
Introduction
A few weeks back, I was approached by a client who lives in Cape Town, South Africa. The data that he wanted to insert into Master data services was far from clean and he was wondering if there was any way have a positive influence on the data quality.
In today’s fire side chat we are going to have a look at a proof of concept that I put together for the client.
So let us get started.
Getting started
As our point of departure, we shall commence our journey in Master data services.
Opening Microsoft Master data services 2016 we arrive at the landing page (see below).
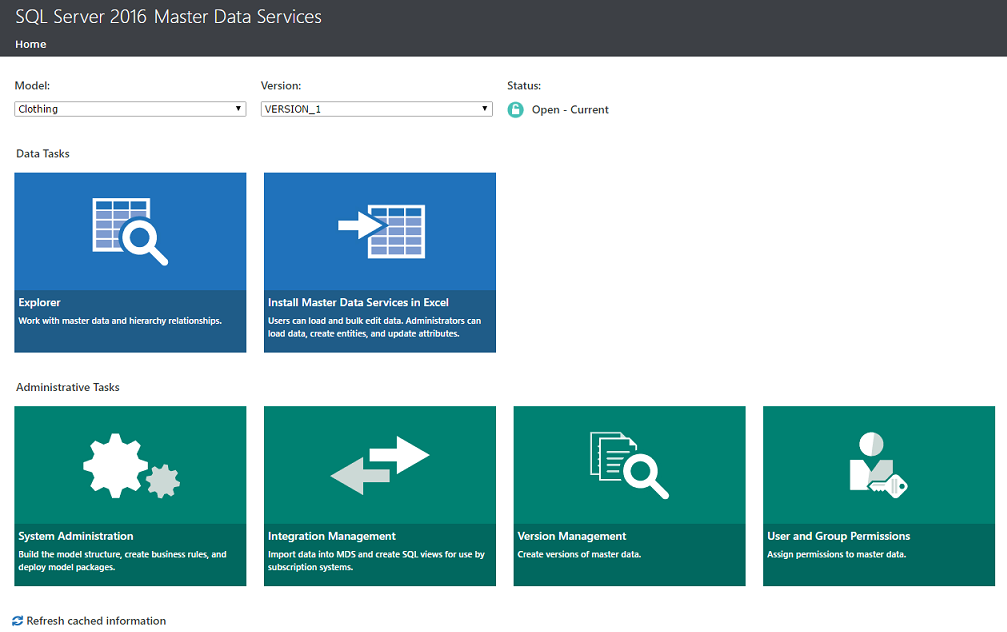
Using a model called “Clothing”, created with some data that I obtained from the Microsoft site (as the client data is obviously confidential), we set the “Model” to “Clothing”. We click upon the “Explorer” tab (see above).
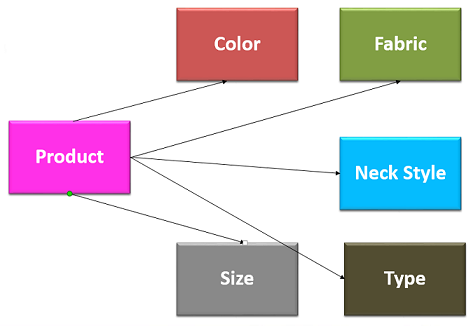
Product is our main table (see above) and each product has several attributes (Colour, Fabric, Neck Style, Type and Size). Each of these attributes forms its own Entity (table).
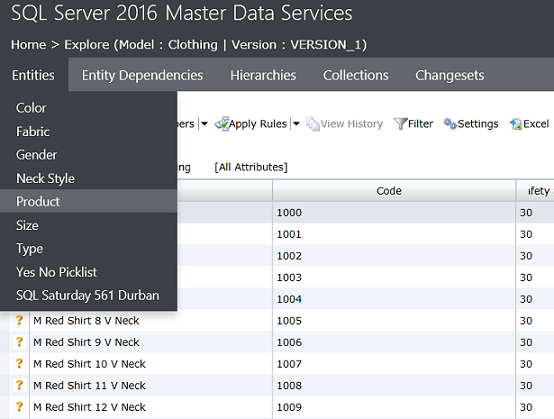
We choose the “Product” Entity (or for us “older folks” a table).
We see the data from the product entity (see above).
In our simple example, users enter raw data (in the form of transactions) and this data is eventually moved to Master data services. Now should a user have entered “Pers” or purple for the colour, this value must be deemed “Invalid”.
So how do we recognise that we have an issue and how do we flag this type of data issue so that the necessary folks are able to rectify the data?
This is where “Data quality services” comes into play.
Now that we have the necessary background of my client’s issue, let us look at a high level view of the strategy that we need to follow.
High level strategy approach
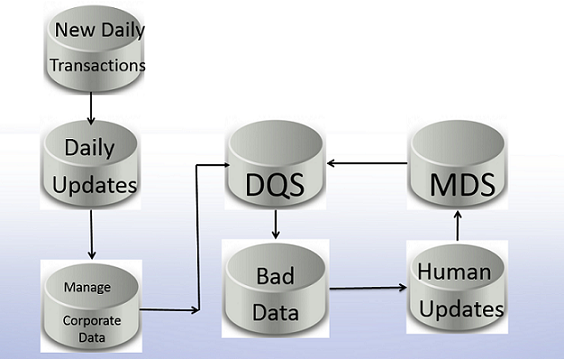
The diagram above shows the “High Level Strategy Approach” that I recommended to the client.
For our discussion, we begin by downloading the Master data services (MDS) data to Data quality services (DQS). For those of us who are not all that familiar with the product, Data quality services is an intelligent piece of software that learns to recognise data patterns and in doing so is able to flag anomalous data. In fact DQS is able to send errors to an “Error” table so that Business Analysts and Data Stewards are able to inspect the data and to rectify any errors.
Setting up the necessary infrastructure within Data quality services
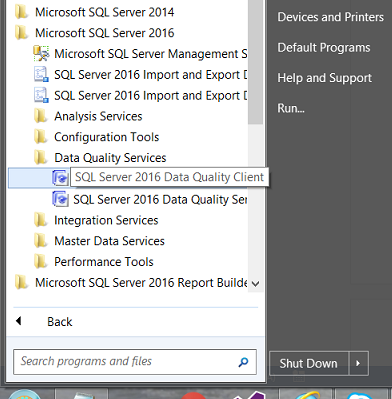
Opening Data quality services from the “Start Menu”, we select “SQL Server 2016 Data Quality Client” from the “Start Menu”(see above).
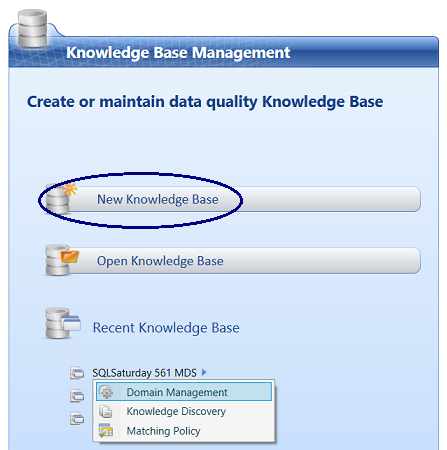
Opening the Data quality services Client we arrive at the home page. We click “New Knowledge Base”.
