ON p.instance_name = perf.instance_name WHERE perf.counter_name LIKE 'Transaction Delay%' AND object_name LIKE 'SQLServer:Database Replica%' AND trnDelayMS IS NULL -- Espere a que vuelva a revisar -- He encontrado que estos contadores de rendimiento no se actualizan con frecuencia -- por lo tanto, existe un largo retraso entre los controles. WAITFOR DELAY '00:05:00' GO --Compruebe las métricas nuevamente INSERT INTO #perf ( instance_name ,mirrorWriteTrnsMS ,trnDelayMS ) SELECT instance_name ,CAST(cntr_value * 1000 AS DECIMAL(19,2)) [mirrorWriteTrnsMS] ,NULL FROM sys.dm_os_performance_counters perf WHERE perf.counter_name LIKE 'Mirrored Write Transactions/sec%' AND object_name LIKE 'SQLServer:Database Replica%' UPDATE p SET p.[trnDelayMS] = perf.cntr_value FROM #perf p INNER JOIN sys.dm_os_performance_counters perf ON p.instance_name = perf.instance_name WHERE perf.counter_name LIKE 'Transaction Delay%' AND object_name LIKE 'SQLServer:Database Replica%' AND trnDelayMS IS NULL --Agregados y presentes ;WITH AG_Stats AS ( SELECT AR.replica_server_name, HARS.role_desc, Db_name(DRS.database_id) [DBName] FROM sys.dm_hadr_database_replica_states DRS INNER JOIN sys.availability_replicas AR ON DRS.replica_id = AR.replica_id INNER JOIN sys.dm_hadr_availability_replica_states HARS ON AR.group_id = HARS.group_id AND AR.replica_id = HARS.replica_id ), Check1 AS ( SELECT DISTINCT p1.instance_name ,p1.mirrorWriteTrnsMS ,p1.trnDelayMS FROM #perf p1 INNER JOIN ( SELECT instance_name, MIN(id) minId FROM #perf p2 GROUP BY instance_name ) p2 ON p1.instance_name = p2.instance_name ), Check2 AS ( SELECT DISTINCT p1.instance_name ,p1.mirrorWriteTrnsMS ,p1.trnDelayMS FROM #perf p1 INNER JOIN ( SELECT instance_name, MAX(id) minId FROM #perf p2 GROUP BY instance_name ) p2 ON p1.instance_name = p2.instance_name ), AggregatedChecks AS ( SELECT DISTINCT c1.instance_name , c2.mirrorWriteTrnsMS - c1.mirrorWriteTrnsMS mirrorWriteTrnsMS , c2.trnDelayMS - c1.trnDelayMS trnDelayMS FROM Check1 c1 INNER JOIN Check2 c2 ON c1.instance_name = c2.instance_name ), Pri_CommitTime AS ( SELECT replica_server_name , DBName FROM AG_Stats WHERE role_desc = 'PRIMARY' ), Sec_CommitTime AS ( SELECT replica_server_name , DBName FROM AG_Stats WHERE role_desc = 'SECONDARY' ) SELECT p.replica_server_name [primary_replica] , p.[DBName] AS [DatabaseName] , s.replica_server_name [secondary_replica] , CAST(ac.mirrorWriteTrnsMS / CASE WHEN ac.trnDelayMS = 0 THEN 1 ELSE ac.trnDelayMS END AS DECIMAL(19,2)) sync_lag_MS FROM Pri_CommitTime p LEFT JOIN Sec_CommitTime s ON [s].[DBName] = [p].[DBName] LEFT JOIN AggregatedChecks ac ON ac.instance_name = p.DBName |

Método de los tipos de espera
NOTA: En resumen, no utilicé el método de dos comprobaciones utilizado anteriormente para encontrar los tipos de espera recientes, pero el método puede ser implementado si se opta por utilizar este método.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
;WITH AG_Stats AS ( SELECT AR.replica_server_name, HARS.role_desc, Db_name(DRS.database_id) [DBName] FROM sys.dm_hadr_database_replica_states DRS INNER JOIN sys.availability_replicas AR ON DRS.replica_id = AR.replica_id INNER JOIN sys.dm_hadr_availability_replica_states HARS ON AR.group_id = HARS.group_id AND AR.replica_id = HARS.replica_id ), Waits AS ( select wait_type , waiting_tasks_count , wait_time_ms , wait_time_ms/waiting_tasks_count sync_lag_MS from sys.dm_os_wait_stats where waiting_tasks_count >0 and wait_type = 'HADR_SYNC_COMMIT' ), Pri_CommitTime AS ( SELECT replica_server_name , DBName FROM AG_Stats WHERE role_desc = 'PRIMARY' ), Sec_CommitTime AS ( SELECT replica_server_name , DBName FROM AG_Stats WHERE role_desc = 'SECONDARY' ) SELECT p.replica_server_name [primary_replica] , w.sync_lag_MS FROM Pri_CommitTime p CROSS APPLY Waits w |

Conclusiones
Con los conocimientos adquiridos, usted ya estaría listo para seleccionar el método de medición para su AG asíncrono o síncrono de compromiso e implementar la línea base y el monitoreo. Yo prefiero el método de cola de envío de registro para comprobar la posible pérdida de datos y el método de contador de monitor de rendimiento para medir el impacto de rendimiento de sus réplicas de confirmación síncronas.
Referencias
- SQL Server 2012 AlwaysOn Parte 11 – Aspectos de rendimiento y supervisión de rendimiento II (SAP)
- SQL Server 2012 AlwaysOn Parte 12 – Aspectos de rendimiento y supervisión de rendimiento II (SAP)
- Supervisar el rendimiento de los grupos de disponibilidad AlwaysOn (BOL)

Derik thanks our #sqlfamily for plugging the gaps in his knowledge over the years and actively continues the cycle of learning by sharing his knowledge with all and volunteering as a PASS User Group leader.
View all posts by Derik Hammer