
Cuando hablamos acerca del uso de la memoria en SQL Server, a menudo nos referimos a la caché del búfer. Esta es una parte importante de la arquitectura de SQL Server, y es responsable por la habilidad de consultar datos frecuentemente accedidos extremadamente rápido. Saber cómo funciona la caché del búfer nos permitirá asignar apropiadamente memoria en SQL Server, estimar de manera precisa cómo las bases de datos están accediendo los datos, y asegura que no haya ineficiencias en nuestro código que causen que datos excesivos sean enviados a la caché.
¿Qué hay en la caché del búfer?
Los discos duros son lentos, la memoria es rápida. Este es un hecho de la naturaliza para cualquiera que trabaja con computadoras. Incluso los SSDs son lentos en comparación a la memoria de alto rendimiento. La manera en que el software lidia con este problema es escribir los datos desde el almacenamiento lento a la memoria rápida. Una vez cargadas, sus aplicaciones favoritas pueden desempeñarse muy rápidamente y sólo necesitan volver al disco cuando nuevos datos son necesarios. Este hecho en la computación es una parte importante de la arquitectura de SQL Server.
Cuando sea que los datos son escritos a o leídos desde una base de datos SQL Server, serán copiados a la memoria por el administrador del búfer. La caché del búfer (también conocida como grupo de búferes) usará tanta memoria como esté asignada a ella para mantener tantas páginas de datos como sea posible. Cuando la caché del búfer se llena, datos más antiguos y menos usados serán purgados para hacer campo para datos más nuevos.
Los datos son almacenados en páginas de 8k dentro de la caché del búfer y pueden ser referidos como páginas “limpias” o “sucias”. Una página sucia es una que ha sido cambiada desde la última vez que fue escriba al disco y es el resultado de una operación de escritura contra el índice o los datos de tabla. Las páginas limpias son aquellas que no han cambiado, y los datos dentro de ellas aún coinciden con lo que está en el disco. Los puntos de control son publicados automáticamente en el fondo por SQL Server y escribirán páginas sucias al disco para crear un buen punto conocido de restauración en el evento de un colapso u otra situación desafortunada del servidor.
Usted puede ver una vista general del estado actual del uso de la memoria en SQL Server revisando la DMV sys.dm_os_sys_info DMV:
|
1 2 3 4 5 6 |
SELECT physical_memory_kb, virtual_memory_kb, committed_kb, committed_target_kb FROM sys.dm_os_sys_info; |
Los resultados de esta consulta me dicen algo acerca del uso de la memoria en mi servidor:

Aquí está lo que significan las columnas:
physical_memory_kb: Memoria física total instalada en el servidor.
virtual_memory_kb: Cantidad total de memoria virtual disponible para SQL Server. Idealmente, no queremos utilizar esto tan a menudo como la memoria virtual (usar un archivo de página en el disco o en algún otro lugar que no sea la memoria, va a ser significativamente más lento que la memoria).
Committed_kb: La cantidad de memoria actualmente asignada por la caché del búfer para el uso por páginas de base de datos.
Committed_target_kb: Esta es la cantidad de memoria que la caché del búfer “quiere” usar. Si la cantidad actualmente en uso (indicada por commited_kb) es más alta que esta cantidad, entonces el administrador del búfer comenzará a remover páginas antiguas desde la memoria. Si la cantidad actualmente en uso es menor, entonces el administrador del búfer asignará más memoria para nuestros datos.
EL uso de la memoria es crítico para el desempeño de SQL Server – si no hay suficiente memoria disponible para servir nuestras consultas comunes, entonces usaremos muchos más recursos leyendo datos desde el disco, sólo para descartarlos y leerlos de nuevo después.
¿Cómo podemos usar las métricas de la caché del búfer?
Nosotros podemos acceder a la información acerca de la caché del búfer usando la vista dinámica de administración sys.dm_os_buffer_descriptors, la cual provee todo lo que usted siempre quiso saber acerca de los datos almacenados en la memoria por SQL Server, pero temía preguntar. Dentro de esta vista, usted encontrará una sola fila por descriptor de búfer, lo que da identificación única y provee algo de información acerca de cada página en la memoria. Note que, en un servidor con bases de datos grandes, puede tomar un poco de tiempo consultar esta vista.
Una métrica útil que es fácil de obtener es la medida del uso de la caché del búfer por la base de datos en el servidor:
|
1 2 3 4 5 6 7 8 |
SELECT databases.name AS database_name, COUNT(*) * 8 / 1024 AS mb_used FROM sys.dm_os_buffer_descriptors INNER JOIN sys.databases ON databases.database_id = dm_os_buffer_descriptors.database_id GROUP BY databases.name ORDER BY COUNT(*) DESC; |
Esta consulta retorna, ordenada desde más páginas a menos, la cantidad de memoria consumida por cada base de datos en la caché del búfer:
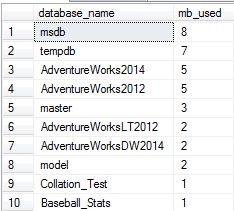
Mi servidor local no es increíblemente emocionante ahora…pero si decidiéramos correr una variedad de consultas contra AdventureWorks2014, podríamos correr nuestra consulta desde arriba de nuevo para verificar el impacto que tuvo en la caché del búfer:
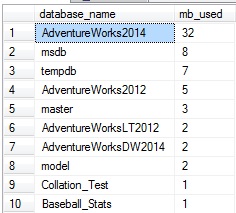
Mientras que no enloquecí aquí, mi consulta al azar sí incrementó la cantidad de datos en la caché del búfer para AdventureWorks2014 en 27MB. Esta consulta puede ser una manera útil de determinar rápidamente qué base de datos cuenta con el mayor uso de memoria en la caché del búfer. En una arquitectura multiusuario, o en un servidor en el cual hay muchas bases de datos clave compartiendo recursos, este puede ser un método rápido para hallar la base de datos que está desempeñándose pobremente o acaparando la memoria en cualquier momento.