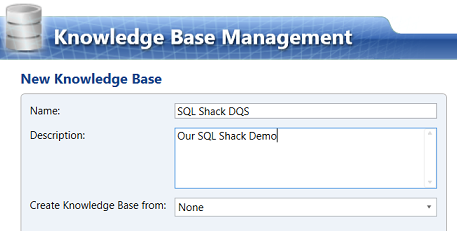
We give our new “Knowledge Base” a name (see above).
We click “Next” to continue.
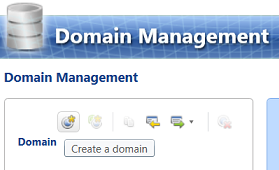
We are taken to the “Domain Management” page. A domain is a nice word for a “table” (see above). The important point being that these domains will contain the ONLY permissible attribute values. If the attribute value that is entered by the user is NOT one in this table, then the whole record will be flagged by DQS as an error and thus invalid. We click “Create a domain”.
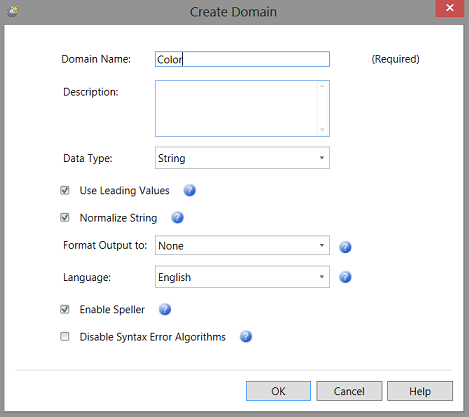
We give our “Domain” a name and define its type. Color will be an Entity on its own HOWEVER it is also an attribute of “Product” as our products have “Color”.
We click “OK” to continue.
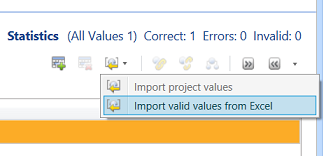
We find ourselves on the “Color” design surface. We click the “Domain Values” tab. Now here is the weird part. We need to import our “Master List” of colours. Thus far, the only way to do so is from a spreadsheet. I have brought this issue up with Microsoft a few years back. The “Color” spreadsheet may be seen below:
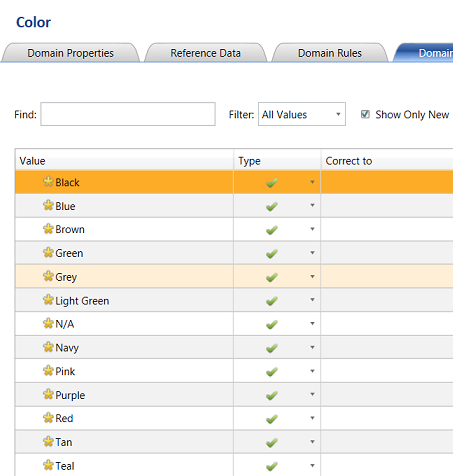
The populated Color Domain may be seen above.
Let us now set a “Domain Rule” that a colour cannot be “Pers” (Purple).
Clicking on the “Domain Rules” tab, we click “Add a new domain rule” as may be seen above.
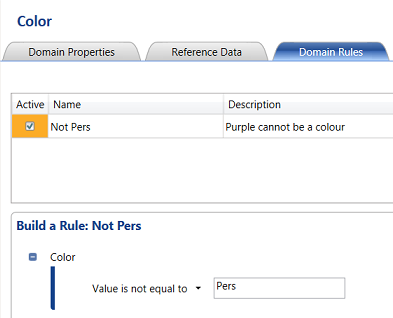
The new “Domain Rule” dialog box opens. We give our rule the name “Not Pers” and give the rule a description. Finally we set the rule: ”Value is not equal to “Pers” (see above). We then “Apply the rule” to leave the screen.
We repeat the same process for the remaining Entities / Domains as may be seen below:
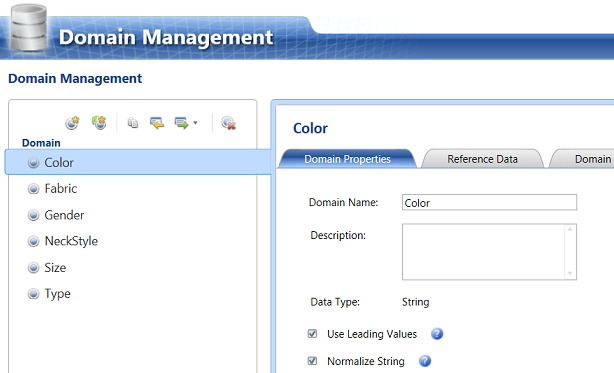
Having created the “Fabric”,”Gender”, “NeckStyle”, “Size” and “Type” Domains we click “Finish” to leave the Domain Management Screen (see below).
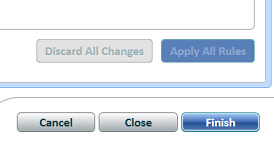
We are asked if we wish to “Publish” the Knowledge Base. We click “Publish”.
Knowledge discovery and matching policy
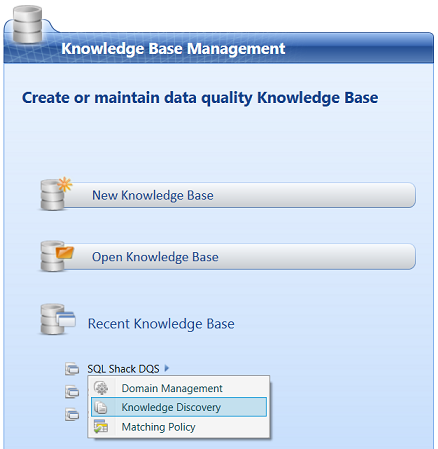
Having completed the “Domain Management” portion of the process, we are now in a position to cover the “Knowledge Discovery” and “Matching Policy” portions of the process.
As I have covered “Knowledge Discovery” and “Matching Policy” exhaustively within another “fire side chat” that we had a year or so back, the reader is referred to the article “How clean is your data”.
At this point, we shall assume that our “Knowledge Base” is complete (having finished the “Knowledge Discovery” and “Matching Policy” processes).
Putting the pieces together
Our next task is to create a SQL Server Integration Services package that will tie all the parts together.

Opening Visual Studio 2015 or SQL Server Data Tools 2010 or greater, we create a SQL Server Integration Services project.
