
How to update SQL Server statistics?
The DBCC SHOW_STATISTICS statement shows statistics for a specific table.
|
1 2 3 |
DBCC SHOW_STATISTICS ("Person.Address", PK_Address_AddressID) |
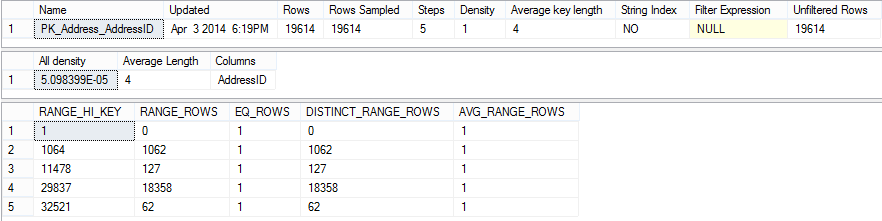
The statistics shown by this command are created using the default sampling rate. Note that the number of sampled rows is the same as the total number of table rows.
Query Optimizer updates statistics whenever it determines it’s needed. In some situations, statistics are not automatically updated and optimal performance is not provided. That’s when SQL Server statistics should be manually updated.
Although updated SQL Server statistics provide better execution plans, keep in mind that updating requires time and query recompilation also, which can slow down SQL Server performance. Therefore, frequent statistics updates should be avoided.
Another method to update statistics is to use the sp_updatestats stored procedure, but this is recommended only for advanced users, as the procedure updates statistics for all tables and indexed views in the database, which can significantly downgrade SQL Server performance.
|
1 2 3 |
EXEC sp_updatestats |
To update statistics on a specific table or change the sampling rate used to create statistics, use the UPDATE STATISTICS statement.
|
1 2 3 |
UPDATE STATISTICS <table_name> |
If there were no data changes on the table, UPDATE STATISTICS will have no effect. Even ten day old statistics will be accurate. On a table with frequent data changes, statistics old an hour can be obsolete and inaccurate.
In this example, we will use the AdventureWorks database, the Person.Address table. The table contains 19,614 rows and we will insert additional 10,000 records.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
DECLARE @i int SET @i = 0 WHILE @i < 10000 BEGIN INSERT INTO Person.Address( AddressLine1, AddressLine2, City, StateProvinceID, PostalCode, rowguid, ModifiedDate ) VALUES( 'Adr1', 'AddressLine2', 'New York', 78, 98011, NEWID(), GETDATE()) SET @i = @i + 1 END |
Then, we will view the table statistics by executing:
|
1 2 3 |
DBCC SHOW_STATISTICS ("Person.Address", PK_Address_AddressID); |
The statistics shown are old and inaccurate. Instead of 29,614 rows, there are only 19,614. All other parameters shown are also obsolete.
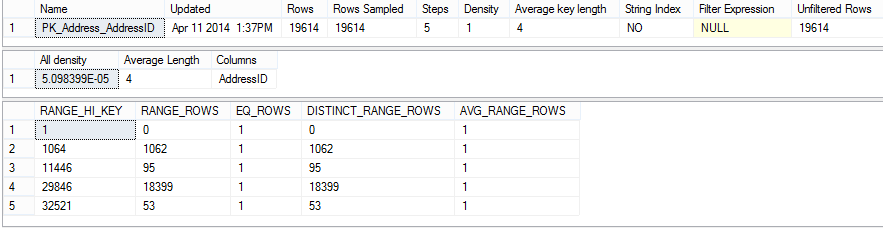
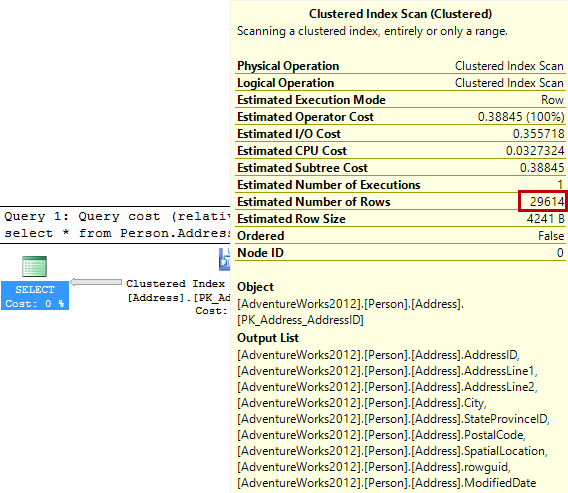
Although the statistics are inaccurate, the estimated query execution plan shows the correct number of records. However, this is the case only for the tables with a small number of records, such as this one.
After updating table statistics, the correct values are shown.
|
1 2 3 |
UPDATE STATISTICS Person.Address |
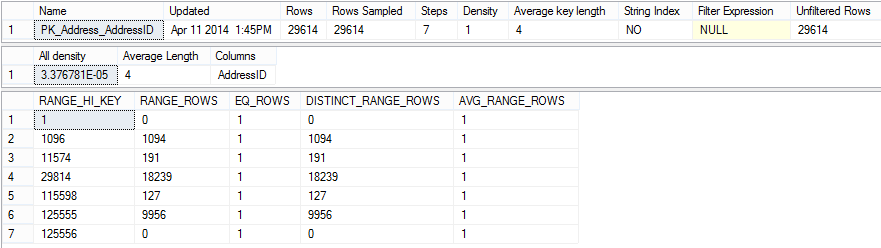
Note the All density value in both cases. The All density value is calculated as 1/total number of distinct rows. In the first case it’s
1/19,614 = 0.00005098099 = 5.098399102681758e-5
In the second, it’s:
1/29,614 = 0.00003376781 = 3.376781252110488e-5
The values are of the same order of magnitude and the difference can be neglected. Even if the obsolete statistics are used, there will be almost no performance degradation. However, this is valid only for tables with a small number of records.
To update statistics just for a specific table index, use the following syntax:
|
1 2 3 |
UPDATE STATISTICS <table_name> <index_name> |
UPDATE STATISTICS parameters
The UPDATE STATISTICS statement has parameters that define table sampling rate.
FULLSCAN – new statistics are created by scanning all table/view rows and the number of Rows Sampled is equal to the number of the table/view rows. For tables with a small number of rows, even when this parameter is not specified, all table/view rows are sampled.
|
1 2 3 |
UPDATE STATISTICS Person.Address WITH FULLSCAN |
Using SAMPLE 100 PERCENT gives the same results as using the FULLSCAN parameter. SAMPLE and FULLSCAN cannot be used in the same UPDATE STATISTICS statement.
|
1 2 3 |
UPDATE STATISTICS Person.Address WITH SAMPLE 10 PERCENT |