De forma similar, podemos ver los totales como una página o un conteo de bytes:
|
1 2 3 4 |
SELECT COUNT(*) AS buffer_cache_pages, COUNT(*) * 8 / 1024 AS buffer_cache_used_MB FROM sys.dm_os_buffer_descriptors; |
Esto retorna una sola fila conteniendo el número de páginas en la caché del búfer, así como la memoria consumida por ellas:

Dado que una página es de 8KB, podemos convertir el número de páginas en megabytes multiplicando por 8 para obtener KB, y luego dividir por 1024 para llegar a MB.
Podemos subdividir esto más allá y ver cómo la caché del búfer es usada por objetos específicos. Esto puede proveer mucha más información acerca del uso de la memoria, ya que podemos determinar qué tablas son acaparadoras de memoria. Adicionalmente, podemos verificar algunas métricas interesantes, como qué porcentaje de una tabla está en la memoria actualmente, o qué tablas son infrecuentemente usadas (o no). La siguiente consulta retornará las páginas en búfer y el tamaño por tabla:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT objects.name AS object_name, objects.type_desc AS object_type_description, COUNT(*) AS buffer_cache_pages, COUNT(*) * 8 / 1024 AS buffer_cache_used_MB FROM sys.dm_os_buffer_descriptors INNER JOIN sys.allocation_units ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id INNER JOIN sys.partitions ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3)) OR (allocation_units.container_id = partitions.partition_id AND type IN (2))) INNER JOIN sys.objects ON partitions.object_id = objects.object_id WHERE allocation_units.type IN (1,2,3) AND objects.is_ms_shipped = 0 AND dm_os_buffer_descriptors.database_id = DB_ID() GROUP BY objects.name, objects.type_desc ORDER BY COUNT(*) DESC; |
Las tablas de sistema son excluidas, y esto sólo jalará datos para la base de datos actual. Las vistas indexadas no serán incluidas, ya que sus índices son entidades distintas de las tablas de las que derivan- La combinación en sys.partitions contiene dos partes para manejar los índices, así como las pilas. Los datos mostrados aquí incluyen todos los índices en la tabla, así como la pila, si no hay ninguna definida.
Un segmento de los resultados de esto es el siguiente (para AdventureWorks2014):
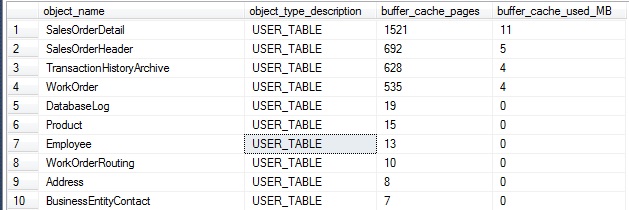
De forma similar, podemos dividir los datos por índice en lugar de por tabla, proveyendo incluso más granularidad en el uso de la caché del búfer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT indexes.name AS index_name, objects.name AS object_name, objects.type_desc AS object_type_description, COUNT(*) AS buffer_cache_pages, COUNT(*) * 8 / 1024 AS buffer_cache_used_MB FROM sys.dm_os_buffer_descriptors INNER JOIN sys.allocation_units ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id INNER JOIN sys.partitions ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3)) OR (allocation_units.container_id = partitions.partition_id AND type IN (2))) INNER JOIN sys.objects ON partitions.object_id = objects.object_id INNER JOIN sys.indexes ON objects.object_id = indexes.object_id AND partitions.index_id = indexes.index_id WHERE allocation_units.type IN (1,2,3) AND objects.is_ms_shipped = 0 AND dm_os_buffer_descriptors.database_id = DB_ID() GROUP BY indexes.name, objects.name, objects.type_desc ORDER BY COUNT(*) DESC; |
Esta consulta es casi la misma que nuestra última, excepto que hacemos una combinación adicional a sys.indexes, y agrupamos en el nombre del índice en adición al nombre de la tabla/vista. Los resultados proveen incluso más detalles acerca de cómo la caché del búfer está siendo usada, y pueden ser valiosos en tablas con muchos índices de uso variado:
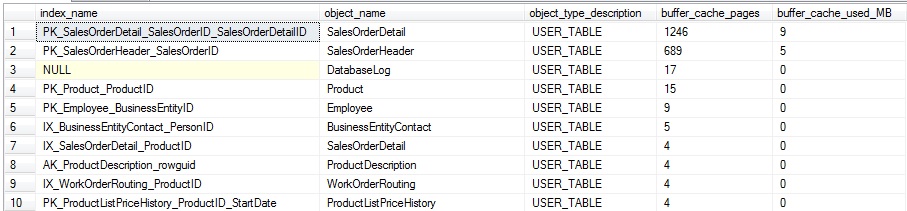
Los resultados pueden ser útiles cuando se trata de determinar el nivel general de uso para un índice específico en cualquier momento. Adicionalmente, nos permite estimar cuánto de un índice está siendo leído, comparado con su tamaño general.