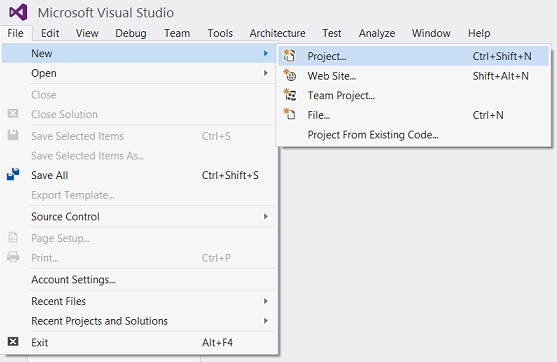
We select “New” and “Project” for the “File” menu (see above).
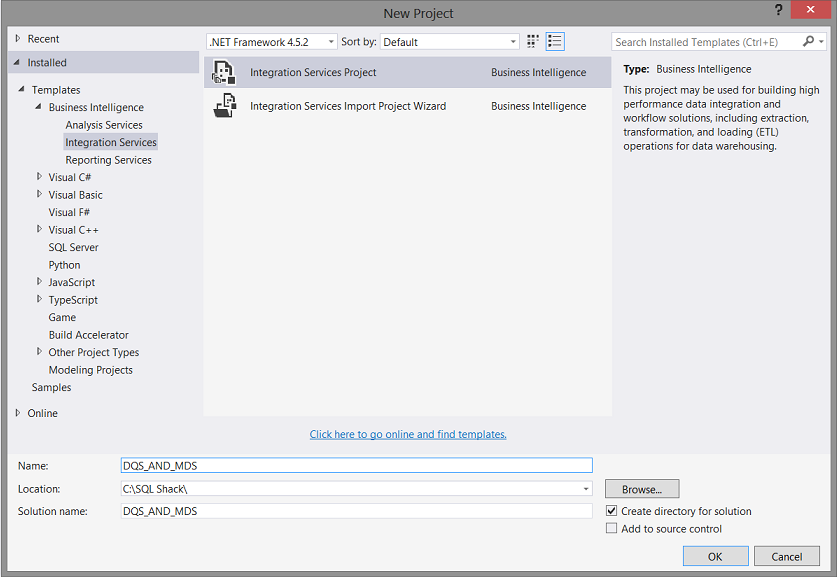
We select an “Integration Services” project and give our project a name (see above).
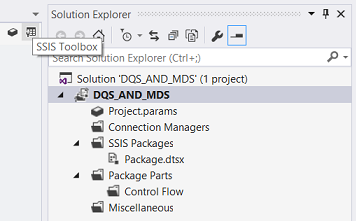
We are brought to our design surface. As an aside, one of the most frustrating things about Visual Studio and SQL Server Data Tools is that if you have used it for Reporting Services or another task in recent days, is that your SSIS tool box disappears. Microsoft calls it a feature, I call it darn frustrating. This said should the tool box not be present, simply click on the tool box icon (see above).
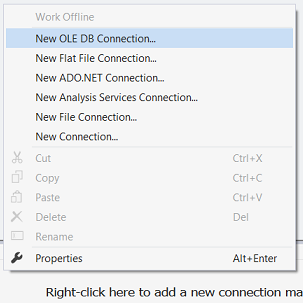
In the “Connection Manager” box, we select the “New OLE DB Connection” option (see above).
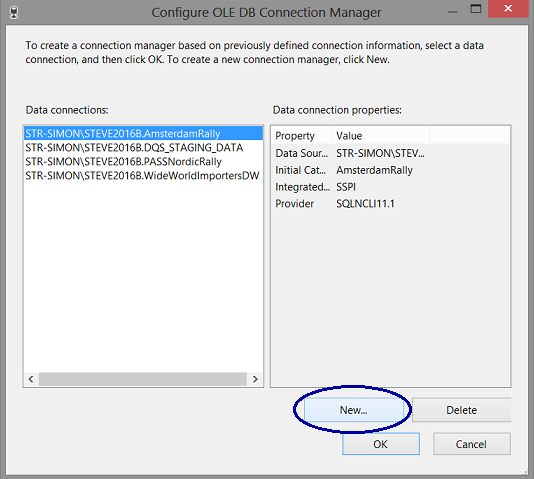
We select “New” (see above).
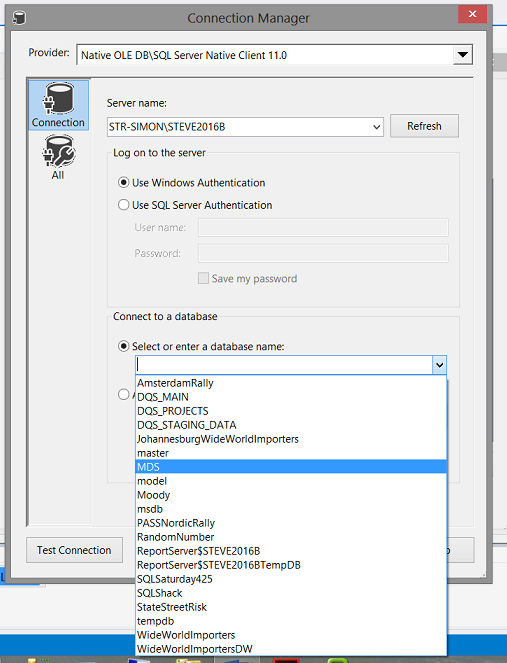
We select our MDS database. Why? Our source data for our process feed originates within Master data services.
As an aside, the MDS database is generated by the system upon setting up Master data services (as a part of the installation process). The actual name for this database is of course your choice HOWEVER, I prefer to call it MDS as it now becomes very apparent exactly what this database does.
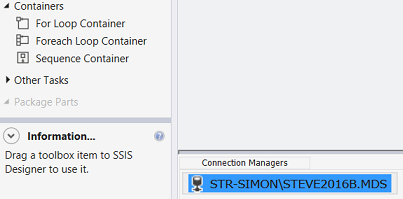
We see that our connection has been created (see above). We add one last connection (which we shall utilize a bit later) and this connection is to the SQL Shack database (that we have utilized on numerous occasions).

Our connection to the SQL Shack database may be seen above.
The data flow
We drag a “Data Flow Task” onto our drawing surface (see above).
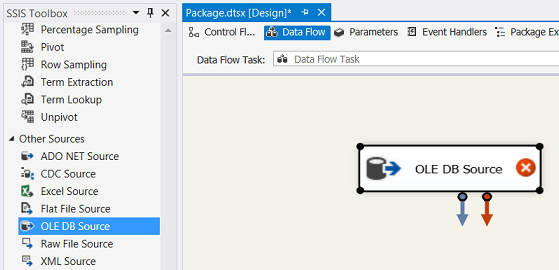
We click the “Data Flow” tab (see above) and we drag an “OLE DB Source” onto our drawing surface (see above).
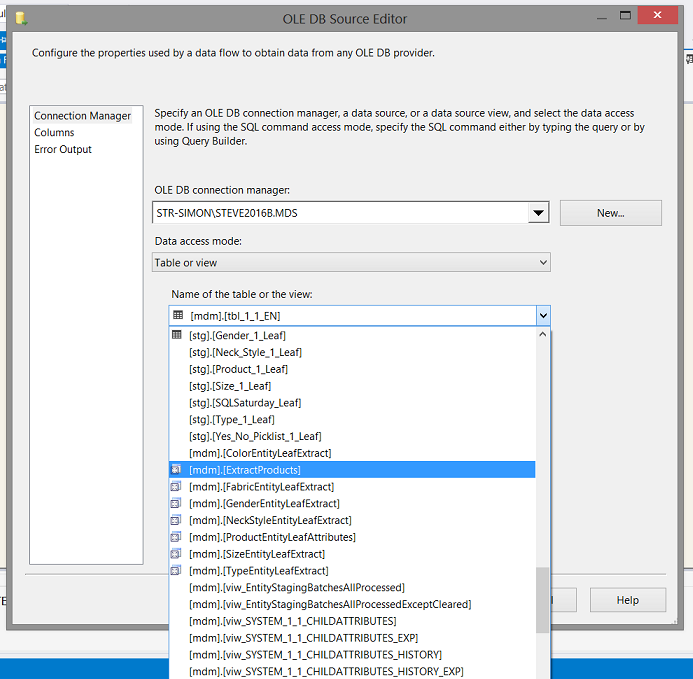
We select a view that I have already created. This view will permit us to pull our existing fact data from MDS. The important point to realize is that a MDS view is not quite the same as a standard view that we would create against normal database tables. MDS creates the view for you.
I have covered MDS views in an earlier “fire side chat” entitled “A front end definitely out of the box”. Should you not be familiar with constructing MDS views, then please do have a quick look at this discussion.
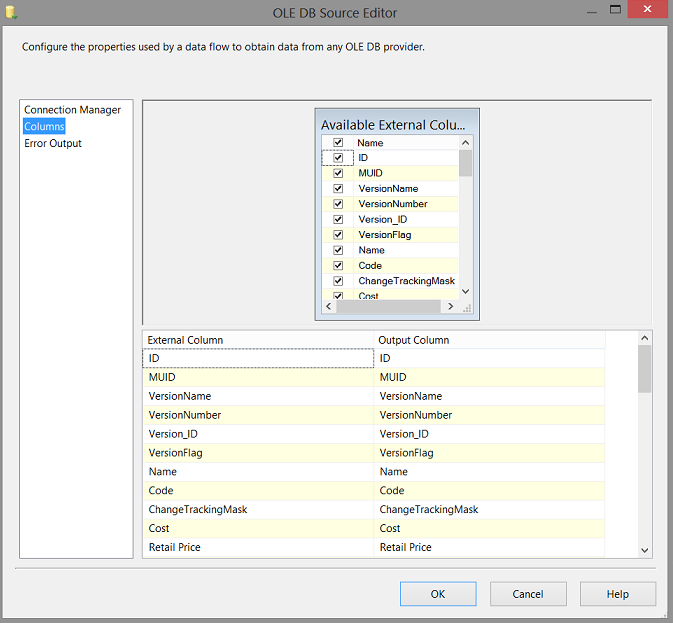
We set our OLE DB connection to the view “Extract Product” and the fields within the view are brought to the screen (see above).
Our drawing surface appears as above.
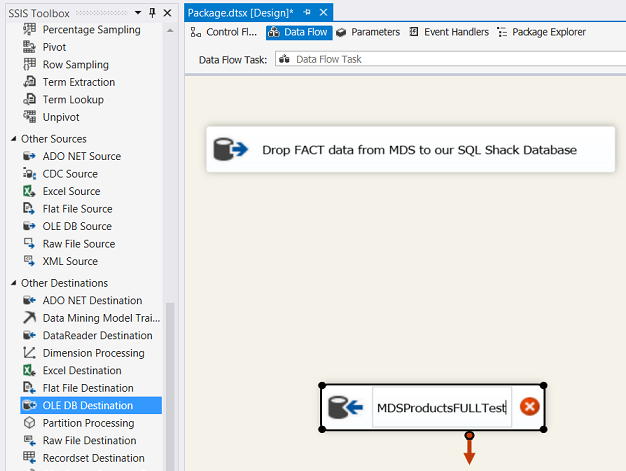
We drag an “OLE DB Destination” control onto the drawing surface (see above).
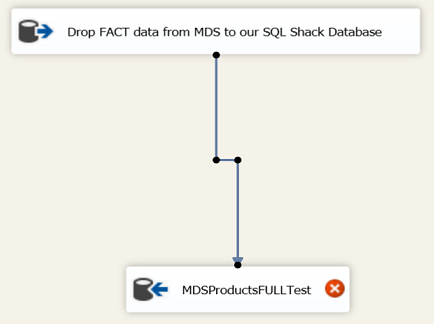
We connect the “Data Source” to the “Data Destination” and then double click on the destination.
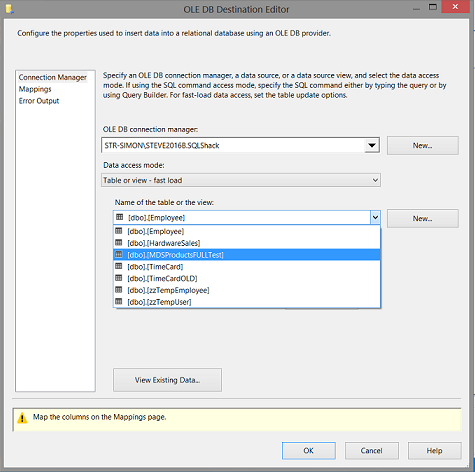
We select the “MDSProductsFULLTest” table (see above).
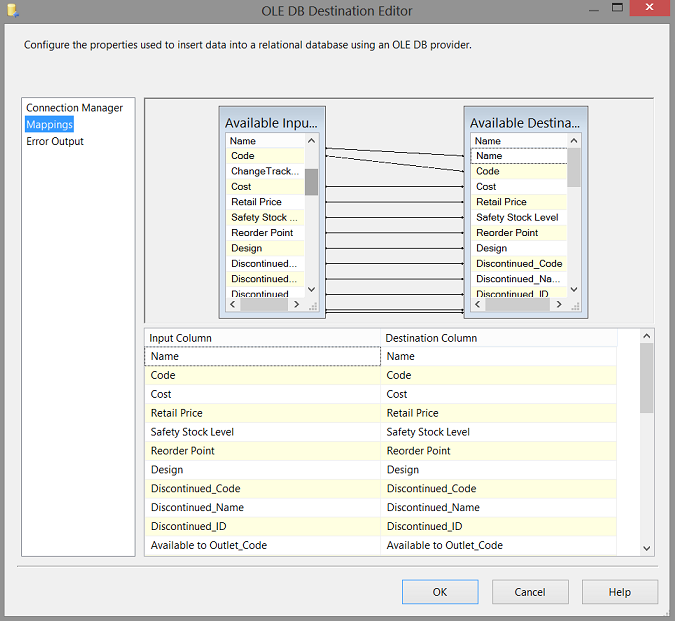
Clicking upon the “Mappings” tab we map the source and destination fields (see above).
“Pushing” our data through Data quality services
Within our SQL Shack Database we create four separate tables for…
- Correct data
- Corrected data (data which Data quality services corrects for you i.e. Kellllloggs becomes Kellogg’s
- New (new data)
- Invalid Data (i.e. the color Pers)
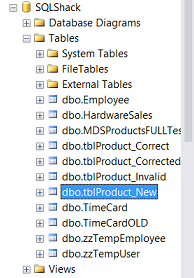
These four tables may be seen above.
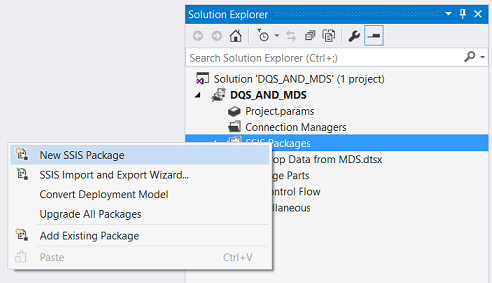
We create another new package and call it “PASS data to DQS”
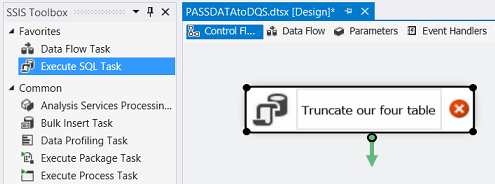
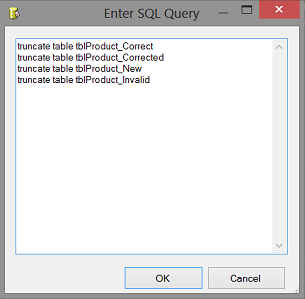
We add an “Execute SQL Task” to the drawing surface (see above). We double click the control and set the connection to the SQL Shack database and add the truncate statements to the control (see below).
This ensures that the tables are empty before we begin processing.
We now add a “Data Flow Task” to our drawing surface.
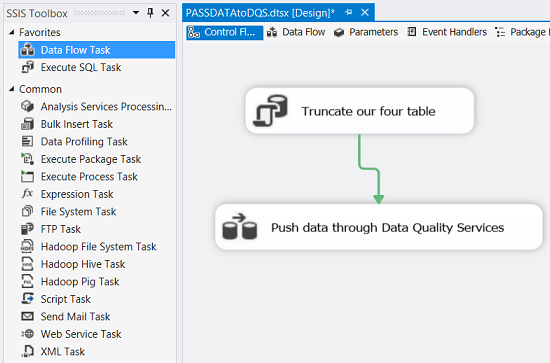
We double click upon the Data Flow Task. The “Data Flow Task” work surface appears (see below).
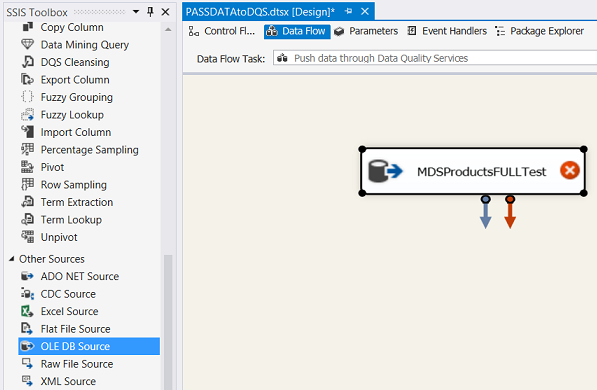
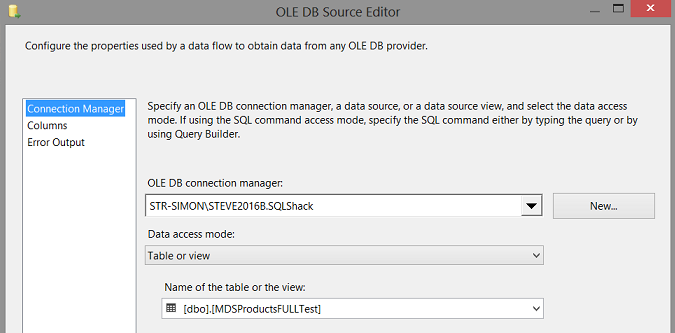
We point the data source to our “MDSProductsFULLTest” table.
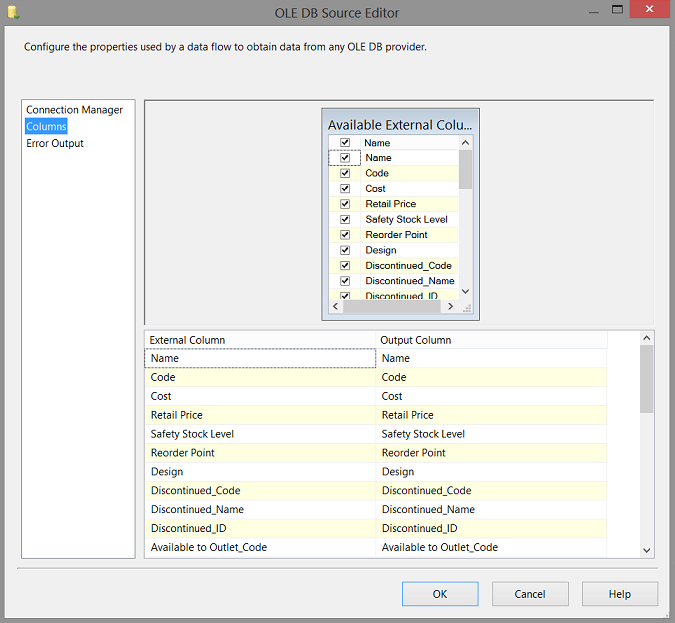
By clicking upon the “Columns” tab we see all the fields within the table (which originated from the MDS view). We click “OK” to leave the “Data Source” editor.
We now add a “DQS Cleansing” Control to our “Data Flow” surface. This control is really super in that it will pass incoming data to the Data quality services knowledge base that we just created.
We join the data source to the “DQS Cleansing” control and double click the control to open and edit it.
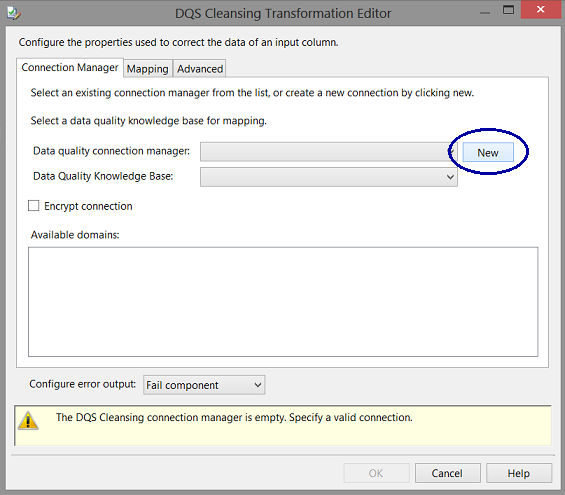
We click the “New” Button to create a new connection (see above).
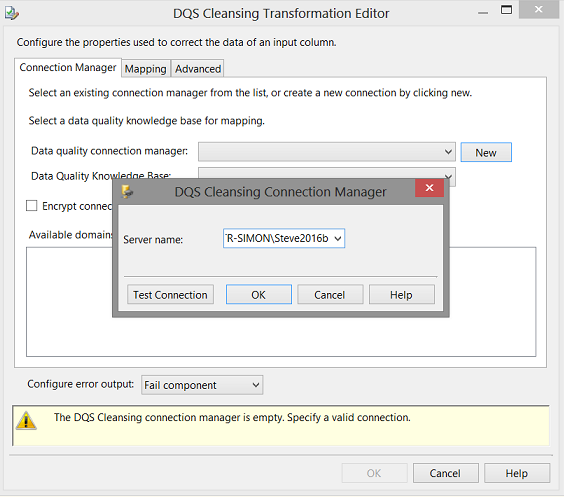
The “DQS Cleansing Connection Manager” appears. We simply set the server name (see above).
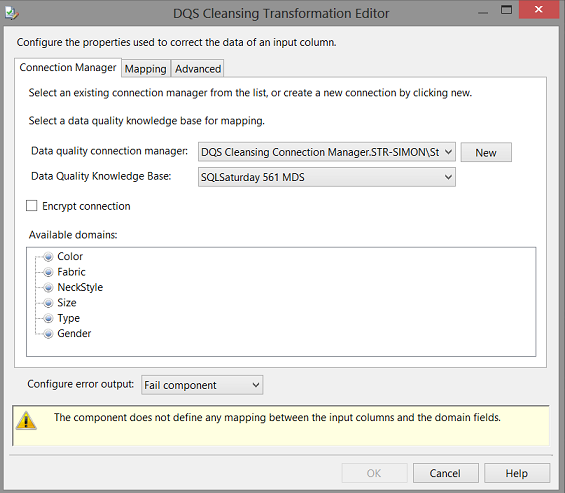
We choose the knowledge base that we created above. Now the eagle–eyed reader will note that I have selected the SQLSaturday 561 MDS Knowledge base. I did so as this model was complete as we had only completed a portion of the knowledge base that we started above.
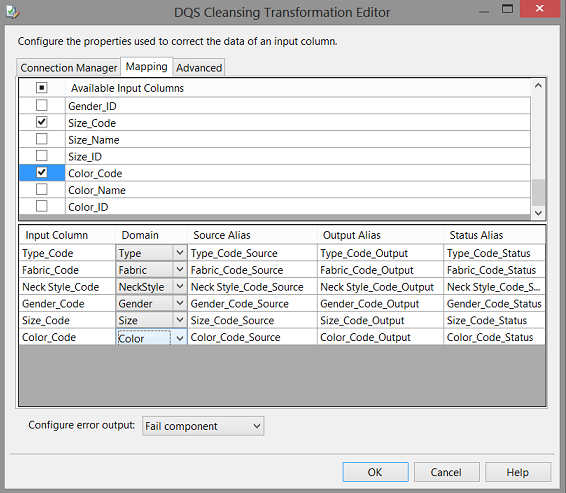
Clicking upon the “Mapping Tab” we map the table input fields to the Domains that we created within Data quality services (see above).We select the “Type_Code”, “Fabric_Code”, “Gender_Code”, “Size_Code”,”Neck_Style_Code”, “Color_Code”. We click “OK” to accept our choices and to leave the “Data Cleansing Transformation Editor”.
The modified drawing surface appears as shown below.
At this point, we remember that the data entering the cleansing task will be “judged” by our Knowledge Base. The Knowledge Base will automatically tag each record as either “Correct” or when it finds “Kelllllllllogggggggs” correct the spelling to “Kellogg’s” after the model has learnt that the two “spellings” are synonymous. Thus this record has been “Corrected”.
Should the Knowledge Base find a product such as the “Latest and Greatest” it will mark it as “New” and finally should the product contain the colour “Pers” then the record will be marked as “Invalid” as we told the “Color” domain that the colour cannot be “Pers”.
This understood, we add a “Conditional Split” and four “OLE DB Destinations” to our Data Flow Surface (see below).
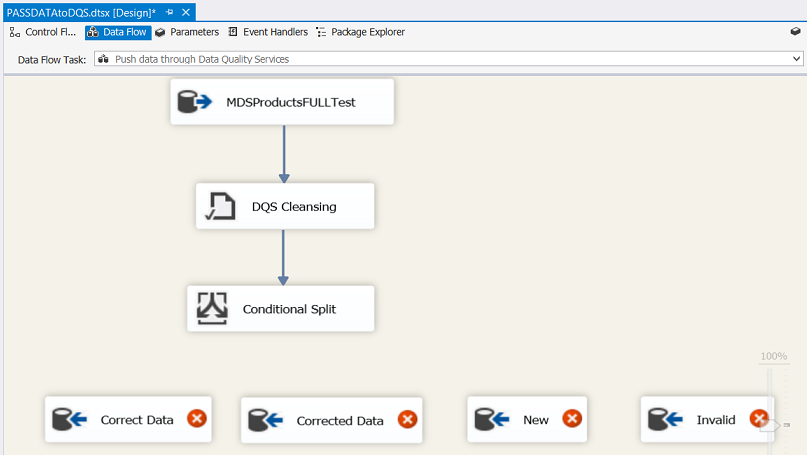
We now double click upon our “Conditional Split” to configure the control (see below).
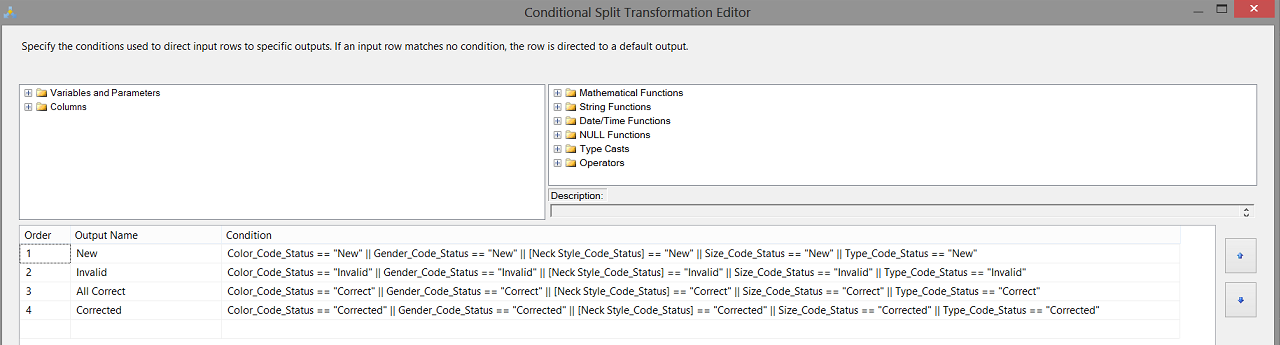
We shuffle the “Destinations” a tad and connect the conditional split to the appropriate destinations (see below).
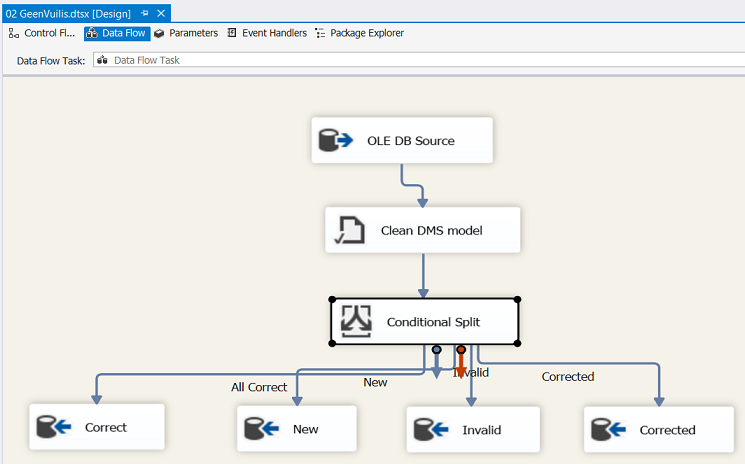
This conclude the construction of the “Cleansing Package”.
A note of explanation
At this point in time we have the data that came down from Master data services split into four parts.
- Correct
- Corrected
- New
- Invalid
It should be obvious that the content of the contents of the Correct, Corrected, and New tables must go back to Master data services to be either “Updated” or “Inserted”.
The only data that will not be returned to master data services will be the invalid data. The important point being that in our case, the MDS data that just came down is always being merged with “NEW” incoming transactions and that the combined lot must be passed through the cleansing module (as may be seen below).
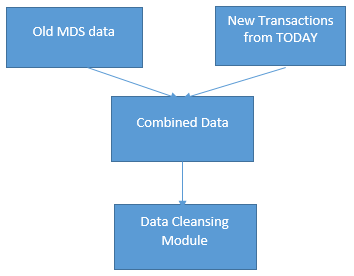
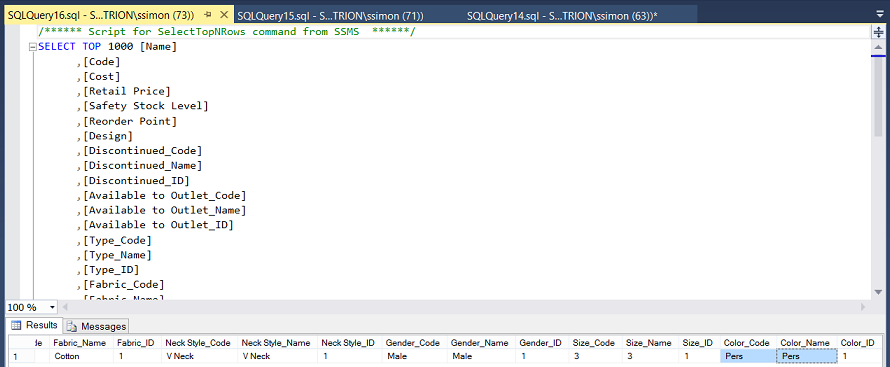
In order to simulate a “New” Transaction that has bad data, I created a special table (see above).
After the data has been brought down from Master data services and has been placed in the “MDSProductsFULLTest” table, we insert this bad record into the mix. The whole table is then passed through the Data Cleansing control. Naturally the record with “Pers” (see above) will be flagged as “Invalid”. The way that I find best to remove these bad records (before the contents of the table is pushed back to Master data services) is by utilizing a small piece of code that deletes the bad records from the “MDSProductsFULLTest” table.
The piece of code to remove the bad record may be found in Addenda 1.
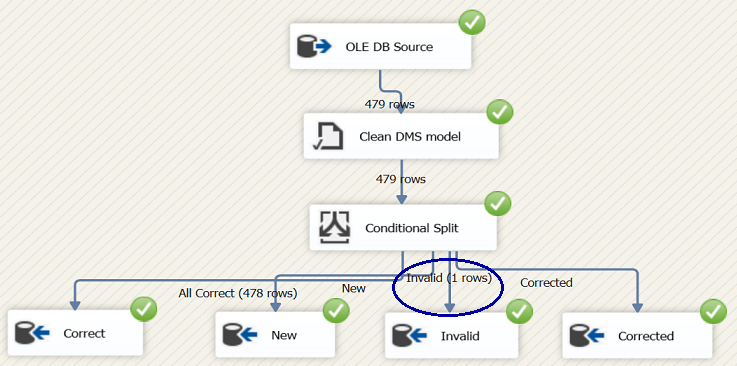
When the “Cleansing” package is run, the results should be similar to what is shown in the screen shot above.
The reader is reminded that Master data services has its own validation rules. Any data within Master data services that obeys the MDS rules is deemed as valid. Further, Master data services will not permit breaches of validation rule. This said, the only potential problematic data will come from new transactions.
The Data quality services knowledge base will handle this.
Returning the data to Master data services
Our final task is to “push” the validated data back to Master data services. We achieve this with another SQL Server Integration Services package.
Once again we add a “Data Flow Task” from the SSIS toolbox to the drawing surface.
We double click on the “Data Flow Task”.
We add an “OLE DB Source” (see above) and point it to our data table “MDSProductsFULLTest” (see below).
We now encounter a bit of a tricky one. Before we are able to “push” our data back to Master data services, we must declare a few control variables that Master Data Service requires to understand exactly what must be done to the data once it arrive up on the Master data services server.
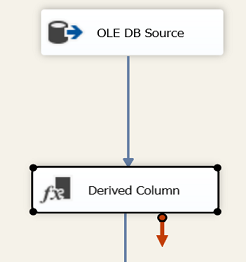
We drag a “Derived Column” control (from the SSIS toolbox) onto the drawing surface. We double click our control to define these control fields and to provide them with the appropriate arguments.
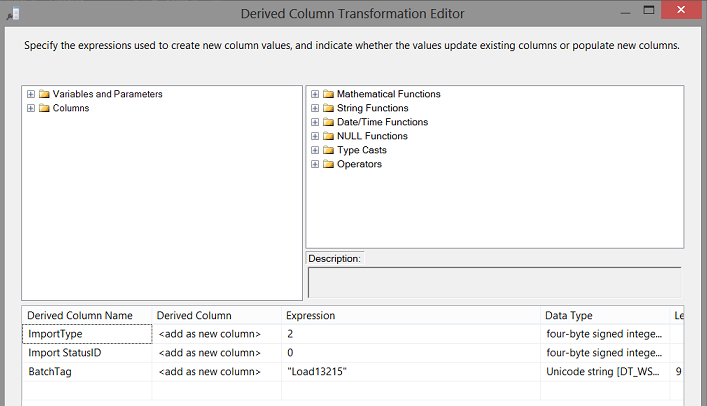
The “ImportType” field tells Master data services how to handle the data. A valid list of arguments may be seen below:

We chose 2 or
“Create new members. Replace existing MDS data with staged data. If you import NULL values, they will overwrite existing MDS values.”
The ImportStatusID field has three possible “Flavours”
- 0
- 1
- 2

We select 0 to indicate that the records are ready for staging.
Finally we give our records a Batch Tag name which is user defined and ensures that the correct records are updated / inserted. REMEMBER, that many records could be circulated day after day (through the process) and with the same Batch Tag name, this will avoid duplicate entries within Master data services.
Our final step is to define the staging table within Master data services where the returning data must be staged. It should be noted that upon the creation of a entity/ table within Master data services, that Master data services automatically creates a staging table. It is only a matter of finding the name of this staging table.
We add an “OLE DB Destination” from the SSIS toolbox and place it on the drawing surface. We double click upon the control to configure it.
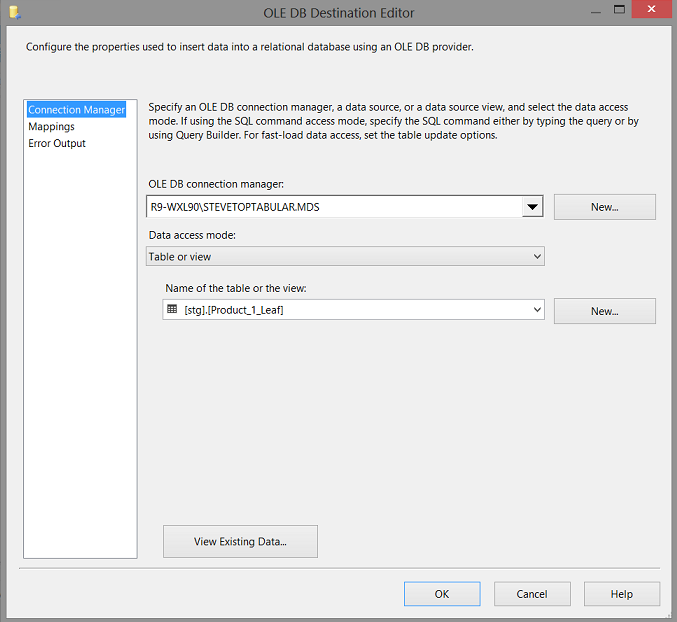
As it stands at the present moment, the mechanism to return the data to Master data services is complete.
The last remaining task is to create a T-SQL command that will tell Master data services to begin processing the incoming data.
Opening the “Execute SQL Task” we enter the following code (see below).
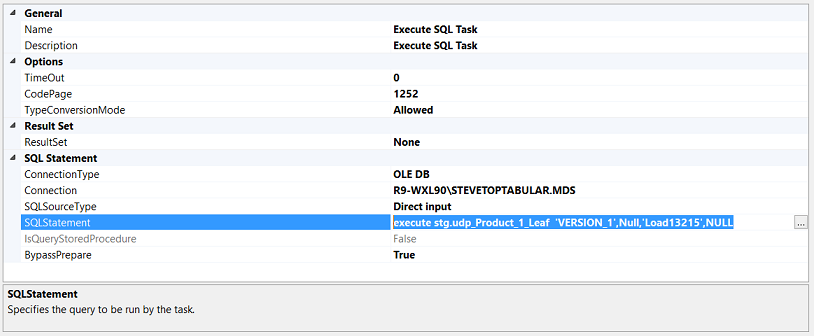
As mentioned above, when this code is executed, then the data from the staging table will be processed and placed into the production tables.
That’s all folks!!!
Conclusions
So we come to the end of another “fire side chat”. Whilst the whole process may appear a tad convoluted, it is really rather simple.
As as DBA or as a Business Intelligence person, we are all concerned about data quality and if we are true to ourselves, then we acknowledge that there are always data quality issues.
Many folks who do not wish to develop .NET front ends are having a serious look at utilizing Master data services as a tried and trusted front end for data maintenance.
Data quality services is a great tool to detect erroneous newly created data and to flag bad records so that the Data Stewards are able to examine these records and to rectify the errors.
Finally when the two product appeared with SQL Server 2012 there were many skeptics however it should be noted that the skeptism is rapidly waning.
Happy programming.
Addenda 1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
USE [SQLshack] GO /****** Object: StoredProcedure [dbo].[InvalidAttributesForProducts] Script Date: 8/10/2016 1:31:48 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE procedure [dbo].[InvalidAttributesForProducts] as Insert into [SQLShack].[dbo].[tblProduct_InvalidDataEntry] SELECT [Name] ,[Code] ,[Cost] ,[Retail Price] ,[Safety Stock Level] ,[Reorder Point] ,[Design] ,[Discontinued_Code] ,[Discontinued_Name] ,[Discontinued_ID] ,[Available to Outlet_Code] ,[Available to Outlet_Name] ,[Available to Outlet_ID] ,[Type_Code] ,[Type_Name] ,[Type_ID] ,[Fabric_Code] ,[Fabric_Name] ,[Fabric_ID] ,[Neck Style_Code] ,[Neck Style_Name] ,[Neck Style_ID] ,[Gender_Code] ,[Gender_Name] ,[Gender_ID] ,[Size_Code] ,[Size_Name] ,[Size_ID] ,[Color_Code] ,[Color_Name] ,[Color_ID] FROM [SQLShack].[dbo].[MDSProductsFULLTest] where not code in ( select data.code from [SQLShack].[dbo].[MDSProductsFULLTest] data inner join [SQLShack].[dbo].[MDSProductsFULLTest1] ref on ref.code = data.code and ref.Color_Code = data.Color_Code and ref.Fabric_Code = data.Fabric_Code and ref.[Neck Style_Code] = data.[Neck Style_Code] and ref.Gender_Code = data.Gender_Code and ref.Size_Code = data.Size_Code and ref.Type_Code = data.Type_Code ) delete from [SQLShack].[dbo].[MDSProductsFULLTest] where code in (select Code from dbo.tblProduct_Invalid) GO |
References:
- Bulk Loading into MDS using SSIS
- Links from the SSIS Roadmap Session
- Introduction to Data quality services
Steve has presented papers at 8 PASS Summits and one at PASS Europe 2009 and 2010. He has recently presented a Master Data Services presentation at the PASS Amsterdam Rally.
Steve has presented 5 papers at the Information Builders' Summits. He is a PASS regional mentor.
View all posts by Steve Simon
- Reporting in SQL Server – Using calculated Expressions within reports - December 19, 2016
- How to use Expressions within SQL Server Reporting Services to create efficient reports - December 9, 2016
- How to use SQL Server Data Quality Services to ensure the correct aggregation of data - November 9, 2016