
When creating a database, SQL Server maps this database with minimum two operating system files; the database data file MDF and the database log file LDF. Logically, the database data files are created under a collection set of files that simplifies the database administration, this logical file container is called the Filegroup. Database data files can come in two types, the Primary data files that contains metadata information for the database and pointers to the other database files in addition to the data, where each database should have only one Primary data file and the optional Secondary files to store data only. The basic storage unit in SQL Server is the Page, with each page size equal to 8KB. And each 8 pages with 64KB size called Extent.
The SQL Server component that is responsible for managing the data storage within the database files, called the SQL Server Storage Engine. It uses a fill mechanism that writes data to the database files depending on the amount of free space in each data file rather than writing in each file untill it is full then moving to the second one sequentially. This data filling algorithm is called Proportional Fill Algorithm. In other words, the SQL Server Storage Engine will write more frequently to the files with more free space. For example, if the first data file has 10 MB free space and the second one has 20 MB, the storage engine will fill one extent to the first file and two extents to the second one. If auto-growth is enabled to the database files and the database files become full, the SQL Server Database Engine will expand the database files one at a time and write to that file, once the expanded file becomes full, SQL Server Database Engine will expand the second database file and so on.
In the Proportional Fill Algorithm, each database data file will be assigned with a ranking integer number to specify how many times this file will be skipped from the writing process to the next file depending on the free space of that file, this number is called the Skip Target where the minimum value equal to 1 means that a write process will be performed on that file. The Skip Target can be measured by dividing the number of free extents in the file with the largest free space amount by the number of free extents in the current file, as integer value. The larger the free space in the database data file, the smaller Skip Target value. To have one file to write on each loop, there should be minimum one data file with Skip Target value equal to 1. Each time a new database data file is added or removed, or 8192 extents is filled in the database filegroup, the Skip Target value will be calculated again. In this way, all database data files will become full approximately at the same time. The Skip Target calculation can be monitored by enabling the Trace Flag 1165.
Let’s go through the practical part of this article to show how to track the Skip Target and how the Proportional Fill Algorithm works. First we will enable the Trace Flag 1165 to monitor the Skip Target which also required enabling the Trace Flag 3605 to allow showing the debugging info:
|
1 2 3 4 |
DBCC TRACEON (1165, 3605); GO |
The error logs will be cycled too to close the current error log file same as restarting the SQL Service:
|
1 2 3 4 |
EXEC sp_cycle_errorlog; GO |
In the same session, a new database with four database data files will be created with PropFillDemo name and each file with 10 MB size:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE DATABASE [PropFillDemo] ON PRIMARY ( NAME = N'PropFillDemo', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2.mdf',SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB ), ( NAME = N'PropFillDemo_1', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2_1.ndf',SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB ), ( NAME = N'PropFillDemo_2', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2_2.ndf' ,SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB ), ( NAME = N'PropFillDemo_3', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2_3.ndf' ,SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB ) LOG ON ( NAME = N'PropFillDemo_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo_log.ldf',SIZE = 10MB , MAXSIZE = 2GB , FILEGROWTH = 10%) |
As mentioned previously, adding new database files will trigger calculating the Skip Target value. We will read the error log to track the calculation process:
|
1 2 3 4 |
EXEC xp_readerrorlog; GO |
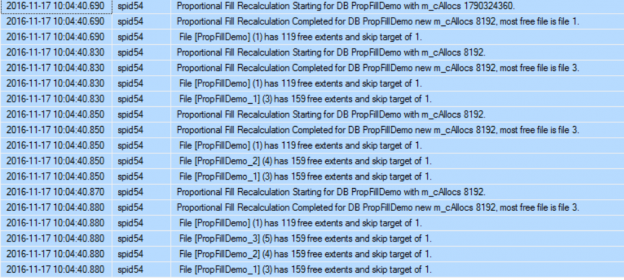
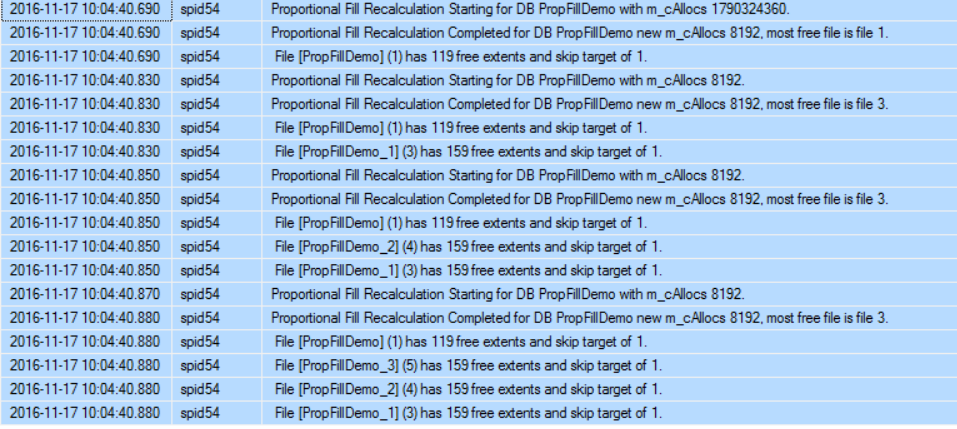
The error log shows that the Proportional Fill calculation is started for the newly created database and the Skip Target value is calculated for all database data files with value equal to 1 for all files as they have the same free space percentage. The m_cAllocs value that is mentioned in the error log is the Skip Target recalculation threshold, with random value when the database is created at the first time and 8192 when the database files created:
Now, we will list all database files with free space percentage by querying the sys.database_files using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 |
USE PropFillDemo GO Select Name AS DBFileName, file_id AS DBFileID, physical_name PathAndPhysicalName, (size * 8.0/1024) as FileSizeMB, ((size * 8.0/1024) - (FILEPROPERTY(name, 'SpaceUsed') * 8.0/1024)) As FileFreeSpaceMB, cast((((size * 8.0/1024) - (FILEPROPERTY(name, 'SpaceUsed') * 8.0/1024))/(size * 8.0/1024))*100 as decimal(6,2)) as FreeSpacePercent From sys.database_files |
The result in our case will be like the below, taking into consideration that the primary database file with ID=1 contains metadata information about the database, so that it has the least free space when the database is created:

When the database is created, each database data file assigned 10 MB size, and while each extent has 64KB size, then the number of extents in each database file can be calculated by (10*1024)/64 which is equal to 160 extents per each database file, with 159 free extents as shown in the error log viewed previously. The ShowFileStats DBCC command can be also used to show the database extents information:
|
1 2 3 4 5 |
USE PropFillDemo GO DBCC showfilestats |
Again the query output shows us that there are 41 extents used from the primary data file storing metadata. The result in our case will be like:

Till the point, the database created successfully and the initial Skip target value is calculated for all database data files. We can start now monitoring the Proportional Fill Algorithm by creating the PropFillTest simple table:
|
1 2 3 4 5 6 |
CREATE TABLE [PropFillTest] ( [ID] INT IDENTITY (1,1), [First_Name] NVARCHAR(50), [Last_Name] NVARCHAR(50) ); |
And fill it with 1000 records. Note that the number beside the GO statement shows the number of times the query will be executed:
|
1 2 3 4 |
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel') GO 500 |
Checking the database files free space percentage again using the previous query, you will find that the three secondary data files that have more free space than the primary data file are filled with data as they all have Skip Target value equal to 1. The data file with ID 3 that has the most free space amount from all the three secondary data files and Skip Target value equal to 1 as mentioned in the previous error log figure, is filled with the most amount of data:

Inserting a bigger amount of data, this time 30000 records:
|
1 2 3 4 |
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel') GO 15000 |
And checking the free space percentage in each file, the data will be distributed in the data files depending on the free space of each data file as below:

Then we will check the number of used extents per each data file:
|
1 2 3 |
DBCC showfilestats |
The result will show us the real data distribution in the data files and how much extent is used in each data file:

The IND DBCC command can be also used to show data pages’ distribution within all database data files by proving the database and table names only:
|
1 2 3 |
DBCC IND ('PropFillDemo', 'PropFillTest', -1); |
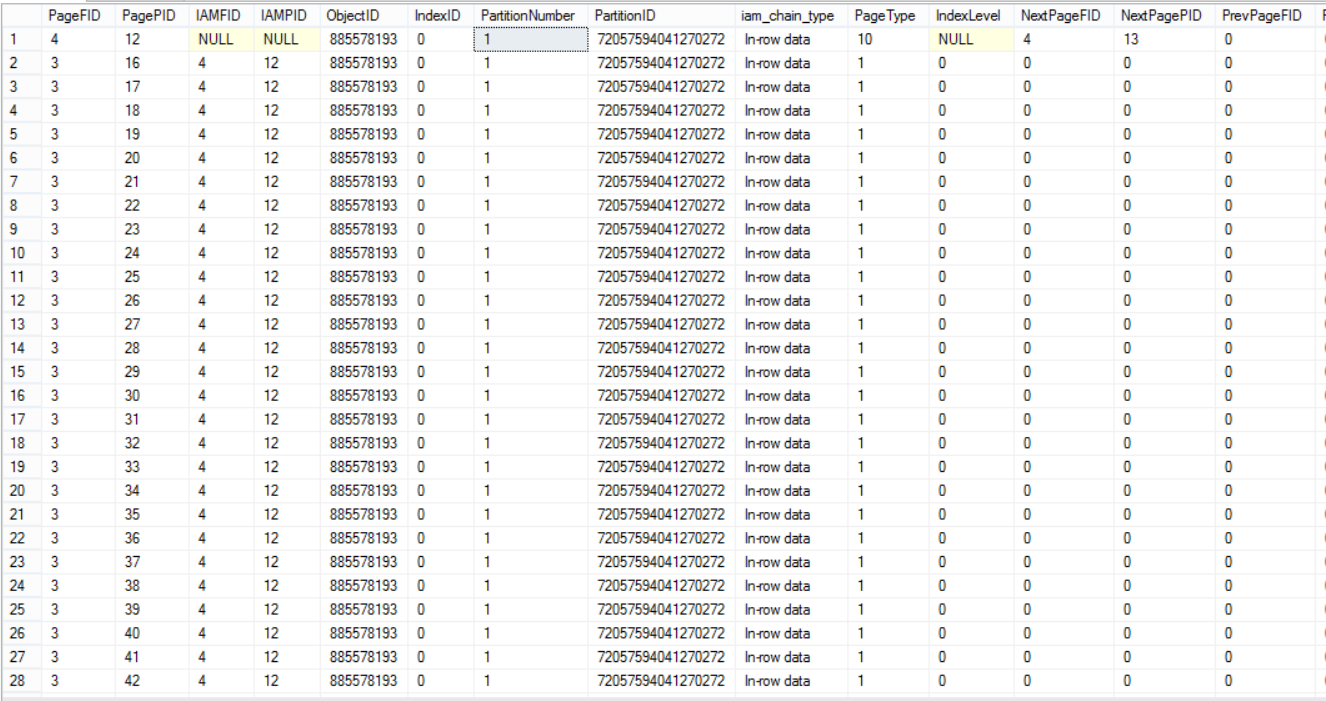
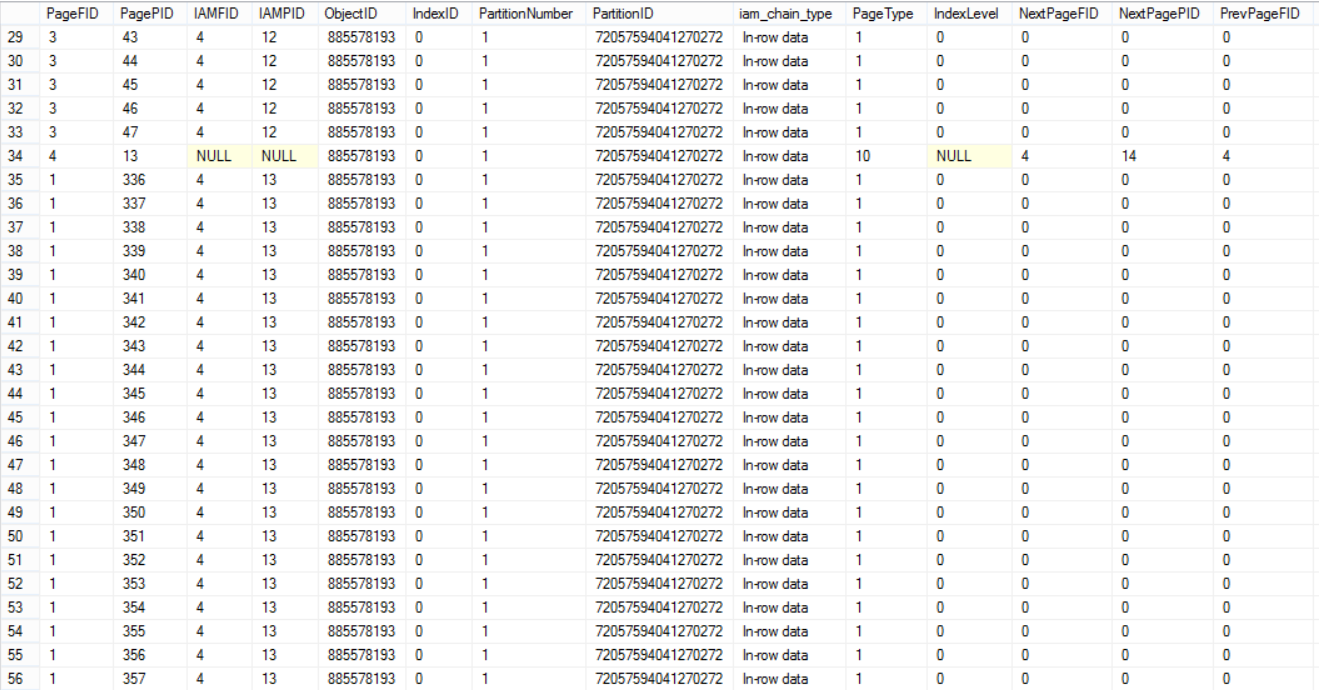
The below three snapshots from the huge result set returned from the DBCC command show that the table’s data is distributed within all data files:
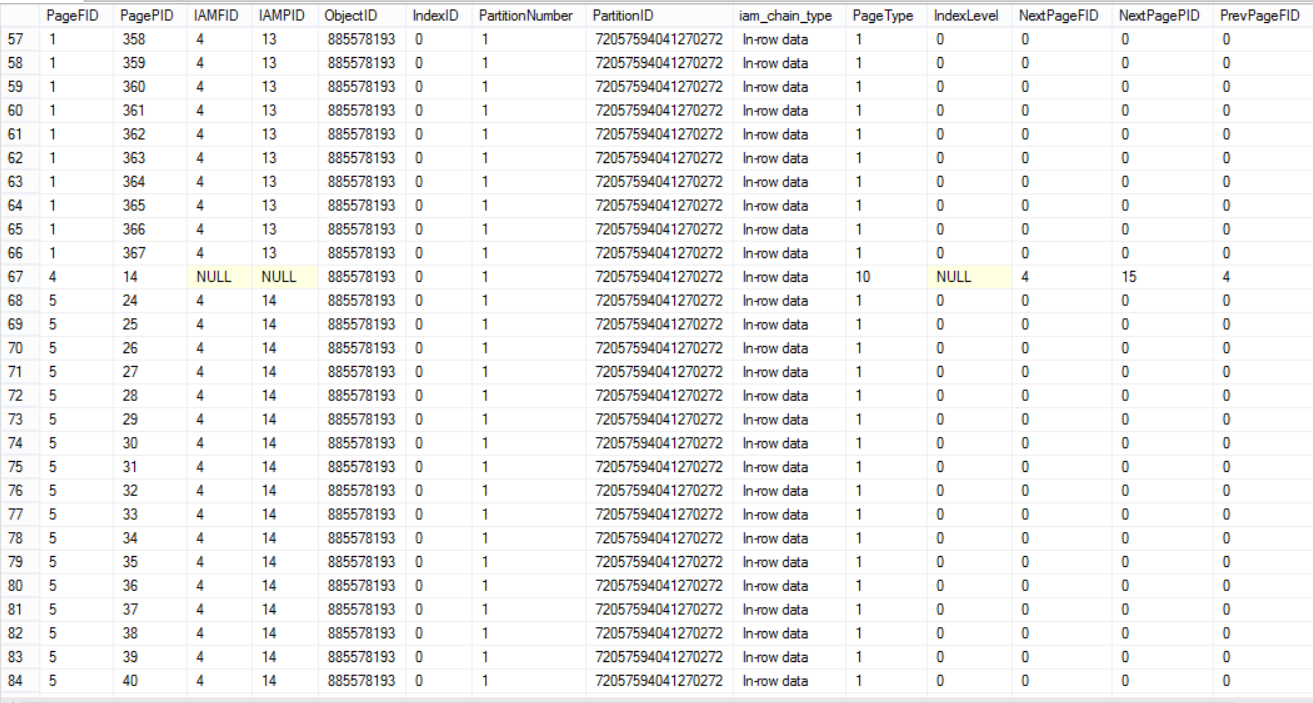
Let’s now try something else. We will insert a huge amount of data to the database data files:
|
1 2 3 4 |
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel') GO 15000000 |
And check the data files free space percentage:

It is clear from the previous result that once the data file become full, it is expanded again depending on the auto-growth amount value configured previously. Now we will add another database data file with size 15 MB:
|
1 2 3 4 5 6 |
USE [master] GO ALTER DATABASE [PropFillDemo] ADD FILE ( NAME = N'PropFillDemo_4', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo_4.ndf' , SIZE = 15360KB , FILEGROWTH = 10240KB ) TO FILEGROUP [PRIMARY] GO |
And check the error log again:
|
1 2 3 4 |
EXEC xp_readerrorlog; GO |
Which shows us that the Skip Target will be calculated again for all database data files:

Depending on the free space found in the below result, with the new file with the most free space:

If we try again to insert extra data:
|
1 2 3 4 |
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel') GO 15000 |
The two data files; 5 and 6, with Skip Target 1 will be allocated with the data, where the other database data files; 1,3 and 4, with Skip Target 239 will be skipped 238 times without writing to it:

Conclusion:
SQL Server uses the Proportional Fill Algorithm to allocate data in the database data files depending on the free space amount on each data file by calculating a measurable value called the Skip Target. It is clear from the previous demo when the Skip Target is recalculated and how the data is filled in each data file and how SQL Server will skip the files with the least free space due to high Skip Target value and write to the ones with smaller Skip Target Value. I hope that everything is clear and please leave a comment if you find anything not clear.
Useful links:
- Using Files and Filegroups
- sp_cycle_errorlog (Transact-SQL)
- More undocumented fun: DBCC IND, DBCC PAGE, and off-row columns

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021