Para recolectar el porcentaje de cada tabla que está en la memoria, podemos poner esa consulta en un CTE y comparar las páginas en memoria versus el total para cada tabla:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
WITH CTE_BUFFER_CACHE AS ( SELECT objects.name AS object_name, objects.type_desc AS object_type_description, objects.object_id, COUNT(*) AS buffer_cache_pages, COUNT(*) * 8 / 1024 AS buffer_cache_used_MB FROM sys.dm_os_buffer_descriptors INNER JOIN sys.allocation_units ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id INNER JOIN sys.partitions ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3)) OR (allocation_units.container_id = partitions.partition_id AND type IN (2))) INNER JOIN sys.objects ON partitions.object_id = objects.object_id WHERE allocation_units.type IN (1,2,3) AND objects.is_ms_shipped = 0 AND dm_os_buffer_descriptors.database_id = DB_ID() GROUP BY objects.name, objects.type_desc, objects.object_id) SELECT PARTITION_STATS.name, CTE_BUFFER_CACHE.object_type_description, CTE_BUFFER_CACHE.buffer_cache_pages, CTE_BUFFER_CACHE.buffer_cache_used_MB, PARTITION_STATS.total_number_of_used_pages, PARTITION_STATS.total_number_of_used_pages * 8 / 1024 AS total_mb_used_by_object, CAST((CAST(CTE_BUFFER_CACHE.buffer_cache_pages AS DECIMAL) / CAST(PARTITION_STATS.total_number_of_used_pages AS DECIMAL) * 100) AS DECIMAL(5,2)) AS percent_of_pages_in_memory FROM CTE_BUFFER_CACHE INNER JOIN ( SELECT objects.name, objects.object_id, SUM(used_page_count) AS total_number_of_used_pages FROM sys.dm_db_partition_stats INNER JOIN sys.objects ON objects.object_id = dm_db_partition_stats.object_id WHERE objects.is_ms_shipped = 0 GROUP BY objects.name, objects.object_id) PARTITION_STATS ON PARTITION_STATS.object_id = CTE_BUFFER_CACHE.object_id ORDER BY CAST(CTE_BUFFER_CACHE.buffer_cache_pages AS DECIMAL) / CAST(PARTITION_STATS.total_number_of_used_pages AS DECIMAL) DESC; |
Esta consulta combina nuestro conjunto previo de datos con una consulta en sys.dm_db_partition_stats para comparar lo que está actualmente en la caché del búfer versus el espacio total usado por cualquier tabla dada. Las muchas operaciones CAST al final ayudan a evitar el truncado y hacen al resultado final fácil de leer. Los resultados en mi servidor local son los siguientes:
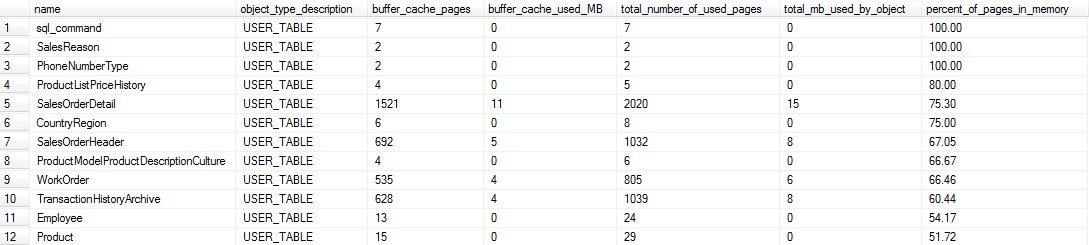
Estos datos nos dicen qué tablas están las zonas calientes en nuestra base de datos, y con un poco de conocimiento de su uso de aplicación, podemos determinar cuáles simplemente tienen demasiados datos residiendo en la memoria. Las tablas pequeñas son probablemente no muy importantes para nosotros aquí. Por ejemplo, las primeras cuatro en la salida anterior están debajo de un megabyte y si quisiéramos omitirlas, podríamos filtrar los resultados para retornar solamente tablas más grandes que un tamaño específico de interés.
Por otra parte, estos datos nos dicen que ¾ de SalesOrderDetail está en la caché del búfer. Si esto pareciera inusual, consultaría la caché del plan de consultas y determinaría si hay alguna consulta ineficiente en la tabla que está seleccionando *, o una cantidad excesivamente grande de datos. Combinando nuestras métricas desde la caché del búfer y la caché del plan, podemos idear nuevas maneras de determinar con precisión mañas consultas o aplicaciones que están jalando muchos más datos de lo que requieren.