Don’t be surprised that even though you specified the exact percentage of the rows to be scanned, the statistics are created by sampling all table rows. This is what SQL Server does for tables with a small number of rows. This behavior provides accurate statistics for small tables, as updating statistics for small tables cost is less than the inaccurate statistics cost.
When SQL Server statistics on large tables are updated with the SAMPLE parameter, sampling percent isn’t ignored, and the number of sampled rows in lower than the number of table rows. The percentage specified is taken as the minimal number of rows that will be sampled. It’s usually higher.
Updating statistics on large tables takes much more time, and taking the sample percentage into account significantly reduces the time needed to update statistics.
We measured the time needed to update SQL Server statistics on the Person.Address table before the records were added, when the table had 19,614 rows. It took less than a second.
|
1 2 3 4 5 |
SET STATISTICS TIME ON UPDATE STATISTICS Person.Address WITH SET STATISTICS TIME OFF |
SQL Server Execution Times: CPU time = 203 ms, elapsed time = 552 ms.
After adding more than a million rows to the Person.Address table, we updated its statistics using a ten percent sampling rate and measured the time needed to complete.
|
1 2 3 4 5 |
SET STATISTICS TIME ON UPDATE STATISTICS Person.Address WITH SAMPLE 10 PERCENT SET STATISTICS TIME OFF |
The time needed was more than 6 minutes.
SQL Server Execution Times: CPU time = 2438 ms, elapsed time = 385063 ms.

The number of the sampled rows is slightly higher than 10% of the total row number. This example shows how expensive statistics updates on large tables are and why the SAMPLE option should be used whenever possible.
NORECOMPUTE – after the statistics are updated, the AUTO_UPDATE_STATISTICS option is set to off, and no further auto-updates of the statistics are possible, unless the option is set back to on. The statistics can be updated only by executing the UPDATE STATISTICS statement or sp_updatestats stored procedure.
|
1 2 3 |
UPDATE STATISTICS Person.Address WITH NORECOMPUTE |
Is the default sampling rate good enough?
In the example above, we showed how time-consuming updating statistics can be for a large number of table rows, and how the SAMPLE parameter can help. The next question is whether you should use the default SQL Server sampling rate, or specify your custom sampling rate using the SAMPLE parameter. There is no out-of-the-box answer, as it depends on your database structure, usage, data change frequency, performance requirements, etc.
Here are some guidelines that can help you determine the right strategy.
Update the statistics on a table by running UPDATE STATISTICS using the SQL Server default sampling rate (no sampling parameters added). Then, execute DBCC SHOW_STATISTICS to view the statistics and create a screenshot, you will need it for later. Run UPDATE STATISTICS on the same table again, but this time, add the FULLSCAN parameter. View the updated statistics and create a new screenshot.
Compare the All density values for default and custom percentage sampling rate. If the values are different by an order of magnitude, the SQL Server default statistics sampling rate shouldn’t be used, as it provides statistics that are not accurate enough.
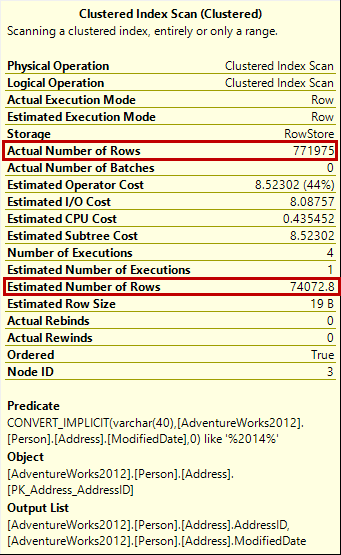
Another useful method is to compare the Actual and Estimated number of rows in a query execution plan. If they are different by an order of magnitude, the SQL Server statistics for the queried table were inaccurate, so investigate it for later executions.
In this article, we showed how to manually update SQL Server statistics, how data is sampled in small and large tables, and gave recommendations how to determine whether manual statistics updates with a custom sampling rate are needed. Keep in mind a performance tradeoff between SQL Server statistics updating and optimal query execution plans.

She has been working with SQL Server since 2005 and has experience with SQL 2000 through SQL 2014.
Her favorite SQL Server topics are SQL Server disaster recovery, auditing, and performance monitoring.
View all posts by Milena "Millie" Petrovic
- Using custom reports to improve performance reporting in SQL Server 2014 – running and modifying the reports - September 12, 2014
- Using custom reports to improve performance reporting in SQL Server 2014 – the basics - September 8, 2014
- Performance Dashboard Reports in SQL Server 2014 - July 29, 2014