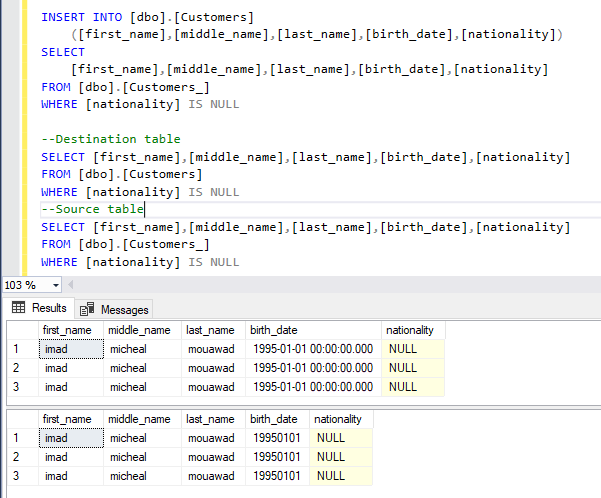
Learn SQL: Insert multiple rows commands
March 6, 2023This article explains the different approaches used to insert multiple rows into SQL Server tables.
This article explains the different approaches used to insert multiple rows into SQL Server tables.
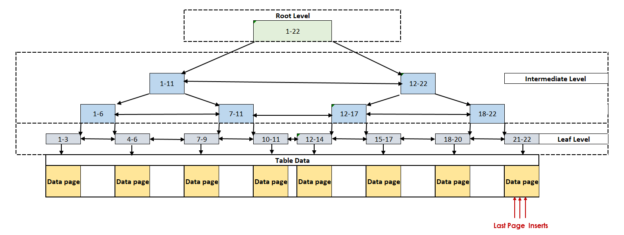
In this article, we will focus on one major SQL Server performance issue that we may experience during heavy data insertion in a table.
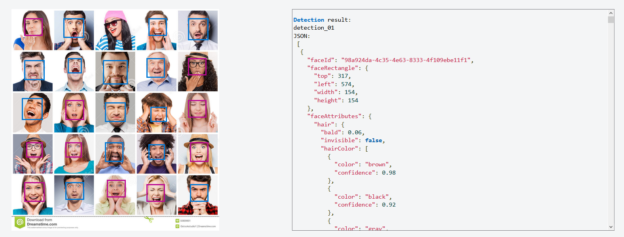
Today, we will implement an Azure Logic App for face recognition and insert its data into an Azure SQL database.
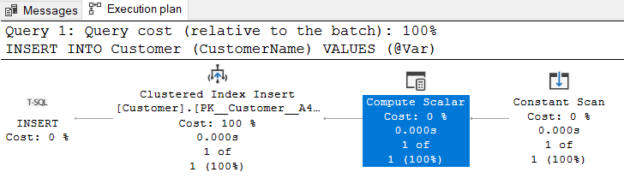
In this article, we will learn how to interpret an execution plan of a SQL Server insert statement.
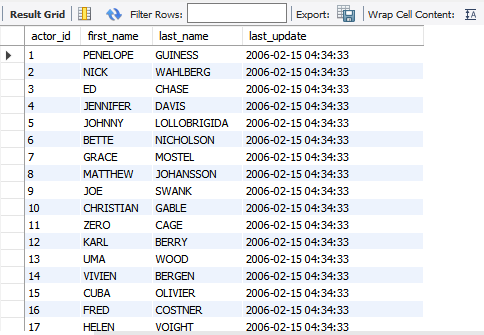
In my previous article, Learn MySQL: Sorting and Filtering data in a table, we had learned about the sorting and filtering of the data using WHERE and ORDER BY clause.