Esta consulta puede ser modificada para proveer el porcentaje de un índice que está siendo usado también, de forma similar a cómo recolectamos el porcentaje de una tabla usada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
SELECT indexes.name AS index_name, objects.name AS object_name, objects.type_desc AS object_type_description, COUNT(*) AS buffer_cache_pages, COUNT(*) * 8 / 1024 AS buffer_cache_used_MB, SUM(allocation_units.used_pages) AS pages_in_index, SUM(allocation_units.used_pages) * 8 /1024 AS total_index_size_MB, CAST((CAST(COUNT(*) AS DECIMAL) / CAST(SUM(allocation_units.used_pages) AS DECIMAL) * 100) AS DECIMAL(5,2)) AS percent_of_pages_in_memory FROM sys.dm_os_buffer_descriptors INNER JOIN sys.allocation_units ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id INNER JOIN sys.partitions ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3)) OR (allocation_units.container_id = partitions.partition_id AND type IN (2))) INNER JOIN sys.objects ON partitions.object_id = objects.object_id INNER JOIN sys.indexes ON objects.object_id = indexes.object_id AND partitions.index_id = indexes.index_id WHERE allocation_units.type IN (1,2,3) AND objects.is_ms_shipped = 0 AND dm_os_buffer_descriptors.database_id = DB_ID() GROUP BY indexes.name, objects.name, objects.type_desc ORDER BY CAST((CAST(COUNT(*) AS DECIMAL) / CAST(SUM(allocation_units.used_pages) AS DECIMAL) * 100) AS DECIMAL(5,2)) DESC; |
Dado que sys.allocation_units provee algo de información acerca del tamaño de nuestros índices, evitamos la necesidad de CTEs y conjuntos de datos adicionales de dm_db_partition_stats. Aquí está un pedazo de los resultados, mostrando el tamaño del índice (MB y páginas) y el espacio usado de la caché del búfer (MB y páginas):

Si estuviéramos poco interesados en tablas/índices pequeños, podríamos añadir una cláusula HAVING a la consulta para filtrar por un índice que es más pequeño que un tamaño especificado, en MB o páginas. Estos datos proveen una vista de la eficiencia de las consultas en índices específicos y podría asistir en la limpieza de índices, el ajuste de índices o algún ajuste más granular del uso de la memoria en su SQL Server.
Una columna interesante en dm_os_buffer_descriptors es free_space_in_bytes. Esta columna nos dice cuán llena está cada página en la caché del búfer, y por lo tanto provee un indicador del espacio potencial desperdiciado o la ineficiencia. Podemos determinar el porcentaje de páginas que han sido tomadas por el espacio libre, en lugar de datos, para cada base de datos en nuestro servidor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
WITH CTE_BUFFER_CACHE AS ( SELECT databases.name AS database_name, COUNT(*) AS total_number_of_used_pages, CAST(COUNT(*) * 8 AS DECIMAL) / 1024 AS buffer_cache_total_MB, CAST(CAST(SUM(CAST(dm_os_buffer_descriptors.free_space_in_bytes AS BIGINT)) AS DECIMAL) / (1024 * 1024) AS DECIMAL(20,2)) AS buffer_cache_free_space_in_MB FROM sys.dm_os_buffer_descriptors INNER JOIN sys.databases ON databases.database_id = dm_os_buffer_descriptors.database_id GROUP BY databases.name) SELECT *, CAST((buffer_cache_free_space_in_MB / NULLIF(buffer_cache_total_MB, 0)) * 100 AS DECIMAL(5,2)) AS buffer_cache_percent_free_space FROM CTE_BUFFER_CACHE ORDER BY buffer_cache_free_space_in_MB / NULLIF(buffer_cache_total_MB, 0) DESC |
Esto retorna una fila por base de datos que muestra la agregación de espacio libre por base de datos, sumada a través de todas las páginas en la caché del búfer para esa base de datos particular:
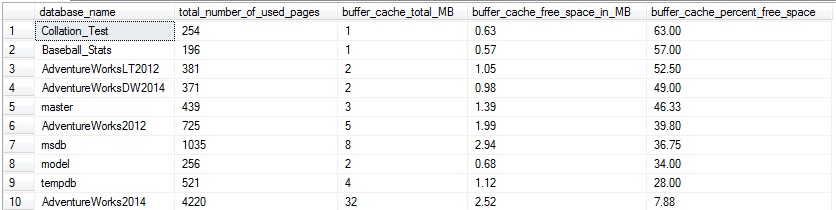
Esto es interesante, pero no muy útil todavía debido a que estos resultados no son muy específicos. Nos dicen que una base de datos puede tener un poco de espacio desperdiciado, pero no mucho sobre qué tablas son las causantes. Tomemos el mismo enfoque que hicimos anteriormente y devolvemos espacio libre por tabla en una base de datos dada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT objects.name AS object_name, objects.type_desc AS object_type_description, COUNT(*) AS buffer_cache_pages, CAST(COUNT(*) * 8 AS DECIMAL) / 1024 AS buffer_cache_total_MB, CAST(SUM(CAST(dm_os_buffer_descriptors.free_space_in_bytes AS BIGINT)) AS DECIMAL) / 1024 / 1024 AS buffer_cache_free_space_in_MB, CAST((CAST(SUM(CAST(dm_os_buffer_descriptors.free_space_in_bytes AS BIGINT)) AS DECIMAL) / 1024 / 1024) / (CAST(COUNT(*) * 8 AS DECIMAL) / 1024) * 100 AS DECIMAL(5,2)) AS buffer_cache_percent_free_space FROM sys.dm_os_buffer_descriptors INNER JOIN sys.allocation_units ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id INNER JOIN sys.partitions ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3)) OR (allocation_units.container_id = partitions.partition_id AND type IN (2))) INNER JOIN sys.objects ON partitions.object_id = objects.object_id WHERE allocation_units.type IN (1,2,3) AND objects.is_ms_shipped = 0 AND dm_os_buffer_descriptors.database_id = DB_ID() GROUP BY objects.name, objects.type_desc, objects.object_id HAVING COUNT(*) > 0 ORDER BY COUNT(*) DESC; |
Esto devuelve una fila por tabla o vista indexada que tiene al menos una página en la memoria caché del búfer ordenada primeramente por aquellos que tienen la mayor cantidad de páginas en memoria.
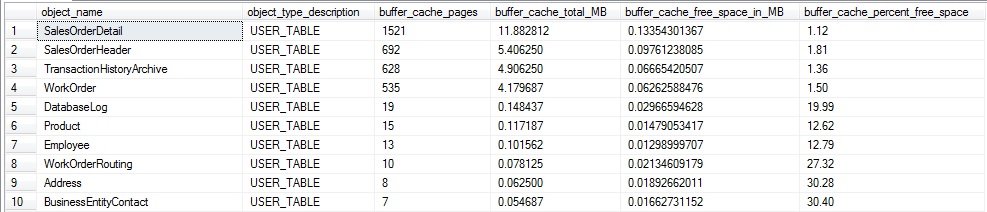
¿Qué significa exactamente? Cuanto más espacio libre por página existe en promedio, más páginas hay que leer para retornar los datos que estamos buscando. Además, se requieren más páginas para almacenar datos, lo que significa que se necesita más espacio en la memoria y en disco para mantener nuestros datos. El espacio perdido también significa más E/S para obtener los datos que necesitamos y las consultas se ejecutan más tiempo de lo necesario a medida que se recuperan estos datos.
La causa más común de un exceso de espacio libre son las tablas con filas muy amplias. Puesto que una página es de 8k, si una fila pasó a ser de 5k, nunca seríamos capaces de encajar una sola fila en una página, y siempre habrá ese extra de ~3k de espacio libre que no se puede utilizar. Las tablas con muchas operaciones de inserción aleatoria pueden ser problemáticas también. Por ejemplo, una clave que no aumenta puede resultar en divisiones de página cuando los datos se escriben en diferente orden. Un GUID sería el peor de los casos, pero cualquier clave que no está aumentando de manera natural puede dar lugar a este problema hasta cierto punto.
A medida que los índices se fragmentan con el tiempo, la fragmentación se verá en parte como un exceso de espacio libre cuando observamos el contenido de la caché del búfer. La mayoría de estos problemas se resuelven con un diseño inteligente de bases de datos y un mantenimiento razonable de la base de datos. Este no es el lugar para entrar en detalles sobre esos temas, pero hay muchos artículos y presentaciones sobre estos temas en la red para su entretenimiento.
Al principio de este artículo, discutimos brevemente qué páginas sucias y limpias son y su correlación con las operaciones de escritura dentro de una base de datos. Dentro de dm_os_buffer_descriptors podemos verificar si una página está limpia o no está usando la columna is_modified. Esta nos dice si una página ha sido modificada por una operación de escritura, pero aún no se ha escrito en disco. Podemos usar esta información para contar las páginas limpias y sucias en la caché del búfer para una base de datos determinada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT databases.name AS database_name, COUNT(*) AS buffer_cache_total_pages, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 1 ELSE 0 END) AS buffer_cache_dirty_pages, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 0 ELSE 1 END) AS buffer_cache_clean_pages, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 1 ELSE 0 END) * 8 / 1024 AS buffer_cache_dirty_page_MB, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 0 ELSE 1 END) * 8 / 1024 AS buffer_cache_clean_page_MB FROM sys.dm_os_buffer_descriptors INNER JOIN sys.databases ON dm_os_buffer_descriptors.database_id = databases.database_id GROUP BY databases.name; |
Esta consulta devuelve el número de páginas y el tamaño de los datos en MB:
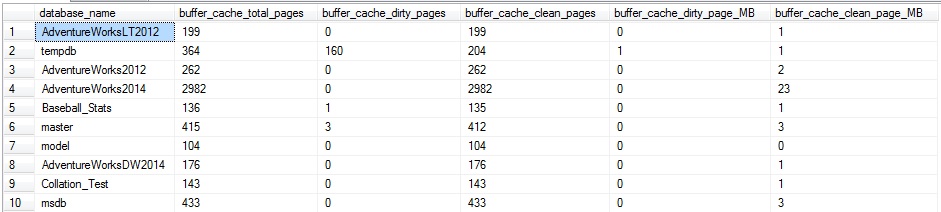
Mi servidor no tiene mucho por el momento. Si corriera una gran sentencia de actualización, podríamos ilustrar qué veríamos cuando más operaciones de escritura están ocurriendo. Corramos la siguiente consulta:
|
1 2 |
UPDATE Sales.SalesOrderDetail SET OrderQty = OrderQty |
Esto es esencialmente una no-operación y no resultará en ningún cambio real a la tabla SalesOrderDetail – pero SQL Server aún pasará por el problema de actualizar cada fila en la tabla para esta columna particular. Si corremos el conteo de páginas sucias/limpias desde arriba, obtendremos algunos resultados interesantes:
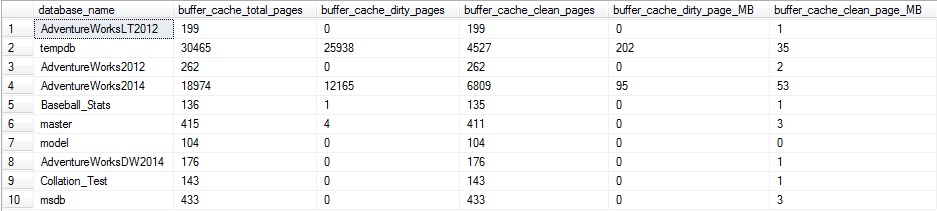
Cerca de 2/3 de las páginas para AdventureWorks2014 en la caché del búfer están sucios. Adicionalmente, TempDB también tiene bastante actividad, lo cual es indicativo del desencadenador update/insert/delete en la tabla, lo que causó que se ejecutara una gran cantidad de T-SQL adicional. El desencadenador causó que haya bastantes lecturas contra AdventureWorks2014, así como la necesidad de trabajo de tablas en TempDB para procesar esas operaciones adicionales.
Como antes, podemos dividir esta tabla o índice para recolectar datos más granulares acerca del uso de la caché del búfer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
SELECT indexes.name AS index_name, objects.name AS object_name, objects.type_desc AS object_type_description, COUNT(*) AS buffer_cache_total_pages, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 1 ELSE 0 END) AS buffer_cache_dirty_pages, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 0 ELSE 1 END) AS buffer_cache_clean_pages, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 1 ELSE 0 END) * 8 / 1024 AS buffer_cache_dirty_page_MB, SUM(CASE WHEN dm_os_buffer_descriptors.is_modified = 1 THEN 0 ELSE 1 END) * 8 / 1024 AS buffer_cache_clean_page_MB FROM sys.dm_os_buffer_descriptors INNER JOIN sys.allocation_units ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id INNER JOIN sys.partitions ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3)) OR (allocation_units.container_id = partitions.partition_id AND type IN (2))) INNER JOIN sys.objects ON partitions.object_id = objects.object_id INNER JOIN sys.indexes ON objects.object_id = indexes.object_id AND partitions.index_id = indexes.index_id WHERE allocation_units.type IN (1,2,3) AND objects.is_ms_shipped = 0 AND dm_os_buffer_descriptors.database_id = DB_ID() GROUP BY indexes.name, objects.name, objects.type_desc ORDER BY COUNT(*) DESC; |
Los resultados muestran el uso de la caché del búfer por índice, mostrando cuántas páginas en la memoria están limpias o sucias:
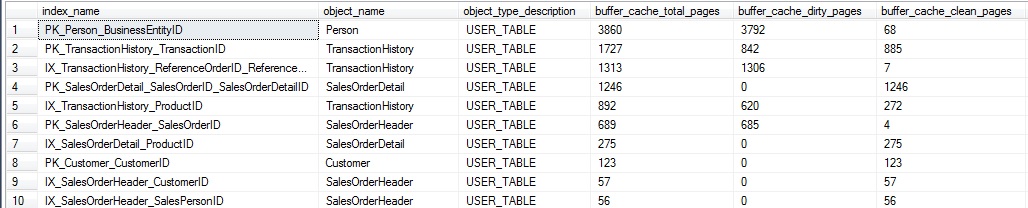
Estos datos proveen una idea de la actividad de escritura en un índice dado en este punto del tiempo. Si fuera rastrado en un periodo de días o semanas, podríamos comenzar a estimar la actividad de escritura general del índice y proyectar una tendencia. Esta investigación podría ser útil si usted estuviera buscando entender el mejor nivel posible de aislamiento para usarse en una base de datos, o si esos reportes que siempre son corridos con READ UNCOMMITED podrían ser más susceptibles a lecturas sucias que lo pensado originalmente. En este caso específico, las páginas sucias todas se relacionan con la consulta de actualización que corrimos previamente, y por lo tanto abarcan un conjunto algo limitado.
DBCC DROPCLEANBUFFERS
Un comando DBCC que es a menudo usado como una forma de probar una consulta y estimar de forma precisa la velocidad de ejecución, es DBCC DROPCLEANBUFFERS. Cuando se corre, este comando remueve todas las páginas limpias de la memoria para un servidor entero de base de datos, dejando atrás solamente páginas sucias, las cuales serán típicamente una pequeña minoría de datos.
DBCC DROPCLEANBUFFERS es un comando que típicamente debería ser corrido sólo en un ambiente que no sea de producción, e incluso entonces, sólo cuando no se está realizando pruebas de desempeño o carga. El resultado de este comando es que la caché del búfer terminará mayormente vacía. Cualquier consulta corrida después de este punto necesitará usar lecturas físicas para traer de vuelta los datos a la caché desde su sistema de almacenamiento, lo cual es, como dijimos antes, mucho más lento que la memoria.
Después de correr este comando en mi servidor local, la consulta de páginas sucias/impías de más antes retorna lo siguiente:

¡Eso es todo lo que queda! Repitiendo mi aviso anterior: Trate este comando de manera similar a DBCC FREEPROCCACHEI en que no debería ser corrido en ningún servidor de producción a menos que usted esté absolutamente seguro de lo que hace.
Esta puede ser una herramienta útil de desarrollo debido a que usted puede correr una consulta en un ambiente de pruebas de desempeño una y otra vez sin ningún cambio en la velocidad/eficiencia debido a que se está enviando los datos de la memoria a la caché. Elimine los datos limpios del búfer entre ejecuciones y estará listo. Esto puede proveer resultados engañosos, aunque en esos ambiente de producción siempre usarán la caché del búfer, y no leerán desde su sistema de almacenamiento a menos que sea necesario. Eliminar los búferes limpios llevará a tiempos de ejecución más lentos que lo que se vería de otra forma, pero puede proveer una manera de probar las consultas en un ambiente consistente con cada ejecución.
Entendiendo todas estas advertencias, siéntase libre de usar esto como lo necesite para probar y obtener una visión acerca del desempeño de las consultas, las páginas leídas en la memoria como resultado de una consulta, las páginas sucias creadas por una sentencia de escritura, y así por el estilo.
Expectativa de Vida de las Páginas
Cuando se discute acerca del desempeño de la memoria en SQL Server, es poco probable que avancemos unos minutos antes de que alguien pregunte acerca de la expectativa de vida de las páginas (PLE, por sus siglas en inglés). PLE es una medida de, en promedio, cuánto tiempo (en segundos) permanecerá una página en la memoria sin ser accedida, punto después del cual es removida. Esta es una métrica que deseamos que sea más alta en la medida que deseamos que nuestros datos importantes permanezcan en la caché del búfer por tanto tiempo como sea posible. Cuando la PLE se ralentiza, los datos están siendo constantemente leídos desde el disco (alias ‘lento’) a la caché del búfer, removidos desde la caché y probablemente leídos desde el disco de nuevo en un futuro cercano. ¡Esta es la receta para un SQL Server lento (y frustrante)!
Para ver la PLE actual en un servidor, usted puede correr la siguiente consulta, la cual pondrá el valor actual desde la vista de administración dinámica de conteo de desempeño:
|
1 2 3 4 5 |
SELECT * FROM sys.dm_os_performance_counters WHERE dm_os_performance_counters.object_name LIKE '%Buffer Manager%' AND dm_os_performance_counters.counter_name = 'Page life expectancy'; |
Los resultados se ven así:

cntr_value es el valor del contador de desempeño, y en mi silencioso servidor local es 210,275 segundos. Dado que muy pocos datos son leídos o escritos en mi SQL Server, la necesidad de remover datos desde la caché del búfer es baja, y por tanto la PLE es absurdamente alta. En un servidor de producción altamente usado, la PLE sería casi con seguridad más baja.
Si su servidor tiene una arquitectura NUMA (acceso de memoria no uniforme), entonces usted deseará considerar una PLE para cada nodo separadamente, lo cual puede ser hecho con la siguiente consulta:
|
1 2 3 4 5 |
SELECT * FROM sys.dm_os_performance_counters WHERE dm_os_performance_counters.object_name LIKE '%Buffer Node%' AND dm_os_performance_counters.counter_name = 'Page life expectancy'; |
En un servidor sin NUMA, estos valores serán idénticos. En un servidor con una arquitectura NUMA, habrá múltiples filas PLE retornadas, todas ellas se sumarán al total dado para el administrador del búfer como un todo. Si usted está trabajando con NUMA, asegúrese de considerar PLE en cada nodo, en adición al total, ya que es posible que un nodo sea un cuello de botella, mientras que el total general se ve aceptable.
La pregunta más obvia ahora es, “¿Cuál es un buen valor para la PLE?” Para responder esta pregunta, necesitamos revisar más profundamente en el servidor para ver cuánta memoria tiene, y cuál debería ser el volumen esperado de datos siendo escritos o leídos. 300 segundos es a menudo citado como un buen valor para la PLE, pero como muchas respuestas fáciles y rápidas, esta seguramente es incorrecta.
Antes de considerar cómo debería verse la PLE, consideremos un poco más lo que significa. Consideremos un servidor que tiene 256GB de RAM, de lo cual 192GB están asignados a SQL Server en su configuración. Reviso la vista dm_os_sys_info y encuentro que actualmente hay cercan de 163GB enviados a la caché del búfer. Finalmente, reviso el contador de desempeño arriba y encuentro que la PLE en este servidor es 2000 segundos.
Basado en estas métricas, podemos saber que tenemos 163GB de memoria disponible para la caché del búfer, y los datos existirán ahí por cerca de 2000 segundos. Esto significa que estamos leyendo, en promedio, 163GB por cada 2000 segundos, lo que resulta ser aproximadamente 83MB/segundo. Este número es muy útil, ya que nos da un indicador claro de cuán activamente está siendo accedido nuestro SQL Server por aplicaciones o procesos. Antes de considerar qué es un buen PLE, necesitamos preguntarnos a nosotros mismos algunas cosas:
- ¿Cuánto tráfico esperamos en promedio por nuestras aplicaciones/servicios?
- ¿Hay momentos “especiales” cuando los respaldos, el mantenimiento de índices, el archivado, DBCC CheckDB, u otros procesos puedan causar que la PLE se vuelva muy lenta?
- ¿Es la latencia un problema? ¿Hay esperas medibles que están causando que las aplicaciones se desempeñen pobremente?
- ¿Hay esperas IO significativas en el servidor?
- ¿Qué consultas esperamos que lean la mayor parte de los datos?
En otras palabras, ¡conozca sus datos! La única respuesta verdadera a la pregunta de la PLE es que un valor bueno de PLE es uno que representa el desempeño óptimo del servidor con suficiente espacio libre para responder por el crecimiento y los picos de uso. Por ejemplo, tomemos el servidor de más antes, el cual tiene 163GB de memoria dedicada a la caché del búfer, una PLE promedio de 2000 segundos y un rendimiento extrapolado de 83MB/segundo. Después de algo de investigación adicional, descubrí que el desempeño comienza a sufrir cuando la PLE cae por debajo de 1500 segundos. Desde este punto, yo hago diligencias adicionales y me encuentro con que la aplicación crece 1% al mes (en términos de tamaño de datos y rendimiento). Como resultado, puedo extrapolar eso en 6 meses, necesitaría 172GB de RAM dedicado a SQL Server para mantener un nivel similar de PLE al que tengo ahora. A medida que el tiempo pasa, la PLE caerá debajo de 1500 segundo más a menudo, y si se lo deja indefinidamente, la PLE promedio eventualmente caería debajo de 1500 segundos y el desempeño sería consistentemente inaceptable.
Estos cálculos son una parte importante de la planificación de capacidad y asegurarse que cualquier organización está lista para el futuro. Esto nos permite permanecer proactivos y no simplemente añadir RAM al servidor cuando las cosas se vuelven intolerablemente lentas. Las aplicaciones raramente crecen 1% al mes por siempre. En cambio, crecen basadas en una mezcla de crecimiento de datos, nuevas características, cambios de arquitectura y cambios de infraestructura. Esto significa que una aplicación puede crecer 1% al mes, pero después de un lanzamiento mayor de software, vemos que el crecimiento salta a 10% como una ocurrencia de una sola vez.
Conclusión
Dar una ojeada a la caché del búfer es una gran manera de aprender más acerca de cómo sus aplicaciones y procesos están desempeñándose. Con esta información, usted puede rastrear consultas de desempeño pobre, identificar objetos que usan más memoria de la que deberían y mejorar la planificación del servidor para el futuro. Este conocimiento abarca desarrollo, administración, arquitectura y diseño en términos de quién lo impacta y quién puede ser influenciado por él. Como resultado, estar efectivamente a cargo de la administración de la memoria de su servidor hará su vida más fácil mientras que mejora la experiencia para cualquier que use sus SQL Servers.
Vimos bastantes scripts que pueden retornar información útil acerca de la caché del búfer, pero no vimos necesariamente en gran detalle las vistas y T-SQL involucrados. En un futuro artículo revisitaré algunas de las vistas de sistema que usamos en más detalle, así como ahondar en los datos de las páginas y algunas maneras adicionales de usar esta información para el beneficio del bien mayor. Espero que esto sea emocionante y terrorífico al mismo tiempo, y no lo haría de otra forma.
Referencias y lecturas adicionales
Hay muchas referencias que proveen información adicional acerca de las vistas usadas en este artículo, así como lecturas detalladas acerca de muchos de los tópicos presentados.
Este es el artículo MSDN con información de todos los contadores de desempeño del búfer, lo cual puede proveer mucho más detalle acerca del uso del búfer en un servidor:
SQL Server, Buffer Manager Object
El siguiente artículo TechNet tiene un poco más de detalle acerca de dm_os_buffer_descriptors, incluyendo información de seguridad y un análisis columna por columna:
sys.dm_os_buffer_descriptors
TechNet también tiene artículos, como este, que proveen documentación acerca de la caché del búfer y su uso:
Buffer Management
La caché del búfer tiene su contraparte en la caché del plan de consultas, la cual almacena planes de ejecución para volver a usar rápidamente en el futuro. El uso de la memoria por la caché del plan será típicamente significativamente más bajo que la caché del búfer, pero entender cómo funciona y qué visión puede ser recogida de eso es importante. Revise un artículo previo mío para más información acerca de eso, así como referencias adicionales para encontrar datos de ejecución dentro de él:
Searching the SQL Server query plan cache

En su tiempo libre, Ed juega video juegos, películas de ciencia ficción y fantásticas, viajar y ser un gran geek al nivel que sus amigos puedan tolerar.
Vea todas las entradas de Ed Pollack
- Técnicas de optimización de consultas en SQL Server: consejos y trucos de aplicación - September 30, 2019
- Todo lo que querías saber sobre SQL Saturday (pero tenías miedo de preguntar) - April 13, 2018
- Cambios del Optimizador de Consultas en SQL Server 2016 explicados - April 21, 2017