One challenge we may face when using SQL bulk insert is whether we want to allow access during the operation or prevent access and how we coordinate this with possible following transactions. We’ll look at working with a few configurations of this tool and how we may apply them in OLAP, OLPT, and mixed environments […]
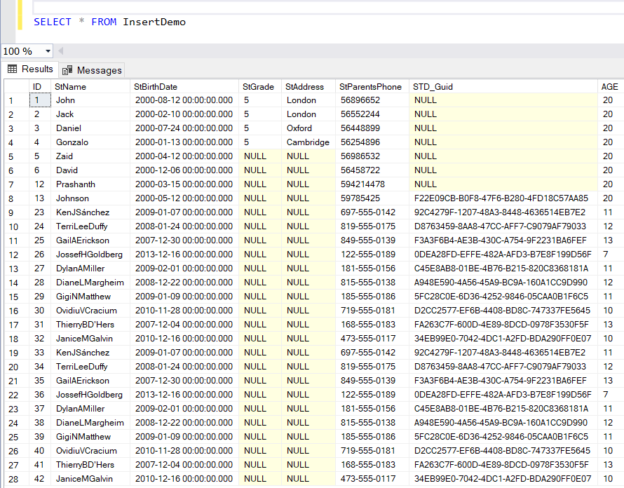
In this article, we will go deeply through the INSERT INTO statement by showing the different syntax formats and usage scenarios for that statement.
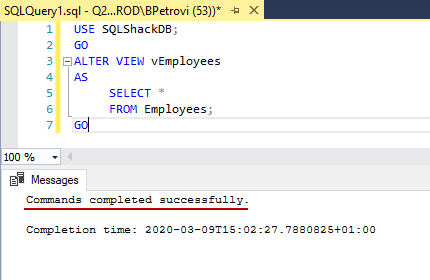
This is the third article in a series of learning the CREATE VIEW SQL statement. So far, I’d say that we’re comfortable and familiar with the syntax, and we’ve learned how to create and modify views. In this part, we’ll continue to work on views using the sample database and data that we created so […]
In the previous article, we’ve created two tables, and now we’re ready to use the SQL INSERT INTO TABLE command and populate these tables with data. In order to do so, we’ll prepare statements in Excel and then paste these statements into SQL Server and execute them. We’ll also check the contents of both tables […]
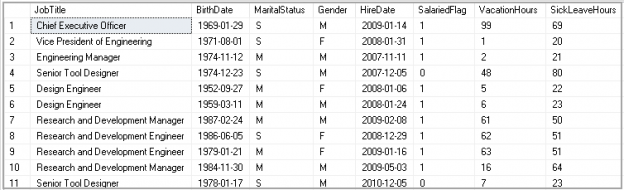
This article covers the SQL INSERT INTO SELECT statement along with its syntax, examples, and use cases.

Summary There are a variety of ways of managing data to insert into SQL Server. How we generate and insert data into tables can have a profound impact on performance and maintainability! This topic is often overlooked as a beginner’s consideration, but mistakes in how we grow objects can create massive headaches for future developers […]
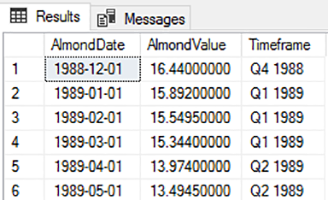
In CTEs in SQL Server; Querying Common Table Expressions the first article of this series, we looked at creating common table expressions for select statements to help us organize data. This can be useful in aggregates, partition-based selections from within data, or for calculations where ordering data within groups can help us. We also saw […]
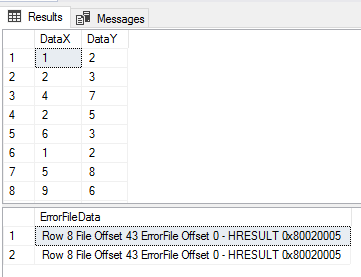
This article will cover SQL bulk insert operations deterministic outcomes and responses covering not allowing any bad data to allowing all data to be inserted, regardless of errors.
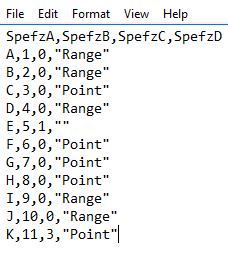
One of the challenges we face when using SQL bulk insert from files flat can be concurrency and performance challenges, especially if the load involves a multi-step data flow, where we can’t execute a latter step until we finish with an early step. We also see these optimization challenges with constraints as well, as fewer […]
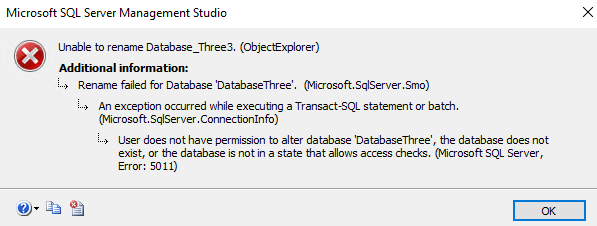
In this article, we’ll discuss security implications of using SQL Bulk Insert and how to mitigate those risks.
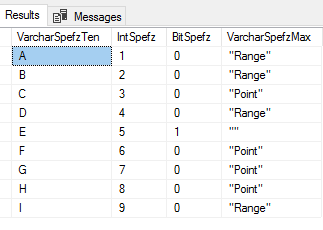
In the first part of reviewing the basics of bulk insert, we looked at importing entire files, specifying delimiters for rows and columns, and bypassing error messages. Sometimes we’ll want to skip first and ending lines, log errors and bad records for review after inserting data, and work with data types directly without first importing […]
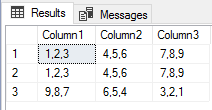
From troubleshooting many data flow applications designed by others, I’ve seen a common pattern of over complexity with many designs. Putting aside possible risks by introducing too much complexity, troubleshooting these designs often involves opening many different applications – from a notepad file, to SSIS, to SQL Server Management Studio, to a script tool, etc. […]
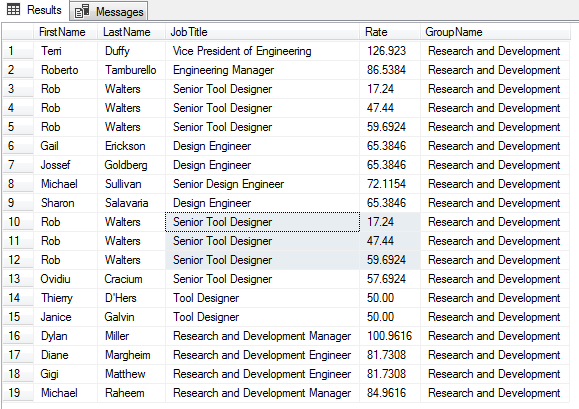
This article on the SQL Insert statement, is part of a series on string manipulation functions, operators and techniques. The previous articles are focused on SQL query techniques, all centered around the task of data preparation and data transformation.
Applies to SSAS Description This performance counter relates to statistics related to the Analysis Services aggregation cache and it measures the total number of insertions into the cache per partition per cube per Analysis Services database. The value of this counter is usually high and is reset whenever the Analysis Services is restarted. Resolved by […]
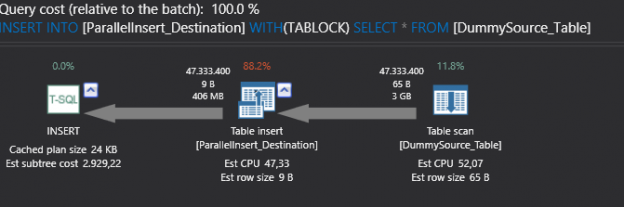
Introduction In the first part of this article, we will discuss about parallelism in the SQL Server Engine. Parallel processing is, simply put, dividing a big task into multiple processors. This model is meant to reduce processing time. SQL Server can execute queries in parallel SQL Server creates a path for every query. This path […]
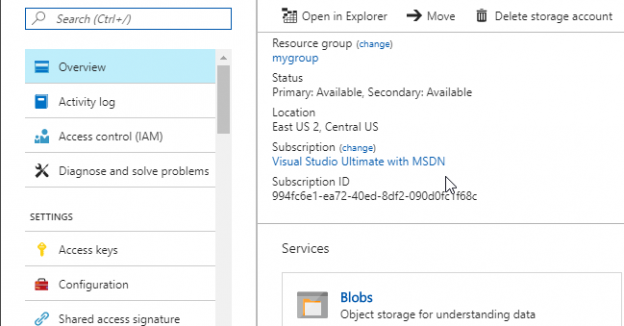
Introduction BULK INSERT is a popular method to import data from a local file to SQL Server. This feature is supported by the moment in SQL Server on-premises. However, there is a new feature that is supported only in SQL Server 2017 on-premises. This feature allows importing data from a file stored in an Azure […]
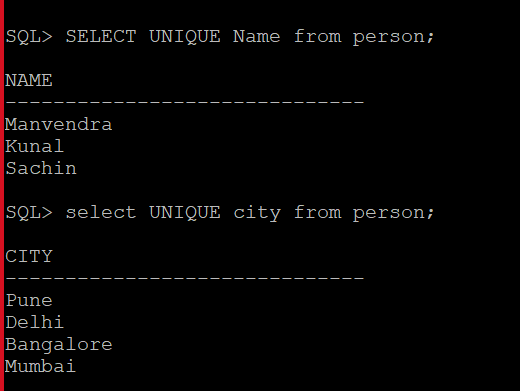
Today, we will learn the difference between SQL SELECT UNIQUE and SELECT DISTINCT in this article. As we all know that SQL is a query language that is used to access, create, delete, and modify data stored in a database system like SQL Server, Oracle, MySQL, etc. All these database systems have their query language […]
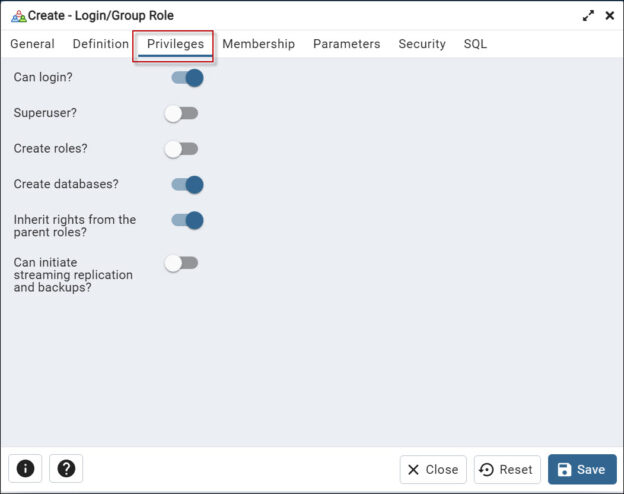
Introduction to the PostgreSQL tutorial to create a user In this article, we will show a PostgreSQL tutorial to create a user using PgAdmin and PL/PgSQL.
This article will show PostgreSQL Data Types with various examples.
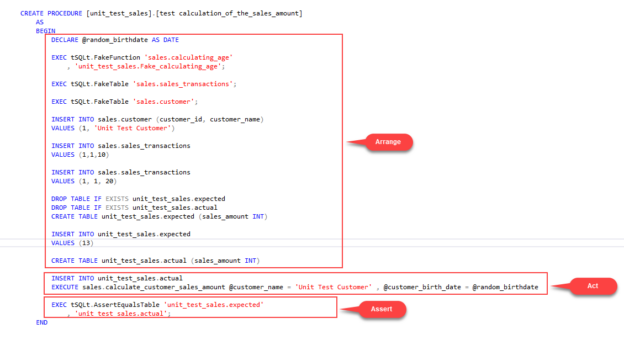
In this article, we are going to learn the basics of SQL unit testing and how to write a SQL unit test through the tSQLt framework.
© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy